1. 搭建专用网络
1.1 登录专有网络管理控制台
阿里云Elasticsearch是搭建在专有网络上的,所以我们先开通阿里云专有网络, 点击开通 .
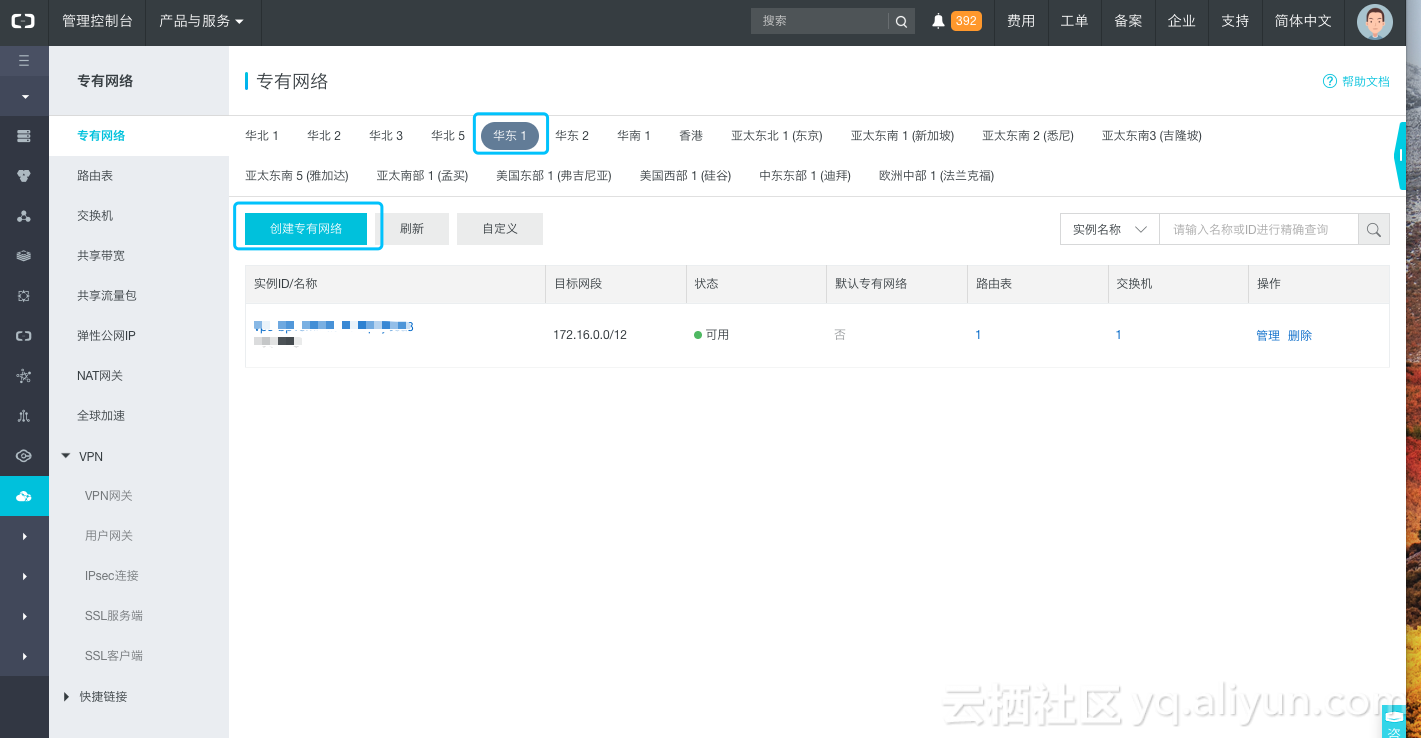
1.2 创建专有网络
点击创建专有网络
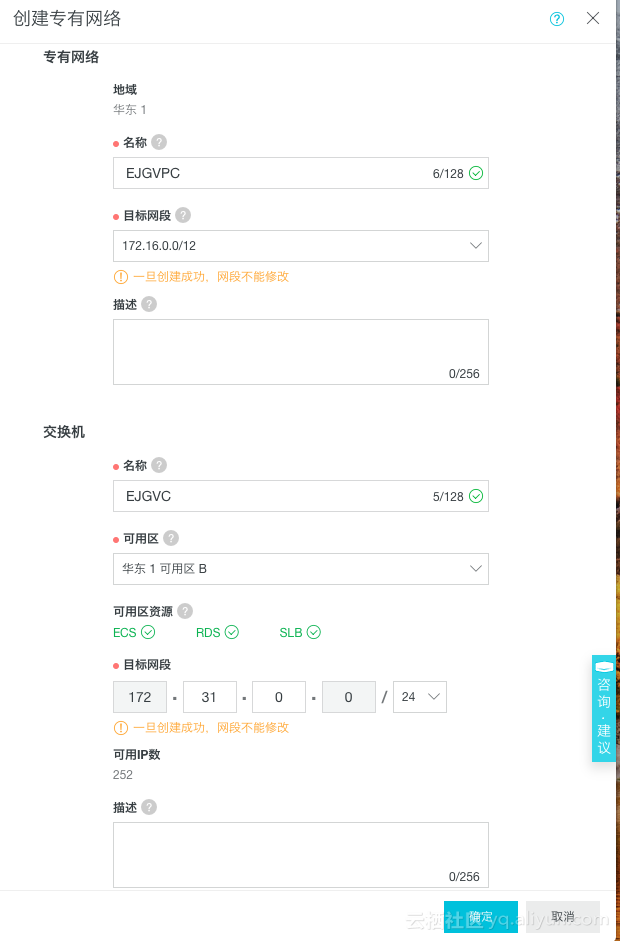
在专有网络名称和交换机上写好名字,后续在购买es和ecs时候对应需要。
参考链接:https://helpcdn.aliyun.com/document_detail/65430.html
2. 购买Elasticsearch服务
2.1 购买入口
2.2 购买服务
在订单页面上选择已经创建的专有网络并设置登录密码
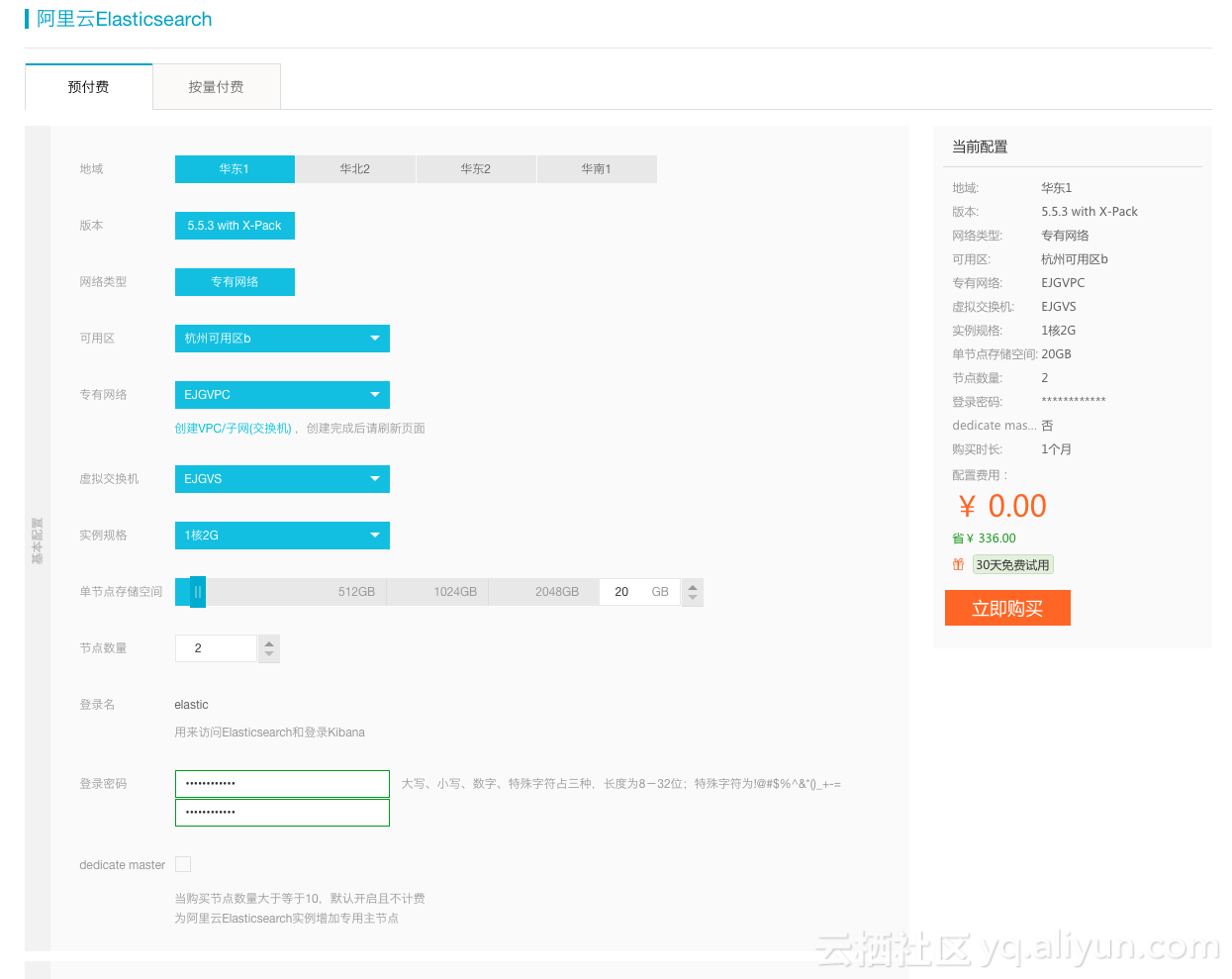 购买页面的登录账号默认为“elastic”,密码可自行设置,与登录Kibana的账号密码是一致的。
购买页面的登录账号默认为“elastic”,密码可自行设置,与登录Kibana的账号密码是一致的。
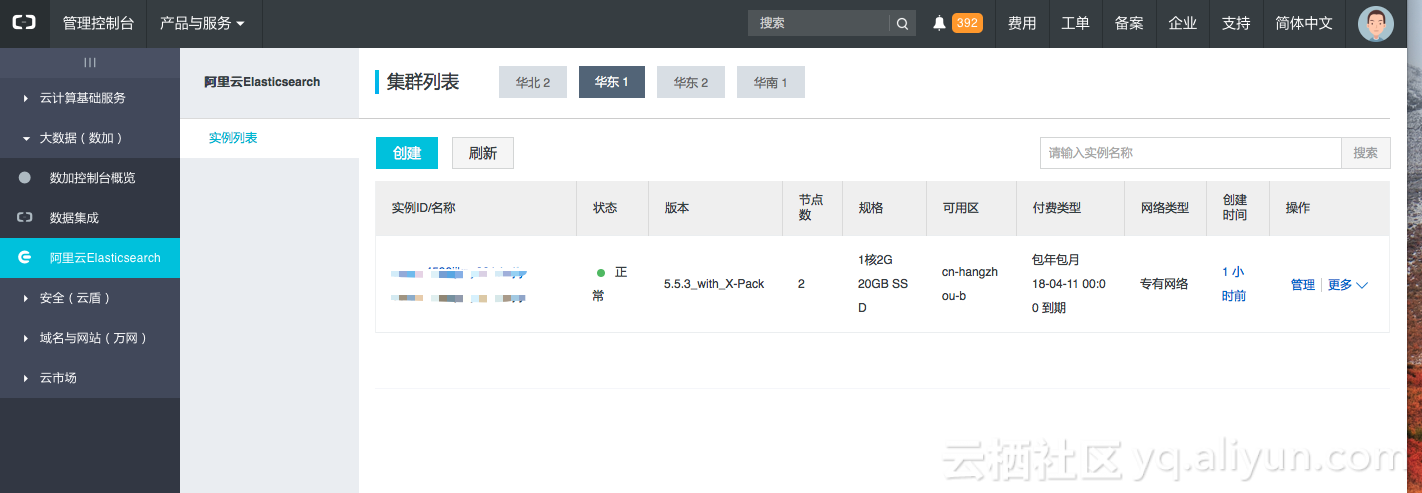
2.3 控制台查看状态
成功购买之后进入阿里云控制台选择大数据(数加)->阿里云Elasticsearch
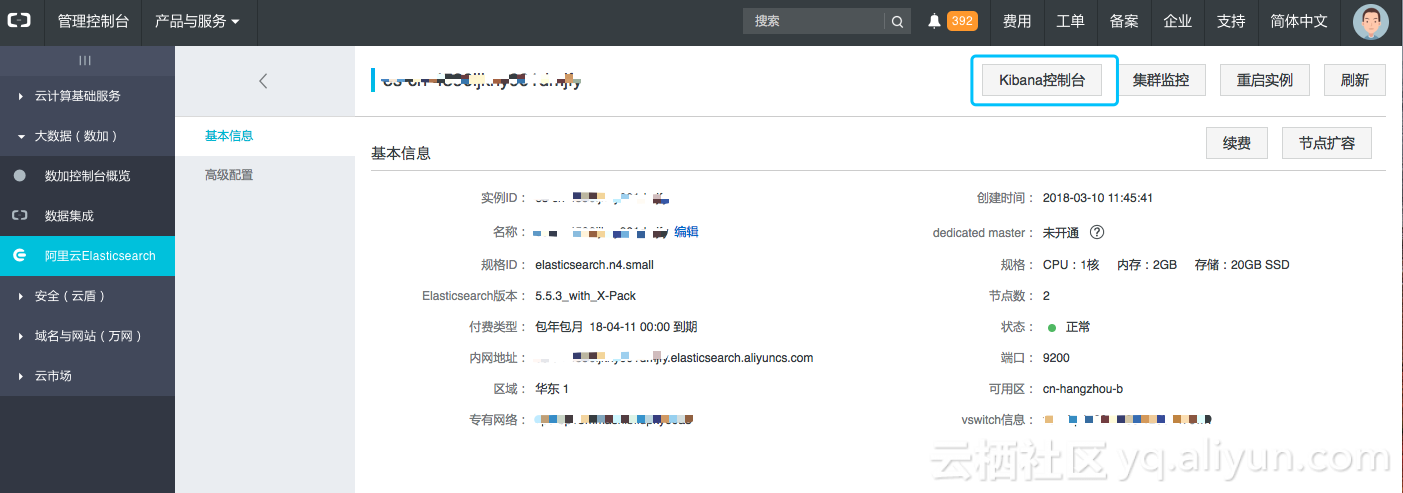
2.4 登录kibana控制台
从控制台点击实例之后可以看到kibana控制台,并用购买时候的用户名和密码进行登录
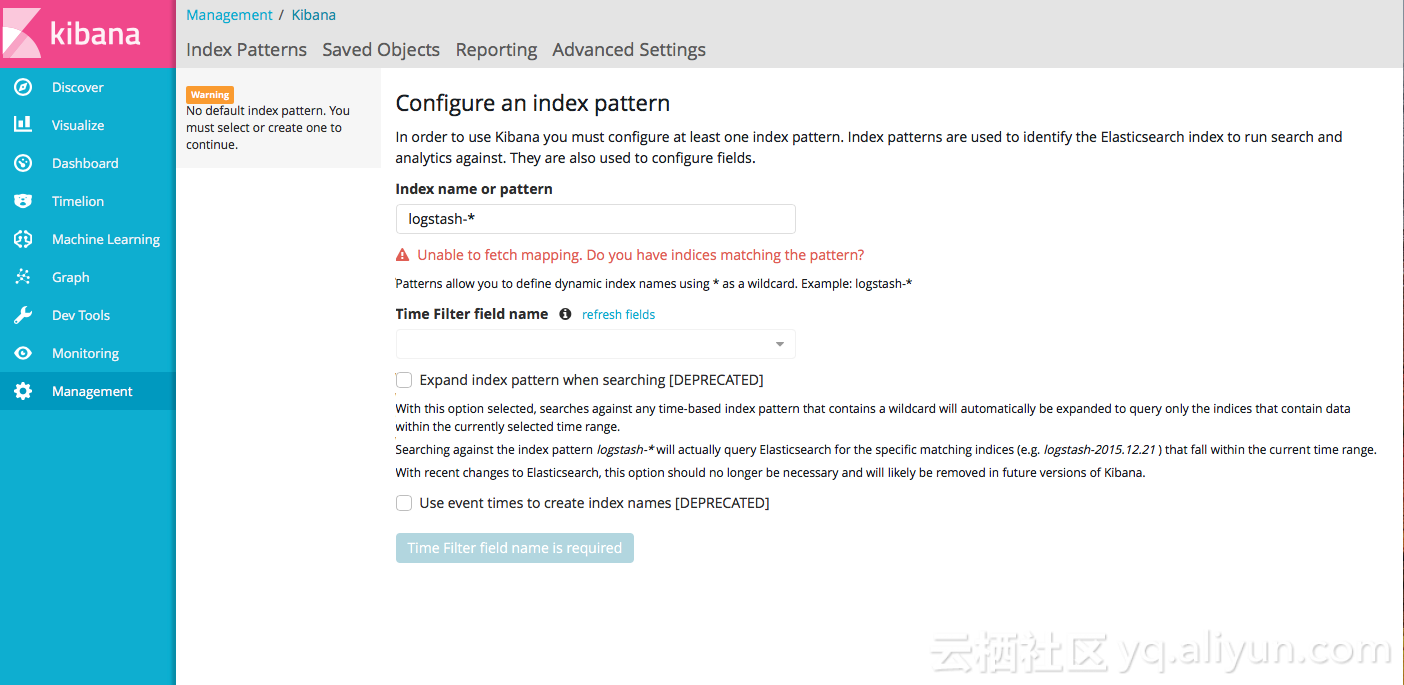
2.5 测试Elasticsearch
通过以上步骤已经创建了Elasticsearch实例,做简单的测试可以通过Kibana的DevTools进行命令发送,但在此我们为了通过logstash抓取日志并推送到es中,因此还需要购买ecs实例安装logstash并与elasticsearch打通。
