
如今,数据是推动人工智能创新的核心要素。但数据的安全和隐私问题限制了数据充分释放其潜能。一直以来,微软都倡导打造负责任的人工智能,并正在开发和利用多种技术以提供更强大的隐私保护、确保数据安全。本文将为大家介绍微软亚洲研究院在机器学习隐私研究的最新进展,以及讨论在深度学习中的隐私攻击与保护。
今天,数据已成为推动人工智能创新的燃料,但同时也是组织和个人所拥有的宝贵资产。因此,只有在充分保护数据安全和隐私的前提下,云计算和人工智能的连接才有可能释放出数据的全部潜能,实现数据效能的共享。
众所周知,在存储和传输过程中加密数据早已是行业标准。而机密计算(Confidential Computing)则可以进一步保护计算过程中使用的数据,降低恶意软件、内部攻击和恶意或疏忽管理员等漏洞的风险。此前的文章“ 如何在机器学习的框架里实现隐私保护? ” ,已经对机密计算做过一些介绍,包括可信执行环境、同态加密、安全多方计算,和联邦学习。这些技术构成了保护隐私的组合套件,通过将它们一起使用,能够对不同场景构建合适的隐私和安全解决方案。
机密计算主要研究计算过程中数据的保护与攻击方法。那么发布计算结果会暴露数据隐私吗?比如,发布一个训练好的深度神经网络模型会暴露它的训练数据吗?如何控制和降低计算结果中隐私暴露的风险?下面我们将对这些问题展开探讨。
训练好的模型真的会泄露隐私吗?
直观上来说,这是一个很难回答的问题:一方面训练好的神经网络一定和训练数据有关系,互信息大于零;另一方面,从模型参数中恢复训练数据是一个求反问题,想要实现精确恢复非常困难。一个相对较容易的概念是成员推断(Membership Inference, MI)——给定一个训练好的模型,判断某一个特定样本是否来自训练集(如图1所示)。如果成员推断准确率很高,那么模型泄露隐私的风险就会相对较大,并且在一些情形下,成员信息本身就是要保护的隐私信息。

图1:成员推断攻击示例[9]
最近的一项研究[7]利用成员推断找出 GPT-2(一种大型的语言模型)记住的训练数据内容,成功提取了包含物理地址、姓名、电话、邮箱等敏感信息的训练数据(如图2所示)。这表明若发布在敏感数据上训练的大模型时,会带来很高的隐私风险。
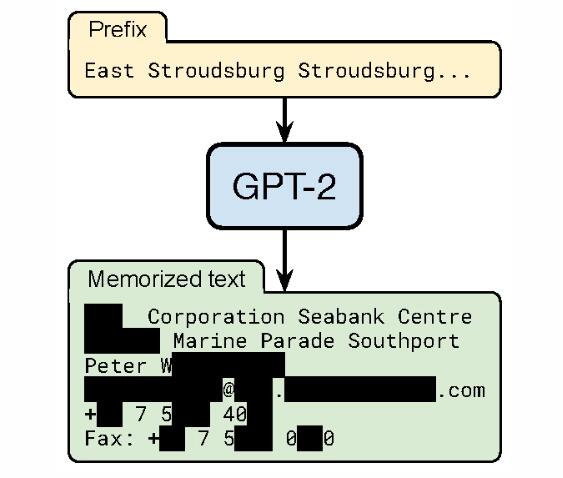
图2:训练数据提取攻击[7]。给定生成前缀,神经网络语言模型 GPT-2 生成的例子是它记住的一段训练文本,包括个人的姓名,电子邮件地址,电话号码,传真号码,物理地址等。因为展示了准确的信息,图例加黑框以保护隐私。
通常认为这种隐私泄露与过度拟合有关[8],因为过拟合表明模型记住了训练集中的样本。事实上,尽管过拟合是隐私泄露的充分条件且许多工作都利用过拟合来进行隐私攻击,但是过拟合和隐私泄露两者的关系并不完全相等。
在刚刚结束的 AAAI 2021 大会上,微软亚洲研究院与中山大学合作完成的工作 How Does Data Augmentation Affect Privacy in Machine Learning? [9]就对此问题进行了深入讨论。人们常常认为泛化误差小的模型隐私泄露风险会很低。然而,该工作通过显示数据增强如何影响成员推断(MI)挑战了这一观念。数据增强(Data Augmentation)是一种在机器学习中广泛应用的训练技巧,它可以显著提高模型的泛化性(过拟合很小)。在模型训练中使用数据增强时,研究员们提出了一种新的成员推断算法,把成员推断作为一个集合分类问题,即对一组增强实例进行分类,而不是对单个数据点进行分类。而针对集合分类问题,研究员们还设计了输入置换不变的神经网络。
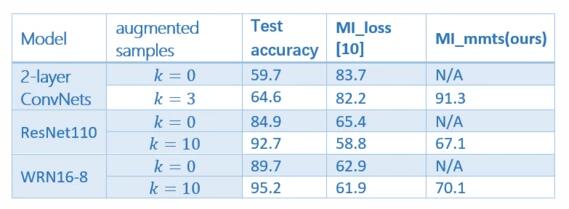
表1:成员推断成功率(%),数据集 CIFAR10
实验证明(如表1所示),当模型经过数据增强训练时,该方法普遍优于原始方法。并且在一些数据增强训练的模型上,甚至取得了比没有数据增强训练的模型上更高的成员推断成功率,而前者往往有较高的测试准确率。而且该方法针对一个宽残差网络(WRN16-8)获得了 >70% 的 MI 攻击成功率,此网络在 CIFAR10 上的测试精度超过 95%。以上结果均表明,通过数据增强训练的模型的隐私风险可能在很大程度上被低估了。
