Flink 没有类似于 spark 中 foreach 方法,让用户进行迭代的操作。虽有对外
Hive on spark时报错 解决a.set spark.yarn.executor.memoryOverhead=512G 调大(权宜之计),excutor-momery + memoryOverhead不能大于集群内存b.该问题的原因是因为OS层面虚拟内存分配导致,物理内存没有占用多少,但检
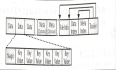
HBase-存储-HFile格式 实际的存储文件功能是由HFile类实现的,它被专门创建以达到一个目的:有效地存储HBase的数据。它们基于Hadoop的TFile类,并模仿Google的BigTable架构使用的SSTable格式。文件格式的详细信息如下图 这些文件是可变长度的,唯一固定的块是Fi
ES-在集群中加入节点 查看分片信息 Music索引有5个主分片,而且都是激活的。未分配的分片代表为该索引配置的一组副本分片。因为只有1个节点,所以这些副本分片尚未分配 多数ES API会返回JSON,但是cat这组API是个特例。还有很多其他的API,它们对于获取集群某个时间点的相关信息很有帮助,
ES-配置 ES可以轻松地、高效地扩展,当处理大量的数据或者请求的时候,这一点是非常重要的。使用集群时需要修改的配置1.在elasticsearch.yml中指定集群的名称-这是ES具体选项所在的主要配置文件2.在logging.yml中编辑日志选项-日志配置文件包括log4j的日志选项,ES使用这
Elasticsearch-如何控制存储和索引文档(_source、_all) _source:可以在索引中存储文档。_all:可以在单个字段上索引所有内容。 1. 存储原有内容的_source _source字段按照原有格式来存储原有的文档。这一点可以看到匹配某个搜索的文档,而不仅仅是他们的ID。
ES-识别文档 为了识别同一个索引中的某篇文档,ES使用_uid中的文档类型和ID结合体。_uid字段是由_id和_type字段组成,当搜索或者检索文档的时候总是能获得这两项信息。 由于所有的文档都位于同一个Lucene的索引中,ES内部使用_uid来唯一确定文档的身份。类型和ID的分离是一种抽象,
ES-更新现有文档 ES的更新API允许发送文档所需要做的修改,而且API会返回一个答复,告知操作是否成功。更新流程如下 1. 检索现有的文档。为了使这步奏效,必须打开_source字段,否则ES并不知道原有文档的内容。2. 进行制定的修改。例如,如果文档是{"name":"Elasticsearc
ES-深入功能ES中数据是如何组织的?逻辑设计:用于索引和搜索的基本单位是文档,可以将其认为是关系数据库里的一行。文档以类型来分组,类型包含若干文档,类似表格包含若干行。最终,一个或多个类型存在于同一索引中,索引是更大的容器,类似数据库。物理设计:ES将每个索引划分为分片,每份分片可以在集群中的不同
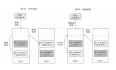
HBase-存储-KeyValue格式 本质上,HFile中的每个KeyValue都是一个低级的字节数组,它允许零复制访问数据。 KeyValue格式如下 该结构以两个分别表示键长度(Key Length)和值长度(Value Length)的定长数字开始。有了这个信息,用户就可以在数据中跳跃,例如
ZooKeeper安装和运行 1. 下载安装包 zookeeper-3.4.9.tar.gz 2. 解压 tar -zxvf zookeeper-3.4.9.tar.gz ZooKeeper提供了几个能够运行服务并与之交互的二进制可执行文件,可以很方便地将包含这些二进制文件的目录加入命令行路径 3.
错误如下 解决 修改命令如下
ES-安装、日志解读 1. 准备tar包 https://www.elastic.co/cn/products/elasticsearch2. 解压 3. 启动 启动日志如下 4.日志解读: (1)第一行提供了启动节点的统计信息 默认情况下,ES为节点随机分配一个名字,可以在配置中修改。此处我修改为
Yarn-本地获取任务日志
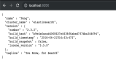
ES-用于定义文档字段的核心类型 ES中一个字段可以是核心类型之一,如字符串、数值、日期、布尔型,也可以是一个从核心类型派生的复杂类型,如数组。 字符串类型 索引一类型为字符串的数据doc1: doc2: 在name字符串字段里搜索单词late 索引过程和搜索过程如下 当索引"name":"Late
Copyright © 2005-2024 51CTO.COM 版权所有 京ICP证060544号