背景由于 CDH6.3.2 以上,已不开源。常用组件只能自编译升级,比如 Spark 。看网上的资料,有人说 Spark3 的 SQL 运行性能比 Spark2 可提升 20%,本人未验证,但是 Spark3 的 AE 功能的确很香,能自适应解决 Spark SQL 的数据倾斜。下载软件软件版本:jdk-1.8、maven-3.8.4、scala-2.12.15 、spark-3.3.0说明:ma
环境原IP目标IP迁移的服务备注192.168.11.20192.168.11.23nebula-metadnebula-graphdnebula-storaged服务部署目录/opt/nebulagraph数据存储目录/data/nebula192.168.11.21192.168.11.24192.168.11.22192.168.11.25迁移前的准备操作系统和环境要保持一致系统存储的目录要
第一部分:字符集规范【强制】数据库字符集指定utf-8,并且只支持utf-8。 命令规范【建议】库名统一使用小写方式,中间用下划线(_)分割,长度62字节内【建议】表名称大小写敏感,统一使用小写方式,中间用下划线(_)分割,长度64字节内第二部分:建表规范【强制】确保每个tablet大小为1-3G之间。举例:假设表内单分区数据量在100G,按天分区,bucket数量100个。【强烈建议】
由于Impala 的 Automatic Invalidate/Refresh Metadata的功能在CDH6.3版本才有的功能,通过以上两个升级,已经具备的该功能,下面是需要配置该功能测试环境1.CM和CDH版本为6.1.1(hive的版本升级到了CDH6.3.2-2.1.1)2.操作系统版本为RedHat 7.63.impala3.4版本操作步骤进入CM界面 > Hive > 配
1.在hive创建数据库的情况下,impala无法自动刷新元数据1.1 发现问题在CDH6.1版本下创建数据库, 如在hive中create database test_db; 再在impala中 show databases;没有显示test_db,说明test_db并没有刷新到Impala的catalog中,通过查找Impala Catalog的role log,发现如下的异常日志:Unexp
因为我的CDH平台用的是虚拟机跑的,上面部署的服务太多了,在重启namenode以后出现down的状态,一直起不来,后来查看error日志,报以下错误:Namenode报 failed; error=‘Cannot allocate memory‘ (errno=12)一、解决办法:由于报错os::commit_memory(0x00000000fec00000, 20971520, 0),但是经
Starrocks是什么,它与其他OLAP数据库的区别是什么?Starrocks是一种分布式列式存储的MPP(Massively Parallel Processing)OLAP数据库,能够支持PB级别的数据存储和查询。与传统的基于Hadoop的OLAP系统相比,Starrocks具有以下几点优势:灵活的存储格式:Starrocks使用列式存储,可以根据数据特点和查询需求进行灵活的存储格式选择,从
升级集群您可以通过滚动升级的方式平滑升级 StarRocks。StarRocks 的版本号遵循 Major.Minor.Patch 的命名方式,分别代表重大版本,大版本以及小版本。注意由于 StarRocks 保证 BE 后向兼容 FE,因此您需要先升级 BE 节点,再升级 FE 节点。错误的升级顺序可能导致新旧 FE、BE 节点不兼容,进而导致 BE 节点停止服务。StarRocks 2.0 之
Starrocks默认是100个表分区,如果超过这个时间,动态分区创建之后会被自动删除解决方案:ALTER TABLE dwd_iov_test SET ("dynamic_partition.start" = "-2000");使用表分区漂移变成2000动态分区动态分区功能开启后,您可以按需为新数据动态地创建分区,同时 StarRocks 会⾃动删除过期分区,从而确保数据的时效性。创建支持动态分
现象:FE节点上安装了KVM之后,虚拟网卡多了一个192.168.12.1的地址,导致FE在重启的时候无法找到元数据的故障,报错如下2023-02-15 09:53:22,082 WARN (UNKNOWN 10.172.128.77_9015_1667993591722(-1)|1) [BDBJEJournal.open():319] catch exception, retried: 0 co
ERROR 1105 (HY000): errCode = 2, detailMessage = NoClassDefFoundError: Could not initialize class org.apache.doris.catalog.PrimitiveType这个报错是jar包的问题1.下载此java-udf-jar-with-dependencies.jarhttps://jia
2023-01-13 09:50:07,603 ERROR (main|1) [BDBEnvironment.setup():233] error to open replicated environment. will exit.com.sleepycat.je.EnvironmentFailureException: (JE 7.3.7) 10.179.110.250_9015_1653712
设置密码jupyter notebook password设置配置文件jupyter notebook --generate-configc.NotebookApp.allow_root =Truec.NotebookApp.ip = '*'c.NotebookApp.open_browser = Falsec.NotebookApp.password='sha1:31aa1f72a166:6e5
org.apache.hive.com.esotericsoftware.kryo.KryoException: java.lang.ArrayIndexOutOfBoundsException: -2
