sysbench是一款测试工具主要包括以下几种方式的测试:1、cpu性能2、磁盘io性能3、调度程式性能4、内存分配及传输速度5、POSIX线程性能6、数据库性能(OLTP基准测试)现在sysbench主要支持MySQL,pgsql,oracle这3种数据库,默认支持MySQL,想要支持pgsql和oracle需要在编译时指定参数环境介绍名称版本sysbench软件版本sysbench0.5操作系
基于RAC的Gataguard架构主备数据库环境准备主备数据库及其实例配置如图表1-1所示。配置项目Primary端Standby端ClusterwareGrid Infrastructure 21C R2(21.5.0.0.0)Grid Infrastructure 21C R2(21.5.0.0.0)Cluster Nodes21crac1,21crac221crac1,2
本文介绍如何离线部署OceanBase社区版。环境信息:作用主机名IPOSOB目录端口CPU内存磁盘observeroceanbase111.114.0.20Centos 7.5/data/observer[2881,2882]8C16G50Gobserveroceanbase211.114.0.5Centos 7.5/data/observer[2881,2882]8C16G50Gobserve
HBase采用LSM树架构,天生适用于写多读少的应用场景。在真实生产环境中,也正是因为HBase集群出色的写入能力,才能支持当下很多数据激增的业务。需要说明的是,HBase服务端并没有提供update、delete接口,HBase中对数据的更新、删除操作在服务器端也认为是写入操作,不同的是,更新操作会写入一个最新版本数据,删除操作会写入一条标记为deleted的KV数据。所以HBase中更新、删除
1. HBase概述 HBase是目前热门的一款分布式KV(keyValue,键值)数据库系统,无论是互联网行业还是其他传统IT行业都在大量使用。尤其是近几年随着国内大数据理念的普及,HBase凭借其高可靠、易扩展、高性能以及成熟的社区支持,受到越来越多企业的青睐。许多大数据系统都将HBase做为底层数据存储服务,例如KyLin、OpenTSDB等。 2. HBase数据模型 从使用角度来看,HB
HBase Shell及其常用命令 HBase 数据库默认的客户端程序是 HBase Shell,它是一个命令行工具。用户可以使用 HBase Shell,通过命令行的方式与 HBase 进行交互。HBase Shell 是一个封装了 Java 客户端 API 的 JRuby 应用软件,在 HBase 的 HMaster 主机上通过命令行输入 hbase shell,即可进入 HBase 命令行环
> 这是一篇介绍关于Oracle数据库组合索引中列顺序的选择,对于SQL效率执行的影响。 ## 什么是组合索引 在Oracle数据库中创建索引时,可以把多个列创建到同一个索引中。这样就组成了组合索引。创建语句 create index idx_tab on tab_name (col1,col2,...); ## 组合索引适用场景 1. 适用在单独查询返回记录很多,组合查询后忽然返回记录很少的情
背景生产上有套RAC,主机已运行超5年,最近一段时间经常出现物理主机无故宕机的状态,宕机没有规律,而且是两个节点交替宕机,看监控宕机前主机负载也不高,硬件厂商看过也没找出具体原因。于是想把主机换掉,但由于数据量较大将近50T,搭建DataGuard耗时长,还需要double的存储空间,不合适。就想到只把集群相关的LUN映射到新集群中,在新集群中MOUNT磁盘组做迁移。下面是测试环境的基本步骤。前期
MongoDB分片介绍分片(sharding)是MongoDB用来将大型集合分割到不同服务器(或者说一个集群)上所采用的方法。尽管分片起源于关系型数据库分区,但MongoDB分片完全又是另一回事。和MySQL分区方案相比,MongoDB的最大区别在于它几乎能自动完成所有事情,只要告诉MongoDB要分配数据,它就能自动维护数据在不同服务器之间的均衡。分片的目的高数据量和吞吐量的数据库应用会对单机的