[点击参考详细测试步骤]( https://help.aliyun.com/document_detail/57877.html)。
3. 购买ECS实例
在专有网络控制台选择交换机,并选择购买ECS实例
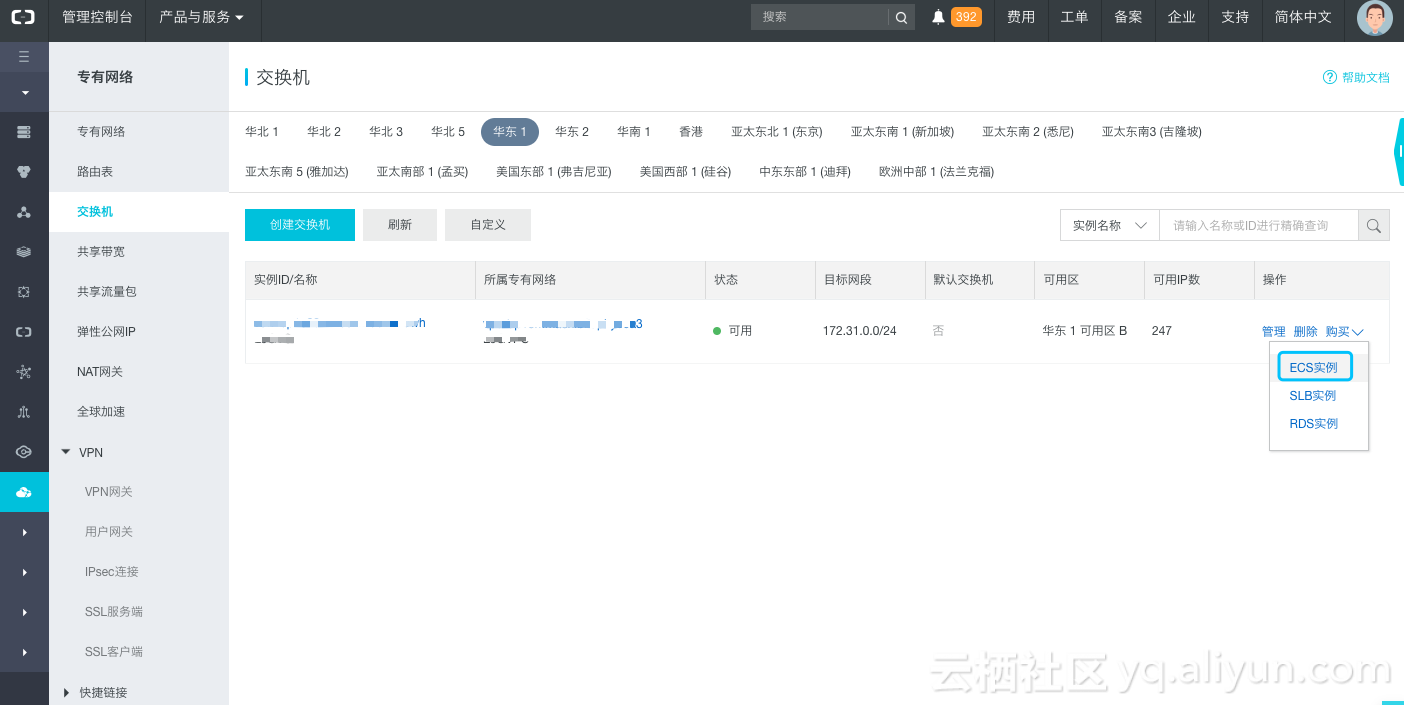
购买ecs步骤省略。
ssh root@49.52.196.12
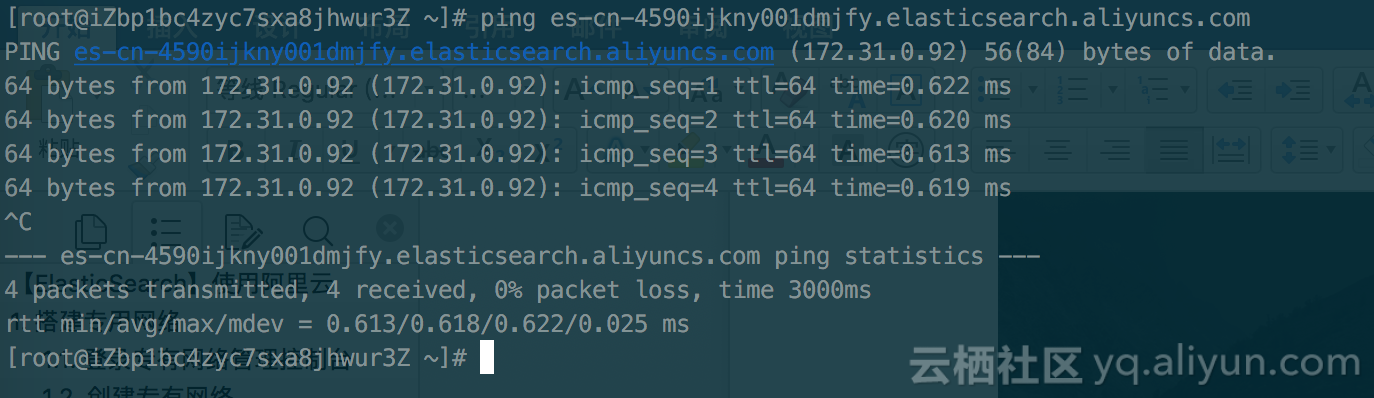
测试是否与es网络通畅
4. 安装logstash
4.1 安装logstash

wget https://artifacts.elastic.co/downloads/logstash/logstash-5.5.3.tar.gz
tar -xzvf logstash-5.5.3.tar.gz
mv logstash-5.5.3 /usr/share/
ln –sf /usr/share/logstash/bin/logstash /bin/4.2 创建索引
因为阿里云默认关闭了elasticsearch的自动创建索引功能,因此需要先创建好索引
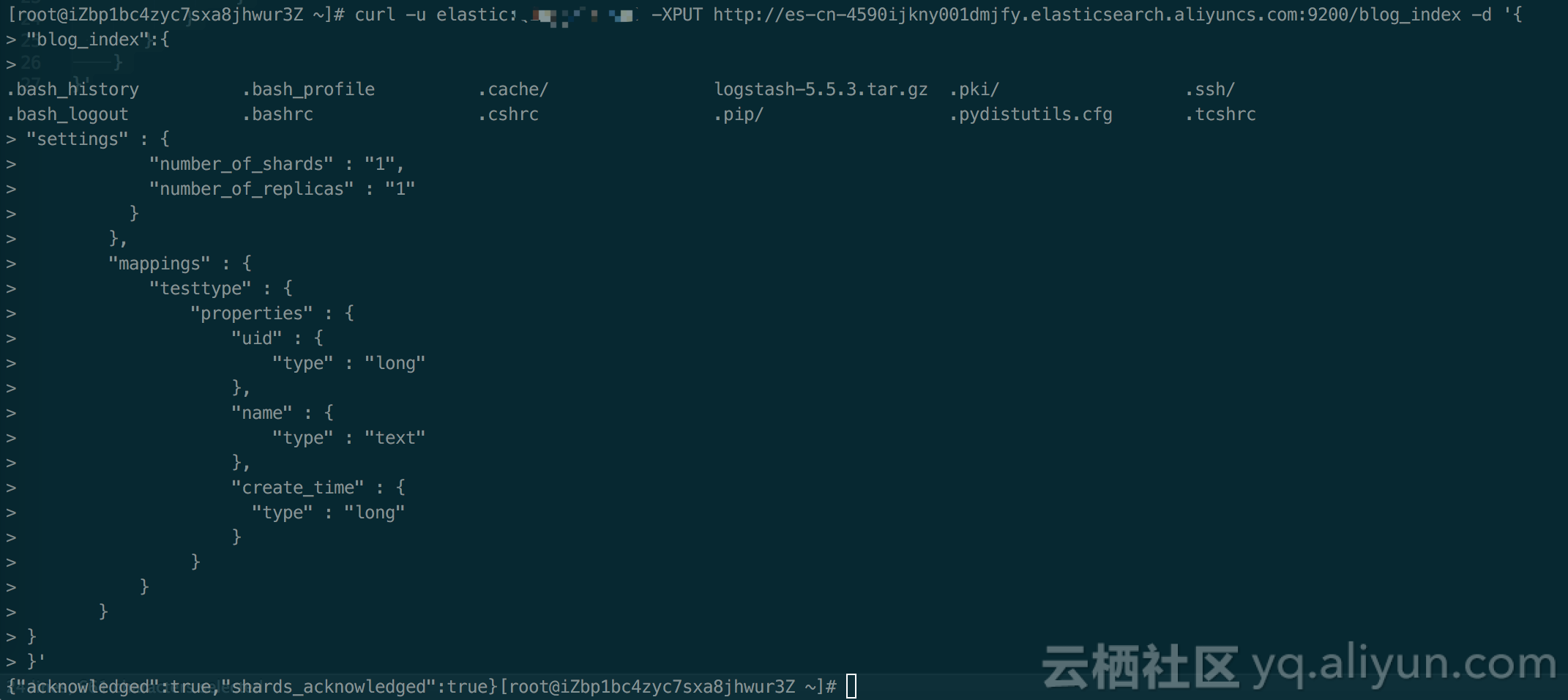
curl -u elastic:elastic -XPUT http://es-cn-4590ijkny001dmjfy.elasticsearch.aliyuncs.com:9200/blog_index -d '{
"blog_index":{
"settings" : {
"number_of_shards" : "1",
"number_of_replicas" : "1"
}
},
"mappings" : {
"blog_type" : {
"properties" : {
"uid" : {
"type" : "long"
},
"name" : {
"type" : "text"
},
"create_time" : {
"type" : "long"
}
}
}
}
}
}'
4.3 添加文档
