
索引分类:
• 逻辑
– 单列或串接:在单列或多列上创建索引,最多包含32列。
– 唯一或非唯一:保证在表中没有两行或以上的键列没有重复值或不限制。
– 基于函数:在建立索引的一列或多列上使用函数或表达式,索引预先计算函数或表达式的值,并将结果存储在索引中。可以创建为B树或位图索引。
– 域:对于特定应用程序的索引。仅支持单列域索引。可以在具有标量、对象或LOB 数据类型的列上建立单列域索引。
• 物理
– 分区或非分区
– B 树
正常或反向键
– 位图
B树索引:
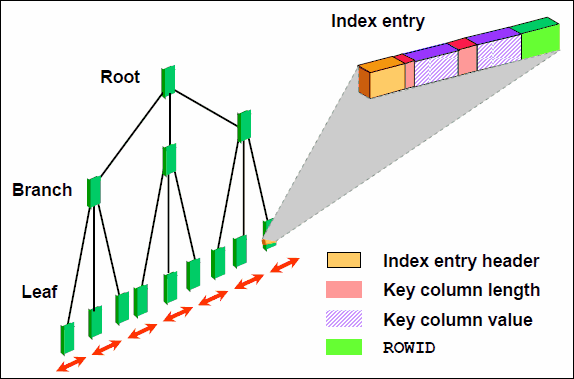
图1
B 树索引的结构:
索引的顶部为根,其中包含指向索引中下一级的项。下一级为分支块,分支块又指向索引中下一级的块。最低一级为叶节点,其中包含指向表行的索引项。叶块为双重链接,有助于按键值的升序和降序扫描索引。如下图:

图2
索引叶项的格式:
索引项由以下部分组成:
• 项标题,存储列数和锁定信息
• 键列的“长度- 值” 对,用于定义键列的大小及该列的值(该值对的数目即索引中的最大列数。)
• 行的行标识,包含键值
索引叶项的特征:
在非分区表上的B 树索引中:
• 如果多行具有相同的键值,除非对索引进行了压缩,否则键值重复。
• 对于所有键列都为NULL 的行,没有对应的索引项。因此,指定NULL 的WHERE 子句始终进行全表扫描。
• 因为所有行都属于同一段,所以使用受限行标识指向表中的行。
DML 操作对索引的影响:
在表上执行DML 操作时,Oracle 服务器将维护所有的索引。下面解释DML 命令对索引的影响:
• 插入操作导致在适当的块中插入索引项。
• 删除行只导致逻辑删除索引项。删除的行所用的空间仍不能用于新项,直到删除块中的所有项。
• 更新键列将导致逻辑删除和向索引插入项。除了创建时以外,PCTFREE 设置在其它任何时候都对索引没有影响。即使索引块空间少于PCTFREE 指定的空间,仍可以向索引块添加新项。
位图索引

图3
在下列情况中,位图索引比B 树索引更有利:
• 当表包含数百万行且键列的基数很低(即,该列中重复的值很多)时。例如,对于包含护照记录的表的性别列和婚姻状况列而言,位图索引比B 树索引更适合
• 当查询经常使用涉及OR 运算符的多个WHERE 条件组合时
• 当键列上存在只读或很少的更新操作时
位图索引的结构:
将位图索引也组织为B 树,但叶节点存储每个键值的位图而非行标识列表。位图中的每一位对应一个可能的行标识,如果设置了位,则意味着具有相应行标识的行包含键值。
如图3所示,位图索引的叶节点包含下列几项:
• 项标题,包含列数和锁定信息
• 键值由每个键列的“长度- 值” 双值组成(本例中,关键字仅包含一列,第一项的键值为Blue)。
• 开始行标识,本例中的开始行标识包含文件号3、块号10 和行号0
• 结束行标识,本例中的结束行标识包含块号12 和行号8
• 位图段,由位串组成(对应的行包含键值时设置位;不包含键值时不设置位。Oracle
服务器使用专利压缩技术存储位图段。)开始行标识是位图的位图段指向的第一行的行标识,即,位图的第一位对应此行标识,位图的第二位对应块中的下一行,而结束行标识是位图段所包含的表中最后一行的指针。位图索引使用受限行标识。
使用位图索引:
B 树用于定位包含给定键值的位图段的叶节点。开始行标识和位图段用于定位包含键值的行。
更改表中的键列时,必须修改位图。这将导致锁定相关的位图段。由于锁是在整个位图段上获取的,所以直到第一个事务处理结束后,才能由其它事务处理更新位图包含的行。

图4
创建索引
CREATE INDEX hr.employees_last_name_idx ON hr.employees(last_name)
PCTFREE 30
STORAGE(INITIAL 200K NEXT 200K PCTINCREASE 0 MAXEXTENTS 50)
TABLESPACE indx;

图5
CREATE [ UNIQUE | BITMAP ] INDEX [ schema. ] index
ON { cluster_index_clause
