作业提交过程比较简单,它主要为后续作业执行准备环境,主要涉及创建目录、上传文件等操作;而一旦用户提交作业后,JobTracker端便会对作业进行初始化。作业初始化的主要工作是根据输入数据量和作业配置参数将作业分解成若干个Map Task以及Reduce Task,并添加到相关数据结构中,以等待后续被高度执行。总之,可将作业提交与初始化过程分
转载
2023-07-20 20:41:30
130阅读
hadoop job -kill jobid 可以整个的杀掉一个作业,在这个作业没啥用了,或者确认没有价值的情况下使用hadoop job -kill-task attempid 如果一个作业的某个mapper任务出了问题,而整个作业还希望继续运行的情况下,使用这个命令 1) 重启坏掉的DataNode或JobTracker。当Hadoop集群的某单个节点出现问题时,一般不必
转载
2023-05-29 11:20:53
386阅读
由于spark的懒执行,在驱动程序调用一个action之前,spark应用不会做任何事情。 针对每个action,Spark调度器就创建一个执行图(execution graph)和启动一个Spark Job。 每个job有多个 stage组成,这些stage就是实现最终的RDD所需的数据转换的步骤。一个宽依赖划分为一个stage。 每个stage由多个tasks组成,这些tasks就表示每个并行
转载
2023-09-23 17:45:06
120阅读

1.案情 很单纯的讲,就是一个spark程序以yarn-cluster的模式运行在yarn集群上,经常遇到Lost executor Container be killed by yarn for exceed memory limits2.spark大致架构3、案发现场  
转载
2024-07-14 08:17:44
51阅读
目录一、分区表1.新建分区表2.向分区表插入数据1.静态分区2.动态分区3.创建多级分区二、分桶表1.新建原表2.建立分桶表并按照sid排序3.向分桶表插入数据4.分桶原理5.分桶排序三、复杂类型1.array2.struct3.map一、分区表避免全表扫描, 减少扫描次数, 提高查询效率.create table t_all_hero_part(
字段1 类型 comment '
hadoop命令行 与job相关的:命令行工具 1.查看 Job 信息:hadoop job -list 2.杀掉 Job: hadoop job –kill job_id3.指定路径下查看历史日志汇总:hadoop job -history output-dir 4.作业的更多细节: hadoop job -history all output-dir 5.打
转载
精选
2016-04-28 15:35:28
1890阅读
job相关 1.查询某个存储过程的内容 select text from all_source where name ='JOB_MB_ERR_CHECK' 2.查询job的内容 select job,NEXT_DATE ,NEXT_SEC,TOTAL_TIME ,INTERVAL,FAILURES,LAST_DATE from dba_jobs
原创
2014-04-29 15:51:52
330阅读
0. 启动flink-session ./bin/yarn-session.sh -n 4 -s 3 -jm 2048 -tm 6144 高版本 bin/yarn-session.sh -d -s 3 -jm 2048 -tm 6144 -qu root.sparkstreaming -nm hm2 ...
转载
2021-10-28 13:54:00
1141阅读
2评论
Hadoop MR Job命令是用于管理和执行MapReduce作业的重要工具。在这篇博文中,我将以一个复盘的形式详细正确记录和分析将Hadoop MR Job命令应用到实践中的过程,涵盖环境配置、编译过程、参数调优、定制开发、调试技巧及进阶指南等方面。
### 环境配置
首先,确保Hadoop环境已正确安装。以下是环境配置的步骤:
1. 下载Hadoop:
- 从[Apache官网下
这篇文档简要描述了 Flink 怎样调度作业, 怎样在 JobManager 里描述和追踪作业状态。调度Flink 通过 Task Slots 来定义执行资源。每个 TaskManager 有一到多个 task slot,每个 task slot 可以运行一条由多个并行 task 组成的流水线。 这样一条流水线由多个连续的 task 组成,比如并行度为 n 的 MapFunction 和 并行度为
转载
2024-03-16 15:25:54
84阅读
由于streaming流程序一旦运行起来,基本上是无休止的状态,除非是特殊情况,否则是不会停的。因为每时每刻都有可能在处理数据,如果要停止也需要确认当前正在处理的数据执行完毕,并且不能再接受新的数据,这样才能保证数据不丢不重。 同时,也由于流程序比较特殊,所以也不能直接kill -9这种暴力方式停掉,直接kill的话,就有可能丢失数据或者重复消费数据。 下面介绍如何优雅的停止streami
转载
2023-05-29 16:03:05
762阅读
<wbr>想kill掉他
<div>使用 kill PID 未提示任何错误信息,但是进程还是在运行着</div>
<div><br></div>
<div>解决办法:</div>
<div>kill -9 PID</div>
<div><br></d
yarn kill job命令 yarn logs -applicationid命令
转载
2023-05-27 14:10:41
161阅读
 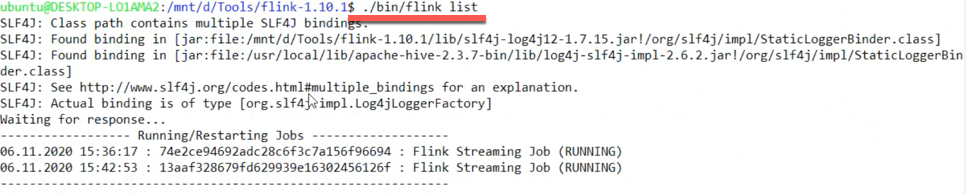 。准备停止JOB,因为在JOB运行情况下,我的所有修改都会报系统资源忙的错误。强行KILL SESSION是行不通的,因为过
转载
2024-03-31 08:57:13
132阅读
linux基本操作和常用命令(1)linux是目前在工作中经常会用到一个操作系统,接下来就根据企业工作中,经常会用到的一些linux基本操作和常常会使用的一个命令,做一下详细介绍。一:linux basis
常用的简单命令很多,有些很简单,这里只是简单列举下,不做效果实现。
1:echo whoami tree cd pwd ls等,其中ls -l会显示文件的属性,-a会显示当前目录下所有的文件和
告警和日志信息监控目录告警和日志信息监控 实验一:查看大数据平台日志信息 实验任务一:查看大数据平台主机日志 步骤一:查看内核及公共消息日志(/var/log/messages)。 步骤二:查看计划任务日志/var/log/cron。 步骤三:查看系统引导日志/var/log/dmesg。
转载
2023-09-20 07:03:43
496阅读