curl -u elastic:elastic -XPOST http://es-cn-4590ijkny001dmjfy.elasticsearch.aliyuncs.com:9200/blog_index/blog_type -d '{"uid":100000, "name": "ruby","create_time":12121212121}'
{"_index":"blog_index","_type":"blog_type","_id":"AWIO9S2KAoLK5rH2_0Oy","_version":1,"result":"created","_shards":{"total":2,"successful":2,"failed":0},"created":true}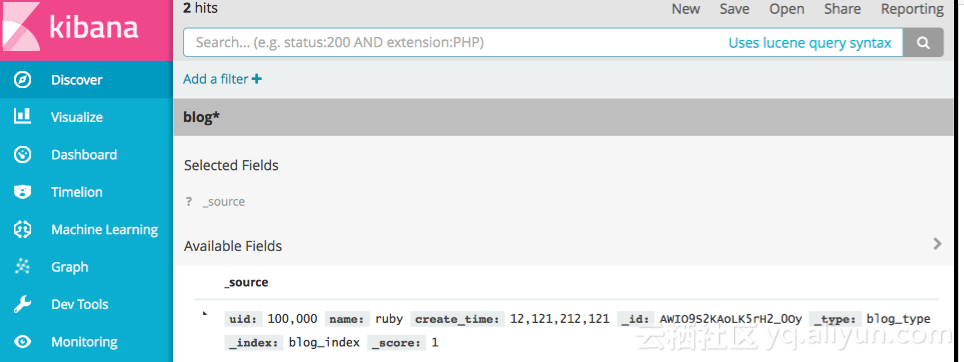
4.4 连接elasticsearch
4.4.1 启动logstash并监听标准输入
logstash -e 'input { stdin { } } output { elasticsearch {
hosts => ["es-cn-4590ijkny001dmjfy.elasticsearch.aliyuncs.com:9200"]
user => ["elastic"]
password => ["elastic"]
index => ["blog_index"]
} stdout { codec => rubydebug }}'4.4.2 输入文档
{"uid":200000, "name": "ruby2","create_time":122121212121}
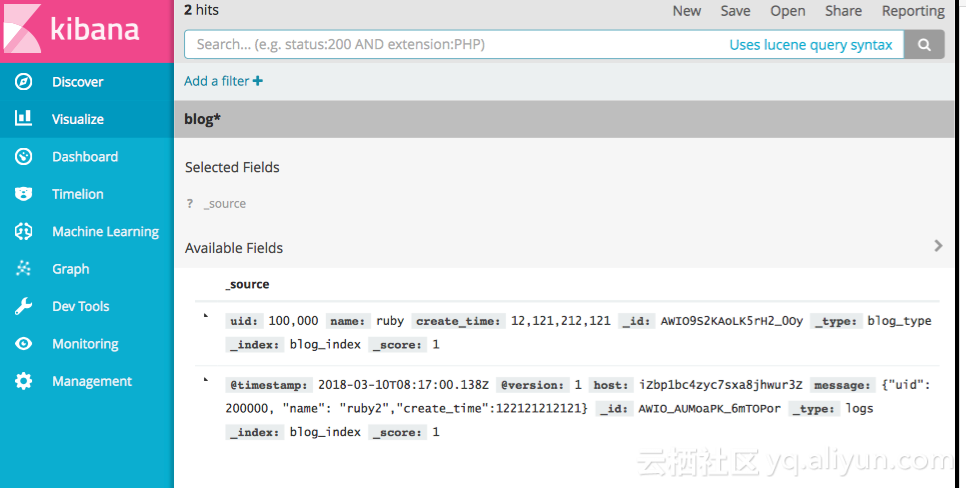
4.5 logstash监听log4j
4.5.1 使用配置文件启动logstash
vim /etc/logstash/conf.d/elk.conf
添加一下内容
input { stdin { } }
output { elasticsearch {