| table_index_clause
| bitmap_join_index_clause
}
[ UNUSABLE ] ;
索引可在表所有者的帐户下或其它帐户下创建,但索引通常在表所在的同一帐户下创建。
上面的语句在EMPLOYEES 表上创建一个索引(使用LAST_NAME 列)。
语法选项
UNIQUE:用于指定唯一的索引(缺省为Nonunique。)
Schema:索引/表的所有者
Index:索引名
Table:表名
Column:列名
ASC/DESC:指示是按升序还是按降序创建索引
TABLESPACE:指定要在其中创建索引的表空间
PCTFREE:创建索引时为容纳新的索引项而在每块中保留的空间大小(以总空间量减去块
头后的百分比表示)
INITRANS:指定每块中预先分配的事务处理项的数目(缺省值和最小值为2。)
MAXTRANS:限制可以为每个块分配的事务处理项数(缺省值为255。)
STORAGE 子句:标识确定如何为索引分配区的存储子句
LOGGING:指定在重做日志文件中记录索引创建操作和在索引上执行的后续操作(这是缺省值。)
NOLOGGING:指定在重做日志文件中不记录创建操作和某些类型的数据加载操作
NOSORT:指定将行按升序存储在数据库中,这样,Oracle 服务器在创建索引时不必对行进行排序
注:
• 如果已为表空间定义了MINIMUM EXTENT,则索引的区大小将向上舍入为下一个更高的MINIMUM EXTENT 值的倍数。
• 如果省略了[NO]LOGGING 子句,索引的事件记录属性将缺省为表所驻留的表空间的事件记录属性。
• 不能为索引指定PCTUSED。由于索引项必须按正确的顺序存储,所以用户无法控制何时在某一索引块中插入。
• 如果在数据未按关键字排序的情况下使用NOSORT 关键字,语句将终止并显示错误。如果表上已经有多个DML 操作,则该选项很可能无效。
• 如果可能,Oracle 服务器使用现有索引创建新的索引。当新索引的关键字与现有索引键的主要部分对应时,就会发生这种情况。
创建索引原则
创建索引时应考虑:
• 索引能够提高查询性能并降低DML 操作速度。始终使易失表所需的索引数保持最少。
• 将索引放在一个单独的表空间中,不要放在有还原段、临时段和表的表空间中。
• 使用统一的区大小:块数是5 的倍数或对表空间使用MINIMUM EXTENT 大小
• 对大型索引而言,避免生成重做日志可显著提高性能。请考虑使用NOLOGGING 子句
创建大型索引。
• 由于索引项比索引行小,所以索引块趋向于在每块中包含更多的项。因此,
INITRANS 在索引中通常比在对应的表中高。
索引和PCTFREE:
索引的PCTFREE 参数与表的PCTFREE 参数工作方式不同。前者仅在创建索引时用来为需要插入到同一索引块的索引项保留空间。而不更新索引项。更新键列时,这将涉及逻辑删除索引项和插入。
在单调递增(如系统生成的发票号)列的索引上使用较低的PCTFREE 值。在这些情况下,新的索引项总是追加到现有项上,没有必要在两个现有索引项间插入一个新项。
如果插入行的索引列值可采用任何值(即新值在当前的值范围内),则应该提供较高的PCTFREE。发票表的客户代码列上的索引就是一个要求高PCTFREE 值的索引。在这种情况下,将PCTFREE 值指定为由下列等式所表示的值是非常有用的:
最大行数– 初始行数x 100
最大行数
最大值可用于特定的时间周期,如一年。
创建位图索引
CREATE BITMAP INDEX orders_region_id_idx ON orders(region_id)
PCTFREE 30 STORAGE(INITIAL 200K NEXT 200K PCTINCREASE 0 MAXEXTENTS 50)
TABLESPACE indx;
语法:
使用下列命令创建位图索引:
CREATE BITMAP INDEX [schema.] index
ON [schema.] table
(column [ ASC | DESC ] [ , column [ASC | DESC ] ] ...)