1.备份hue.makocp -rf /opt/cloudera/parcels/CDH/lib/hue/desktop/core/src/desktop/templates/hue.mako /opt/cloudera/parcels/CDH/lib/hue/desktop/core/src/desktop/templates/hue.mako.bak2.打开hue.mako文件vim /opt
hive.server2.session.check.intervalhive.server2.idle.operation.timeout 中配置以下设置。hive.server2.idle.session.timeout1). hive.server2.idle.session.timeout会话将在这段时间内未访问时关闭,以毫秒为单位;通过设置为零或负值来禁用。例如,值“86400000”指
HiveServer2 是一个节俭服务器,它是一个精简的服务层,以无缝的方式与 HDP 集群进行交互。它同时支持 JDBC 和 ODBC 驱动程序,以提供用于查询数据的 SQL 层。传入的 SQL 查询将转换为 TEZ 或 MR 作业,获取结果并将其发送回客户端。HS2内部无需进行繁重的起重工作。它只是充当一个拥有 TEZ/MR 驱动程序、扫描元数据和应用护林员策略进行授权的地方。HiveServ
原因是因为session不释放导致的解决方案:需要设置的参数会话检查间隔hive.server2.session.check.interval=5分钟空闲操作超时hive.server2.idle.operation.timeout=0空闲会话超时hive.server2.idle.session.timeout=0重启hiveserver2问题解决
报错代码如下:Encountered exception loading fsimagejava.io.IOException: NameNode is not formatted. at org.apache.hadoop.hdfs.server.namenode.FSImage.recoverTransitionRead(FSImage.java:237) at org.apache.
异常日志022-10-09 10:26:16,230 ERROR org.apache.hadoop.hdfs.qjournal.server.JournalNode: Failed to start journalnode.org.apache.hadoop.security.KerberosAuthException: failure to login: for principal: jn/h
1、比较函数 = <> > >= < <= 注意:select null=null; 返回为null IS NULL 、 IS NOT NULL --非空判断 value1 IS DISTINCT FROM value2、value1 IS NOT DISTINCT FROM value2、
报错内容如下:2022-09-29T10:19:39,785 ERROR [be6bd8ac-4a04-4f23-ac2a-540949dea68a main] metadata.HiveMetaStoreChecker: org.apache.hadoop.hive.ql.metadata.HiveException: Unexpected partition key hour found at
公司的数据变更字段时出现以下报错:java.net.SocketTimeoutException: Read timed out原因:hive.metastore.client.socket.timeout的值,目前是300。 解决方案:hive.metastore.client.socket.timeout的值,改为1000。
公司用的是原生的Hadoop,执行hadoop fs -ls /的时候出现以下hadoop的配置打印出来 原因是因为hadoop的文件中别人在前面加了set -x解决方案:vim /opt/hadoop/bin/hadoop把set -x改为set +x问题解决
Presto查询的时候报错User: wangyx@XXX.COM is not allowed to impersonate wangyx2022-09-19T14:37:42.936+0800 DEBUG query-execution-1 com.facebook.presto.execution.QueryStateMachine Query 20220919_0637
hive3.1.2用的cdh6.3.2中自带的spark2.4,在beeline客户端中,切换执行引擎为spark报错,报错为加载配置文件报加载不到解决方案检查了hive-site.xml文件,缺了一个配置,就是spark.yarn.jars
安装presto的时候,报jdk版本不兼容的问题解决方案,提示最低需要java 8u151及以上版本vim /data/presto/bin/launcher export JAVA_HOME=/opt/jdk1.8.0_151export PATH=$JAVA_HOME/bin:$PATHjava -versionexec "$(dirname "$0")/launcher.py" "$@" #
提示check failure stack trace解决方案:主要的原因是因为配置的问题,更改为正确的配置后,问题解决
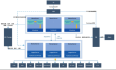
架构设计1.1系统架构图1.2启动流程图1.3架构说明MasterServerMasterServer采用分布式无中心设计理念,MasterServer主要负责 DAG 任务切分、任务提交监控,并同时监听其它MasterServer和WorkerServer的健康状态。 MasterServer服务启动时向Zookeeper注册临时节点,通过监听Zookeeper临时节点变化来进行容错处
Copyright © 2005-2025 51CTO.COM 版权所有 京ICP证060544号