
该gif做了加速处理,便于观看~
今天在将一个500w+条数据的文件导入至数据库时,遇到一个异常,相信做大数据应该都有遇到。500w条数据说多不多,说少也不少。既然问题出现了,那么就一定要解决。
异常如下图所示:
造成异常的方法代码在如下链接:


由于数据通过该方式转换为一条sql,执行读取工作量过于庞大,导致所创建的对象都为强引用,垃圾回收机制无法释放内存,所导致堆内存溢出而造成的异常。
想了一下,虽然通过prepareStatement的addBatch( )方法可以做到只访问一次数据库,面对100w的数据CPU还可以处理,但是遇到千万级的数据或更多就会出现问题(甚至损耗cpu)。
于是便在此基础上做了升级,并封装了工具类,代码如下:(一行代码一行注释,不理解之处留言即可)
public class DataImport {
// 参数一:数据库连接对象、参数二:流文件读取出的集合、参数三:从第几条数据开始读取,目的是排除表头、参数四:是否包含主键、参数五:每次批量执行添加数据的数量、参数六:sql语句
public static void dispose(Connection conn, List<String> list, Integer startRows, boolean includePrimaryKey, Integer size, String sql) {
try {
conn.setAutoCommit(false); // 设置事物手动提交
PreparedStatement ps = conn.prepareStatement(sql);