[ TABLESPACE tablespace ]
[ PCTFREE integer ]
[ INITRANS integer ]
[ MAXTRANS integer ]
[ storage-clause ]
[ LOGGING| NOLOGGING ]
[ NOSORT ]
注意,位图索引不能是唯一的(unique)。
初始化参数CREATE_BITMAP_AREA_SIZE 决定了内存中用于存储位图段的空间量。缺省值为8
MB。使用较大的值,可提高索引创建的速度。如果基数很小,可将该值设置为一个较小值。例如,如果基数仅为2,则该值可以为千字节数量级而非兆字节数量
级。一般来讲,基数越大,则获取最佳性能所需的内存越多。
更改索引的存储参数
某些存储参数和块使用参数可通过ALTER INDEX 命令进行修改。
语法:
ALTER INDEX [schema.]index
[ storage-clause ]
[ INITRANS integer ]
[ MAXTRANS integer ]
更改索引存储参数与更改表存储参数的含义一样。通常,进行此类更改是为了增加索引的MAXEXTENTS。可更改块使用参数以保证在索引块上实现更高级别的并发性。
分配和回收索引空间
手动分配索引空间:
在表上进行频繁的插入操作前,可能需要向索引添加区。添加区可防止索引动态扩展并导致性能降低。
从索引中手动回收空间:
使用ALTER INDEX 命令的DEALLOCATE 子句释放索引中超过高水位标记的未用空间。
语法:
使用下列命令分配或回收索引空间:
ALTER INDEX [schema.]index
{ALLOCATE EXTENT ([SIZE integer [K|M]]
[ DATAFILE ‘filename’ ])
| DEALLOCATE UNUSED [KEEP integer [ K|M ] ] }
手动分配和手动回收索引空间所遵循的规则与在表上使用这些命令时相同。
注:当建立索引的表被截断时,回收索引空间。截断表将导致截断关联的索引。
离线重建索引
ALTER INDEX orders_region_id_idx REBUILD TABLESPACE indx02;
Oracle操作步骤:
1、锁定表。
2、创建一个新的,临时的索引,从原索引读取信息。
3、删除原索引。
4、重命名临时索引为原索引。
5、解除表锁定。
索引重建具有以下特点:
• 将现有索引作为数据源建立新索引。
• 使用现有索引建立索引时无需排序,从而使性能更佳。
• 在建立新索引后,删除旧索引。在重建期间,各自的表空间内需要有足够的空间以容
纳新旧索引。
• 结果索引不包括任何已删除的项。因此,该索引可以更有效地使用空间。
• 在建立新索引的过程中,查询可继续使用现有索引。
可能的重建情况:
在下列情况下应重建索引:
• 需要将现有索引移到另外的表空间中。如果索引和表在同一表空间中或者需要跨磁盘重新分布对象时,可能需要执行此操作。
