
最后以巨佬——“贝叶斯大爷”作为基本机器学习算法学习的压轴算法》》》》》》》》》》》》》膜拜!!!!!!
1 准备知识:条件概率公式
2 如何使用条件概率进行分类
假设这里要被分类的类别有两类,类c1和类c2,那么我们需要计算概率p(c1|x,y)和p(c2|x,y)的大小并进行比较:
如果:p(c1|x,y)>p(c2|x,y),则(x,y)属于类c1
p(c1|x,y)<p(c2|x,y),则(x,y)属于类c2
我们知道p(x,y|c)的条件概率所表示的含义为:已知类别c1条件下,取到点(x,y)的概率;那么p(c1|x,y)所要表达的含义呢?显然,我们同样可以按照条件概率的方法来对概率含义进行描述,即在给定点(x,y)的条件下,求该点属于类c1的概率值。那么这样的概率该如何计算呢?显然,我们可以利用贝叶斯准则来进行变换计算:
利用上面的公式,我们可以计算出在给定实例点的情况下,分类计算其属于各个类别的概率,然后比较概率值,选择具有最大概率的那么类作为点(x,y)的预测分类结果。
以上我们知道了通过贝叶斯准则来计算属于各个分类的概率值,那么具体而言,就是计算贝叶斯公式中的三个概率,只要得到了这三个概率值,显然我们就能通过贝叶斯算法预测分类的结果了。因此,到了这里,我们就知道了朴树贝叶斯算法的核心所在了。
3 朴素贝叶斯中朴素含义
特征之间的相互独立性假设,所谓独立,是指的是统计意义上的独立,即一个特征出现的可能性与它和其他特征没有关系。同时,朴素贝叶斯另外一个含义是,这些特征同等重要。虽然这些假设都有一定的问题,但是朴素贝叶斯的实际效果却很好。
from:
朴素贝叶斯不能用于回归,但他是一个有效的分类器。
朴素贝叶斯的经典应用是对垃圾邮件的过滤,是对文本格式的数据进行处理,因此这里以此为背景讲解朴素贝叶斯定理。设D是训练样本和相关联的类标号的集合,其中训练样本的特征属性集为 X { X1,X2, ... , Xn }, 共有n 个属性;类标号为 C{ C1,C2, ... ,Cm }, 有m种类别。朴素贝叶斯定理:

其中,P(Ci | X)为后验概率,P(Ci)为先验概率,
为条件概率。朴素贝叶斯的两个假设:
1、属性之间相互独立。
2、每个属性同等重要。
通过假设1知,条件概率
可以简化为:

分别计算
,P(C_{2}|X)...P(C_{m}|X)")
这m个值的大小,哪个最大,样本就归属于哪个类。
朴素贝叶斯算法的核心思想:选择具有最高后验概率作为确定类别的指标。
三、朴素贝叶斯分类
对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。通俗来说,就好比这么个道理,你在街上看到一个黑人,我问你你猜这哥们哪里来的,你十有八九猜非洲。为什么呢?因为黑人中非洲人的比率最高,当然人家也可能是美洲人或亚洲人,但在没有其它可用信息下,我们会选择条件概率最大的类别,这就是朴素贝叶斯的思想基础。
朴素贝叶斯分类的正式定义如下:
1、设
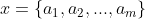
为一个待分类项,而每个a为x的一个特征属性。2、有类别集合
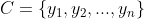
。
3、计算 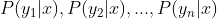
4、如果
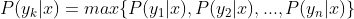
,则
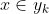
。
那么现在的关键就是如何计算第3步中的各个条件概率。我们可以这么做:
1、找到一个已知分类的待分类项集合,这个集合叫做训练样本集。
2、统计得到在各类别下各个特征属性的条件概率估计。即
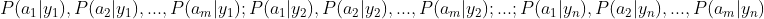
。
3、如果各个特征属性是条件独立的,则根据贝叶斯定理有如下推导:
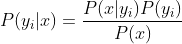
因为分母对于所有类别为常数,因为我们只要将分子最大化皆可。又因为各特征属性是条件独立的,所以有:
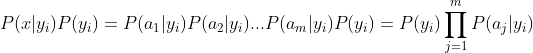
根据上述分析,朴素贝叶斯分类的流程可以由下图表示:

可以看到,整个朴素贝叶斯分类分为三个阶段:
第一阶段——准备工作阶段,这个阶段的任务是为朴素贝叶斯分类做必要的准备,主要工作是根据具体情况确定特征属性,并对每个特征属性进行适当划分,然后由人工对一部分待分类项进行分类,形成训练样本集合。这一阶段的输入是所有待分类数据,输出是特征属性和训练样本。这一阶段是整个朴素贝叶斯分类中唯一需要人工完成的阶段,其质量对整个过程将有重要影响,分类器的质量很大程度上由特征属性、特征属性划分及训练样本质量决定。
第二阶段——分类器训练阶段,这个阶段的任务就是生成分类器,主要工作是计算每个类别在训练样本中的出现频率及每个特征属性划分对每个类别的条件概率估计,并将结果记录。其输入是特征属性和训练样本,输出是分类器。这一阶段是机械性阶段,根据前面讨论的公式可以由程序自动计算完成。
第三阶段——应用阶段。这个阶段的任务是使用分类器对待分类项进行分类,其输入是分类器和待分类项,输出是待分类项与类别的映射关系。这一阶段也是机械性阶段,由程序完成。
估计类别下特征属性划分的条件概率及Laplace校准
由上文看出,计算各个划分的条件概率P(a|y)是朴素贝叶斯分类的关键性步骤,当特征属性为离散值时,只要很方便的统计训练样本中各个划分在每个类别中出现的频率即可用来估计P(a|y),下面重点讨论特征属性是连续值的情况。
当特征属性为连续值时,通常假定其值服从高斯分布(也称正态分布)。即:
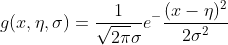
而
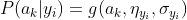
因此只要计算出训练样本中各个类别中此特征项划分的各均值和标准差,代入上述公式即可得到需要的估计值。均值与标准差的计算在此不再赘述。
另一个需要讨论的问题就是当P(a|y)=0怎么办,当某个类别下某个特征项划分没有出现时,就是产生这种现象,这会令分类器质量大大降低。为了解决这个问题,我们引入Laplace校准,它的思想非常简单,就是对没类别下所有划分的计数加1,即

