CH01 统计学方法概论前言章节目录统计学习监督学习基本概念问题的形式化统计学习三要素模型策略算法模型评估与模型选择训练误差与测试误差过拟合与模型选择正则化与交叉验证正则化交叉验证泛化能力泛化误差泛化误差上界生成模型与判别模型分类问题标注问题回归问题导读直接看目录结构,会感觉有点乱,就层级结构来讲感觉并不整齐。可以看本章概要部分,摘录几点,希望对本章内容编排的理解有帮助:1. 统计学习三要素对理解
转载
2024-01-16 06:31:54
43阅读

实际上这里从线性可分支持向量机到线性支持向量机再到非线性支持向量机,就是从特殊到一般的过程.
这里介绍了函数间隔和几何间隔,这里前面乘以y的目的就是为了保证得到的值为正;注意定义中是间隔还是间隔的最小值;先引入函数间隔,然后为了规范化又引入了几何间隔(这里我感觉类似于向量中的单位向量,即用向量除以模长).
关于间隔最大化,网上看到篇博客是这么描述的:到样本中最近的点最远,感觉很形象;网上还有个证
# 统计学习方法中的Python实现
在现代的数据科学和机器学习中,统计学习方法已经成为了一个重要的研究领域。李航的《统计学习方法》一书提供了许多经典的统计学习算法,并且在实践中用Python实现这些算法是非常有趣和有意义的。本文将介绍一些基础的统计学习方法及其Python实现,并附上相应的类图和序列图,帮助读者更好地理解这些算法。
## 1. 什么是统计学习
统计学习主要研究如何利用数据对
一 EM算法引入EM算法是一种用于含有隐变量的概率模型参数的极大似然估计。 它分为两步进行: 第一步E步,求期望。第二步M步,求极大。 所以也被称为期望极大算法。看了上面的描述可能会有疑问,什么叫做含有隐变量的概率模型参数的极大似然估计。我们首先说一下什么叫做似然函数和极大似然估计:在数理统计学中,似然函数是一种关于统计模型中的参数的函数,表示模型中参数的似然性,似然性类似于概率,指某种事件发生的