String[] split = null;
if (includePrimaryKey) { // 包含主键,只需判断一次
for (int i = startRows; i < list.size(); i++) {
// 按逗号切割字符串,-1代表忽略数组长度,避免数组长度越界异常
split = list.get(i).split(",", -1);
/*下方代码产生警告提示的原因:同一项目中,有重复的代码块(idea很好的提示。但是这里无法将判断放在循环内,不然会多出百万次判断使程序缓慢)*/
for (int j = 0; j < split.length; j++) { // 遍历刚刚获取的数组
// 对集合中的每条数据进行处理,将字符串中多出的引号去掉,避免录入数据库时因字段类型不匹配而导致的格式转换异常
ps.setObject(j + 1, split[j].replace("\"", "")); // 循环赋值
}
ps.addBatch(); // 将所有数据转为一条sql
if (i % size == 0 && i != 0) { // 如果i能整除size,即执行循环体
ps.executeBatch(); // 批量执行sql
conn.commit(); // 事物手动提交
conn.setAutoCommit(false); // 重新设置事物为手动提交
ps = conn.prepareStatement(sql); // 再次为ps对象赋值
}
}
} else { // 不包含主键
for (int i = startRows; i < list.size(); i++) {
String s = list.get(i);
// 将集合中的对象从第一个逗号切割,substring包头不包尾,因此此处需加1
split = s.substring(s.indexOf(",") + 1).split(",", -1);
for (int j = 0; j < split.length; j++) {
ps.setObject(j + 1, split[j].replace("\"", ""));
}
ps.addBatch();
if (i % size == 0 && i != 0) {
ps.executeBatch();
conn.commit();
conn.setAutoCommit(false);
ps = conn.prepareStatement(sql);
}
}
}
ps.executeBatch(); // 循环外提交是因为可能会出现循环内条件不成立而未提交过的情况
conn.commit(); // 提交事物,避免脏数据(事物太长也有弊端)
ps.close(); // 关闭资源
conn.close();
} catch (Exception throwables) {
throwables.printStackTrace();
}
}
}- 参数一:数据库连接对象;
- 参数二:IO流读取文件得到的集合;
