1.引言1.1. 背景PostgreSQL 从 10 版本之后推荐采用源码编译或 yum 方式安装,本文介绍源码安装方式1.2. 关于此文档本文档主要介绍 PostgreSQL 的源码编译安装及基本配置。1.3. 参考资料2. 安装前准备2.1. 软件、硬件说明文件系统建议使用 LVM 管理最新源码下载网址:https://www.postgres
pg_hba.conf作用哪些主机可以连接数据库实例哪个数据库用户可以使用它允许这个用户使用哪些数据库客户端使用什么连接方式和认证方式postgresql.conflisten_addresses = '*' #(关联配置文件pg_hba.conf)#指定服务器在哪些 TCP/IP 地址上监听客户端连接。值的形式是一个逗号分隔的主机名和/或数字 IP 地址列表。 特殊项*对应监听所有可用 IP
vacuum free能有效将事务年龄过大的问题解决,但是这个非常耗时间,这个时候最方便的就是开启screen进行vacuum freeze开启screen窗口$ screen -dmS your_session_name #your_session_name 自定义 可以直接使用 —S-d <作业名称> 将指定的screen作业离线。-m 即使目前已在作业中的screen作
小版本升级小版本升级不会改变内部的存储格式,因此总是和大版本兼容。例如,PostgreSQL 12.4 和 PostgreSQL 12.0 以及后续的 PostgreSQL 12.x 兼容。对于这些兼容版本的升级非常简单,只需要关闭数据库服务,安装替换二进制的可执行文件,重新启动服务即可。大版本升级官方提供三种方式Upgrading Data via pg_dumpall,使用 pg_dumpa
pg模板库template1和template0是PostgreSQL的模板数据库。所谓模板数据库就是创建新database时,PostgreSQL会基于模板数据库制作一份副本,其中会包含所有的数据库设置和数据文件。PostgreSQL安装好以后会默认附带两个模板数据库:template0和template1。设置模板库属性pg_database的datistemplate字段可以表明该库是否是模
赋予查询指定列的权限postgres=# create table test(name text,credit text,passwd text);CREATE TABLEpostgres=# insert into test values('zhangsan','11111123','asdf');INSERT 0 1postgres=# create user customer;CREATE
PG中的bug根据SQL标准,一个模式的所有者总是拥有其中的所有对象。PostgreSQL允许模式包含由模式所有者以外的用户拥有的对象。这种情况才会发生在,当模式拥有者将模式的"CREATE"权限授予其他人,或者超级用户选择在模式中创建对象。所以,就存在这么一种情况,一个对象属于两个owner,schema的owner可以直接drop其他用户创建的对象。同样这种情况在database中也出现。模式
角色和用户的使用举个例子,创建一个只读用户和两个读写用户通用前提操作REVOKE CREATE ON SCHEMA public FROM PUBLIC;REVOKE ALL ON DATABASE mydatabase FROM PUBLIC;创建只读角色CREATE ROLE readonly;GRANT CONNECT ON DATABASE mydatabase TO readonly;G
权限结构图pg中权限至上而下层次分明,首先要了解pg的逻辑架构,如下图需要注意的是在如上架构中数据库是严格分开的,这意味着不能同时使用两个不同的数据库,而模式不是严格分开的,可以一起使用和访问同一数据库的两个或多个模式中的对象。模式是逻辑层面的划分,那么表空间就是物理层面的划分,表空间只能属于某一个实例,但是可以被多个数据库使用。权限总结概念(1)在数据库中所有的权限都和角色(用户)挂钩,角色和用
单机版流复制测试环境搭建搭建规划主库备库数据目录/pgdata/12/data/pgdata/1202/data归档目录/pgdata/12/arch/pgdata/1202/arch端口54325433创建流复制用户create role replica with replication login password '123456';备份主库pg_basebackup -D /backup/
备份pg_basebackup -D /tmp/pg_backup/ -Ft -Pv -U postgres -h 1.15.57.253 -p5432 -R空文件,没有该目录会自动创建 F 格式话 t 打包为tar包 Pv显示备份的详细过程 -u 用户 -p 端口备份报错在配置文件pg_hba.conf增加一行备份流程:pg_basebackup: initiating base back
wal日志介绍wal日志即write ahead log预写式日志,简称wal日志。wal日志可以说是PostgreSQL中十分重要的部分,相当于oracle中的redo日志。当数据库中数据发生变更时:(1)change发生时:先要将变更后内容计入wal buffer中,再将变更后的数据写入data buffer;(2)commit发生时:wal buffer中数据刷新到磁盘;(3)checkpo
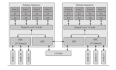
PG进程和内存结构图建立会话的过程阶段一:客户端发起请求阶段二:该阶段由主服务postmaster进程负责服务器是否接受客户端的host通信认证服务器对客户端进行身份鉴别PM进程:提供监听,连接协议,验证功能,fork其他进程 ,监听哪个IP是受到postgres.conf影响的,默认提供socket和TCP方式连接。建立会话的过程验证功能:通过pg_hba.conf和用户验证模块来提供。阶段三:
postgres=# select name ,setting from pg_settings where name like '%parallel%'; name | setting ----------------------------------+--------- enable_parallel_append
analyze自动收集统计信息自动收集统计信息是依赖AUTOVACUUM定时触发analyze触发 vacuum analyze的条件 表上(insert,update,delte 记录) >= autovacuum_analyze_scale_factor* reltuples(表上记录数) + autovacuum_analyze_threshold这个我在这篇里面写过https://b
