
1.简介
上一篇中,主要是介绍了拖拽的各种方法的理论知识以及实践,今天宏哥讲解和分享一下划取字段操作。例如:需要在一堆log字符中随机划取一段文字,然后右键选择摘取功能。
2.划取字段操作
划取字段操作就是在一段文字中随机选中一段文字,或者在标记文字。当然了,这个在一些网站的登录也需要滑块验证等。
selenium中提供了ActionChains类来处理鼠标事件。这个类中有2个方法和滑块移动过程相关。click_and_hold():模拟按住鼠标左键在源元素上,点击并且不释放;release():松开鼠标按键。字面意思就可以理解这2个函数的作用。今天跟随宏哥看一下,playwright是如何处理这种测试场景的。
2.1牛刀小试
在一段文字中,随机划取一小段文字(这个感觉比较鸡肋,貌似没有什么卵用,但是宏哥还是说一下吧)。那么宏哥就用度娘的免责声明进行实践,划取其中的一小段文字。
使用locator.drag_to()执行拖放操作,实现自动化测试。
2.1.1代码设计

2.1.2参考代码
# coding=utf-8🔥
# 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行
# 2.注释:包括记录创建时间,创建人,项目名称。
'''
Created on 2023-07-22
@author: 北京-宏哥 QQ交流群:705269076
公众号:北京宏哥
Project: 《最新出炉》系列初窥篇-Python+Playwright自动化测试-18-处理鼠标拖拽-中篇
'''
# 3.导入模块
from playwright.sync_api import Playwright, sync_playwright, expect
def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch(headless=False)
context = browser.new_context()
page = context.new_page()
page.goto("https://www.baidu.com/duty")
page.wait_for_timeout(1000)
page.locator("//*/p").drag_to(page.locator('//*/ul[@class="privacy-ul-gap"]/li[1]'))
# page.drag_and_drop('//*/p', '//*/ul[@class="privacy-ul-gap"]/li[1]')
page.wait_for_timeout(3000)
# page.pause()
context.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)2.1.3运行代码
1.运行代码,右键Run'Test',控制台输出,如下图所示:

2.运行代码后电脑端的浏览器的动作。如下图所示:

使用page.drag_and_drop(locator, loacator),实现自动化测试。
2.1.4参考代码
# coding=utf-8🔥
# 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行
# 2.注释:包括记录创建时间,创建人,项目名称。
'''
Created on 2023-07-22
@author: 北京-宏哥 QQ交流群:705269076
公众号:北京宏哥
Project: 《最新出炉》系列初窥篇-Python+Playwright自动化测试-18-处理鼠标拖拽-中篇
'''
# 3.导入模块
from playwright.sync_api import Playwright, sync_playwright, expect
def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch(headless=False)
context = browser.new_context()
page = context.new_page()
page.goto("https://www.baidu.com/duty")
page.wait_for_timeout(1000)
# page.locator("//*/p").drag_to(page.locator('//*/ul[@class="privacy-ul-gap"]/li[1]'))
page.drag_and_drop('//*/p', '//*/ul[@class="privacy-ul-gap"]/li[1]')
page.wait_for_timeout(3000)
# page.pause()
context.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)精确控制拖动操作,可以使用较低级别的手工方法,如locator.hover()、mouse.down()、mouse.move()和mouse.up()。来实现自动化测试。
2.1.5参考代码
# coding=utf-8🔥
# 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行
# 2.注释:包括记录创建时间,创建人,项目名称。
'''
Created on 2023-07-19
@author: 北京-宏哥 QQ交流群:705269076
公众号:北京宏哥
Project: 最新出炉》系列初窥篇-Python+Playwright自动化测试-18-处理鼠标拖拽-中篇
'''
# 3.导入模块
from playwright.sync_api import Playwright, sync_playwright, expect