hosts => ["es-cn-4590ijkny001dmjfy.elasticsearch.aliyuncs.com:9200"]
user => ["elastic"]
password => ["elastic"]
index => ["blog_index"]
} stdout { codec => rubydebug }
}启动
logstash –f /etc/logstash/conf.d/elk.conf
添加文档
{"uid":300000, "name": "ruby3","create_time":122121212121}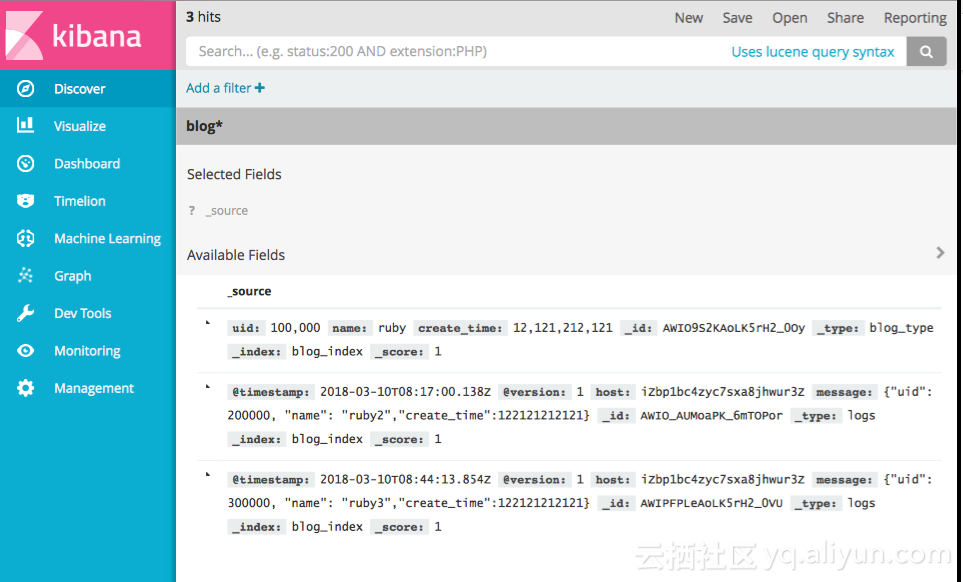
4.5.2 输入源配置log4j日志文件
vi /etc/logstash/conf.d/elk.conf
编辑配置添加一下配置
input {
file{
path => "/var/log/messages"
type => "system"
start_position => "beginning"
}
stdin { } }
output {
elasticsearch {
hosts => ["es-cn-4590ijkny001dmjfy.elasticsearch.aliyuncs.com:9200"]
user => ["elastic"]
password => ["elastic"]
index => ["blog_index"]
}
stdout { codec => rubydebug }
}
启动
logstash -f /etc/logstash/conf.d/elk.conf
logstash将日志文件中内容全部采集到elasticsearch中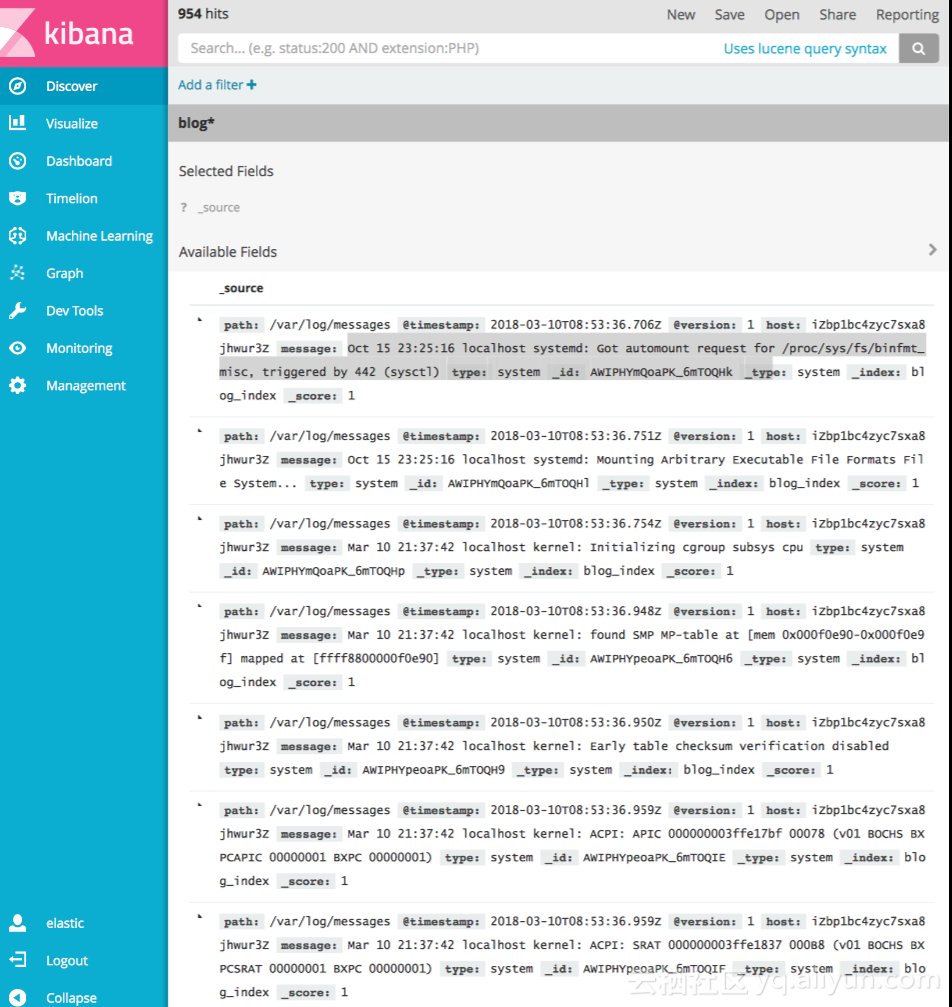
5.Elasticsearch的日志检索介绍
文章上半部分已对elk的入门搭建进行了介绍,下面我们将学习如何使用es进行文档检索。
5.1 基本概念