字符类型char(n), varchar(n) 和textchar和varchar除非超出长度的字符都是空白,这种情况下该字串将被截断为最大长度如果没有长度声明,char等于char(1),而varchar则可以接受任何长度的字串数字类型由2、4或8字节的整数以及4或8字节的浮点数和可选精度小数组成。名字存储尺寸描述范围smallint2字节小范围整数-32768 to +32
用户角色管理创建用户角色create user cjr LOGIN;create role cjr1 CREATEDB;create role cjr2 superuser;create user cjr3 encrypted password '123456' valid until '2022-10-28';create user admin with SUPERUSER password
整体架构图共享内存区shared_buffers ---共享缓冲区它表示数据缓冲区中的数据块的个数,每个数据块的大小是8KB。数据缓冲区位于数据库的共享内存中,它越大越好,不能小于128KB。这个参数只有在启动数据库时,才能被设置。默认值是128MB。推荐值:1/4 主机物理内存 wal_buffers --- 日志缓存区的大小可以降低IO,如果遇上比较多的并发短事务,应该和commit_del
Sort需要排序数据时,这个节点就会作为计划树的一部分被添加。可以显式或隐式地要求排序数据postgres=# drop table demotable;DROP TABLEpostgres=# CREATE TABLE demotable (num numeric, id int);CREATE TABLEpostgres=# INSERT INTO demotable SELECT rando
PostgreSQL支持如下几种连接方式:Nested Loop JoinHash JoinMerge Joinpostgres=# create table blogtable1(id1 int, id2 int);CREATE TABLEpostgres=# create table blogtable2(id1 int, id2 int); CREATE TABLEpostgres=# i
CTID是什么CTID是一个系统列,用于标识某一元组位于哪个位置,由(block number + 块内的偏移量offset)组成和oracle的rowid十分类似select attname from pg_attribute where attrelid='test2'::regclass; attname ---------- cmax cmin ctid 类似oracle的r
VACUUM表膨胀是什么有效数据量不变,表越来越大,扫描的效率变低。是因为PG的MVCC写数据时,旧数据不删除,把新数据插入,将旧数据标记为无效,清理之前一直占用空间。执行update的话就是insert+delete的原理,依然会导致表膨胀。vacuum的作用磁盘清理dead tuple ;更新统计信息;重组数据;解决事务ID回卷问题。vacuum : 不要求获得排它锁,找到那些旧的“死”数据
下载源码包https://www.postgresql.org/ftp/source/v12.7/安装必要的包yum -y install readline readline-devel zlib zlib-devel gettext gettext-devel openssl openssl-devel pam pam-devel libxml2 libxml2-devel l
vacuum概述磁盘清理dead tuple ;更新统计信息;重组数据;解决事务ID回卷问题。vacuum做了什么1、清除update或delete 操作后留下的死元组2、跟踪表块中可用空间,更新free space map3、更新visibility map,index only scan 以及后续vacuum都会利用到4、冻结表中的行,防止事务ID回卷5、配合analyze ,定期更新统计信
优化准则在数据库优化中,主要有以下优化指标。响应时间:衡量数据库系统与用户交互时多久能够发出响应。吞吐量:衡量在单位时间内可以完成的数据库任务。进行数据库优化时,笔者都是围绕着上述指标进行优化的。数据库优化工作中,第一项就是确定优化目标。性能目标:如CPU利用率或IOPS需要降到多少。响应时间:需要从多少毫秒降到多少毫秒。吞吐量:每秒处理的SQL数或QPS需要提高到多少。一个已运行的数据库系统,如
索引更新问题因为多版本的原因,当PostgreSQL中更新一行时,实际上原数据行并不会被删除,只是插入了一个新行。如果表上有索引,而更新的字段不是索引的键值时,由于新行的物理位置发生了变化,仍然需要更新索引,这将导致性能下降。引入HOT为了解决这一问题,PostgreSQL自8.3版本之后引入了一个名为“Heap-Only Tuple”的新技术,简称HOT。使用HOT技术之后,如果更新后的行与原数
PG索引的多版本实现可见性映射表在PostgreSQL数据库中,索引上并没有多版本信息,因此即使SELECT的列都是索引列,在PostgreSQL 9.2之前的版本中还是需要再到表上去查询一次,但在PostgreSQL 9.2版本之后,该查询就可以省略了。这种扫描方式被称为“Index-Only Scans”。实际上,9.2版本也没有在索引中添加多版本信息,那它是如何实现该功能的呢?它是靠使用可见
实例恢复的原理数据库宕机原因导致数据库实例异常终止的原因有以下几种:·内存不足时被OOM Killer或用户kill掉。·操作系统崩溃。·硬件故障导致机器停机或重启。PG如何保证恢复后数据不丢失但只要磁盘上的数据没有丢失,PostgreSQL就能保证数据不会丢失,这里说的不丢数据是指如下情况:·数据库实例还能再次启动,如果数据库无法启动,很多时候相当于数据全部丢失,PostgreSQL会全力保证这
PG存储结构术语PostgreSQL中有一些术语与其他数据库中的名称不一样,了解了这些术语的含义,就能更好地看懂PostgreSQL中的文档。与其他数据库不同的术语有如下几个。Relation:表示表或索引,也就是其他数据库的Table或Index。具体表示的是Table还是Index需要看具体情况。Tuple:表示表中的行,在其他数据库中使用Row来表示。Page:表示在磁盘中的数据块。Buff
为什么需要MVCC在并发操作中,当正在写时,如果有用户在读,这时写可能只写了一半,如一行的前半部分刚写入,后半部分还没有写入,这时可能读的用户读取到的数据行的前半部分数据是新的,后半部分数据是原来的,这就导致了数据一致性问题。解决这个问题的最简单的方法是使用读写锁,写的时候不允许读,正在读的时候也不允许写,但这种方法会导致读和写的操作不能并发执行。于是,有人想到了一种能够让读写并发执行的方法,这种
Copyright © 2005-2024 51CTO.COM 版权所有 京ICP证060544号