- 参数三:代表从文件的第几条数据开始读取,主要目的是为了排除表头;
- 参数四:存入数据库时是否需要包含主键
- 参数五:每次批量执行sql时添加数据的数量;
- 参数六:所要执行的sql语句;
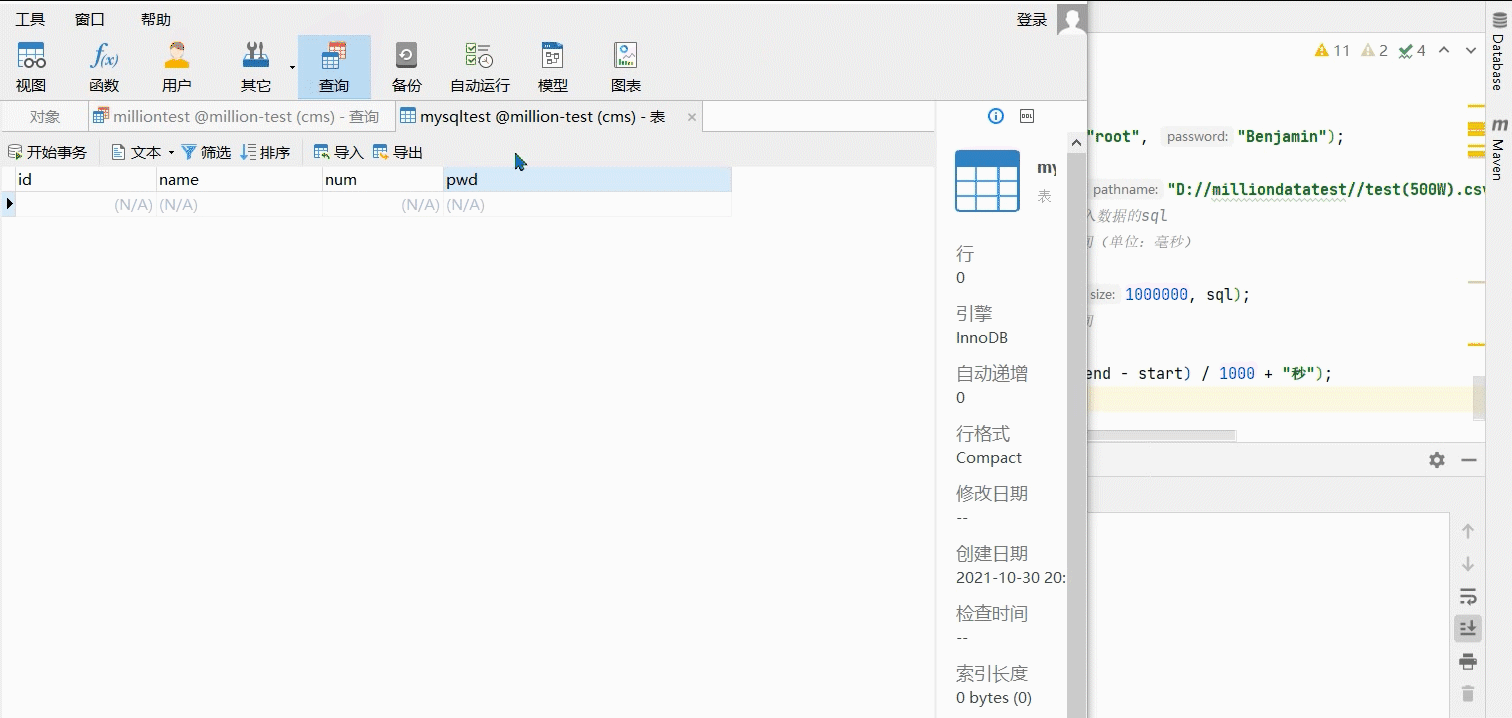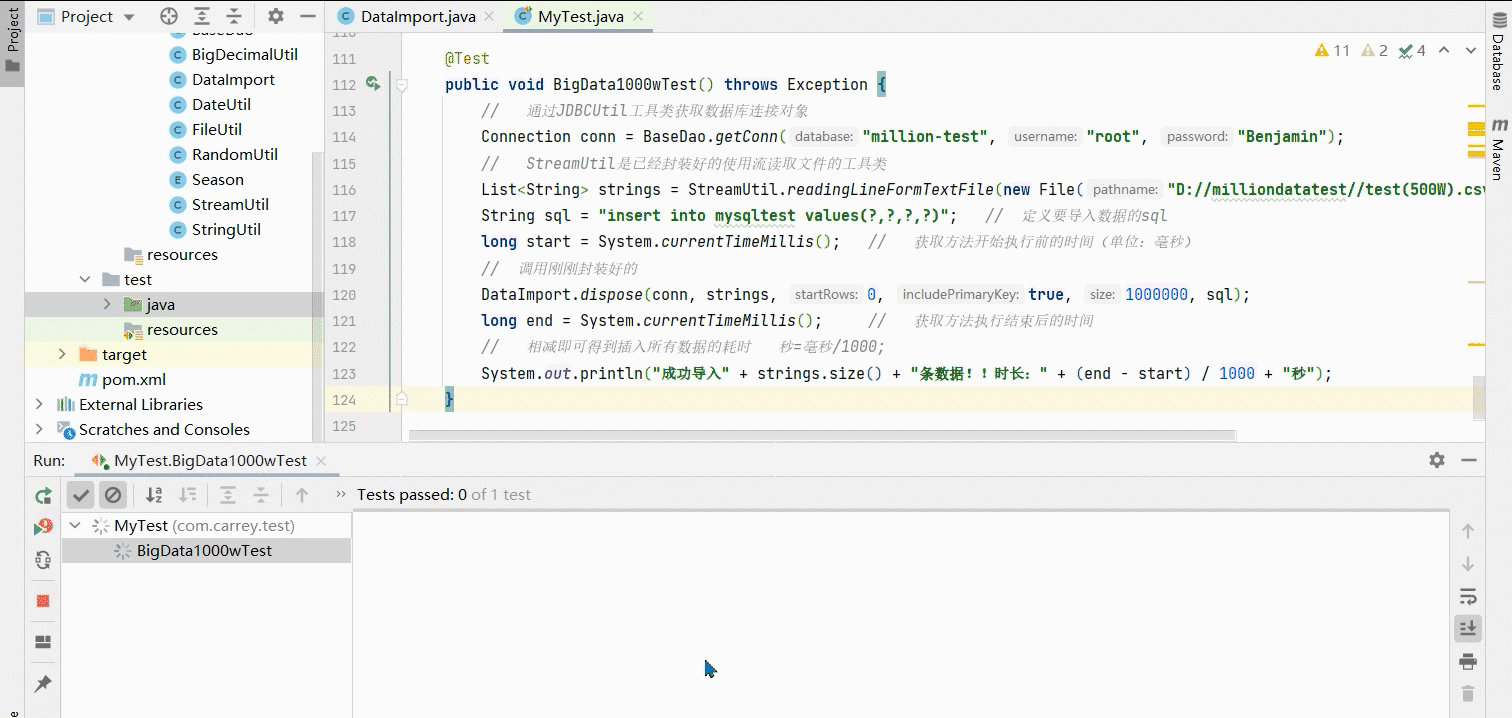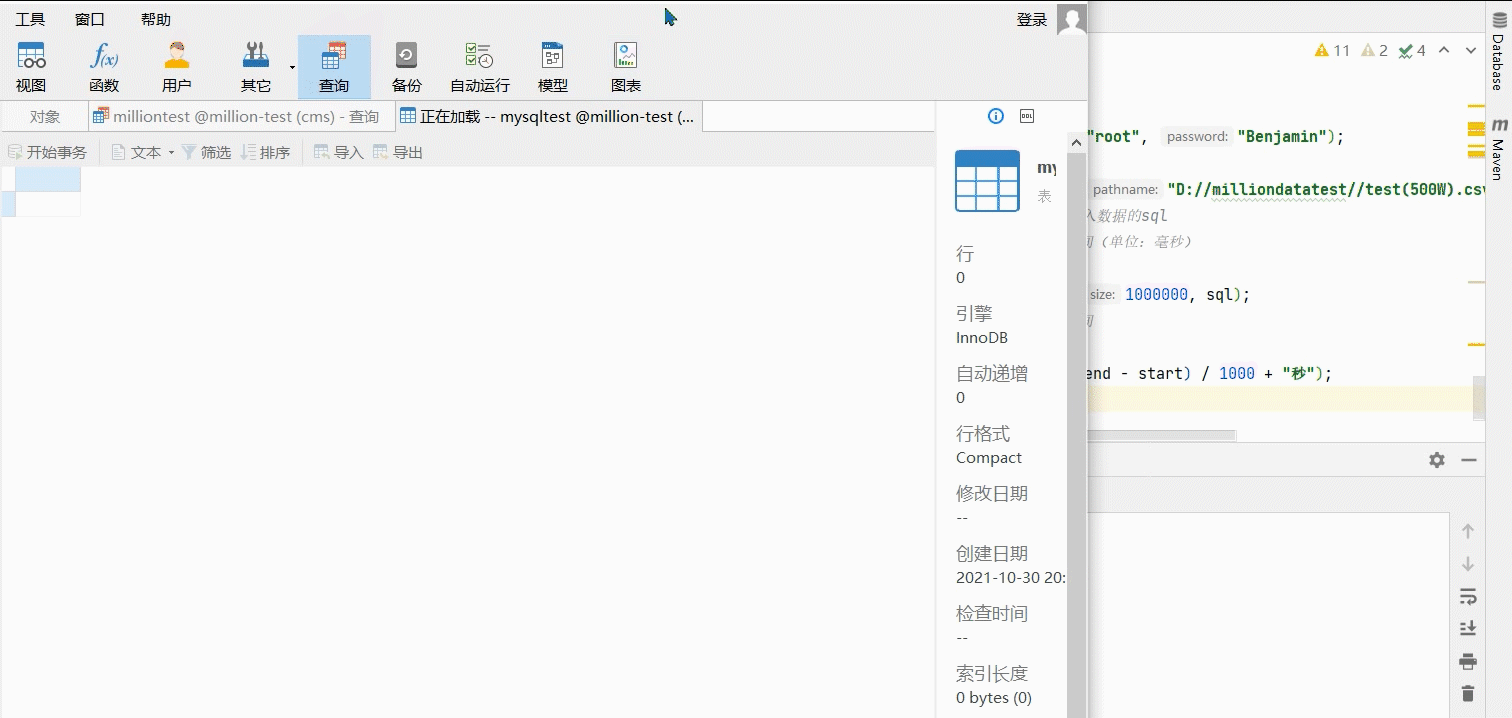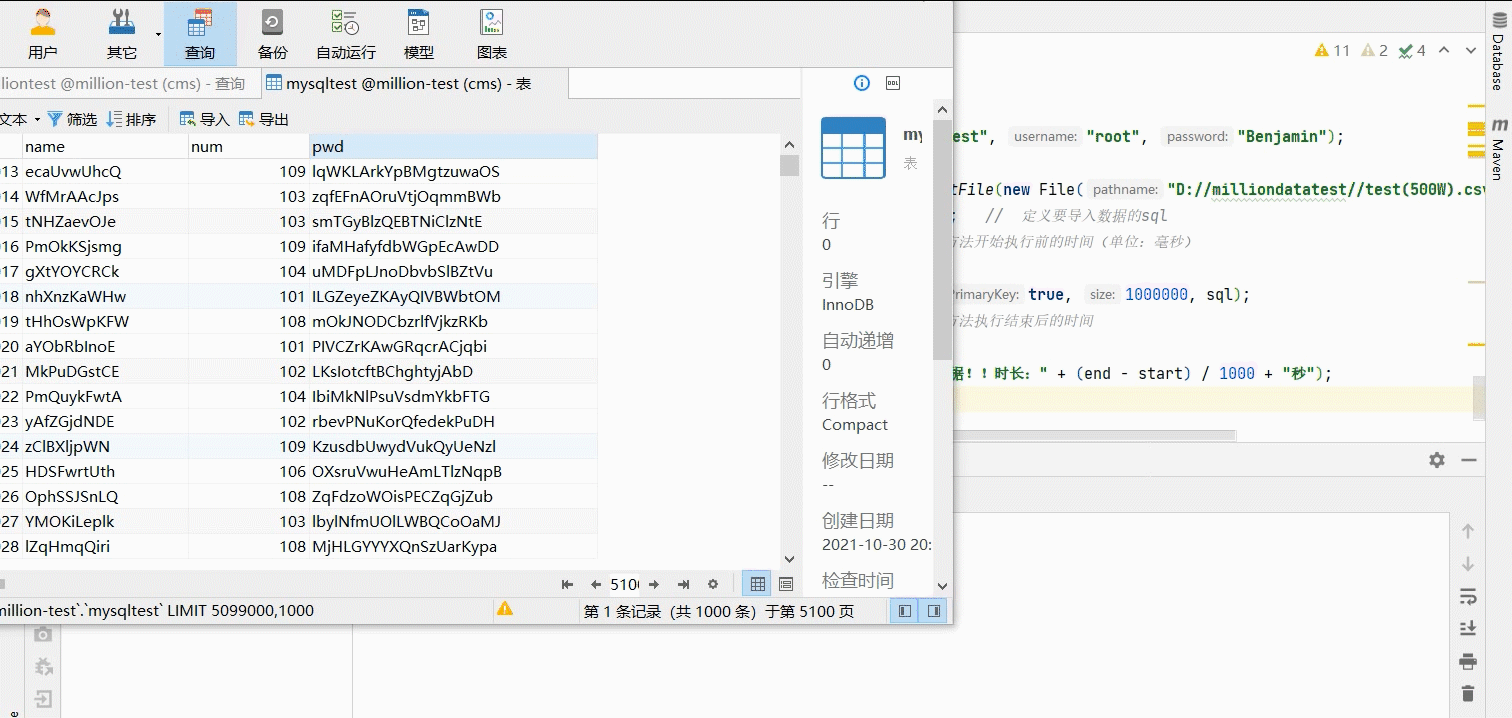
测试代码如下(拿去测试):
(所用到的工具类源码可通过下方链接获取:
BaseDao(JDBCUtil)工具类:JDBC访问数据库的BaseDao工具类代码【拿去使用】
IO流读取文件工具类:IO流读取文件 工具类 【拿去使用】)
@Test
public void BigData1000wTest() throws Exception {
// 通过JDBCUtil工具类获取数据库连接对象
Connection conn = BaseDao.getConn("million-test", "root", "root");
// StreamUtil是已经封装好的使用流读取文件的工具类
List<String> list = StreamUtil.readingLineFormTextFile(new File("D://milliondatatest//test(500W).csv"));
