安装Oracle客户端oracle_fdw插件依赖Oracle客户端的so文件,客户端包需要使用官方地址下载,然后解压。x86: https://www.oracle.com/database/technologies/instant-client/linux-x86-64-downloads.htmlARM: https://www.oracle.com/database/t
检查点在PostgreSQL中的检查点叫全量检查点,执行时会将buffer中的所有的脏页刷到磁盘,需要在一定时间内完成刷脏页的操作,导致数据库运行性能波动较大。同时全量检查点开始时需要遍寻内存中的所有脏页,内存越大,寻找脏页的时间也越长,具体过程如下:遍历所有BUFFER,将当前时刻的所有脏块状态改为CHECKPOINT NEEDED,来表示需要将这些脏块写出磁盘。这一步是在内存中完成的不涉及磁盘
简述Mogdb在1.1.0版本引入动态脱敏(Dynamic Data Masking),通过2个版本的迭代,目前已经日趋完善,该功能通过定制化制定脱敏策略从而实现对隐私数据保护的一种技术,可以有效地不更改业务SQL的前提下,解决非授权用户对敏感信息的访问问题。当管理员指定待脱敏对象(LABEL)和定制数据脱敏策略(POLICY)后,用户所查询的数据库资源如果关联到对应的脱敏策略时,则会根据用户身份
MogDB=# select version(); version ---------------------
pg_trgm是PostgreSQL数据库的一个扩展插件,它提供了文本相似度查询函数和操作符,可以快速搜索相似字符串,并基于这些功能开发文本搜索工具或结合索引加速文本模糊查询。以下是关于pg_trgm的详细介绍:一、pg_trgm的基本概念Trigram(三元组):pg_trgm插件引入了Trigram概念,即从一个字符串中取出的由三个连续字符组成的文本组。对于长度小于3的字符串,pg_trgm会
概念描述pg_prewarm 是一个辅助数据库在重启后预热重启前的数据,防止在重启后,数据库内存中并没有数据进行数据预读,这样的情况下,系统在第一次査询数据的时候后会比较慢,等待数据LOAD 仅内存中。pg_prewarm 模块提供了一种方便的方式将关系数据加载到操作系统缓冲区缓存或 PostgreSQL 缓冲区缓存中。预热可以使用 pg_prewarm 函数手动执行,也可以通过在 shared_
PostgreSQL常用系统信息查询命令1.查看当前数据库实例的版本select version();2.查看数据库的启动时间,命令如下: select pg_postmaster_start_time(); 3.显示当前数据库时区,命令如下: 注意,有时数据库的时区不是当前操作系统的时区,这时在数据库中看到的时间就与操 作系统中看到的时间不一样,如下:&
PostgreSQL体系结构本地内存本地内存是服务器进程独占的内存结构,每个postgresql子进程都会分配一小块相应内存空间,随着连接会话的增加而增加,它不属于实例的一部分work_mem:用于排序的内存maintenance_work_mem:用于内部运维工作的内存,如VACUUM垃圾回收、创建和重建索引等等temp_buffers:用于存储临时表的数据共享内存Shared Buffer:-
当我们在使用PostgreSQL数据库的时候,就算我们不新赋予Superuser权限给用户,默认,也会存在一个跟系统初始化用户同名的Superuser,这个Superuser的存在其实对于权限的管控是很有用的,但是如果我们误操作,把数据库所有的superuser都变成普通账号后,可能会引起很多问题。如下,为找回Superuser权限的步骤,供参考。一、误操作模拟[xmaster@mogdb-ker
适用范围本文档适用于在 CentOS/RHEL 7.X 环境下安装部署 PostgreSQL 14.X 的 pg_auto_failover 高可用环境。方案概述一、总体概述1.1、pg_auto_failover 的简单介绍1.1.1、pg_auto_failover 的参考资料软件下载地址:https://github.com/citusdata/pg_auto_failover/releas
/*+ set(enable_nestloop off) set(enable_index_nestloop off) */关闭嵌套查询,走hash/*+ use_cplan */常量和绑定变量执行计划一致Custom Plan和Generic Plan选择的Hint语法格式:指定使用Custom Plan: use_cplan 指定使用Generic Plan: use_gplan示例://强
SQL1 耗时200Sexplain (analyse, buffers, costs,timing ) delete from t_test_del a where a.ctid <> (select min(t.ctid) from t_test_del t where a.aid=t.aid);业务表中有大量重复数据, 需要对重复数据删除。重复的数据保留一条Delete on t
适用范围postgresql on linuxLinux 内核提供了各种可能影响性能的配置选项,为了获得最佳性能,PostgreSQL 数据库取决于正确定义的操作系统参数。操作系统内核参数配置不当可能会导致数据库服务器性能下降与系统稳定。因此,必须根据数据库服务器及其工作负载配置这些参数。就像任何其他数据库一样,PostgreSQL依赖于Linux内核进行最佳配置。在这篇文章中,我们将讨论一些可能
Q.PostgreSQL里recovery模式和standby模式有什么区别?问题描述PostgreSQL里经常能看到recovery模式和standby模式,这两种模式有什么区别呢?问题解答recovery模式是一种恢复应用WAL的过程状态,standby模式是主从架构下的一种只读模式,可以提供查询。Q.PostgreSQL里是否可以单独做归档备份?问题描述PostgreSQL备份数据除了使用p
Q1.数据库升级到PG 14之后,为什么很多应用软件连接失败?问题描述已经遇到过几次客户反馈PG数据库连接失败的问题,为什么只有升级到14,而其他版本没有出现呢?问题解答如果我们有关注14的新特性变化可以知道SCRAM-SHA-256现在已经是客户端认证的默认方式了,在此之前一直是MD5。其实从PG 10开始就已经支持SCRAM-SHA-256,只不过默认方式还是MD5,并且伴随PG 10的发布,