既然我们已经看到了模型泄露隐私的风险,那么将如何拥有隐私保证的共享模型呢?这就需要引入差分隐私(Differential Privacy, DP)[1]。差分隐私可确保计算结果(如训练好的模型)可以被安全地共享或使用。由于其严格的数学原理,差分隐私被公认为是隐私保护的黄金标准。应用差分隐私能够从数据集中计算出有用的信息,同时还可以保证模型无法从计算结果中重新识别数据集中的任何个体。这为金融服务和医疗保健等领域的组织机构使用人工智能技术带来了更大的信心,因为这些领域的数据都高度敏感,隐私保护格外受关注。
差分隐私从统计意义上衡量和控制了模型对训练数据的泄露。它刻画了单个数据样本对模型的影响:一个随机算法 M 符合 (ϵ,δ)-DP 意味着对于任何两个相邻的数据集 S, S' 和任意事件 E 满足 P(M(S)∈E))≤e^ϵ P(M(S' )∈E)+δ。具体来说,差分隐私通常会按以下方式工作。它会给每次查询的结果添加少量噪声以掩盖单个数据点的影响,然后跟踪并累积查询的隐私损失,直至达到总体隐私预算,之后便不再允许查询。为保证差分隐私所加入的噪声,可能会影响结果的准确性,但如果查询结果的维数较小,则不会有显著影响。
噪声扰动哪家强?
在机器学习过程中实现差分隐私的一种通用做法也是加噪声,即用噪声掩盖单个数据点的影响。机器学习的一般流程如图3中的上半部分所示:设计目标函数即经验风险最小化(Empirical Risk Minimization, ERM),然后训练过程一般是基于梯度的优化算法,最后输出训练好的模型。对应地,根据加噪声的时机,差分隐私机器学习(Differential Private Machine Learning) 有三种实现方法(如图3中的下半部分所示)——目标扰动(Objective Perturbation),即在目标函数上添加噪声;梯度扰动(Gradient Perturbation, GP),即在梯度上添噪声;输出扰动(Output Perturbation),即在最后输出上添加噪声。不过若添加的噪声很大,会带来模型的性能损失,但太小又不能很好地保护隐私。因此,差分隐私机器学习可以研究如何在给定隐私损失的要求下,添加最少的噪声取得最好的性能。
微软亚洲研究院与中山大学在最近的工作 Gradient Perturbation is Underrated for Differentially Private Convex Optimization [2] 中介绍了相关的研究工作,该论文被 IJCAI 2020 接收。研究员们发现在梯度扰动算法中加入的噪声和优化算法会相互影响,噪声会让优化算法避开最差曲率方向,而优化算法的收缩性则可以弱化之前步骤所添加的噪声。所以研究员们在分析中利用了这种相互影响,推导出了一个新的基于期望曲率的理论性能,可以显式地看出梯度扰动比另外两种扰动方式(目标扰动和输出扰动)的优势。梯度扰动依赖期望曲率,而目标扰动或输出扰动则依赖最差曲率,在实际中期望曲率往往比最差曲率大得多。研究员们还给出了另外两种扰动无法利用这种相互影响的原因——在目标扰动和输出扰动中,都需要确定单个数据点对最终学到的模型的影响(敏感度),这是由目标函数的 Lipschitz 系数和强凸系数决定,而这些系数又是由问题本身的特征所决定,与优化算法无关。据此,梯度扰动是一种实现差分隐私机器学习的有效算法。在之后的研究中,研究员们也会将重点放在梯度扰动算法(如 DP-SGD)方面。
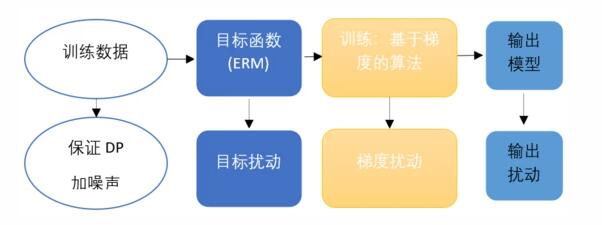
图3:机器学习流程,与其对应的添加噪声保证 DP 的三种方式
然而,在应用 DP-SGD 训练大规模深度神经网络模型时仍面临巨大挑战。由于差分隐私的性能有很差的维数依赖,模型参数越多,加入的噪声能量也越大,这就导致大模型的性能下降明显。而如今的深度学习模型都是由大量参数组成的,对于一个合理的隐私预算,应用 DP-SGD 训练的深度神经网络性能并不好。那么要如何克服 DP-SGD 的维数依赖问题?