5.1.1 Node和Cluster
Elastic 本质上是一个分布式数据库,允许多台服务器协同工作,每台服务器可以运行多个 Elastic 实例。
单个 Elastic 实例称为一个节点(node)。一组节点构成一个集群(cluster)。
5.1.2 Index
Elastic 会索引所有字段,经过处理后写入一个反向索引(Inverted Index)。查找数据的时候,直接查找该索引。
所以,Elastic 数据管理的顶层单位就叫做 Index(索引)。它是单个数据库的同义词。每个 Index (即数据库)的名字必须是小写。
下面的命令可以查看当前节点的所有 Index。
curl -u elastic:elastic -XGET http://es-cn-4590ijkny001dmjfy.elasticsearch.aliyuncs.com:9200/_cat/indices?v
5.1.3 Document
Index 里面单条的记录称为 Document(文档)。许多条 Document 构成了一个 Index。
{
"uid": "10000",
"name": "ruby",
" create_time ": "10293822737"
}同一个 Index 里面的 Document,不要求有相同的结构(scheme),但是最好保持相同,这样有利于提高搜索效率。
5.1.4 Type
Document 可以分组,比如上面执行过程中我们分别通过命令行执行添加文档,通过logstash标准输入添加文档,监听日志文件添加文档,从kibana可以看出分别用3种type进行了分类

不同的 Type 应该有相似的结构(schema),举例来说,id字段不能在这个组是字符串,在另一个组是数值。这是与关系型数据库的表的一个区别。性质完全不同的数据(比如products和logs)应该存成两个 Index,而不是一个 Index 里面的两个 Type(虽然可以做到)。
下面的命令可以列出每个 Index 所包含的 Type。
