文章目录1 两阶段提交核心设计2 大数据去重普适架构3 Flink 整合 Redis HBase exactly once4 Kafka exactly once5 SQL on Stream 平台架构通过幂等性实现仅一次语义两阶段提交 预提交 提交 精选面试题 Flink 相比 SparkStreaming 有什么区别? 多角度问答架构模型Spark Streaming 在运行时的主要角色包括
转载
2024-03-21 09:46:38
41阅读

# 使用Flink在YARN上运行作业的步骤
## 1. 确保环境配置
在开始之前,确保你已经完成了以下步骤:
1. 安装和配置Flink集群和YARN集群。
2. 确保你有一个可用的Flink作业Jar文件。
## 2. 将作业提交到YARN
接下来,我们将具体说明如何提交Flink作业到YARN上。
1. 打开终端并登录到你的Flink集群的主节点。
2. 使用以下命令运行作业:
原创
2023-09-06 12:32:37
355阅读
1. 上传 flink 相关 plugins 到hdfs2. 上传 flink 相关 依赖到 hdfs3. 上传用户 jar 到 hdfs4. 提交任务flink run-application -t yarn-application \-c com.sm.analysis.rdw.SdkDataEtlOdsToDwd \-Djobmanager.memory.process.size=1600m \-Dtaskmanager.memory.process.size=2048
原创
2021-08-31 13:47:37
1447阅读
前言Kafka是我们日常的流处理任务中最为常用的数据源之一。随着数据类型和数据量的增大,难免要增加新的Kafka topic,或者为已有的topic增加更多partition。那么,Kafka后面作为消费者的实时处理引擎是如何感知到topic和partition变化的呢?本文以Spark Streaming和Flink为例来简单探究一下。Spark Streaming的场合 根据官方文
转载
2024-06-21 20:47:21
82阅读
注: 所有内容都基于Flink 本地模式JobGraph 的生成是从 LocalExecutor.java. execute 方法开始的// 本地执行调用 Pipeline 是 StreamGraph 的父类
@Override
public CompletableFuture<JobClient> execute(Pipeline pipeline, Configuration c
转载
2024-07-04 22:49:00
35阅读
0. 启动flink-session ./bin/yarn-session.sh -n 4 -s 3 -jm 2048 -tm 6144 高版本 bin/yarn-session.sh -d -s 3 -jm 2048 -tm 6144 -qu root.sparkstreaming -nm hm2 ...
转载
2021-10-28 13:54:00
1141阅读
2评论
这篇文档简要描述了 Flink 怎样调度作业, 怎样在 JobManager 里描述和追踪作业状态。调度Flink 通过 Task Slots 来定义执行资源。每个 TaskManager 有一到多个 task slot,每个 task slot 可以运行一条由多个并行 task 组成的流水线。 这样一条流水线由多个连续的 task 组成,比如并行度为 n 的 MapFunction 和 并行度为
转载
2024-03-16 15:25:54
84阅读
一、flink架构1.1、集群模型和角色如上图所示:当 Flink 集群启动后,首先会启动一个 JobManger 和一个或多个的 TaskManager。由 Client 提交任务给 JobManager,JobManager 再调度任务到各个 TaskManager 去执行,然后 TaskManager 将心跳和统计信息汇报 给 JobManager。TaskManager 之间以流的形式进行
转载
2024-03-27 10:34:02
255阅读
Flink 命令行参数介绍一、Flink Command | CLI Actions1.1 客户端命令介绍1.2 使用示例二、Flink Run Command | flink run2.1 命令介绍2.2 使用示例 参考文档: 1、https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/deployment/cli/ 2、
转载
2023-09-20 16:30:47
540阅读
点赞
history job的写入1. org.apache.flink.runtime.jobmanager,Object JobManagerrunJobManager中指定使用MemoryArchivist进行作业保存startJobManagerActors中创建了进行作业保存的actor此archive的actor会被传入jobmanager的actor2. org.apache.flink.