背景生产上选用repmgr给PostgreSQL数据库做高可用集群,在给生产上一套库做高可用改造时发现standbyclone时报错,无法复制备库,报错内容如下:原因先说原因,是因为对PG和pg_basebackup比较了解的同学可能自己就可以想出解决方案,不需要再继续往下看了。原因是由于创建的独立表空间指定的目录放在$PGDATA目录下,repmgr的standbyclone调用的是pg_bas
MongoDB集群介绍与搭建--RS篇
mongodb 配置与安装
正所谓“福无双至,祸不单行”,生产上有套2节点Oracle11.2.0.4数据库,其中2节点因硬件故障宕机,1节点去HANG住了。我们一起来分析这起故障。凌晨4点半,值班同时电话说一套生产库节点2宕机了,机房的同事看机器正在启动,估计是硬件原因导致的。心想节点2宕了还有一个节点1在跑,应该问题不大,于是继续睡觉,离公司近的另一位DBA同事赶往现场支持。可是没有过多长时间,到现场的DBA反馈信息:活
问题现象:一套两节点的RAC集群,其中节点2集群无法启动,ohas进程已经启动但CRS、CSS进程未启动1、首先查看查看RAC中的alert日志,发现日志中一直在报如下报错:file rotation terminated. log file: "/app/11.2.0.4/grid/log/uatdb02/client/olsnodes.log"从日志中可以看到提示说olsn
在自己的虚拟机的做实验,突然发现使用PL/SQL Developer无法连接到数据库,报错ORA-12514,说是监听没有启动。先介绍虚拟机一下环境:redhat7.2+GI 12.2.0.1+Oracle 12.2.0.1,为了测试12.2的ASM特性安装了GI。平时监听程序默认是开启启动的。但是今天不知道为什么没有启动。使用crsctl查看资源状态:发现监听的状态确实是OFFLINE状态[ro
今天在看一条应用反应说执行不出来的SQL时,发现数据库中的AWR报告没有自动收集,最近的还停留在9月26日的,查看当前的时间是10月20日,现在有意思了,怎么会这样的,默认的AWR是1个小时收集一次,保留8天(此数据库版本为11.2.0.4)。下面来检查一下AWR的设置情况:SQL> show parameter statistics_level NAME&n
最近在看一些Oracle分享的时候,经常提到导出ASH的dump给另外的人来做分析,但我没有什么相关的操作,不知道是怎样的一个操作流程,于是上网看了各种博文。于是自己动手做实验做一次导出导入。实验环境:Oracle 11.2.0.4+rhel 7.2执行下面的语句对ASH信息做dump操作sys@ORA11G>alter system set events&nb
之前写过一篇关于NULL对in和not in结果的影响:Oracle的where条件in/not in中包含NULL时的处理。今天来看看exists和not exists中NULL值对结果的影响。网上经常看到关于in和exixts、not in和not exists性能比对和互换的例子,但它们真的就可以简单互换么?我们通过下面的实验来看一下。实验环境:Oracle 11.2.0.41、创建表并插入
最近在看python,虚拟机装的是Centos6.6,自带的python版本是2.6.6,打算升级到2.7。我的升级过程大致如下: 下载2.7源码包https://www.python.org/downloads/source/ 卸载旧的python,rpm -e python 编译安装python2.7整个过程没有遇到问题,但升级完后,再用yum安装软件时报
用数据泵impdp往开发数据库导数据,但导入到INDEX时感觉卡住不动了Processing object type SCHEMA_EXPORT/TABLE/INDEX/INDEX ----查看状态,Completed Objects: 33一直没有变化。 Import> status Job: SYS_IMPORT_FU
一、Oracle约束的状态Oracle完整性约束的状态有4种,分别是ENABLE、DISABLE、VALIDATE、NOVALIDATE。ENABLE 表示Oracle将检查要插入或更新的数据库中的数据是否符合约束;DISABLE 表示表中可以存放违反约束的行;VALIDAT