curl -u elastic:elastic -XGET http://es-cn-4590ijkny001dmjfy.elasticsearch.aliyuncs.com:9200/_mapping?pretty=true | more5.1.5 文档检索
5.1.5.1 返回所有记录
curl -u elastic:elastic -XGET http://es-cn-4590ijkny001dmjfy.elasticsearch.aliyuncs.com:9200/blog_index/logs/_search{
"took": 3,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 1.0,
"hits": [{
"_index": "blog_index",
"_type": "logs",
"_id": "AWIO_AUMoaPK_6mTOPor",
"_score": 1.0,
"_source": {
"@timestamp": "2018-03-10T08:17:00.138Z",
"@version": "1",
"host": "iZbp1bc4zyc7sxa8jhwur3Z",
"message": "{\"uid\":200000, \"name\": \"ruby2\",\"create_time\":122121212121}"
}
}, {
"_index": "blog_index",
"_type": "logs",
"_id": "AWIPFPLeAoLK5rH2_0VU",
"_score": 1.0,
"_source": {
"@timestamp": "2018-03-10T08:44:13.854Z",
"@version": "1",
"host": "iZbp1bc4zyc7sxa8jhwur3Z",
"message": "{\"uid\":300000, \"name\": \"ruby3\",\"create_time\":122121212121}"