转载
2024-05-07 21:28:02
208阅读
  2. 任务管理器(TaskManager)二、作业提交流程1. 高层级抽象2. 独立模式(Standalone)3. YARN 集群三、一些重要概念1. 数据流图(Dataflow Graph)2. 并行度(Parallelism)3. 算子链(Operator Chain)4. 作业图(Jo
转载
2024-03-19 07:40:55
65阅读
作业调度这篇文档简要描述了 Flink 怎样调度作业, 怎样在 JobManager 里描述和追踪作业状态调度Flink 通过 Task Slots 来定义执行资源。每个 TaskManager 有一到多个 task slot,每个 task slot 可以运行一条由多个并行 task 组成的流水线。 这样一条流水线由多个连续的 task 组成,比如并行度为 n 的 MapFunction 和 并
转载
2024-03-15 11:18:26
71阅读
.一 .前言二 .名词解释2.1. StreamGraph2.2. JobGraph2.3. ExecutionGraph2.4. 物理执行图二 .Flink 四层转化流程2.1. Program 到 StreamGraph 的转化2.2. StreamGraph 到 JobGraph 的转化2.3. JobGraph 到 ExexcutionGraph 以及物理执行计划 一 .前言Flink
众所周知,flink作为流计算引擎,处理源源不断的数据是其本意,但是在处理数据的过程中,往往可能需要一些参数的传递,那么有哪些方法进行参数的传递?在什么时候使用?这里尝试进行简单的总结。使用configuration 在main函数中定义变量1 // Class in Flink to store parameters
2 Configuration configuration = new Co
转载
2023-07-04 11:43:43
152阅读
一、flink涉及到的基础概念Flink 几个最基础的概念,Client、JobManager 和 TaskManager.二、概述Flink 整个系统主要由两个组件组成,分别为 JobManager 和 TaskManager,Flink 架构也遵循 Master - Slave 架构设计原则,JobManager 为 Master 节点,TaskManager 为
转载
2024-05-01 23:24:57
69阅读
.一 .前言二 .StreamOperator2.1. 生命周期相关2.2. 快照状态相关2.3. 其他接口2.4.OneInputStreamOperator三.AbstractStreamOperator3.1. 属性3.2. 源自父类相关方法实现四 .AbstractUdfStreamOperator4.1. 属性4.2. 构造方法五 .StreamMap5.1. 构造方法5.2. pro
转载
2024-06-28 09:58:36
35阅读
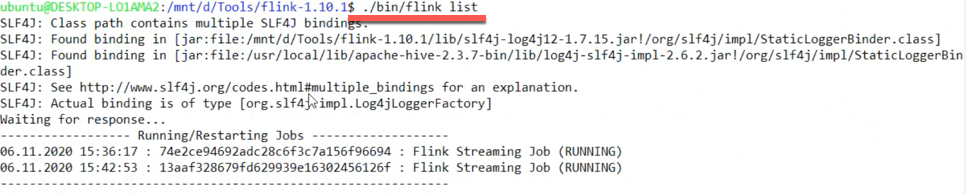
flink启动命令分析1. flink启动命令的固定格式./flink <ACTION> [OPTIONS] [ARGUMENTS]2 <ACTION>种类run 编译和运行一个程序。run-application 在应用模式下运行一个应用程序info 显示程序的优化执行计划(JSON)。list 列出正在运行的和计划中的程序。stop 用一个保存点停止一个正在运行的程序(
转载
2023-12-01 18:25:09
112阅读
# Flink on YARN Per-Job 启动命令详解
## 流程图
```flow
st=>start: 开始
op1=>operation: Flink on YARN Per-Job 启动命令
op2=>operation: 执行flink run命令
op3=>operation: 配置flink-conf.yaml文件
op4=>operation: 执行yarn-session
原创
2023-08-15 09:27:34
473阅读
1、首先我使用的Flink版本Flink1.12.02、出现错误场景在进行Flink和Hive(3.1.2)版本进行集成,通过sql-client.sh embedded来执行(select * from emp)语句时出现此错误信息---> 报错信息---> 分析org.apache.flink.util.FlinkException: Could not upload job fi
转载
2024-03-31 08:27:28
232阅读
























