一、Jvm参数在zookeeper/conf创建java.env文件,以16G内存为例export JVMFLAGS="-Xms8G -Xmx8G -Xmn4G -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:/data/zkout/gc/gc-%t.log $JVMFLAGS" 二、日志滚动1.conf/log4j.properties调整
背景突然收到电话告警,RocketMQ集群的cpu被打到90%以上,马上打开监控系统查看下,cpu直线上升硬盘I/O也在狂飙集群中只有两个节点的cpu暴涨,通过集群信息查下,发现是集群中的两个从节点的cpu暴涨。(我们的集群是4主4从,2个节点部署在同一台机器上,为了省钱)。虽然从节点cpu暴涨不影响整个集群的正常tps写入,还得要清楚是啥原因造成的cpu暴涨。找到对应的集群业务负责人,询问有什么
背景收到业务人员反馈,延迟30s的消息,到时间还没有正常被消费,于是登陆到broker节点上去查看日志,有个ERROR级别的报错:#vim rocketmq-log/stats.log ScheduleMessageService, a message time up, but reput it failed, topic: SCHEDULE_TOPIC_XXXX msgId 016F51324
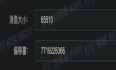
背景公司有一个topic,消费者160个,都使用了tag来过滤消息,在压测的时候,发现有一个问题,consumerA的积压值在不停的变化,触发了积压告警。而且实际上生产者并没有发送consumerA所使用的tag,理论上不应该有积压才对。在平台上看consumerA的积压情况,到集群通过命令行查看也是一样都显示积压。原因分析假如消费者在消费offset=100的这条tag1消息后,后面连续出现10
Copyright © 2005-2024 51CTO.COM 版权所有 京ICP证060544号