}
}]
}
}上面代码中,返回结果的 took字段表示该操作的耗时(单位为毫秒),timed_out字段表示是否超时,hits字段表示命中的记录,里面子字段的含义如下。
total:返回记录数,本例是2条。
max_score:最高的匹配程度,本例是1.0。
hits:返回的记录组成的数组。
返回的记录中,每条记录都有一个_score字段,表示匹配的程序,默认是按照这个字段降序排列。
5.1.5.2 全文搜索
查询语法:https://www.elastic.co/guide/en/elasticsearch/reference/5.5/query-dsl.html
使用条件搜索
curl -u elastic:elastic -XGET http://es-cn-4590ijkny001dmjfy.elasticsearch.aliyuncs.com:9200/blog_index/logs/_search -d '
{
"query" : { "match" : { "message" : "ruby3" }},
"from":1,
"size":1
}匹配条件为
message字段里包含 ruby3,
size为返回条数,
from为开始位置,可用户分页查询
结果为:
{
"took": 6,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 6.061471,
"hits": [{
"_index": "blog_index",
"_type": "logs",
"_id": "AWIPFPLeAoLK5rH2_0VU",
"_score": 6.061471,
"_source": {
"@timestamp": "2018-03-10T08:44:13.854Z",
"@version": "1",
"host": "iZbp1bc4zyc7sxa8jhwur3Z",
