
数据加载方式:

图1
•SQL*loader
•直接加载:直接加载插入可用于在同一数据库中从一个表向另一个表复制数据。此方法绕过数据库缓冲区高速缓存直接将数据写入数据文件,从而加快了插入操作的速度。
直接加载
直接加载插入(串行或并行)只能支持INSERT 语句的INSERT ... SELECT 语法而无法支持其INSERT ... Values 语法。INSERT ... SELECT 的并行性是由并行提示或并行表定义决定的。Oracle9i 提供了语法扩展,扩大了INSERT ... SELECT语句的使用范围。结果,可以将行插入到多个表中(作为单个DML 语句的一部分)。
可使用APPEND 提示调用直接加载插入,如以下的命令所示:
INSERT /*+APPEND */ INTO [ schema. ] table
[ [NO]LOGGING ] #该选项无效。
sub-query;
其中:
schema:表的所有者
table:表名
sub-query:用于选择所要插入的列和行的子查询
LOGGING 模式:
如果使用LOGGING 选项(缺省设置)进行插入,该操作将生成重做日志条目,从而使得从失败中完全恢复成为可能。如果使用NOLOGGING 选项,则不会将对数据所做的更改记入重做日志缓冲区中。但对于更新数据字典的操作,仍进行最小限度的记录。如果已为表
设置NOLOGGING 属性,则将使用NOLOGGING 模式。如果表空间为force logging模式则插入时为log模式。
如果接下来可能对表数据进行多次联机修改,则最好在加载前设置NOLOGGING 属性,并在完成加载后再将表的属性重置为LOGGING。
注:
通过直接加载插入而加载的所有数据都将加载在高水位标记之上。如果表中有许多块中的行已被删除,则可能会浪费空间并减慢全表扫描的速度。
直接加载方式:
•到非分区表、分区表或子分区表中的串行直接加载插入:
数据将插入到表段或各分区段的当前高水位标记之上。高水位标记是一个分界线,分界线
以上的块不会格式化,因而无法接收数据。执行一条语句后,就会将高水位标记更新为一
个新值,以便使些数据可见。当加载分区表或子分区表时,SQL*Loader 将对行进行分区
并维护索引(也可进行分区)。如果对分区表或子分区表进行直接路径加载,那可能会消
耗大量的资源。
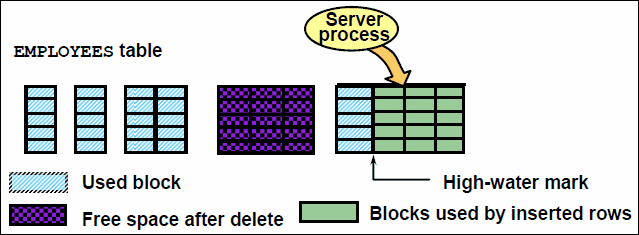
图2
SQL> create table loadtest as select * from all_objects where 1=0;
Table created.
SQL> select count(*) from all_objects;
COUNT(*)
----------
30363
SQL> select count(*) from loadtest;
COUNT(*)
----------
0
传统加载插入方式:
SQL> insert into loadtest select * from all_objects;
30363 rows created.
SQL> select count(*) from loadtest;
COUNT(*)
----------
30363
#在提交前就可以查询。
SQL> commit;
Commit complete.
串行直接加载:
SQL> insert /*+ append */ into loadtest
2 nologging
3 select * from loadtest;
30363 rows created.
SQL> select count(*) from loadtest;
select count(*) from loadtest
*
ERROR at line 1:
ORA-12838: cannot read/modify an object after modifying it in parallel
#在提交前无法查询。
SQL> commit;
Commit complete.
