现在日本名古屋工作,51的博客有空会回来看看,有邮件我,我看到会回复mooreyxia@gmail.
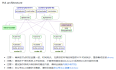
这张图是我写文章做笔记用的概念图。大家要用的话截图下面就可以啦,画起来也不麻烦,重点是里面的内容。
MongoDB概要MongoDB保存的是“JSON Document”,并非一般的PDF,WORD文档MongoDB内部使用类似于Json的bson格式内部执行引擎为JS解释器。把文档存储成bson结构,在查询时转换为JS对象,并可以通过熟悉的js语法来操作MongoDB被称为最像RDBMS 的NoSQL,支持事务,锁,索引类似于MySQLhttp://www.mongodb.com/ http
DNS CDN LVS KeepAlived Haproxy Nginx Tomcat Zookeeper Redis NFS Mysql Zabbix ELK gitlab Jenkins 默认端口以下是常见IT领域中的一些技术术语及其默认端口: DNS: 53 CDN: 80 或 443 端口 LVS: 2100-2122 KeepAlived: 112-114 端口 Haproxy: 80
VxLAN技术演进VxLAN的技术演进二层通信 - 基于目标mac地址通信,不可夸局域网通信,通常是由接入交换机或汇聚交换机实现报文转发。VLAN(Virtual Local Area Network)- 即虚拟局域网,是将一个物理(交换机)的网络在逻辑上划分成多个广播域的通信技术,VLAN内的主机间可以直接通信,而VLAN网络外的主机需要通过三层网络设备转发才可以通信,因此一个vlan可以将服务
关于ELK的使用,请参考《日志分析系统ELK》专题博客,本章只在梳理实际生产中如何利用ELK对kubernetes进行日志采集,请大家知晓日志收集意义及流程日志收集意义分布式日志数据统一收集,实现集中式查询和管理日志查询,问题排查,故障恢复,故障自愈安全信息和事件管理性能分析,用户行为分析报表统计及展示功能日志收集流程容器内日志存储路径#containerd [root@K8s-master01
Kubernetes HPA控制器实现pod的弹性伸缩Pod伸缩简介根据当前pod的负载,动态调整 pod副本数量,业务高峰期自动扩容pod的副本数以尽快响应pod的请求。在业务低峰期对pod进行缩容,实现降本增效的目的。公有云支持node级别的弹性伸缩。手动调整pod副本数#当前pod副本数1个 [root@K8s-ansible ~]#kubectl get pod -n mooreyxia
前提:基础镜像的构建请参考分层镜像构建并部署业务到Kubernetes集群生产案例基于StatefulSet实现MySql业务容器化案例Pod调度运⾏时,如果应⽤不需要任何稳定的标示、有序的部署、删除和扩展,则应该使⽤⼀组⽆状态副本的控制器StatefulSet来部署应⽤,例如 Deployment 或 ReplicaSet更适合⽆状态服务需求,⽽StatefulSet适合管理所有有状态的服务,⽐
前提:基础镜像的构建请参考分层镜像构建并部署业务到Kubernetes集群生产案例PV/PVC及Redis单机业务容器化架构及部署架构图单机redis迁移至kubernetes步骤构建redis镜像#准备镜像构建文件 [root@K8s-ansible redis]#ls Dockerfile build-command.sh redis-4.0.14.tar.gz redis.conf
在生产环境中业务迁移至Kubernetes环境都需要提前规划机房kubernetes集群部署基本步骤:机房环境搭建 基础服务搭建系统迁移数据库迁移测试及联调使用服务及版本Pod地址规划端口使用统计业务迁移Nginx+Tomcat+NFS实现动静分离实现步骤:Centos 基础环境镜像制作#准备安装包 [root@K8s-ansible centos]#ls Dockerfile build-co
基于nerdctl + buildkitd+containerd构建容器镜像软件部署部署nerdctl#官方源码 https://github.com/containerd/nerdctl #下载并安装nerdctl [root@K8s-ansible containerd-bin]#wget https://github.com/containerd/nerdctl/releases/down
Kubernetes资源对象管理及示例资源对象概念Kubernetes分层架构Kubernetes API遵循RestFull API涉及理念声明式且面向对象表达式规范内置API查询集群内可使用API#注意:不同版本的Kubernetes,API也会发生变化 #查询内置API [root@K8s-ansible ~]#kubectl api-resources NAME
6.4估算活动持续时间(规划)❤❤❤★估算活动持续时间是根据资源估算的结果,估算完成单项活动所需工作时段数 的过程,主要作用是,确定完成每个活动所需花费的时间量。 ★创建WBS→估算活动资源→估算活动持续时间→产生进度基准 ★★负责估算活动持续时间的是熟悉这个活动本质的团队成员。 ★★估算活动持续时间依据的信息包括:工作范围、所需资源类型与技能水平、估 算的资源数量和资源日历。 ★★可能影响持续时
实现在集群内部Pod通过Service进行流量转发逻辑图基于yaml文件创建nginx及tomcat pod创建Nginx pod[root@K8s-ansible nginx-tomcat-case]#cat nginx.yaml kind: Deployment #apiVersion: extensions/v1beta1 apiVersion: apps/v1 metadata: l
Kubectl常用命令[root@K8s-ansible ~]#kubectl api-resources NAME SHORTNAMES APIVERSION NAMESPACED KIND bindings
集群节点伸缩管理添加Masterkubeasz部署的集群每个node上都有一个用nginx作为LB的组件[root@K8s-noded01 ~]#cat /etc/kube-lb/conf/kube-lb.conf user root; worker_processes 1; error_log /etc/kube-lb/logs/error.log warn; events {
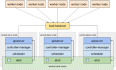
使用kubeasz进行Kubernetes自动化集群部署Kubeasz架构项目地址https://github.com/easzlab/kubeasz https://github.com/easzlab/kubeasz/blob/master/docs/setup/00-planning_and_overall_intro.md项目架构图及部署方式每个Node节点上部署了轻量级Nginx作为代理
主机环境预设#DNS解析 192.168.11.200 K8s-dns.mooreyxia.com DNS01 #镜像仓库 192.168.11.201 K8s-harbor01.mooreyxia.com Harbor01 192.168.11.202 K8s-harbor02.mooreyxia.com Harbor02 #负载均衡器 192.168.11.203 K8s-haproxy01.
