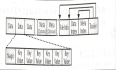
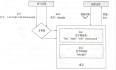
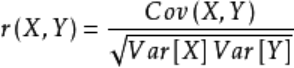Flink 没有类似于 spark 中 foreach 方法,让用户进行迭代的操作。虽有对外
Hive on spark时报错 解决a.set spark.yarn.executor.memoryOverhead=512G 调大(权宜之计),excutor-momery + memoryOverhead不能大于集群内存b.该问题的原因是因为OS层面虚拟内存分配导致,物理内存没有占用多少,但检
HBase-存储-HFile格式 实际的存储文件功能是由HFile类实现的,它被专门创建以达到一个目的:有效地存储HBase的数据。它们基于Hadoop的TFile类,并模仿Google的BigTable架构使用的SSTable格式。文件格式的详细信息如下图 这些文件是可变长度的,唯一固定的块是Fi
ES-在集群中加入节点 查看分片信息 Music索引有5个主分片,而且都是激活的。未分配的分片代表为该索引配置的一组副本分片。因为只有1个节点,所以这些副本分片尚未分配 多数ES API会返回JSON,但是cat这组API是个特例。还有很多其他的API,它们对于获取集群某个时间点的相关信息很有帮助,
ES-配置 ES可以轻松地、高效地扩展,当处理大量的数据或者请求的时候,这一点是非常重要的。使用集群时需要修改的配置1.在elasticsearch.yml中指定集群的名称-这是ES具体选项所在的主要配置文件2.在logging.yml中编辑日志选项-日志配置文件包括log4j的日志选项,ES使用这
Elasticsearch-如何控制存储和索引文档(_source、_all) _source:可以在索引中存储文档。_all:可以在单个字段上索引所有内容。 1. 存储原有内容的_source _source字段按照原有格式来存储原有的文档。这一点可以看到匹配某个搜索的文档,而不仅仅是他们的ID。
ES-识别文档 为了识别同一个索引中的某篇文档,ES使用_uid中的文档类型和ID结合体。_uid字段是由_id和_type字段组成,当搜索或者检索文档的时候总是能获得这两项信息。 由于所有的文档都位于同一个Lucene的索引中,ES内部使用_uid来唯一确定文档的身份。类型和ID的分离是一种抽象,
ES-更新现有文档 ES的更新API允许发送文档所需要做的修改,而且API会返回一个答复,告知操作是否成功。更新流程如下 1. 检索现有的文档。为了使这步奏效,必须打开_source字段,否则ES并不知道原有文档的内容。2. 进行制定的修改。例如,如果文档是{"name":"Elasticsearc
ES-深入功能ES中数据是如何组织的?逻辑设计:用于索引和搜索的基本单位是文档,可以将其认为是关系数据库里的一行。文档以类型来分组,类型包含若干文档,类似表格包含若干行。最终,一个或多个类型存在于同一索引中,索引是更大的容器,类似数据库。物理设计:ES将每个索引划分为分片,每份分片可以在集群中的不同
HBase-存储-KeyValue格式 本质上,HFile中的每个KeyValue都是一个低级的字节数组,它允许零复制访问数据。 KeyValue格式如下 该结构以两个分别表示键长度(Key Length)和值长度(Value Length)的定长数字开始。有了这个信息,用户就可以在数据中跳跃,例如
ZooKeeper安装和运行 1. 下载安装包 zookeeper-3.4.9.tar.gz 2. 解压 tar -zxvf zookeeper-3.4.9.tar.gz ZooKeeper提供了几个能够运行服务并与之交互的二进制可执行文件,可以很方便地将包含这些二进制文件的目录加入命令行路径 3.
