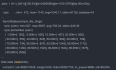
no interfaces matched the MTU interface pattern. To use auto-MTU, set mtuIfacePattern to match yo
通常情况下,我们的kubernetes集群是内网环境,如果希望通过本地访问这个集群,怎么办呢?大家想到的是Kubeadm在初始化的时候会为管理员生成一个 Kubeconfig文件,把它下载下来 是不是就可以?事实证明这样不行, 因为这个集群是内网集群,Kubeconfig文件 中APIServer的地址是内网ip。解决方案很简单,把公网ip签到证书里面就可以,其中有apiServerCertSAN
etcd 概述 etcd 是 CoreOS团队于2013年6月发起的开源项目,它的目标是构建一个高可用的分布式键值(key-value)数据库。 etcd 内部采用 raft 协议作为一致性算法
问题描述 测试集群三台master,每个master上面的kube-apiserver都频繁的重启。登录其中一台master,发现kube-apiserver的内存占用特别高,每次重启完后内存很快就飙到了20G左右,而且还有继续增长的趋势。因为默认kube-apiserver的静态pod是没有设置m
一 原理 Velero 的基本原
本文最终的解决方式很简单,就是将
本文最终的解决方式很简单,就是将现有
使用crio容器运行时,部署ssh pod后,ssh root@127.0.0.1 后,出现 connection reset by 127.0.0.1 port 22. 但是telnet 显示能通, 在pod中 ping 其他pod 出现 socket: Operation not permitt
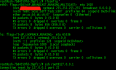
由于master2 节点重新克隆了,造成etcd异常, 恢复过程 1. 从etcd集群中删除 master2 etcd # 登录集群的任意 ETCD Pod kubectl exec -it etcd-master sh -n kube-system # Pod 中设置登录 ETCD 的命令 exp
事件背景 因为 k8s 中采用大量的异步机制、以及多种对象关系设计上的解耦,当应用实例数 增加/删除、或者应用版本发
报错信息 kubelet summary_sys_containers.go: "Failed to get system container stats stats"
kustomize 是一个通过 kustomization 文件定制 kubernetes 对象的工具,它可以通过一些资源生成一些新的资源,也可以定制不同的资源的集合。 一个比较典型的场景是我们有一个应用,在不同的环境例如生产环境和测试环境,它的 yaml 配置绝大部分都是相同的,只有个别的字段不同
内核参数调优 我们先看看通过内核的哪些参数能够提高Ingress的性能。保证在高并发环境下,发挥Ingress的最大性能。 调大全连接队列的大小 TCP 全连接队列的最大值取决于 somaxconn 和 backlog 之间的最小值,也就是 min(somaxconn, backlog)。在高并发环
配置Nginx-Ingress 这里将NG的日志落盘,便于处理。 (1)、修改ConfigMap,如下: # Source: ingress-nginx/templates/controller-configmap.yaml apiVersion: v1 kind: ConfigMap metada
安装 Metrics server Metrics Server 是 Kubernetes 内置自动缩放管道的可扩展、高效的容器资源指标来源。 Metrics Ser
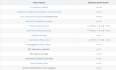
集群指标 集群 CPU 利用率 目录 表达式 详细信息 1 - (avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by (instance)) 摘要 1 - (avg(irate(node_cpu_seconds_total{mode="idl
采集器categraf集成了prometheus的agent mode模式,prometheus所支持服务发现模式,例如docker_swarm_ad_configs,docker_sd_config, dns_sd_configs, http_sd_configs都可以和categraf无缝对接。
使用的 rancher出现 Internal error occurred: failed calling webhook "ranch
简述: 最近k8s master内存压力比较大, pod数量越来越多, 打算对cpu 内存进行扩容 扩容有 cpu 4C/8G, 变更成8C/16G, 通过升级后,发现apiserver 静态pod无法启动, 在kubelet 配置文件中发现 --cpu-manager-policy=static配
1.12 配置Linux内核(cilium必选)cilium和其他的cni组件最大的不同在于其底层使用了ebpf技术,而该技术对于Linux的系统内核版本有较高的要求,完成的要求可以查看官网的详细链接,这里我们着重看内核版本、内核参数这两个部分。 Linux内核版本默认情况下我们可以参考cilium
使用 subPath 有时,在单个 Pod 中共享卷以供多方使用是很有用的。 volumeMounts.subPath 属性可用于指定所引用的卷内的子路径,而不是其根路径。 下面例子展示了如何配置某包含 LAMP 堆栈(Linux Apache MySQL PHP)的 Pod 使用同一共享卷。 此示
HorizontalPodAutoscaler(简称 HPA ) 自动更新工作负载资
创建pv yaml挂载使用 storageclass 动态挂载, storageclassName 为 nfs-storageclass
一 、 使用kubeadm 搭建 kubernetes 集群 1.1 获取kubernetes 安装包 登陆github , https://github.com/kubernetes/release 通过git clone 命令下载到linux, 进入rpm目录,安装好docker执行 docke
在近期的工作中,我们发现 K8s 集群中有些节点资源使用率很高,有些节点资源使用率很低,我们尝试重新部署应用和驱逐 Pod,发现并不能有效解决负载不均衡问题。在学习了 Kubernetes 调度原理之后,重新调整了 Request 配置,引入了调度插件,才最终解决问题。这篇就来跟大家分享 Kuber
安装k8s 1.24版本,使用yum 安装了crio 出现 /var/log/message 日志中出现了 error adding seccomp filter rule for syscall bdflush : requested action matches default action o
1、想要去删除k8s中的一个指定命名
1. 准备go环境 下载go, 编译kubernetes 要求go大于1.17版本 wget https://golang.google.cn/dl/go1.18.linux-amd64.tar.gz tar -zxvf go1.18.linux-amd64.tar.gz rm /usr/local
# my global config global: scrape_interval: 30s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 30s # E
Copyright © 2005-2024 51CTO.COM 版权所有 京ICP证060544号