前言:我很认同英国科幻作家道格拉斯·亚当斯的科技三定律:1)任何在我出生时已经有的科技都是稀松平常的世界本来秩序的一部分。2)任何在我15-35岁之间诞生的科技都是将会改变世界的革命性产物。3)任何在我35岁之后诞生的科技都是违反自然规律要遭天谴的。这么多年,个人技术有限也因为生存需要,从熟悉企业信息化到新旧技术的浅尝辄止发现都和自己想做的事情相去甚远。去日本工作了5年,也看到一些实验室级别的虚拟
弹性伸缩介绍#官方帮助文档https://help.aliyun.com/document_detail/25857.html使用弹性伸缩(Auto Scaling),可以根据业务需求和策略设置伸缩规则,在业务需求增长时自动增加ECS实例以保证计算能力,在业务需求下降时自动减少ECS实例以节约成本。弹性伸缩不仅适合业务量不断波动的应用程序,同时也适合业务量稳定的应用程序。弹性伸缩的使用流程如下图所
云计算定义:云计算是一种按使用量付费的模式,这种模式提供可用的、便捷的、按需的网络访问, 进入可配置的计算资源共享池(资源包括网络,服务器,存储,应用软件,服务),这些资源能够被快速提供,只需投入很少的管理工作,或与服务供应商进行很少的交互云计算分层:传统IDC:直接在物理机运行服务,不能快速对业务横向扩容。把计算机资源放在云端,提供给用户,又分为三种层次:第一层次,是最底层的硬件资源,主要包括C
Prometheus 简介cadvisor(Container Advisor) 是 Google 开源的一个容器监控工具,它以守护进程方式运行,用于收集、聚合、处理和导出正在运行容器的有关信息。具体来说,该组件对每个容器都会记录其资源隔离参数、历史资源使用情况、完整历史资源使用情况的直方图和网络
案例: 利用 Filebeat 收集 Nginx的 Json 格式访问日志和错误日志到 Elasticsearch 不同的索引默认Nginx的每一次访问生成的访问日志是一行文本,ES没办法直接提取有效信息,不利于后续针对特定信息的分析,可以将Nginx访问日志转换为JSON格式解决这一问题安装 nginx 配置访问日志使用 Json格式#安装Nginx[root@web01 ~]#apt upda
Kibana 图形显示Kibana 是一款开源的数据分析和可视化平台,它是 Elastic Stack 成员之一,设计用于和 Elasticsearch协作,可以使用 Kibana 对 Elasticsearch 索引中的数据进行搜索、查看、交互操作,您可以很方便的利用图表、表格及地图对数据进行多元化的分析和呈现。安装并配置 Kibana注意: Kibana的版本要和 Elasticsearch
Elasticsearch 集群工作原理单机节点 ES 存在单点问题,可以实现Elasticsearch多机的集群ES 节点分类Elasticsearch 集群的每个节点的角色有所不同,但都会保存集群状态Cluster State的相关的数据信息节点信息:每个节点名称和地址索引信息:所有索引的名称,配置,数据等ES的节点有下面几种Master 节点ES集群中只有一个 Master 节点,用于控制和
Elasticsearch单点安装及优化安装前环境初始化CPU 2C内存4G或更多操作系统: Ubuntu20.04,Ubuntu18.04,Rocky8.X,Centos 7.X操作系统盘50G主机名设置规则为nodeX.mooreyxia.org*生产环境建议准备单独的数据磁盘[root@ubuntu2204 ~]#hostnamectl set-hostname es-node1.moore
Copyright © 2005-2024 51CTO.COM 版权所有 京ICP证060544号