错误如下 解决 修改命令如下
ES-安装、日志解读 1. 准备tar包 https://www.elastic.co/cn/products/elasticsearch2. 解压 3. 启动 启动日志如下 4.日志解读: (1)第一行提供了启动节点的统计信息 默认情况下,ES为节点随机分配一个名字,可以在配置中修改。此处我修改为
Yarn-本地获取任务日志
ES-用于定义文档字段的核心类型 ES中一个字段可以是核心类型之一,如字符串、数值、日期、布尔型,也可以是一个从核心类型派生的复杂类型,如数组。 字符串类型 索引一类型为字符串的数据doc1: doc2: 在name字符串字段里搜索单词late 索引过程和搜索过程如下 当索引"name":"Late
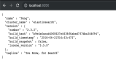
Elasticsearch-搜索并获取数据 在group中搜索elasticsearch curl -XGET "localhost:9200/get-together/group/_search?\ > q=elasticsearch\ > &fields=name,location\ > &si
Elasticsearch-数值类型 数值类型可以是浮点数,也可以是费浮点数。如果不需要小数,可以选择byte、short、int或者long.如果确实需要小数,可以选择float和double。这些类型对应于Java的原始数据类型,对于他们的选择将会影响索引的大小,以及能够索引的取值范围。例如,l
ES-使用映射来定义各种文档 每篇文档属于一种类型,而每种类型属于一个索引。从数据的逻辑划分来看,可以认为索引是数据库,而类型是数据库中的表。类型包含了映射中每个字段的定义。映射包括了该类型的文档中可能出现的所有字段,并告诉ES如何索引一篇文档的多个字段。 类型只提供逻辑上的分离:在ES中,不同类型
Elasticsearch-日期类型 date类型用于存储日期和时间。它是这样运作的:通常提供一个表示日期的字符串,例如2019-06-25T22:47。然后,E
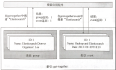
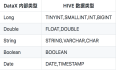
DataX操作HDFS 读取HDFS 1 快速介绍 HdfsReader提供了读取分布式文件系统数据存储的能力。在底层实现上,HdfsReader获取分布式文件系统上文件的数据,并转换为DataX传输协议传递给Writer。目前HdfsReader支持的文件格式有textfile(text)、orc
ES-删除数据 删除单个文档或者一组文档。这样做的时候,ES只是将它们标记为删除,所以它们不会再出现于搜索结果中,稍后ES通过异步的
可以将ZK看作一个具有高可用性特征的文件系统。这个文件系统中没有文件和目录,而是统一使用节点(znode)的概念,称为znode。znode既可以作为保存数据的容器(如同文件),也可以作为保存其他znode的容器(如同目录)。所有的znode构成了一个层次化的命名空间,一种自然的建立组成员列表的方式
DataX的安装 1. 可下载tar包 https://github.com/alibaba/DataX/blob/master/userGuid.md 2. 下载源码自己编译 git clone https://github.com/alibaba/DataX.git打包mvn -U clean
DataX操作MySQL 一、 从MySQL读取 介绍 MysqlReader插件实现了从Mysql读取数据。在底层实现上,MysqlReader通过JDBC连接远程Mysql数据库,并执行相应的sql语句将数据从mysql库中SELECT出来。不同于其他关系型数据库,MysqlReader不支持F
机器学习-随机性、概率论、多元统计、特征间的相关性 随机性 洛伦兹动力学方程:美国气象学家洛伦兹建立了一个描述大气对流状况的数学模型。 洛伦兹动力学方程描绘出的运动轨迹具有一种奇特的形状,像一只展开了双翼的蝴蝶,所以又称为蝴蝶效应。 在这个蝴蝶上,确定性和随机性被统一在一起:一方面,运动的轨迹必然落
挖掘频繁模式、关联和相关性:基本概念和方法 频繁模式(frequent pattern)是频繁地出现在数据集中的模式(如项集、子序列或子结构)。 例如,频繁地同时出现在交易数据集中的商品(如牛奶和面包)的集合是频繁项集。 一个子序列,如首先购买PC,然后是数码相机,再后是内存卡,如果它频繁地出现在购
机器学习-文本分类实例-朴素贝叶斯 1.准备训练样本 使用的复旦大学文本分类样本数据 2.训练模型 3.准备测试数据 4.分类 训练模型 import os import jieba #Bunch类 from sklearn.datasets.base import Bunch import pic
在学习sqoop job之前,最好先学习一下sqoop命令的导入导出 sqoop 使用 import 将 mysql 中数据导入到 hive sqoop 使用 import 将 mysql 中数据导入到 hdfs sqoop 使用 export 将 hive 中数据导出到 mysql sqoop j
机器学习-各类距离的定义 两个向量之间的距离(此时向量作为n维坐标系中的点)计算,在数学上称为向量的距离(distance),也称为样本之间的相似性度量(Similarity Measurement) 它反映为某类事物在距离上接近或远离的程度。直觉上,距离越近的就越相似,越容易归为一类;距离越远就越
ES-数组和多字段 当需要在同一个字段中需要拥有多个值时,就会用到数组。 数组 如果要索引拥有多个值的字段,将这些值放入方括号中即可。在music索引下的album类型中,添加songs字段,存储专辑下的歌曲列表 FengZhendeMacBook-Pro:bin FengZhen$ curl -X
Copyright © 2005-2024 51CTO.COM 版权所有 京ICP证060544号