一、物化视图日志是什么oracle 的物化视图的快速刷新要求必须建立物化视图日志,通过物化视图日志可以实现增量刷新功能。官方文档给出的对物化视图日志的释义:A materialized view log is required on a master to perform a fast refresh on materialized views based on the master. When
在Oracle12.2版本之前,如果想把一个非分区表转为分区表常用的有这几种方法:1、建好分区表然后insert into select 把数据插入到分区表中;2、使用在线重定义(DBMS_REDEFINITION)的方法。它们的币是:第一种方法,如果对表有频繁的DML操作,尤其是update操作,就需要停业务来做转换。第二种方法可以在线进行操作,不需要停业务,但操作步骤比较复杂,且可能出错。Or
在Oracle12c版本之前,使用RMAN能恢复的级别为数据库级别和表空间级别,如果只有一张表需要恢复,而在数据库级别或表空间级别做恢复,影响范围就太大了。因此12.2版本中提供了一个新特性使用RMAN在表级别做恢复,并且恢复过程中不影响数据库的正常使用。这一功能不仅可以恢复表,还可以恢复表分区。To recover a table or table partition, you must hav
在Oracle12.1之前的版本中要重命名数据文件或移动数据文件需要关闭数据库或把表空间/数据文件置为offline状态才可以,参考之前总结的Oracle修改数据文件名/移动数据文件。但到了12.1版本,可以直接在数据文件online状态下把数据文件重命名或移动数据文件。要实现这一功能需要使用ALTER DATABASE MOVE DATAFILE 语句,语
Oracle12.2版本之前,对表做move操作时会对表加exclusive锁,表上无法执行DML操作。虽然move操作有ONLINE子句,但只适用于IOT表,不适用于堆表。这就意味着在对表做move操作时,无法执行任何DML操作,如果对关键表做move操作时只能停业务来完成。到了Oracle12.2版本,推出了一个新特性----在线move表,对于普通堆表可以在move过程中执行DML操作。下面
最近两天在虚拟机上搞Oracle 12.2的安装,安装的过程挺顺利的。但虚拟机重启之后就无法连接数据库,执行sqlplus / as sysdba报错ORA-12547: TNS:lost contact为什么呢?安装完后测试都好好的,怎么重启之后会这样呢。在网上找了很多方法来处理: 网上给出的解决思路如下: 1、查看操作系统内核参数是否无误
要了解Oracle数据库的启动和停止需要先了解“实例”(instance)和“数据库”(database)这两个名词的定义:数据库(database):物理操作系统文件或磁盘(disk)的集合。实例(instance):一组Oracle后台进程/线程以及一个共享内存区,这些内存由同一个计算机上运行的线程/进程所共享。这两个词有时可以互换使用,不过二者的概念完全不同。实例和数据库之间的关系是:数据库
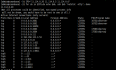
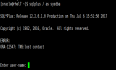
最近生产上的数据库升级到了11.2.0.4当前最新的PATCH——170418,但是在使用sqlplus登录数据库进行操作时,发现与以往登录时不同的地方。打PATCH以前登录时的截图:打PATCH之后 登录时的截图:从截图上直观看到的是登录时的信息没有显示出来,但实际上是所有以前对sqlplus的配置都没有生效。这是什么原因呢。先来看sqlplus启动过程:sqlplus在启动时会自动运行两个脚本
Oracle 11gR2 中,引入了SCAN(Single ClientAccess Name)的特性。SCAN是一个域名,可以解析至少1个IP,最多解析3个SCAN IP,客户端可以通过这个SCAN 名字来访问数据库,另外SCAN ip必须与public ip和VIP在一个子网。在11gR2之前配置TNS连接串使用的都是VIP,如果RAC集群添加节点或VIP有变化,就需要对所有的客户端的TNS配
Copyright © 2005-2024 51CTO.COM 版权所有 京ICP证060544号