SQL> select count(*) from loadtest;
COUNT(*)
----------
60726
•并行直接加载

图3
可以使用下列方法之一来并行执行直接加载插入:
•在INSERT 语句中使用PARALLEL 提示,如下面例子所示。
•创建表或改变表以指定PARALLEL 子句
进行并行的直接加载插入时,Oracle 服务器会使用多个称为“并行查询从属”的进程将数据插入到表中。分配临时段以存储各个从属进程所插入的数据。提交事务处理时,这些段中的区就将成为用来插入记录的那个表的一部分。
注:
•必须在事务处理一开始时执行ALTER SESSION ENABLE PARALLEL DML 命令。
•在同一事务处理中,不能再次查询或修改那些通过并行直接加载插入而被修改的对象。
到非分区表中的并行直接加载插入:
每个并行执行服务器都将分配一个新的临时段,并将数据插入到该临时段中。执行一条语句后,并行执行协调程序就会将这些新临时段合并为主表段。
到分区表中的并行直接加载插入:
给每个并行执行服务器分配一个或多个分区,其中每个分区最多只能有一个进程在运行。并行执行服务器将数据插入到给它分配的分区段的当前高水位标记之上。执行一条语句后,并行执行协调程序就会将每个分区段的高水位标记更新为一个新值,以便使这些数据可见。
创建分区表:
SQL> create table customers1
2 (cust_code varchar2(3) not null,name varchar2(50),region varchar2(5)
3 )
4 partition by hash(cust_code)
5 (partition part1,partition part2)
6 /
Table created.
SQL> desc customers1
Name Null? Type
---------------------------------------- -------- ----------------
CUST_CODE NOT NULL VARCHAR2(3)
NAME VARCHAR2(50)
REGION VARCHAR2(5)
SQL> select object_name,object_type from user_objects;
OBJECT_NAME OBJECT_TYPE
------------------------------ ------------------
CUSTOMERS TABLE
CUSTOMERS1 TABLE PARTITION
CUSTOMERS1 TABLE PARTITION
CUSTOMERS1 TABLE
EXCEPTIONS TABLE
ORDERS TABLE
PK_CUST INDEX
7 rows selected.
SQL> alter session enable parallel dml;
Session altered.
SQL> insert /*+parallel(customers1,2) */ #2表示启用2个进程,这里指定多于分区个数也可以执行。
2 into customers1 nologging
3 select * from customers;
7 rows created.
SQL> select * from customers;
CUS NAME REGIO
--- -------------------------------------------------- -----
A01 TKB SPORT SHOP West
A02 VOLLYRITE North
A04 EVERY MOUNTAIN South
A05 SHAPE UP South
A06 SHAPE UP West
A07 WOMENS SPORTS South
A08 NORTH WOODS HEALTH AND FITNESS SUPPLY CENTER East
7 rows selected.
#未提交前也可以查询???
SQL> commit;
Commit complete.
非分区表并行插入:
SQL> create table orders1 as select * from orders where 1=0;
Table created.
SQL> insert /*+ parallel(orders1,2) */
2 into orders1 nologging
3 select * from orders;
16 rows created.
SQL> select * from orders1;
ORD_ID ORD_DATE CUS DATE_OF_D PRODUCT_ID
---------- --------- --- --------- ----------
610 11-NOV-97 A01
611 15-NOV-97 A02
612 19-NOV-97 A04
。。。。。。
16 rows selected.
SQL> commit;
Commit complete.
怎样使直接载入时为nologging模式?
SQL> set autot on stat
SQL> insert into loadtest select * from all_objects;
24930 rows created.
Statistics
----------------------------------------------------------
366 recursive calls
2221 db block gets
94179 consistent gets
0 physical reads
2845488 redo size
623 bytes sent via SQL*Net to client
546 bytes received via SQL*Net from client
3 SQL*Net roundtrips to/from client
2 sorts (memory)
0 sorts (disk)
24930 rows processed
SQL> insert /*+ append */ into loadtest select * from all_objects;
24930 rows created.
Statistics
----------------------------------------------------------
73 recursive calls
40 db block gets
93670 consistent gets
0 physical reads
2872084 redo size
607 bytes sent via SQL*Net to client
560 bytes received via SQL*Net from client
3 SQL*Net roundtrips to/from client
1 sorts (memory)
0 sorts (disk)
24930 rows processed
SQL> commit;
Commit complete.
SQL> insert /*+ append */ into loadtest nologging select * from all_objects;
24930 rows created.