问题概述现场实施发来求救,简单查询数据表报错, 业务应用出现异常select * from middXXXXX.t_geo_mv_xxxxxegment_var; ERROR: missing chuunk number 0 for toast value 142340922 in pg_toast_2619问题原因此报错信息一般为数据库中有坏块导致 。https://www.pos
问题概述应用在做查询操作时报错ERROR: invalid memory alloc request size 18446744073709551613问题原因数据中有物理坏块解决方案删除损坏的行1.创建扩展create extension hstore;2.创建functionCREATE OR REPLACE FUNCTION find_bad_row(tableName TEXT)
在 PostgreSQL 数据库,统计信息可以大致分为两种。一种是通常意义上规划器用于生成执行计划的关于数据分布的统计信息,还有一种是跟踪服务进程的统计信息一、数据分布统计信息1、什么是数据分布统计信息?与每张表的数据分布有关,是一种描述数据分布的统计数据。规划器使用的统计信息有两种:单列统计信息比较常见的,可以从pg_statistic表中查看某张表单个字段的统计信息扩展统计信息analyze只
一、pg_statistic的toast表数据损坏问题现象在安装插件的时候使用\dx元命令的时候,突然发现报了一个错误:postgres=# \dx ERROR: missing chunk number 0 for toast value 32789 in pg_toast_2619根据提示来看,主表字段还留存着Toast Pointer,但Toast表中已经没有对应的Chunk条目,怀疑to
一、基础概念1、归档作用 归档,它不仅可以用于大型数据库的增量备份和恢复,也可以用于搭建standby镜像备份。 PostgreSQL默认处于非归档模式。开启归档模式,主要涉及到三个参数:wal_level,archive_mode和archive_command。 wal_level参数默认为mininal,设置此参数
1. 概述SQL执行计划是一个节点树,显示MogDB执行一条SQL语句时执行的详细步骤。每一个步骤为一个数据库运算符。执行计划对于我们进行SQL调优可以说是必不可少的关键信息。以下是总结的关于如何查看mogdb数据库当前、历史执行SQL的执行计划以及定位执行缓慢算子的方法。首先介绍MogDB与SQL密切相关的两个特性:ASP和全量SQL&慢查询。2. ASP2.1 特性简介ASP(Acti
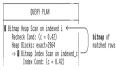
1、背景PostgreSQL中扫描的方式有:Sequence Scan:顺序扫描(全表扫描)。按顺序扫描所有页面Index Scan:根据索引列创建的索引进行扫描,速度快Index only Scan:SELECT 表的目标列都在索引键中,为了减少 I/O,仅索引扫描会直接使用索引中的键值索引扫描在读取表的非索引键的数据时,按照以下顺序:从索引页面获取TID->从heap中取数据->从
概念描述PostgreSQL中的SERIAL是一种特殊的类型,用于创建自增长的整数列,通常用作表的主键或其他需要唯一标识的列。SERIAL实际上不是真正的类型,而是一种便捷的写法,它会自动创建一个SEQUENCE对象,并将该SEQUENCE的下一个值作为该列的默认值。PostgreSQL SERIAL是一种特殊的用于生产整数序列数据库对象serial通常用于主键列,与mysql的AUTO_INCR
测试环境 IPVIPOSDB主库168.3.1.212168.3.1.214rhel7.6KingbaseES V008R006C007B0012备库1168.3.1.213168.3.1.214rhel7.6KingbaseES V008R006C007B0012备库2168.3.1.215168.3.1.214rhel7.6KingbaseES V008R006C007B0012测试
测试环境 IPVIPOSDB主库168.3.1.212168.3.1.214rhel7.6KingbaseES V008R006C007B0012备库168.3.1.213168.3.1.214rhel7.6KingbaseES V008R006C007B0012SWITCH_OVERswitch_over指人为的计划性的切换.1.确认节点信息node1是主库,node2是备库.2.确认
测试环境 IPVIPOSDB主库168.3.1.212168.3.1.214rhel7.6KingbaseES V008R006C007B0012备库168.3.1.213168.3.1.214rhel7.6KingbaseES V008R006C007B0012测试记录1.操作系统配置该步骤主库和备库都必须执行.systemctl stop firewalld systemct
地址系统版本架构168.3.1.212rhel7.6v8.6单实例测试步骤关闭防火墙和selinuxsystemctl stop firewalld systemctl disable firewalld sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config修改系统内核cat >> /etc/sys
确定主从库方法一ps -ef|grep "wal" |grep -v "grep如果输出wal sender…streaming 进程说明当前数据库为主库如果输出wal receiverstreaing 进程说明当前数据库为备用库方法二select * from pg_stat_replication;在主库上查询pg_stat_replication视图,如果返回记录说明是主库,备库上查询此视图
创建新的表空间数据库版本 pg12主机上创建表空间需要的目录[postgres@db1 ~]$ cd /app/pg/tbs_test [postgres@db1 ~]$ mkdir tbs_test使用root用户登录数据库,创建表空间并授权给u1用户使用mydb=# create tablespace tbs_test location '/app/pg/tbs_test'; CREATE T
通常来说,优化器分为两种,一种是CBO,即Cost-BasedOptimizer 的缩写,直译过来就是“ 基于成本的优化器”。一种是RBO,是Rule-BasedOptimizer 的缩写,直译过来就是“基于规则的优化器”在得到最终的执行计划时,RBO会根据一组内置的规则,去选择执行计划,这就导致了RBO选择的执行计划可能不是最优的,不是执行时间最短的,因为他只根据对应的规则去选取执行计划。而CB
Copyright © 2005-2024 51CTO.COM 版权所有 京ICP证060544号