String sql = "insert into mysqltest values(?,?,?,?)"; // 定义要导入数据的sql,无需主键将第一个?设置为null
long start = System.currentTimeMillis(); // 获取方法开始执行前的时间(单位:毫秒)
// 调用刚刚封装好的工具类
DataImport.dispose(conn, list, 0, true, 1000000, sql);
long end = System.currentTimeMillis(); // 获取方法执行结束后的时间
// 相减即可得到插入所有数据的耗时 秒=毫秒/1000;
System.out.println("成功导入" + list.size() + "条数据!!时长:" + (end - start) / 1000 + "秒");
}效果如图所示:

数据库如下:

成功!
这么运行的原理就是让程序分批处理sql语句,不会像之前那么吃cpu,我的cpu大概稳定在30%~50%之间。
当然如果你的数据在100W左右,还是升级前的快一些,毕竟只造访一次数据库,执行一条sql语句与一次事物。升级前如下:
千万级数据甚至更多数据使用本文工具类也是没有问题的,该工具类尽可能多的避免了创建对象,使用时只需根据不同电脑性能控制每次执行sql要导入的数据量即可。
如有错误,欢迎指正
Thanks
本文章为转载内容,我们尊重原作者对文章享有的著作权。如有内容错误或侵权问题,欢迎原作者联系我们进行内容更正或删除文章。


