模型大,维数高,保证 DP 再难也要上?
维数依赖性是应用差分隐私(DP)的一个本质困难。为了解决“维数”挑战,在最近的 ICLR 2021 论文 Do not let privacy overbill utility: gradient embedding perturbation for private learning [4] 中,微软亚洲研究院的研究员们提出了一种算法“梯度嵌入扰动(Gradient embedding perturbation, GEP)”。其基本想法是模型维数虽然很大,但梯度却通常在一个低维空间中,这不仅符合人们对数据生长在低维流形上的认知,也在实践中可以被广泛验证(图4)。利用这个性质,研究员们把模型梯度先投影到一个低维空间后再做扰动,从而巧妙地绕开了维数依赖。
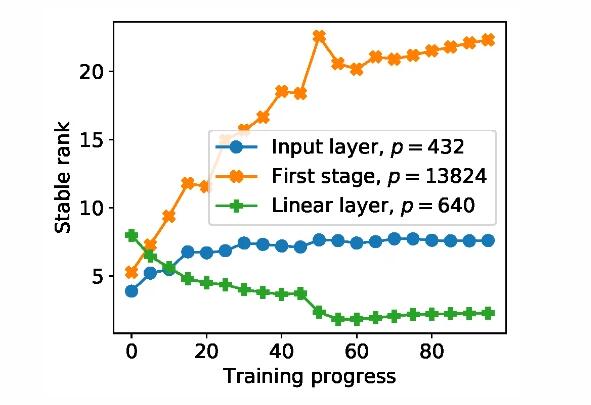
图4:梯度矩阵的稳定秩(p为参数维度),设置为 CIFAR-10 上的 ResNet20。在整个训练中,相比于参数维度,梯度矩阵的稳定秩都很小[4]。
具体来说(如图5所示),在每个梯度下降步中,首先用辅助数据估计一个锚子空间,然后将私有梯度投影到锚子空间,得到一个低维梯度嵌入和一个小范数的残余梯度,之后分别扰动梯度嵌入和残余梯度,以保证差分隐私预算。总的来说,可以使用比原来的梯度扰动低得多的扰动,以保证相同的隐私水平。
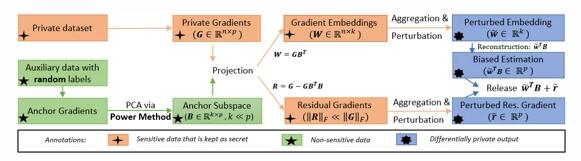
图5:梯度嵌入扰动 GEP 算法图示[4]
梯度嵌入扰动有哪些特征呢?首先,在梯度嵌入扰动中使用的非敏感辅助数据的假设比之前的工作[5,6]中使用的公开数据的假设弱得多——梯度嵌入扰动只需要少量非敏感无标记数据,并只要求其特征分布与私有数据相似,比如在实验中使用 ImageNet 的2000个降采样图像作为 MNIST、SVHN 和 CIFAR-10 数据集的辅助数据。其次,梯度嵌入扰动同时扰动低维梯度嵌入和残余梯度,这是目标梯度的无偏估计,也是取得好性能的关键。第三,使用幂法估计梯度矩阵的主成分,从而实现简单高效。
这种分解使用的噪声相对小很多,从而有助于打破隐私学习的维度障碍。借助梯度嵌入扰动,研究员们在合理的隐私预算下实现了深度模型较好的准确性。在隐私预算 ϵ=8 的情况下,实验在 CIFAR10 上达到了74.9%的测试准确度,并在 SVHN 上达到了95.1%的测试准确度,大大提高了现有结果(表2)。据目前所知,梯度嵌入扰动是首个从头训练而实现这种效果的算法,并且隐私预算只有"个位数"。如果使用 ImageNet 预训练模型,梯度嵌入扰动还可以在 CIFAR10 验证集上取得94.8%的准确率,详细信息请参考论文。
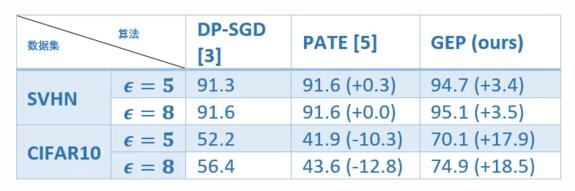
表2:不同算法在 SVHN 和 CIFAR10 测试集准确率
通过对隐私攻击更深入的研究以及利用训练深度神经网络模型时梯度的低秩属性,微软亚洲研究院的研究员们正在努力把隐私保护应用到深度神经网络模型中,让用户即使在处理敏感数据时也可以安全地使用现代机器学习技术。研究员们认为,隐私保护并不会限制机器学习的性能,因为它们从根本上并不冲突——隐私保护个体,学习挖掘整体。未来,相信隐私保护研究可以让可利用的“燃料”(海量数据)得到更大的释放,人工智能的边界和性能也将因此得以拓展和提高。



















