
2.2 多元变量
二元变量可以描述两种可能中取其中一种情况的值的数量,然而,我们遇到的离散变量往往可以从K种相互排斥的状态中取值。尽管有很多可选择的方法来表示这种变量,但我们采用特别方便的1-K组合表示方法,该方法中的变量由一个K维的向量X表示,向量中只有一个元素为1,其余的都取值为0.比如,我们有一个K=6状态的变量和该变量的一次特定观察,在该观察中碰巧符合状态3取值为1即x3=1,那么X可表示为:

注意,这种向量满足

这里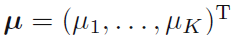 ,因为参数uk表示概率,所以严格满足 uk≧0 而且
,因为参数uk表示概率,所以严格满足 uk≧0 而且
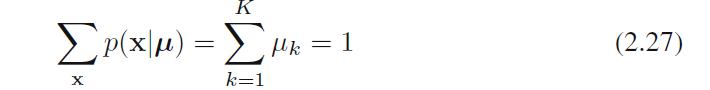
而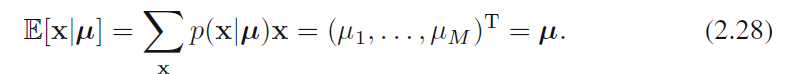
现在考虑一个N次独立观察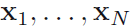 的数据集
的数据集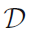 。它的似然函数响应为:
。它的似然函数响应为:
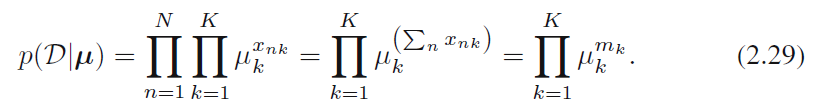
可见,似然函数仅取决于N个数据点上的K的数量

表示观察中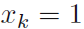 的次数。这些称为该分布的充分统计量(sufficient statistics)。
的次数。这些称为该分布的充分统计量(sufficient statistics)。
为了计算出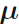 的最大似然解,在考虑
的最大似然解,在考虑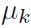 必须满足和为1的限制下对每个使得
必须满足和为1的限制下对每个使得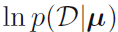 值最大。这可以通过拉格朗日乘子(Lagrange multiplier)
值最大。这可以通过拉格朗日乘子(Lagrange multiplier)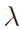 和最大化
和最大化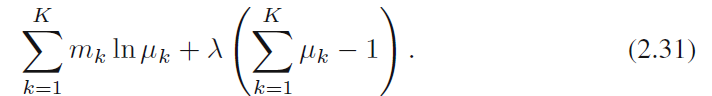
对每个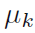 使得(2.31)的导数为0,得到:
使得(2.31)的导数为0,得到:
将(2.32)式带入约束条件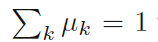 可以解得
可以解得 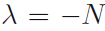 。由此,最大似然解为:
。由此,最大似然解为:

它正好是N次观察中xk=1的所占的比例。
在参数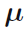 以及总的观察次数N的条件下,来考虑
以及总的观察次数N的条件下,来考虑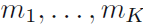 的联合分布。从(2.29)可知该条件分布的形式为
的联合分布。从(2.29)可知该条件分布的形式为
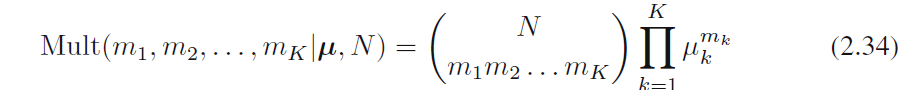
它被称为多元分布。归一化参数是N个对象分成K个大小为m1,m2,…,mk组,它表示为
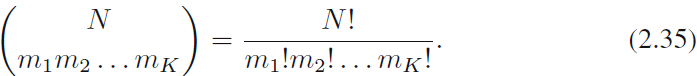
注意变量mk服从约束



