• 索引中包含很多已删除的项。这是滑动索引(如订单表中的订单号上的索引)存在的典型问题,完成的订单已被删除,并将具有更高订单号的新订单添加到表中。如果有几个旧订单未完成,则可能有若干个索引叶块包含除几个已删除项之外的全部项。
• 需要将现有正常索引转换成反向键索引。在从Oracle 服务器的早期发行版移植应用程序时,可能会出现这种情况。
• 已通过ALTER TABLE..MOVE TABLESPACE 命令将索引表移至其它表空间。
语法:
使用下列命令重建索引:
ALTER INDEX [schema.] index REBUILD
[ TABLESPACE tablespace ]
[ PCTFREE integer ]
[ INITRANS integer ]
[ MAXTRANS integer ]
[ storage-clause ]
[ LOGGING| NOLOGGING ]
[ REVERSE | NOREVERSE ]
ALTER INDEX ...REBUILD 命令不能用于将位图索引更改为B 树索引,反之亦然。只能为B 树索引指定REVERSE 或NOREVERSE 关键字。
联机重建索引
过程:

图6
建立或重建索引是一项费时的任务,尤其当表非常大时更是如此。在Oracle8i 之前,建立或重建索引都需要锁定表,并要防止并发的DML 操作。Oracle9i 允许在基表上进行并发操作的同时建立或重建索引,但不建议在此过程中执行大量的DML 操作。
注:仍存在DML 锁,这意味着在联机索引建立期间不能执行其它DDL 操作。
限制:
• 不能在临时表中重建索引
• 不能重建整个分区索引。必须分别重建每个分区或子分区。
• 也不能回收未用空间。
• 不能整个更改索引的PCTFREE 参数值。
合并索引

图7
1、扫描叶子节点。
2、把能合并成一个块的合并。
遇到索引碎片时,可以重建或合并索引。执行上述任务前,应考虑每种选择的成本和好处,然后选择最适合自己情况的方案。索引合并是联机完成的块重建过程。
如果有可以释放以供重用的B 树索引叶块,则可使用下列SQL 语句合并这些叶块:
SQL> ALTER INDEX hr.employees_idx COALESCE;
图5显示了ALTER INDEX … COALESCE 语句对索引hr.employees_idx 的影响。
检查索引及其有效性
分析索引以执行以下操作:
• 检查所有的索引块是否存在损坏。注意,此命令并不验证索引项是否与表中的数据对应。
• 将检查结果返回给INDEX_STATS 视图。
语法:
ANALYZE INDEX [ schema.]index VALIDATE STRUCTURE
运行此命令后,查询INDEX_STATS 以获取索引的有关信息,如下例所示:
SQL> SELECT blocks, pct_used, distinct_keys,
2 lf_rows, del_lf_rows
3 FROM index_stats;
BLOCKS PCT_USED LF_ROWS DEL_LF_ROWS
------ --------- -------- ------------
25 11 14 0
1 row selected.