def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch(headless=False)
context = browser.new_context()
page = context.new_page()
page.goto("https://www.baidu.com/duty")
page.wait_for_timeout(1000)
page.locator('//*/p').hover()
page.mouse.down()
page.locator('//*/ul[@class="privacy-ul-gap"]/li[1]').hover()
page.mouse.up()
page.wait_for_timeout(3000)
# page.pause()
context.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)3.项目实战
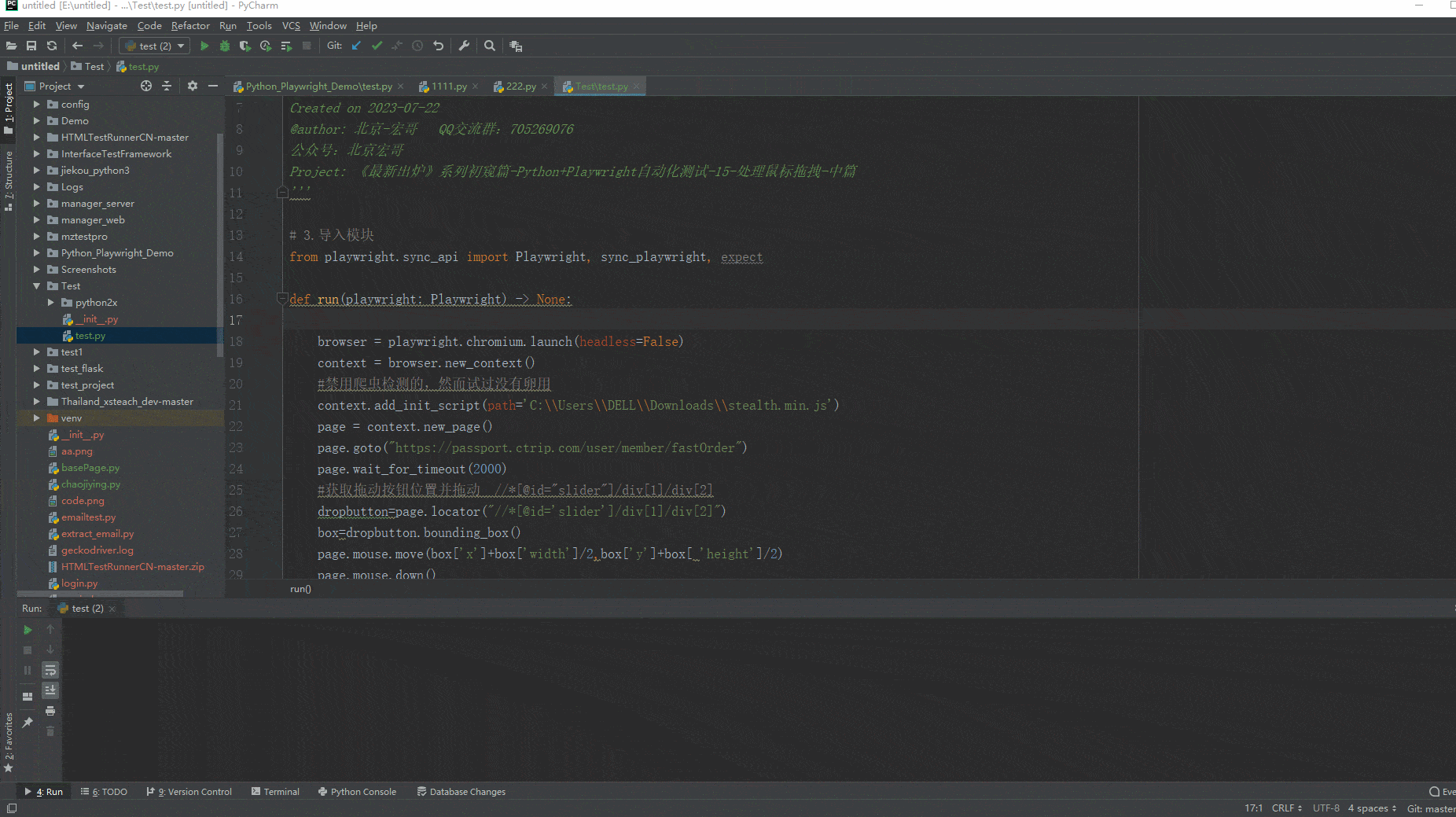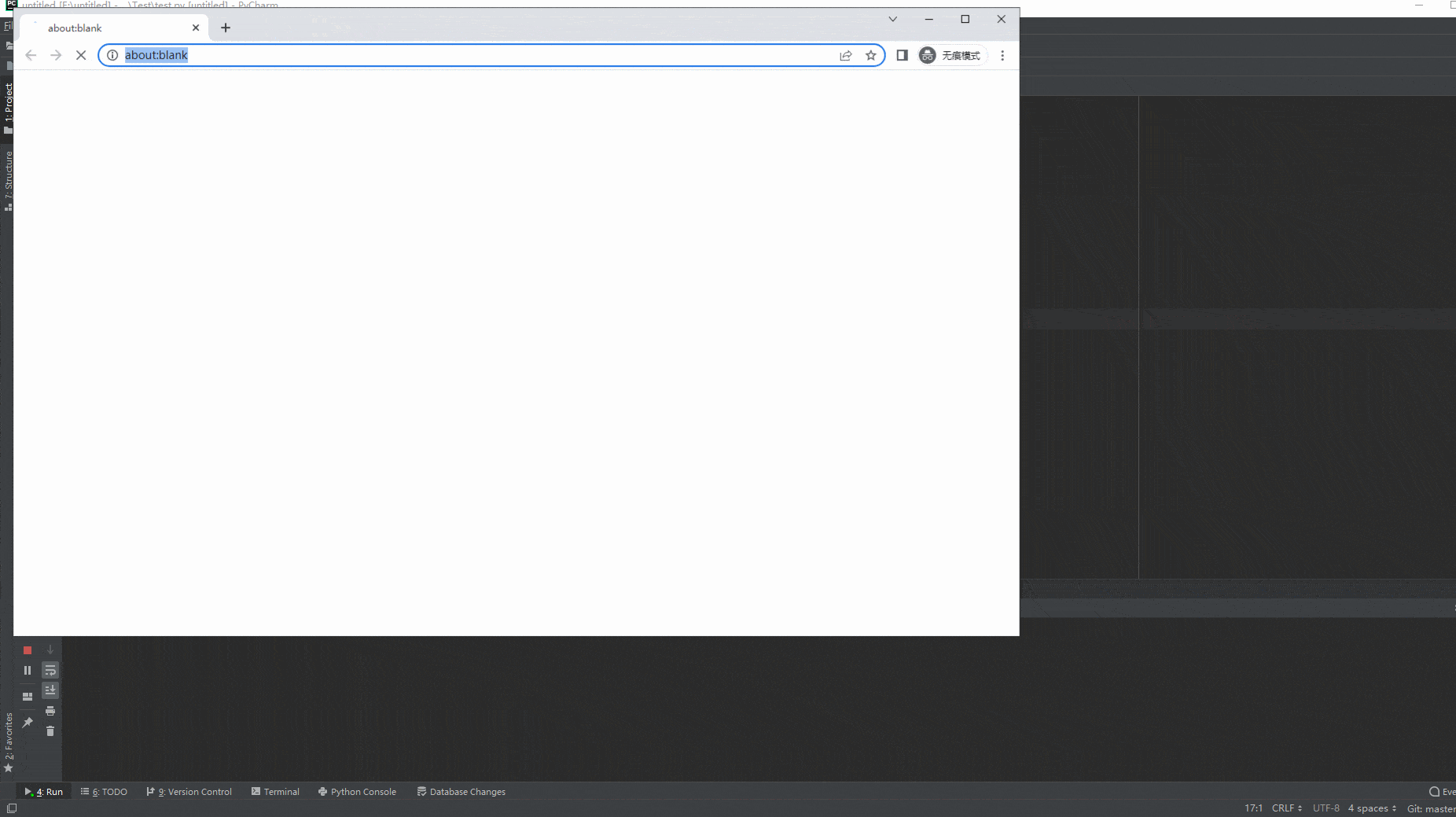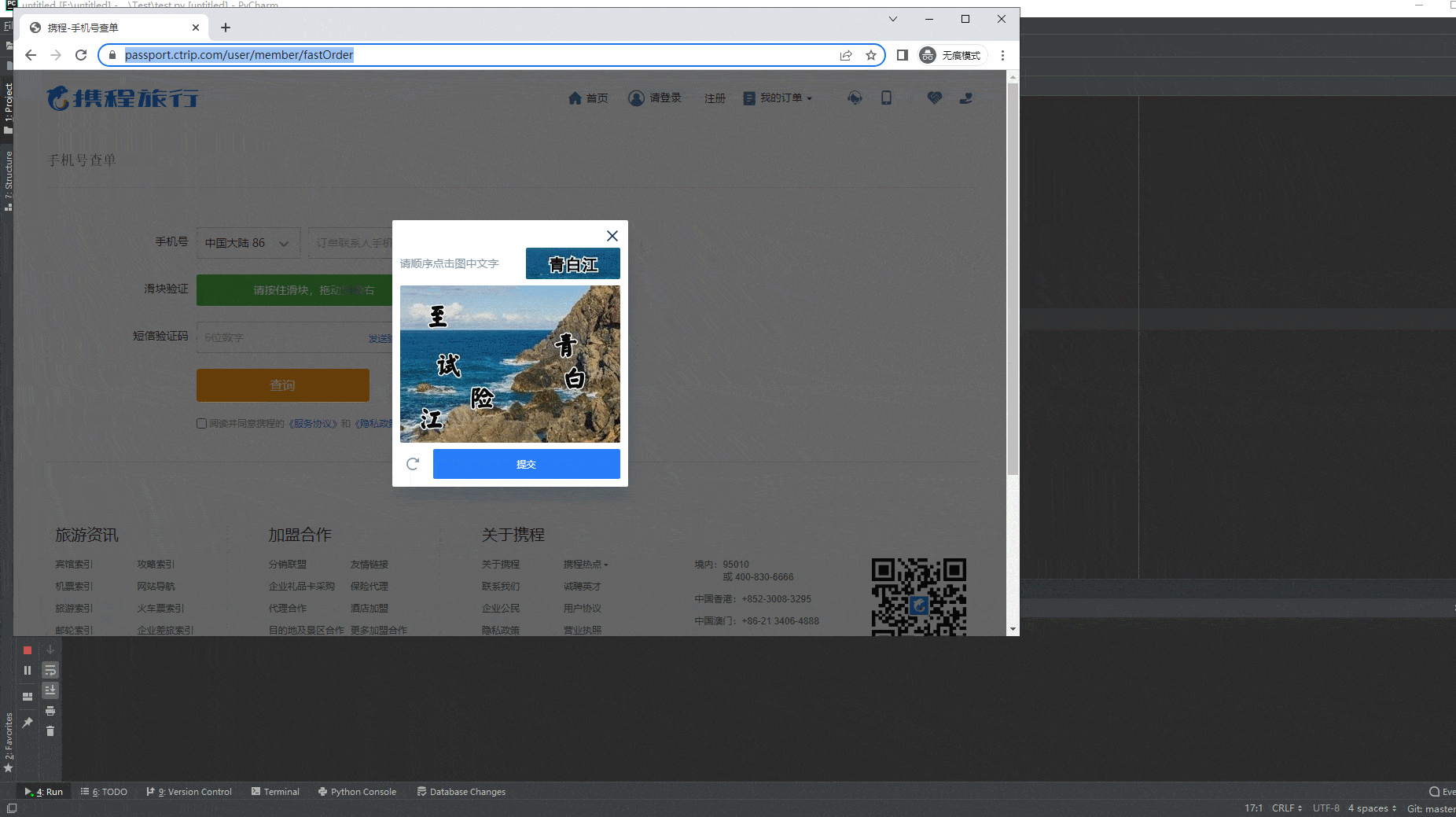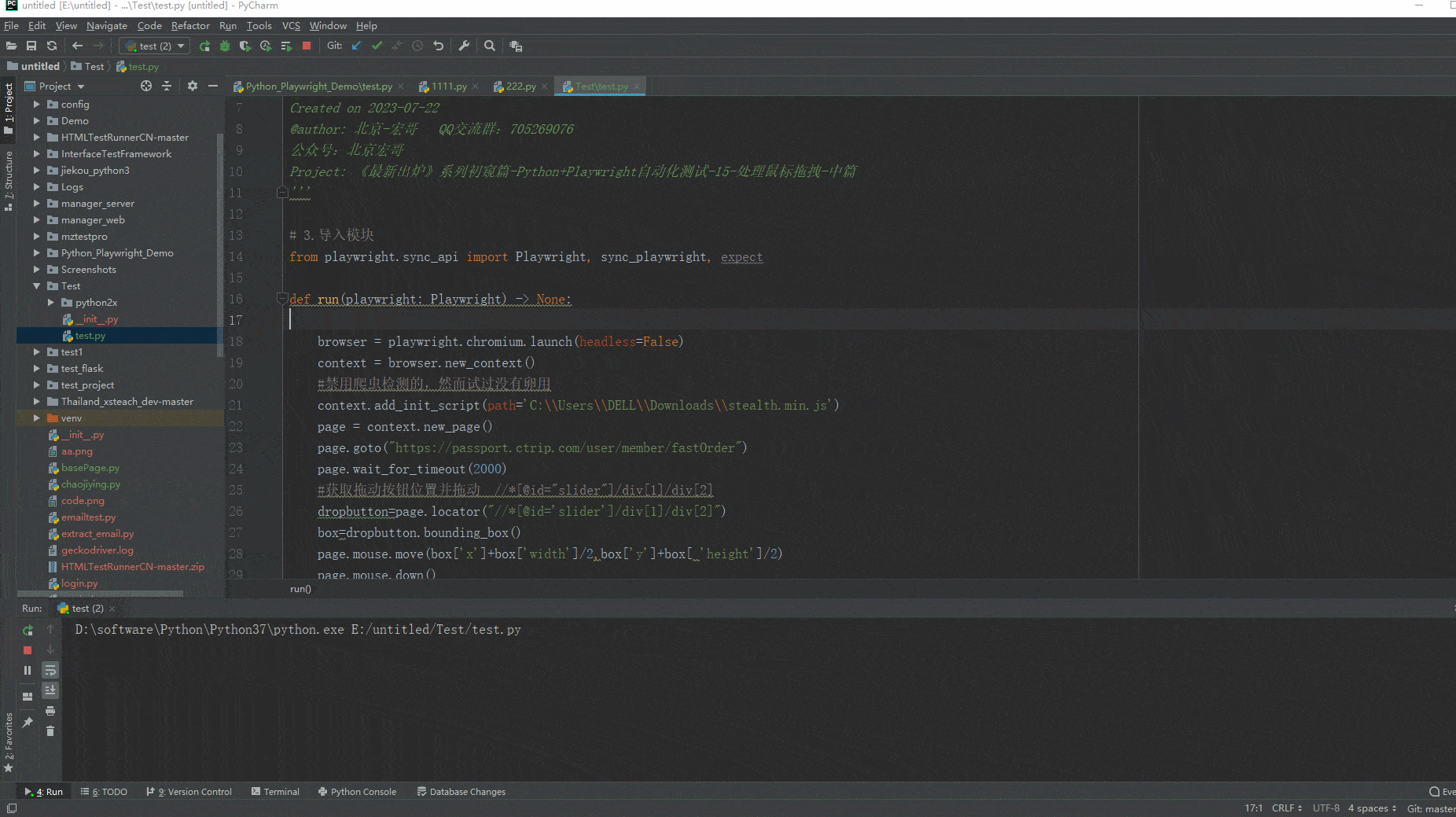
这里宏哥用java+selenium中的携程旅行,手机号查单页面的一个滑动,进行项目实战。如下图所示:

3.1思路说明
- 使用locator定位到要拖动滑块元素,如元素名叫ele
- 获取元素ele的bounding_box含4分属性值:x,y,width,height
- 把鼠标移动到元素ele的中心点,中心点位置为:x+width/2,y+height/2
- 按下鼠标
- 计算出要移动的下一个位置,以长条滑块为例,拖动到长条头部实现解锁,那x的位置应该为x+width/2 + 某个固定值(足够大就好)
- 执行移动操作,下一个位置坐标为:x+width/2 + 某个固定值,y+height/2
- 释放鼠标
3.2调用方法
- 元素定位:page.locator()
- 获取元素位置及大小:ele.bounding_box()
- 鼠标移动:page.mouse.move()
- 按下鼠标:page.mouse.down()
- 释放鼠标:page.mouse.up()
3.2代码设计

3.3参考代码
# coding=utf-8🔥
# 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行
# 2.注释:包括记录创建时间,创建人,项目名称。
'''
Created on 2023-07-22
@author: 北京-宏哥 QQ交流群:705269076
公众号:北京宏哥
Project: 《最新出炉》系列初窥篇-Python+Playwright自动化测试-18-处理鼠标拖拽-中篇
'''
# 3.导入模块
from playwright.sync_api import Playwright, sync_playwright, expect
def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch(headless=False)
context = browser.new_context()
#禁用爬虫检测的,然而试过没有卵用
context.add_init_script(path='C:\\Users\\DELL\\Downloads\\stealth.min.js')
page = context.new_page()
page.goto("https://passport.ctrip.com/user/member/fastOrder")
page.wait_for_timeout(2000)
#获取拖动按钮位置并拖动 //*[@id="slider"]/div[1]/div[2]
dropbutton=page.locator("//*[@id='slider']/div[1]/div[2]")
box=dropbutton.bounding_box()
page.mouse.move(box['x']+box['width']/2,box['y']+box[ 'height']/2)
page.mouse.down()
mov_x=box['x']+box['width']/2+280
page.mouse.move(mov_x,box['y']+box[ 'height']/2)
page.mouse.up()
page.wait_for_timeout(3000)
context.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)3.4运行代码
1.运行代码,右键Run'Test',控制台输出,如下图所示:

2.运行代码后电脑端的浏览器的动作。如下图所示:
4.小结
之前宏哥在java+selenium的文章中测试的时候,就会跳转到这个页面,之前说的是selenium检查机制,但是这里没有用selenium,怎么还会有这个,查了半天资料说是反爬虫机制。但是代码中加入反爬虫的机制不好使。有知道怎么回事的可以给宏哥留言。

4.1测试网站
测试链接:Antibot
正常浏览结果:

宏哥然后加入暂停代码(page.pause()),在这个页面用网址监测一下,看到绕过Chrome的selenium反爬虫检测机制,但是还是会出现那个选择字的验证。查了半天也不知道怎么回事,有知道给宏哥留言,让宏哥学习学习。如下图所示:

好了,时间不早了,今天就分享和讲解到这里。


