"message": "{\"uid\":300000, \"name\": \"ruby3\",\"create_time\":122121212121}"
}
}]
}
}5.1.5.3 逻辑运算
或查询示例:
"query" : { "match" : { "message" : "ruby3 ruby2" }}结果中包含ruby3 或则 ruby2
与查询示例:
"query" : {
"bool":{
"must":[
"match" : { "message" : "ruby2" }},
"match" : { "message" : "ruby3" }}
]
}
}6.kibana的分析功能介绍
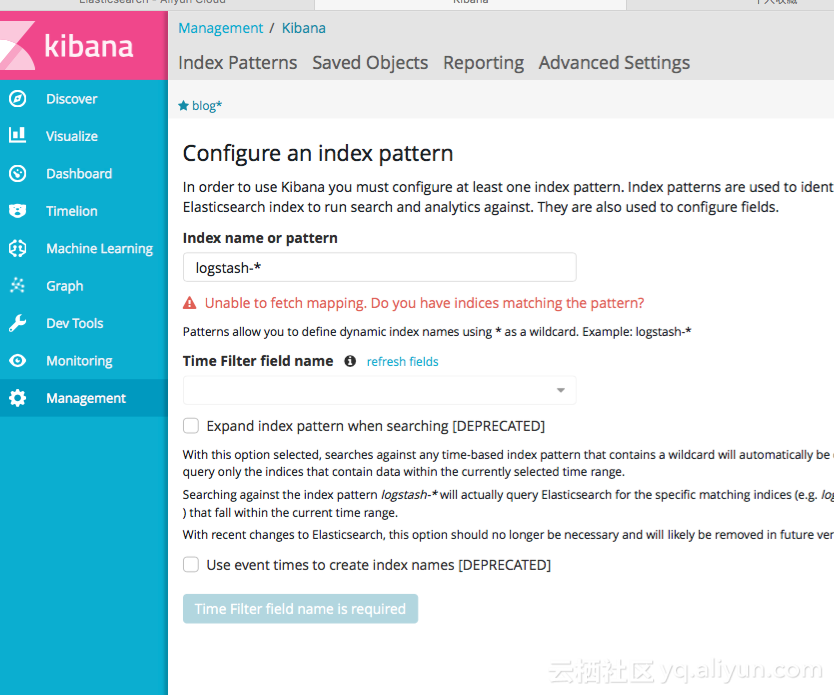
6.1 创建索引
左边导航上选择Management->Kibana(Index Patterns),此处需要先手动命令行创建索引,然后再kibana中建立视图;
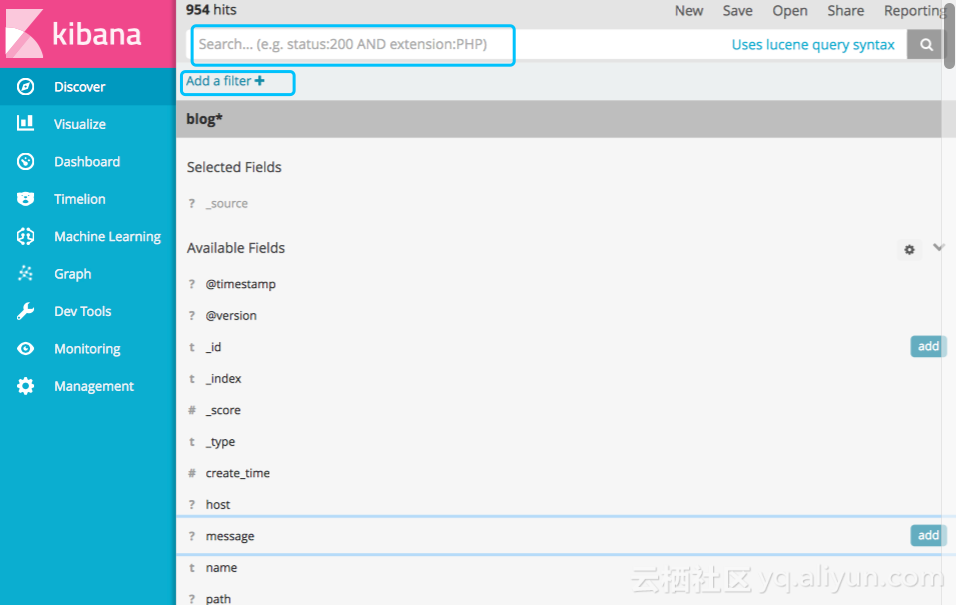
6.2 Discover
此功能是通过搜索查看文档数据,可通过添加过滤器或则填写表达式来进行搜索;
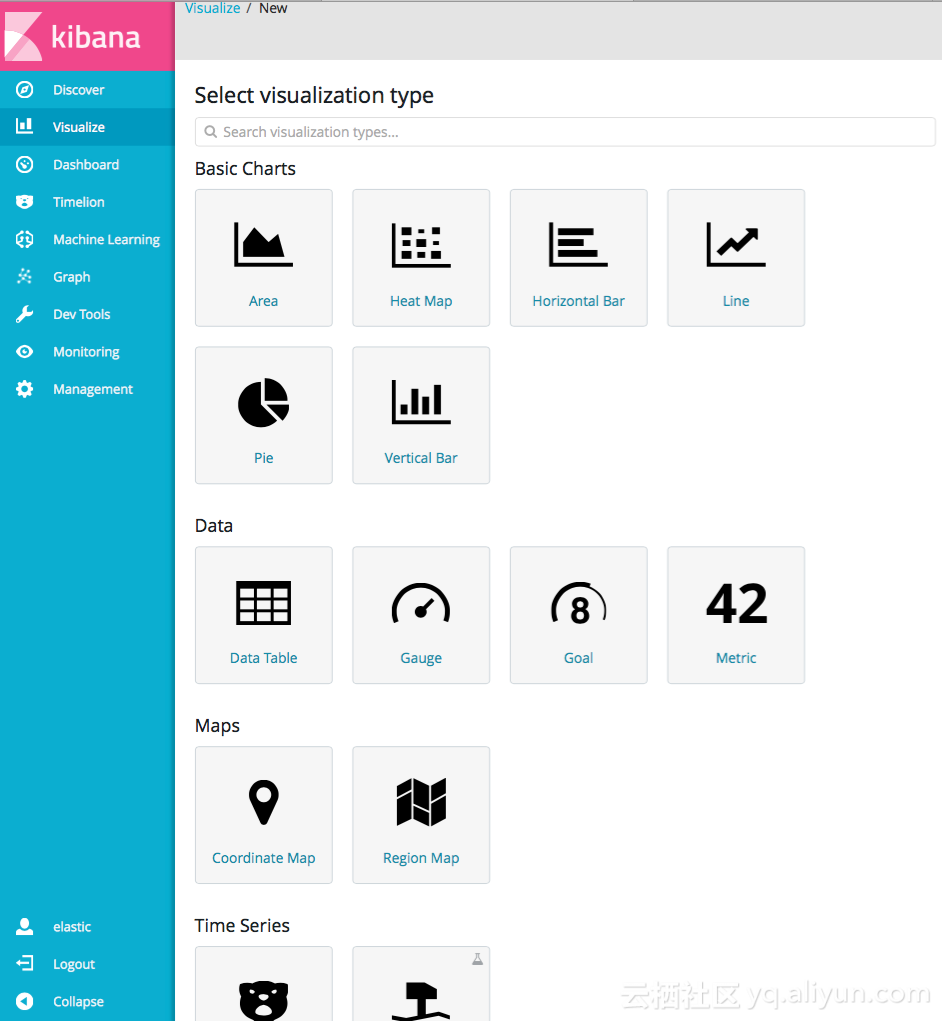
6.3 Visualize
此功能是将查询出的数据进行可视化展示;
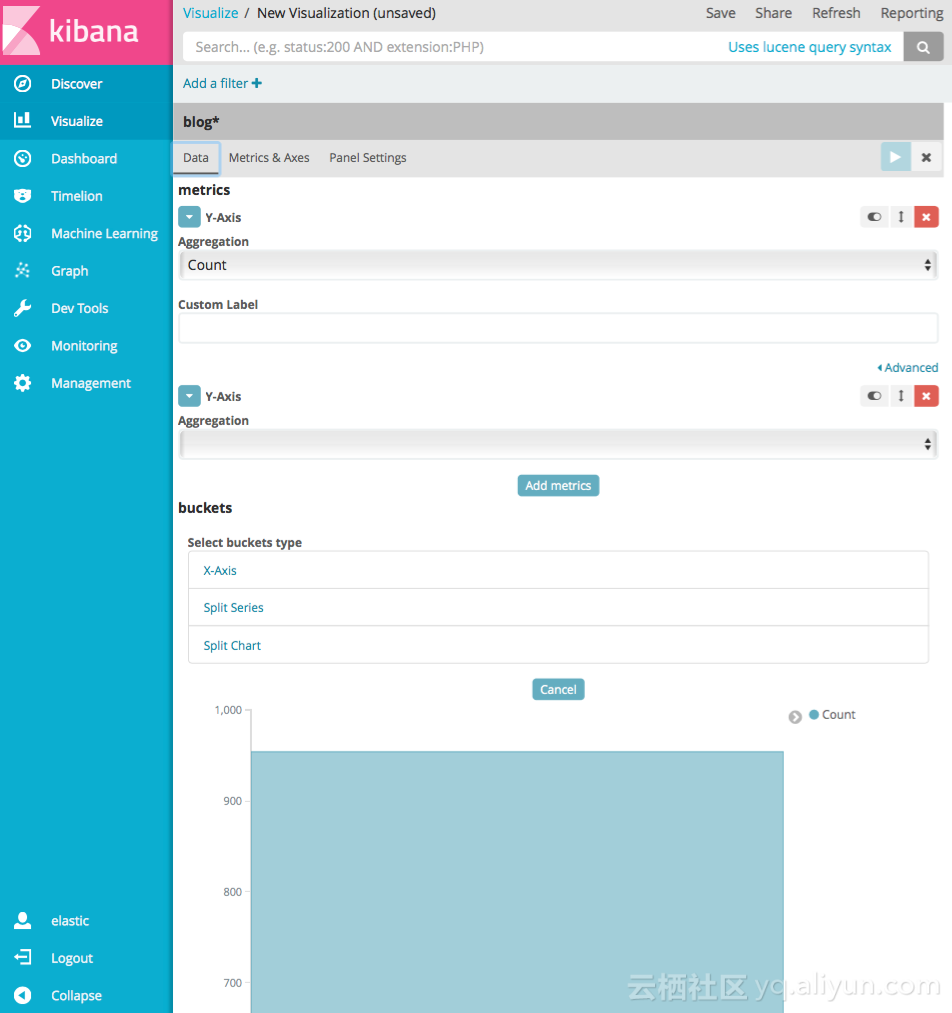
6.4 Dashboard
这里主要对筛选条件进行组合并保存;
在“Dashboard” 菜单界面中,我们可以自由排列一组已保存的可视化数据。
点击左侧 “Dashboard” 菜单,再点击界面中间的 “Create a dashboard” 按钮进行创建;
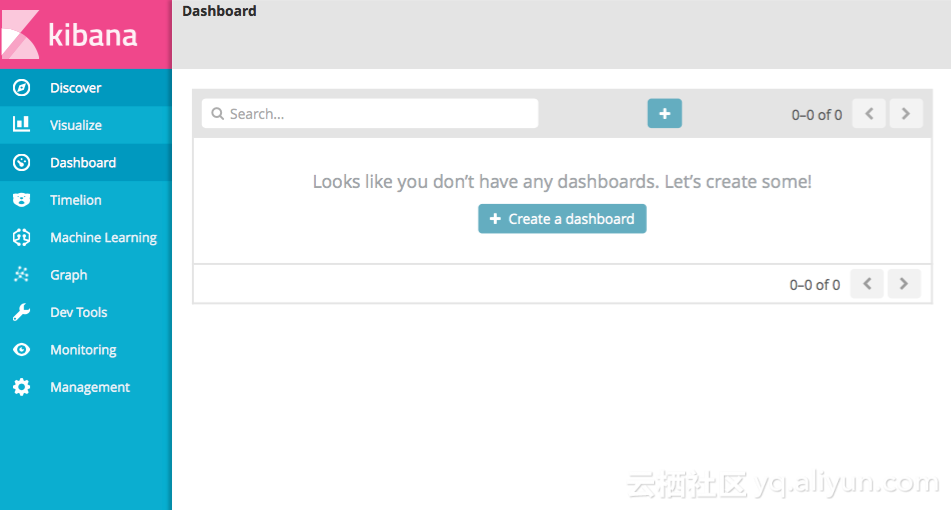
6.5 Timelion
Timelion 是一个时间序列数据的可视化,可以结合在一个单一的可视化完全独立的数据源。它是由一个简单的表达式语言驱动的,用来检索时间序列数据,进行计算,找出复杂的问题的答案,并可视化的结果。