Statistics
----------------------------------------------------------
51 recursive calls
29 db block gets
93660 consistent gets
0 physical reads
2870728 redo size
608 bytes sent via SQL*Net to client
573 bytes received via SQL*Net from client
3 SQL*Net roundtrips to/from client
1 sorts (memory)
0 sorts (disk)
24930 rows processed
SQL> commit;
Commit complete.
SQL> alter table loadtest nologging;
Table altered.
SQL> insert /*+ append */ into loadtest select * from all_objects;
24930 rows created.
Statistics
----------------------------------------------------------
279 recursive calls
40 db block gets
93713 consistent gets
0 physical reads
4956 redo size
609 bytes sent via SQL*Net to client
560 bytes received via SQL*Net from client
3 SQL*Net roundtrips to/from client
6 sorts (memory)
0 sorts (disk)
24930 rows processed
SQL*Loader
参考文献:联机文档Utilities;Oracle自带11个实例(ORACLE_HOME/rdbms/demo/ulcase*);Expert.Oracle.Database.Architecture.9i.and.10g

图4
SQL*Loader 控制文件
SQL*Loader 控制文件是一个文本文件,其中包含一些数据定义语言(DDL) 指令。DDL 用于控制SQL*Loader 会话的以下方面:
• SQL*Loader 到何处查找所要加载的数据
• SQL*Loader 希望数据采用什么格式
• SQL*Loader 在加载数据时如何进行配置(内存管理、拒绝记录、处理被中断的加载等)
• SQL*Loader 如何操纵正在加载的数据
虽然并未明确定义,但是可以将加载程序控制文件划分为三个部分。
•第一部分包含会话范围内的信息,例如:
–全局选项(如绑定大小、行、要跳过的记录等)
–指定输入数据所在位置的INFILE 子句
–如何加载数据
•第二部分包含一个或多个INTO TABLE 块。其中每个块都包含一些与要在其中加载数据的那个表有关的信息,如该表的名称以及表中各列。
•第三部分是可选的。如果该部分存在,其中将包含输入数据。
以下示例为一个典型的SQL*Loader 控制文件。
1 -- This is a sample control file
2 LOAD DATA
3 INFILE ’SAMPLE.DAT’
4 BADFILE ’sample.bad’
5 DISCARDFILE ’sample.dsc’
6 APPEND
7 INTO TABLE emp
8 WHEN (57) = ’.’
9 TRAILING NULLCOLS
10 (hiredate SYSDATE,
deptno POSITION(1:2) INTEGER EXTERNAL(3)
NULLIF deptno=BLANKS,
job POSITION(7:14) CHAR TERMINATED BY WHITESPACE
NULLIF job=BLANKS "UPPER(:job)",
mgr POSITION(28:31) INTEGER EXTERNAL
TERMINATED BY WHITESPACE, NULLIF mgr=BLANKS,