# 机器学习方法 李航 PDF 简介
## 一、引言
随着人工智能的发展,机器学习作为一种重要的技术手段,受到越来越多的关注。而李航的《统计学习方法》(PDF版)是一本经典的机器学习教材,被广泛应用于教学和实践中。本文将介绍该书的主要内容,并结合代码示例进行解释,帮助读者更好地理解机器学习方法。
## 二、主要内容
《统计学习方法》一书介绍了统计学习的基本概念、方法和应用。其中包括监督学习
原创
2024-03-11 03:57:32
1894阅读
# 李航 前馈神经网络模型
## 引言
前馈神经网络(Feedforward Neural Network)是一种受到生物神经网络启发而设计的人工神经网络模型。它是一种最常见的神经网络模型,也是深度学习的基础。本文将介绍前馈神经网络模型的基本原理和代码示例。
## 前馈神经网络模型
前馈神经网络模型是一种有向无环图(Directed Acyclic Graph)模型,它由输入层、隐藏层和输
原创
2023-09-27 17:04:51
28阅读
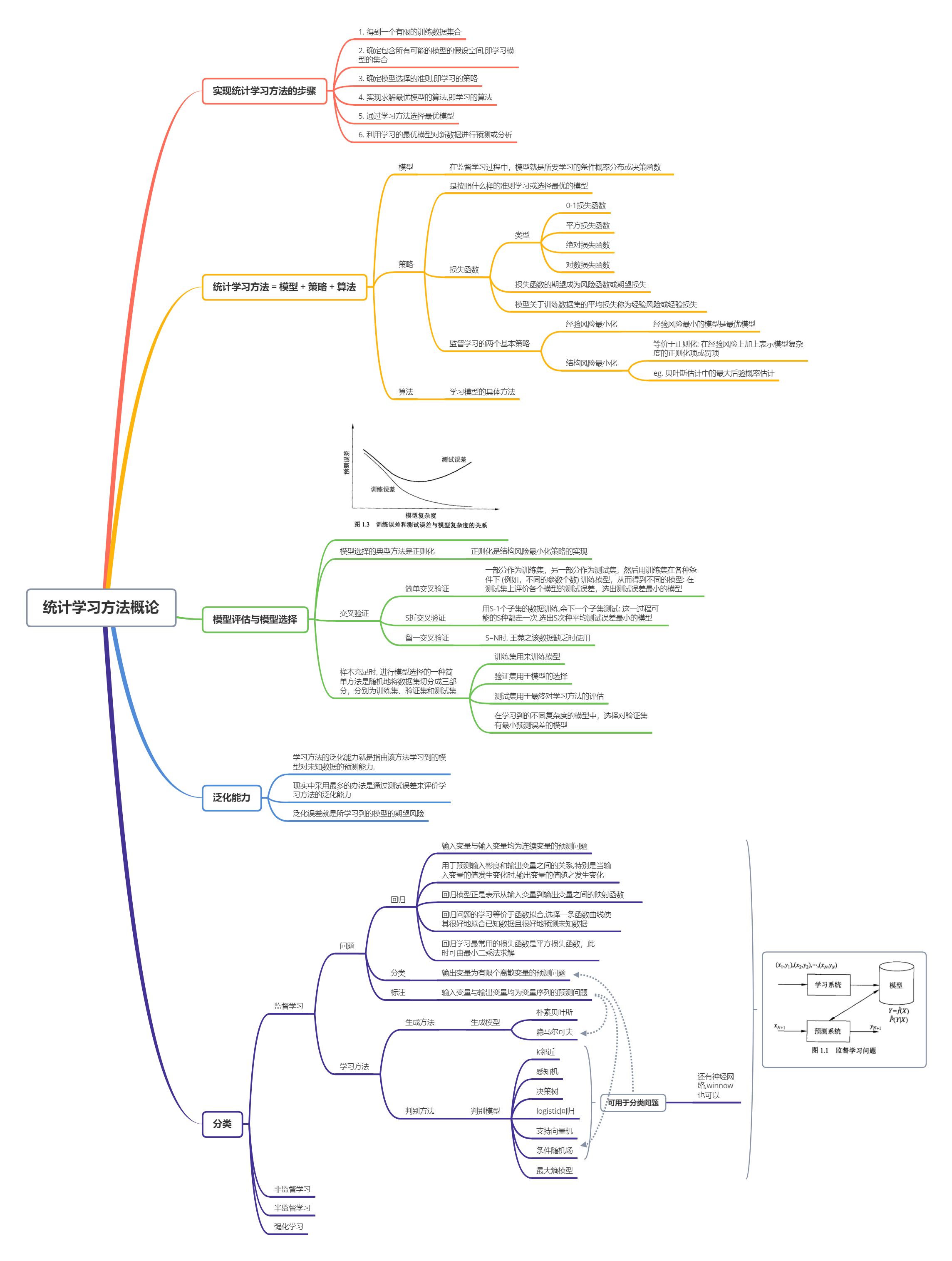
文章目录统计学习方法概论监督学习知识点统计学习方法概论统计学习方法三要素:模型、策略和算法统计学习的目的:统计学习用于对数据进行预测与分析,特别是对未知算机的某些性能得到所数据进行预测与分析.对数据的预测可以使计算机更加智能化,或者说使计高:对数据的分析可以让人们获取新的知识
原创
2021-07-19 15:07:21
877阅读
P大一个小孩,就学会了要求大人做这做那。看着不懂事的他,忽然想到了自己以前会不会也是这个样子呢?加入以后自己的小孩也是这样的话自己又该怎样来教育呢?