如果索引中已删除行的比例很高,请重新组织该索引。例如:当DEL_LF_ROWS 占
LF_ROWS 的比率超过30% 时。
实验:
SQL> select * from t;
ID NAME
---------- --------------------
0 aaa
1 aaa
3 aaa
4 aaa
5 aaa
6 aaa
7 aaa
8 aaa
9 aaa
2 aaa
已选择10行。
SQL> analyze index t_id_idx validate structure;
索引已分析
SQL> select height,blocks,lf_rows,del_lf_rows from index_stats;
HEIGHT BLOCKS LF_ROWS DEL_LF_ROWS
---------- ---------- ---------- -----------
1 8 10 0
SQL> delete from t where id=4;
已删除 1 行。
SQL> commit;
提交完成。
SQL> analyze index t_id_idx validate structure;
索引已分析
SQL> select height,blocks,lf_rows,del_lf_rows from index_stats;
HEIGHT BLOCKS LF_ROWS DEL_LF_ROWS
---------- ---------- ---------- -----------
1 8 10 1
SQL> alter index t_id_idx rebuild;
索引已更改。
SQL> select height,blocks,lf_rows,del_lf_rows from index_stats;
未选定行
SQL> analyze index t_id_idx validate structure;
索引已分析
SQL> select height,blocks,lf_rows,del_lf_rows from index_stats;
HEIGHT BLOCKS LF_ROWS DEL_LF_ROWS
---------- ---------- ---------- -----------
1 8 9 0
SQL> delete from t where id=9;
已删除 1 行。
SQL> analyze index t_id_idx validate structure;
索引已分析
SQL> select height,blocks,lf_rows,del_lf_rows from index_stats;
HEIGHT BLOCKS LF_ROWS DEL_LF_ROWS
---------- ---------- ---------- -----------
1 8 9 1
SQL> alter index t_id_idx coalesce;
索引已更改。
SQL> analyze index t_id_idx validate structure;
索引已分析
SQL> select height,blocks,lf_rows,del_lf_rows from index_stats;
HEIGHT BLOCKS LF_ROWS DEL_LF_ROWS
---------- ---------- ---------- -----------
1 8 9 1
删除索引:
DROP INDEX hr.deptartments_name_idx;
•在批量载入数据前可以先删除索引,载入完成再创建。
•删除不常用的索引,需要时再创建。
•删除并重新创建无效索引(注意:删除再建比重建索引效率低)。
• 当在某种类型的操作(如加载)期间出现例程失败时,可能会将索引标记为INVALID。在这种情况下,需要删除并重建索引。
注意:除约束所需的索引,因此,必须先禁用或删除相关的约束。
监视索引(用于标识未使用索引):
• 要开始监视索引的使用,执行以下语句:
ALTER INDEX hr.dept_id_idx MONITORING USAGE
• 要停止监视索引的使用,执行以下语句:
ALTER INDEX hr.dept_id_idx NOMONITORING USAGE
实验:
SQL> select * from v$object_usage;
未选定行
SQL> alter index t_id_idx monitoring usage;
索引已更改。
SQL> set lines 300
SQL> col index_name format a20
SQL> col start_monitoring format a15
SQL> col end_monitoring format a15
SQL> select * from v$object_usage;
INDEX_NAME TABLE MONITO USED START_MONITORIN END_MONITORING
-------------------- ----- ------ ------ --------------- ---------------
T_ID_IDX T YES NO 04/09/2010 01:43:52
SQL> set autot on exp
SQL> select * from t where id=5;
ID NAME
---------- --------------------
5 aaa
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE
1 0 TABLE ACCESS (BY INDEX ROWID) OF 'T'
2 1 INDEX (RANGE SCAN) OF 'T_ID_IDX' (NON-UNIQUE)
SQL> select * from v$object_usage;
INDEX_NAME TABLE MONITO USED START_MONITORIN END_MONITORING
-------------------- ----- ------ ------ --------------- ---------------
T_ID_IDX T YES YES 04/09/2010 01:43:52
SQL> select * from t;
ID NAME
---------- --------------------
0 aaa
1 aaa
3 aaa
5 aaa
6 aaa
7 aaa
8 aaa
2 aaa
已选择8行。
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE
1 0 TABLE ACCESS (FULL) OF 'T'
#全表扫描时不会用到索引。
SQL> alter index t_id_idx nomonitoring usage;
索引已更改。
SQL> select * from v$object_usage;
INDEX_NAME TABLE MONITO USED START_MONITORIN END_MONITORING
-------------------- ----- ------ ------ --------------- ---------------
T_ID_IDX T NO YES 04/09/2010 01:43:52 04/09/2010 01:58:25
有用视图:
• DBA_INDEXES:提供有关索引的信息
• DBA_IND_COLUMNS:提供有关索引列的信息
• V$OBJECT_USAGE:提供有关索引使用情况的信息
本文出自 “冰冷的太阳” 博客,请务必保留此出处http://luotaoyang.blog.51cto.com/545649/293088




