ename POSITION(34:41) CHAR
TERMINATED BY WHITESPACE "UPPER(:ename)",
empno POSITION(45) INTEGER EXTERNAL
TERMINATED BY WHITESPACE,
sal POSITION(51) CHAR TERMINATED BY WHITESPACE
"TO_NUMBER(:sal,’$99,999.99’)",
comm INTEGER EXTERNAL ENCLOSED BY ’(’ AND ’%’
":comm * 100"
)
对示例控制文件的解释如下:
1. 这就是在控制文件中输入注释的方法。注释可以出现在文件的命令部分中的任何地方,但不能出现在数据中。
2. LOAD DATA 语句通知SQL*Loader 将要开始一个新的数据加载。如果要继续执行之前遭到中断的加载进程,则应该使用CONTINUE LOAD DATA 语句。
3. INFILE 关键字指定其中包含所要加载的数据的数据文件的名称。
4. BADFILE 关键字指定用于保存遭拒绝记录的文件的名称。
5. DISCARDFILE 关键字指定用于放置废弃记录的文件的名称。
6. APPEND 关键字是那些可用于将数据加载到非空的表中的多种选项中的一种选项。若要将数据加载到空表中,则可以使用INSERT 关键字。
7. INTO TABLE 关键字用于指定表、字段和数据类型。它定义了数据文件中的记录与数据库中的表之间的关系。
8. WHEN 子句指定了一个或多个字段条件。在SQL*Loader 加载数据之前,每条记录都必须符合这些条件。在此示例中,仅当第57 个字符是小数点时,SQL*Loader 才会加载这条记录。该小数点分隔字段中的元和分,而且在SAL 没有值的情况下将导致该记录被拒绝。
9. TRAILING NULLCOLS 子句指示SQL*Loader 将任何处于相对位置的列(即不在该记录中的列)作为空列处理。
10. 控制文件的剩余部分包含字段列表,该列表提供了所要加载的表中的列格式的有关信息。
与控制文件的语法有关的注意事项
•控制文件的语法在格式方面没有任何限制(语句可以长达数行)。
•它不区分大小写。但是,单引号或双引号内的字符串必须完全保留原样(包括大小写在内)。
•在控制文件的语法中,注释从两个标记注释开始处的连字符(--) 开始一直延续到行尾。控制文件的第三部分(可选)被认为是数据(而非控制文件的语法),因此,注释在此部分中不受支持。
•对SQL*Loader 来说,CONSTANT和ZONE关键字具有特殊含义,因此将该关键字加以保留。为避免出现潜在的冲突,不应将CONSTANT或ZONE 一词用作任何表或列的名称。
输入数据和数据文件
固定记录格式:
如果数据文件中的所有记录具有相同的字节长度,则文件采用的是固定记录格式。虽然这种格式最为死板,但是它所带来的性能比可变记录格式或流格记录格式都好。此外,固定记录格式还很易于指定。例如:INFILE <datafile_name> "fix n"在此示例中,SQL*Loader 应该认为特定数据文件采用的是固定记录格式,其中每条记录都具有n 个字节。
以下示例显示的是一个指定让数据文件采用固定记录格式的控制文件。该数据文件包含4条物理记录。第一条记录是[0001, abcd],其中正好包括9 个字节(使用单字节字符集),回车符是第10 个字节。
load data
infile ’example.dat’ "fix 10"
into table example
fields terminated by ’,’
(col1, col2)
example.dat:
0001,abcd
0002,fghi
0003,klmn
可变记录格式:
如果数据文件中每条记录的开头都包含了该记录在字符字段中的长度,则文件所采用的可变记录格式。这种格式与固定记录格式相比具有更大的灵活性,与流式记录格式相比则能带来更高的性能。例如,可以按以下方法指定一个被认为是采用了可变记录格式的数据文件:
INFILE "datafile_name" "var n"