,这样如果训练样本集数量充分大时,并不会对结果产生影响,并且解决了上述频率为0的尴尬局面。
分子分母个加上一个数:
条件概率:
先验概率 :
 = \frac{\sum_{i=1}^{n}I(y=ck)+\lambda }{n+K\lambda }")
四、举例
下面讨论一个使用朴素贝叶斯分类解决实际问题的例子,为了简单起见,对例子中的数据做了适当的简化。这个问题是这样的,对于SNS社区来说,不真实账号(使用虚假身份或用户的小号)是一个普遍存在的问题,作为SNS社区的运营商,希望可以检测出这些不真实账号,从而在一些运营分析报告中避免这些账号的干扰,亦可以加强对SNS社区的了解与监管。
说白了,就是要将社区中所有账号在真实账号和不真实账号两个类别上进行分类,下面我们一步一步实现这个过程。
首先,设:C = 0 表示真实账号; C = 1 表示不真实账号
1、确定特征属性及划分
这一步要找出可以帮助我们区分真实账号与不真实账号的特征属性,在实际应用中,特征属性的数量是很多的,划分也会比较细致,但这里为了简单起见,我们用少量的特征属性以及较粗的划分,并对数据做了修改。
我们选择三个特征属性:
a1:日志数量 / 注册天数(比例)
a2:好友数量 / 注册天数(比例)
a3:是否使用真实头像。
在SNS社区中这三项都是可以直接从数据库里得到或计算出来的。由于特征a1、a2都是连续变量,我们进行如下划分:
a1:{a<=0.05, 0.05<a<0.20, a>=0.20}
a2:{a<=0.10, 0.10<a<0.80, a>=0.80}
a3:{a=0(不是真实头像),a=1(是真实头像)}
2、获取训练样本
这里使用运维人员曾经人工检测过的1万个账号作为训练样本。
3、训练
计算训练样本中每个类别的频率,用训练样本中真实账号和不真实账号数量分别除以一万,得到:
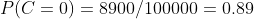
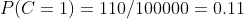
计算每个类别条件下各个特征属性划分的频率:
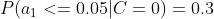
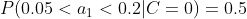
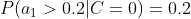
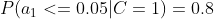
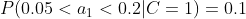
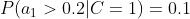
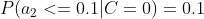
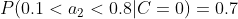
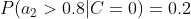
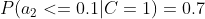
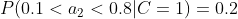
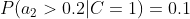
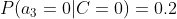
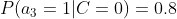
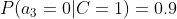
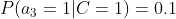
所谓的训练就是计算样本集中各特征取值的条件概率的值。
4、预测
下面我们使用上面训练得到的分类器鉴别一个账号,这个账号使用非真实头像,日志数量与注册天数的比率为0.1,好友数与注册天数的比率为0.2。即:a1 = 0.1;a2 = 0.2;a3 = 0
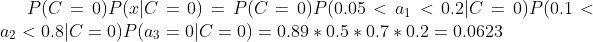
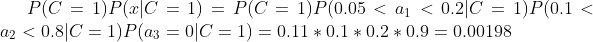
可以看到,虽然这个用户没有使用真实头像,但是通过分类器的鉴别,更倾向于将此账号归入C = 0,即真实账号类别。这个例子也展示了当特征属性充分多时,朴素贝叶斯分类对个别属性的抗干扰性。
from:
Python实现:
数据来源: http://pan.baidu.com/s/1pLoKUMJ
from:朴素贝叶斯算法--python实现
#coding:utf-8
# 极大似然估计 朴素贝叶斯算法
import pandas as pd
import numpy as np
class NaiveBayes(object):
def getTrainSet(self):
dataSet = pd.read_csv('C://pythonwork//practice_data//naivebayes_data.csv')
dataSetNP = np.array(dataSet) #将数据由dataframe类型转换为数组类型
trainData = dataSetNP[:,0:dataSetNP.shape[1]-1] #训练数据x1,x2
labels = dataSetNP[:,dataSetNP.shape[1]-1] #训练数据所对应的所属类型Y
return trainData, labels
def classify(self, trainData, labels, features):
#求labels中每个label的先验概率
labels = list(labels) #转换为list类型
P_y = {} #存入label的概率
for label in labels:
P_y[label] = labels.count(label)/float(len(labels)) # p = count(y) / count(Y),count(label)表示list中 某元素label出现 的次数
#求label与feature同时发生的概率
P_xy = {}
for y in P_y.keys(): #keys() 函数以列表形式返回一个字典所有的键
y_index = [i for i, label in enumerate(labels) if label == y] # labels中出现y值的所有数值的下标索引
for j in range(len(features)): # features[0] 在trainData[:,0]中出现的值的所有下标索引
x_index = [i for i, feature in enumerate(trainData[:,j]) if feature == features[j]]
xy_count = len(set(x_index) & set(y_index)) # set(x_index)&set(y_index)列出两个表相同的元素
pkey = str(features[j]) + '*' + str(y)
P_xy[pkey] = xy_count / float(len(labels))
#求条件概率
P = {}
for y in P_y.keys():
for x in features:
pkey = str(x) + '|' + str(y)
P[pkey] = P_xy[str(x)+'*'+str(y)] / float(P_y[y]) #P[X1/Y] = P[X1Y]/P[Y]
#求[2,'S']所属类别
F = {} #[2,'S']属于各个类别的概率
for y in P_y:
F[y] = P_y[y]
for x in features:
F[y] = F[y]*P[str(x)+'|'+str(y)] #P[y/X] = P[X/y]*P[y]/P[X],分母相等,比较分子即可,所以有F=P[X/y]*P[y]=P[x1/Y]*P[x2/Y]*P[y]
features_label = max(F, key=F.get) #概率最大值对应的类别
return features_label
if __name__ == '__main__':
nb = NaiveBayes()
# 训练数据
trainData, labels = nb.getTrainSet()
# x1,x2
features = [2,'S']
# 该特征应属于哪一类
result = nb.classify(trainData, labels, features)
print features,'属于',result1、labels.count()
list中的 count()函数表示list中某元素出现 的次数
2、P_y.keys()
Dict字典中的keys函数,以列表形式返回一个字典所有的键
dict = {'Name': 'Zara', 'Age': 7}
print "Value : %s" % dict.keys()
结果为:Value : ['Age', 'Name']
3、max(F, key=F.get)
lambda a : b , 实际上就是:lambda是一个输入值为a,返回值为b的函数。函数形式:max( x ,key=lambda a : b ) # x可以是任何数值,可以有多个x值。这个函数的意思是:我们先把x值带入lambda函数转换成b值,然后再将b值进行比较。
max(F, key=F.get)返回与最大值对应的键。
字典“F”是python中的一个可迭代的结构。当您在F中循环使用x时,您将循环使用字典中的键,max函数有两个参数:一个可迭代对象(F)和一个可选的“key”函数。 Key功能将用于评估F中最大的项目的值。
4、enumerate()
list=[1,2,3,4,5,6]
for i ,j in enumerate(list)
print(i,j) 输出:
0, 1
1, 2
2, 3
3, 4
4, 5
5, 6
from:
4、列表解析
根据已有列表,高效创建新列表。列表解析是Python迭代机制的一种应用,它常用于实现创建新的列表,因此用在[]中。
语法:[expression for iter_val in iterable]或者[expression for iter_val in iterable if cond_expr]
要求:列出1~10所有数字的平方
####################################################
1、普通方法:
>>> L = []
>>> for i in range(1,11):
... L.append(i**2)
...
>>> print L
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
####################################################
2、列表解析
>>>L = [ i**2 for i in range(1,11)]
>>>print L
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]from:
实例2:
(Laplace校准)
#coding:utf-8
#朴素贝叶斯算法 贝叶斯估计, λ=1 K=2, S=3; λ=1 拉普拉斯平滑
import pandas as pd
import numpy as np
class NavieBayesB(object):
def __init__(self):
self.A = 1 # 即λ=1
self.K = 2
self.S = 3
def getTrainSet(self):
trainSet = pd.read_csv('C://pythonwork//practice_data//naivebayes_data.csv')
trainSetNP = np.array(trainSet) #由dataframe类型转换为数组类型
trainData = trainSetNP[:,0:trainSetNP.shape[1]-1] #训练数据x1,x2
labels = trainSetNP[:,trainSetNP.shape[1]-1] #训练数据所对应的所属类型Y
return trainData, labels
def classify(self, trainData, labels, features):
labels = list(labels) #转换为list类型
#求先验概率
P_y = {}
for label in labels:
P_y[label] = (labels.count(label) + self.A) / float(len(labels) + self.K*self.A)
#求条件概率
P = {}
for y in P_y.keys():
y_index = [i for i, label in enumerate(labels) if label == y] # y在labels中的所有下标
y_count = labels.count(y) # y在labels中出现的次数
for j in range(len(features)):
pkey = str(features[j]) + '|' + str(y)
x_index = [i for i, x in enumerate(trainData[:,j]) if x == features[j]] # x在trainData[:,j]中的所有下标
xy_count = len(set(x_index) & set(y_index)) #x y同时出现的次数
P[pkey] = (xy_count + self.A) / float(y_count + self.S*self.A) #条件概率
#features所属类
F = {}
for y in P_y.keys():
F[y] = P_y[y]
for x in features:
F[y] = F[y] * P[str(x)+'|'+str(y)]
features_y = max(F, key=F.get) #概率最大值对应的类别
return features_y
if __name__ == '__main__':
nb = NavieBayesB()
# 训练数据
trainData, labels = nb.getTrainSet()
# x1,x2
features = [2,'S']
# 该特征应属于哪一类
result = nb.classify(trainData, labels, features)
print (features,'属于',result)max函数:当key参数不为空时,就以key的函数对象为判断的标准。
例如:找出一组数中绝对值最大的数,就可以配合lamda先进行处理,再找出最大值,结果 tmp=-9
a = [-9, -8, 1, 3, -4, 6]
tmp = max(a, key=lambda x: abs(x))
print(tmp)feature_y=max(F,key=F.get()) , 在对字典进行数据操作的时候,默认只会处理key,而不是value,这是我们先执行F.get(),返回value对象,比较value的大小,但是结果还是返回对应的key.
朴素贝叶斯模型:文本分类+垃圾邮件分类实例:
最小错误率贝叶斯决策
1.判别函数:

就是朴素贝叶斯函数嘛。。
最小风险贝叶斯决策
在决策中,除了关心决策的正确与否,有时我们更关心错误的决策将带来的损失。比如在判断细胞是否为癌细胞的决策中,若把正常细胞判定为癌细胞,将会增加患者的负担和不必要的治疗,但若把癌细胞判定为正常细胞,将会导致患者失去宝贵的发现和治疗癌症的机会,甚至会影响患者的生命。这两种类型的决策错误所产生的代价是不同的。
考虑各种错误造成损失不同时的一种最优决策,就是所谓的最小风险贝叶斯决策。设对于实际状态为wj的向量x采取决策αi所带来的损失为

该函数称为损失函数,通常它可以用表格的形式给出,叫做决策表。需要知道,最小风险贝叶斯决策中的决策表是需要人为确定的,决策表不同会导致决策结果的不同,因此在实际应用中,需要认真分析所研究问题的内在特点和分类目的,与应用领域的专家共同设计出适当的决策表,才能保证模式识别发挥有效的作用。
对于一个实际问题,对于样本xx,最小风险贝叶斯决策的计算步骤如下: (1)利用贝叶斯公式计算后验概率:

其中要求先验概率和类条件概率已知。 (2)利用决策表,计算条件风险:

(3)决策:选择风险最小的决策,即:


由此可见,因为对两类错误带来的风险的认识不同,从而产生了与之前不同的决策。显然,但对不同类判决的错误风险一致时,最小风险贝叶斯决策就转化成最小错误率贝叶斯决策。最小错误贝叶斯决策可以看成是最小风险贝叶斯决策的一个特例。
from:
实例:有一家医院为了研究癌症的诊断,对一大批人作了一次普查,给每人打了试验针,然后进行统计,得到如下统计数字:
①这批人中,每1000人有5个癌症病人;
②这批人中,每100个正常人有1人对试验的反应为阳性,
③这批人中,每100个癌症病人有95人对试验的反应为阳性。
假设将正常人预测为正常人和将癌症患者预测为癌症患者的损失函数均为0,将癌症患者预测为正常人的损失函数为3,将正常人预测为癌症患者的损失函数为1.
此阳性患者预测为患癌症的风险概率为(67.7% )。
患癌症的风险概率:不患癌症概率*(不患癌症却被判为癌症的损失系数1)+患癌症概率*(患癌症被判为癌症的损失系数0)

同理:将此阳性患者预测为正常的风险概率为:不患癌症概率*(不患癌症被判不患癌症的损失系数0)+患癌症概率*(患癌症被判为不患癌症的损失系数 3)
最大最小决策
最大最小决策是在类先验概率未知的情况下,考察先验概率变化对错误率的影响,找出使最小贝叶斯奉献最大的先验概率,以这种最坏情况设计分类器


