今天这小子老爱哭,要吃什么东西非要吃到了才甘心,明明自己做不了的事却总不要别人去碰,要自己弄却又怎么弄也弄不开,然后就是发脾气的哭。
我完全想不到一个几岁大的小娃娃会有这么怪的脾气,看着他无理的行为,霸道的哭声,我真想冲上去给他几下,但他毕竟是小
原创
2008-09-08 17:28:52
474阅读
作者:李航,《统计学习方法》 编辑:Datawhale本文阐述李航老师对 LLM 的一些看法,主要观点如下:ChatGPT 的突破主要在于规模带来的质变和模型调教方式的发明。LLM 融合了实现人工智能的三条路径。LLM 的开发需要结合第三者体验和第一者体验。LLM 能近似生成心智语言。LLM 需要与多模态大模型结合,以产生对世界的认识。LLM 本身不具备逻辑推理能力,需要在其基础上增加推理能力。1
转载
2023-10-23 16:29:00
0阅读
李航老师的《统计学习方法》第一版于 2012年出版,讲述了统计机器学习方法,主要是一些常用的监督学习方法。第二版增加了一些常用的无监督学习方法,由此本书涵盖了传统统计机器学习方法的主要内容。前段日子,李航老师在微博上公布了新作《机器学习方法》,现在上市了!《统计学习方法》目录:《机器学习方法》新增部分内容:第23章 前馈神经网络第24章 卷积神经网络第25章 循环神经网络第26章 序列到序列模型第
转载
2022-12-12 12:56:33
371阅读
感知机/k近邻/贝叶斯/决策树 前言:有时候公式实在不好理解的时候可以看一道例题理解,或者运行程序debug调试逐步看输入输出变化进行理解!统计学习方法pdf链接:https://pan.baidu.com/s/1qLxkiRQZlHIgBJoydMEAew 提取码:tu1b第二章感知机感知机概念输入到输出空间的映射:f(x) =sign(w*x+b) sign函数如下: 感知器是一种线性分类器模
KNN简介来自百度百科 以及 mlapp 邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。 kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法
转载
2023-12-06 16:07:33
63阅读
机器学习的定义是:通过对大量的数据分析 ,来生成 一个模型 (或者一个函数 ,通过对大量的数据求出**F(x)**的过程),利用模型来预测结果解决问题库,通过预测的结果来调整 模型, 是一个循环的过程。 这个过程其实有点像学生的学习,学生通过做某一类题来训练自己解决这一类问题的模型,然后利用解题模型来解决问题,有问题的结果来调整自己的解决问题的模型。机器学习分为有监督与无监督的学习 有监督的学习是
转载
2024-06-29 08:01:57
40阅读
(一)作业题目: 原生python实现knn分类算法(使用鸢尾花数据集) K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依
转载
2023-12-27 17:37:59
43阅读
一.KNN简介 1.KNN算法也称为K邻近算法,是数据挖掘分类技术之一。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。 2.KNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 K
转载
2023-06-27 10:36:12
135阅读
二、Python实现 对于机器学习而已,Python需要额外安装三件宝,分别是Numpy,scipy和Matplotlib。前两者用于数值计算,后者用于画图。安装很简单,直接到各自的官网下载回来安装即可。安装程序会自动搜索我们的python版本和目录,然后安装到python支持的搜索路径下。反正就python和这三个插件都默认安装就没问题了。&n
转载
2023-06-29 23:22:10
176阅读
0 SVM的原理? 支持向量机的基本模型是定义在特征空间上间隔最大的线性分类器,间隔最大化使得它有别于感知机。它是一种二分类模型,当采用核技巧之后,支持向量机可以用于非线性分类。 1 线性可分支持向量机(硬间隔支持向量机):当训练数据线性可分时,通过硬间隔最大化,学得一个线性可分支持向量机; 2 线性支持向量机(软间隔支持向量机):当训练数据近似线性可分时,通过软间隔最大化,学得
 ...
转载
2021-09-14 13:19:00
400阅读
2评论
计算机与网络已融入到了人们的日常学习、工作和生活之中,成为人们不可或缺的助
手和伙伴。计算机与网络的飞速发展完全改变了人们的学习、工作和生活方式。智能化是
计算机研究与开发的一个主要目标。近几十年来的实践表明,统计机器学习方法是实现这
一目标的最有效手段,尽管它还存在着一定的局限性。
作者一直从事利用统计学习方法对文本数据进行各种智能性处理的研究,包括自然语
言处理、信息检索、文本数据挖掘。近20
原创
2023-12-28 10:07:47
137阅读
9.1 复杂数据的局部性建模第3章使用决策树来进行分类。决策树不断将数据切分成小数据集,直到所有目标变量完全相 同 ,或者数据不能再切分为止。决策树是一种贪心算法,它要在给定时间内做出最佳选择,但并不关心能否达到全局最优。树回归优点:可以对复杂和非线性的数据建模。 缺点:结果不易理解。 适用数据类型:数值型和标称型数据。第3章使用的树构建算法是ID3。ID3的做法是每次选取当前最佳的特征来分割
转载
2024-08-29 22:08:10
629阅读