在此示例中,n 指定记录长度字段中的字节数。如果未指定n,则SQL*Loader 假定记录长度为5 个字节。如果指定的n 大于40,就会出现错误。以下示例显示的是一个控制文件说明,它指示SQL*Loader 在example.dat 数据文件中查找数据,并且向SQL*Loader 指明该文件采用的格式为可变记录格式,其中的记录长度字段包括3 个字节。example.dat数据文件包含3 条物理记录。其中,第1 条记录的长度被指定为009(即9)个字节,第2记录的长度为010 个字节(包括由一个字符组成的新行),第3 条记录的长度为012 个字节。此示例还假定该数据文件使用单字节字符集。
load data
infile ’example.dat’ "var 3“
into table example
fields terminated by ’,’ optionally enclosed by ’"’
(col1 char(5),col2 char(7))
example.dat:
009hello,cd,
010world,im,
012my,name is,
流式记录格式:
如果不是按大小来指定记录,而是让SQL*Loader 通过扫描记录结束符来判断记录的起始和结束,则文件所采用的是流式记录格式。流式记录格式是最灵活的格式,但可能会使性能下降。要使数据文件的格式被认为是流式记录格式,则该数据文件的说明将类似以下语句:
INFILE <datafile_name> ["str terminator_string"]
将terminator_string 指定为’char_string’或X’hex_string’,其中:char_string’是用一个用单引号或双引号引起来的字符串X’hex_string’是一个采用十六进制格式的字节字符串如果terminator_string 中包含特殊字符(即不可打印的字符),应该将它指定为X’hex_string’。但是,通过使用反斜杠,可以将某些不可打印的字符指定为(’char_string’)。例如:
\n 换行符(新行)
\t 横向制表符
\f 换页符
\v 纵向制表符
\r 回车符
如果通过NLS_LANG 参数给会话指定的字符集与数据文件的字符集不相同,则将字符串转换为数据文件的字符集。十六进制字符串应该在数据文件的字符集范围之内,因此不会进行转换。如果未指定terminator_string,则它将采用缺省值:新行(行尾)符。在基于UNIX 的平台上,新行符为换行符,而在Microsoft 平台上则为回车符加上换行符。新行符将放在数据文件的字符集后面。
以下示例说明了如何加载采用流式记录格式的数据,在此格式中将使用字符串’|\n’来指定结束符字符串。通过在该字符串中使用反斜杠字符,可指定不可打印的换行符。
load data
infile ’example.dat’ "str ’|\n’“
into table example
fields terminated by ’,’ optionally enclosed by ’"’
(col1 char(5),
col2 char(7))
example.dat:
hello,world,|
james,bond,|
逻辑记录
SQL*Loader 按照指定的记录格式将输入数据以物理记录的形式出现。缺省情况下,一条物理记录就是一条逻辑记录。但是为了增大灵活性,可以指示SQL*Loader 将大量的物理记录合并为一条逻辑记录。SQL*Loader 可以使用以下两种方法之一完成该操作:
•将固定数量的物理记录合并为一条逻辑记录
•当某种条件为真时,将物理记录合并为逻辑记录
使用CONCATENATE 来汇集逻辑记录:
如果SQL*Loader 应该始终将相同数量的物理记录组合成一条逻辑记录,则使用CONCATENATE。以下是CONCATENATE 的一个使用示例。在该示例中,integer 用于指定所要合并的物理记录的数量:CONCATENATE integer
使用CONTINUEIF 来汇集逻辑记录:
如果所要合并的物理记录的数量是变化的,则必须使用CONTINUEIF。在CONTINUEIF关键字后面跟有一个条件。读取每条物理记录时,都会对该条件进行求值。例如,如果第1 条记录在字符位置80 处有一个英镑符号(#),则有可能将两条记录合并。如果该字符位置上是任何其它字符,则不将第2 条记录添加到第1 条记录上。
加载方法

图5
常规路径加载:
常规路径加载将需要插入的行排成一个数组,并使用SQL INSERT 语句加载数据。在常规路径加载期间,将基于字段说明来分析输入记录,而且将记录排成一个数组并将其插入到控制文件所指定的表中。不符合字段说明的记录将被拒绝,而不满足选择标准的记录则将被废弃。
可通过常规路径加载将数据加载到集簇表及非集簇表中。至于重做日志的生成情况,则受到所加载表的记录属性的控制。
直接路径加载:
直接路径加载在内存中建立数据块,并将这些块直接保存到为正在进行加载的表分配的区内。仅当数据库处于ARCHIVELOG 模式时,才会生成重做日志条目。直接路径加载使用字段说明建立全部的Oracle 数据块,并将这些块直接写入Oracle 数据文件中。直接路径加载绕过数据库缓冲区高速缓存,而且仅在需要管理区和调整高水位标记时才会访问SGA。
直接路径加载通常比常规路径加载速度快,但它不能应付所有情况。
注:Oracle 所提供的脚本catldr.sql 可创建供直接路径加载使用的视图。该脚本将在运行catalog.sql 脚本时自动调用。
直接路径加载和常规路径加载的比较
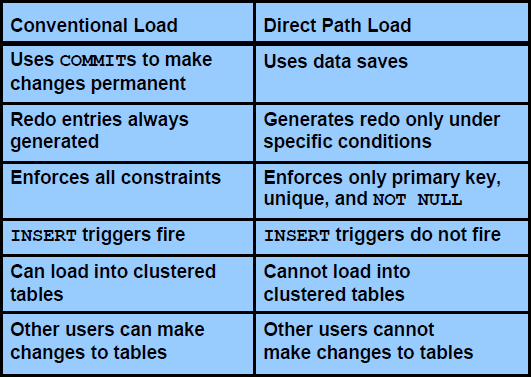
图6
保存数据的方法:
常规路径加载使用SQL 处理及数据库COMMIT 来保存数据。在插入记录数组后将执行提交操作。每次数据加载都可能涉及多个事务处理。
直接路径加载使用数据保存来将数据块写入到Oracle 数据文件中。数据保存与COMMIT
之间存在以下区别:
•数据保存期间,只将写满的数据库块写入数据库。
•块写在表的高水位标记之后。
•数据保存之后,高水位标记移动。
•数据保存之后不释放内部资源。
•数据保存不结束事务处理。
•每次数据保存时不更新索引。
记录所进行的更改:
常规路径加载就像任何DML 语句一样生成重做日志条目。如果使用直接路径加载,则在下列情况下将不生成重做日志条目:
•数据库为NOARCHIVELOG 模式
•数据库为ARCHIVELOG 模式,但禁用事件记录。通过为表设置NOLOGGING 属性或在控制文件中使用UNRECOVERABLE 子句,可禁用事件记录。
执行约束:
常规路径加载期间,与在任何DML操作期间一样,强制执行所有启用的约束。
在直接路径加载期间,对约束进行如下处理:
•建立数组时检查NOT NULL 约束。
•禁用外键约束和CHECK 约束,并可在运行结束时通过使用控制文件中的有关命令来启用它们。禁用外键约束的原因在于:这些约束引用其它行或表;禁用CHECK约束则是因为这些约束可能使用SQL 函数。如果只要将少数几行插入到一个大表中,可使用常规加载。
•运行期间和运行结束时检查主键约束和唯一性约束,如果违反,则可能禁用。
触发INSERT 触发器:
虽然在常规加载期间会触发INSERT 触发器,但它们在进行直接路径加载之前被禁用,并在运行结束时重新启用。如果某个引用对象在运行结束时无法访问,说明这些触发器可能仍被禁用。请考虑使用常规路径加载,以通过INSERT 触发器将数据加载到表中。
加载到集簇表中:
不能通过直接加载来将行加载到集簇表中。只能使用常规路径加载来加载集簇表。
锁定:
在直接加载期间,其它事务处理不能对正被加载的表进行更改。不过,该规则存在一种例外情况,即在并发使用多个并行直接加载会话时可以对正被加载的表进行更改。
并行直接路径加载
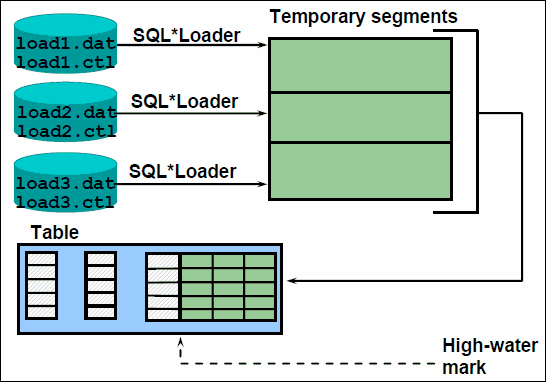
图7
使用多个SQL*Loader 会话可提高直接路径加载的性能。有三种并发模式可用于最大限度地缩短数据加载所需的时间:
•并行常规路径加载
•在直接路径加载方法中使用段间并发
•在直接路径加载方法中使用段内并发
并发常规路径:
如果触发器或完整性约束出现问题,但又希望获得更快的加载速度,则应该考虑使用多个并发的常规路径加载。请在具有多个CPU 的系统上使用多个并发执行的加载会话。在逻辑记录边界上将输入数据文件拆分为多个单独的文件,然后使用常规路径加载会话分别加载拆分得到的输入数据文件。
段间并发:
段间并发可用于并发加载不同的对象。在直接路径加载中,这种技术可用于并发加载不同的表,或者并发加载同一表中的不同分区。
段内并发:
并行直接路径加载允许多个直接路径加载会话将数据并发加载到同一表中,或者加载到某个允许进行段内并发操作的分区表的同一分区中。
数据转换
在常规路径加载过程中,分两步将数据文件中的数据字段转换为数据库中的列:
•控制文件中的字段说明用于解释数据文件的格式,并使用该数据将数据文件转换为SQL INSERT 语句。
• Oracle 数据库服务器接受该数据,并执行INSERT 语句将数据存储到数据库中。
被废弃或拒绝的记录
坏文件:
坏文件包含被SQL*Loader 或Oracle 数据库拒绝的记录。
SQL*Loader 所拒绝的记录:
如果输入格式无效,SQL*Loader 将拒绝记录。例如,如果记录的右引号分隔符丢失或者其中某个受限制的字段超过其最大长度,则SQL*Loader 将拒绝该记录。该遭拒绝的记录将被置入坏文件中。
Oracle 所拒绝的记录:
在SQL*Loader 接受一条记录以进行处理后,就会向Oracle 发送一行以进行插入。如果Oracle 确定该行有效,就会将该行插入到数据库中。否则,将拒绝该记录,并且SQL*Loader 将该记录放到坏文件中。如果出现以下情况,该行就可能被拒绝:某个键不是唯一的、某个所需的字段为空,或者字段中包含的数据对于Oracle 来说属于无效的数据类型。
废弃文件:
执行SQL*Loader 时,它可能会创建一个称为“废弃文件”的文件。仅在确实需要废弃文件、并且您已指定应该启用废弃文件时才创建该文件。废弃文件包含在加载过程中过滤出来的记录,因为这些记录与控制文件中指定的任何记录选择标准均不符合。因此,废弃文件包含那些未插入到数据库任何表中的记录。可以指定废弃文件所能接受的此类记录的最大数量。
日志文件的内容
“标头信息”部分包含以下条目:
•运行日期
•软件版本号
“全局信息”部分包含以下条目:
•所有输入/输出文件的名称
•命令行参数的回显
•续行符说明
“表信息”部分为所加载的每个表提供以下条目:
•表名
•加载条件(如有)。也即,是加载所有的记录,还是仅加载那些符合WHEN 子句标准的记录。
• INSERT、APPEND 或REPLACE 说明
•以下列信息:
–位置、长度、数据类型和分隔符(如果能在数据文件中找到)
– RECNUM、EQUENCE、CONSTANT 或EXPRESSION(如果指定)
– DEFAULTIF 或NULLIF(如果指定)
如果SQL*Loader 控制文件包含任何可用于加载日期时间或时间间隔等数据类型的指令,则日志文件将在数据类型标题下面包含DATETIME 或INTERVAL 关键字。如果适用的话,还将在DATETIME 或INTERVAL 关键字后面加上相应的标记。
仅当数据文件中的数据有错误时,才会出现“数据文件信息”部分。该部分提供以下条目:
• SQL*Loader 和Oracle 数据记录错误
•被废弃的记录
“表加载信息”部分为所加载的每个表提供以下条目:
•加载的行数
•有资格加载但由于数据错误而被拒绝的行数
•由于未通过WHEN 子句测试而被废弃的行数
•相关字段均为空的行数
“小结统计信息”部分显示以下数据:
•占用的空间量:
–用于绑定数组(实际使用量基于已指定的BINDSIZE)
–用于其它开销(始终需要,而与BINDSIZE 无关)
•累计得到的加载统计信息;即对于所有的数据文件,所跳过、读取或拒绝的记录数加载表时,将记录以下统计信息:
•如果对分区表进行直接路径加载,将报告每个分区的统计信息。
•常规路径加载无法报告每个分区的统计信息。
如果没有启用介质恢复,则不对加载进行记录。即,如果禁用介质恢复,将忽略记录操作请求。
SQL*Loader 原则
使用SQL*Loader 时应遵循下列原则,以使错误减到最少并提高性能:
•使用参数文件来指定常用的命令行选项。例如,如果每周都要将数据加载到数据仓库中,则除文件名外,其它所有选项都可以保持不变。
•将控制文件与数据文件分开,这样可以在多个加载会话中反复使用控制文件。
•基于预期的数据量预先分配好空间,以免在加载期间动态分配区,从而可提高加载速度。
•对于直接加载,将使用临时段来生成新数据的索引。加载结束时,这些索引将与现有索引合并。通过按最大索引的关键字对输入数据进行排序,可以最大限度地减少排序所使用的空间。
•在并行直接加载中,可指定用于插入数据的临时段的位置。对于每个加载会话,可指定不同的数据库文件以获得最佳性能。




















