
模型结构
CBOW模型,中文译为“连续词袋模型”,完成的任务是给定中心词
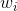
的一定邻域半径(比如半径为2,通常成为windows,窗口,这里窗口的大小为5)内的单词
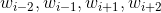
,预测输出单词为该中心词
的概率,由于没有考虑词之间的顺序,所以称为词袋模型。论文中给出的CBOW模型的结构如下图:

在上面的结构示意图中,符号w(t-1),w(t-2),w(t+1),w(t+2) 表示输入的单词,实际是一个one-hot的vector,通过构建词典,建立单词索引可以很容易实现,向量的维度和词典中单词数目相同,只有一个维度的值为1,该维度对应该单词在词典索引中的位置,其余维度的值为0。其中的PROJECTION层是通过查表得到的,首先初始化一个words vector矩阵W,W是一个二维的矩阵,行数等于构建的词典中的单词的数目,依赖具体语料库大小等因素,列数是一个超参数,人为设定,一般为100;论文中给出的结构图太简单,我自己画了一个,如下:

输入是中心词
的上下文单词,都是one-hot编码的,我假设了widows size 是5,所以有4个one-hot编码向量的输入

。设输入层矩阵为
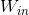
,大小为
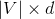
,其中
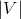
是词典的大小 ,
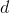
是词向量的维度,

向量则是
的一行,lookup的过程即是如下的操作:
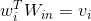
将one-hot编码的向量
和
相乘,就是取出了输入矩阵
中
对应的一行,该行的行号是单词
在词典中的索引号。经过输入层操作得到的向量是一个稠密的向量(dense),假设为
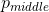
。输出层的矩阵设为
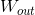
,输出矩阵的大小
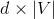
,则输出向量为
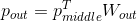
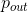
的大小为
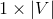
,每一个维度的值可以理解为在当前上下文
环境下,输出的中心单词是字典每一个单词的logit概率,做softmax后,就是每一个单词的概率了。以上描述的也是CBOW模型一次前向传播的过程。
公式详解每一步操作
1、查表(lookup) 从单词到向量
对
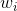
进行查表即是完成下列操作:
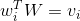
这是一个(n x 1) 的矩阵和一个(n x d)的矩阵之间的矩阵乘法,得到的是一个(1 x d)的向量
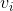
,就是一个向量。这个
向量就是单词
对应的词向量。同理有:
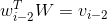
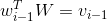
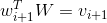
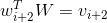
2、求和平均(sum and average)
上一步通过lookup,得出了中心词
上下文单词
对应的词向量
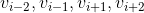
,因为我们要根据这些词向量算出单词
出现的概率,所以需要对这4个词向量做求和,然后取平均值,作为PROJECTION层的输出,即
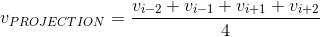
这里做一下说明,论文中给出的求和后取平均值,可以看成是四个上下文
词向量对生成中心词
的贡献是相同的,没有考虑单词的顺序问题(CBOW名称的来源)。
3、输出(output)
这一步需要计算的是由
生成
的概率。即计算:
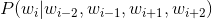
由于经过lookup层后,上下文单词
被综合表示成
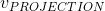
,所以我们需要计算由
生成中心单词
的概率是多大。所以
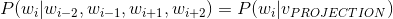
由于给定上下文时,不止是只能生成中心词,还能生成整个词典中的任何一个单词,只是生成的概率没有中心词概率大,我们用一个通用的公式表示如下:
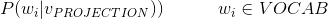
表示给定上下文单词
时,生成中心单词
的概率。这个值是通过对整个字典中的单词做softmax后得到的,具体的计算公式如下:
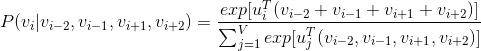
其中,
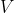
表示词典的大小,
表示上下文单词的向量。这里不好理解的是
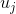
。在上一步的查表中,可以得知向量

就是上下文单词的词向量,因为
就是通过一个one-hot编码的向量和词向量矩阵进行矩阵乘法得到的。
就是输出层矩阵
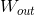
中的一行。在李沐的“动手学深度学习”教程中,将
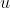
和
看成是一个单词的两套词向量,即
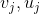
是同一个单词
的两个词向量,对应到CBOW的结果图中,就是一个是输出矩阵中的行,一个输入矩阵中的行。我个人认为这个解释不是太有力,我更倾向于
是一个打分权重,这个打分权重可以理解为在当前上下文输入下,输出单词为
的得分是多少,类似于logistic regression中的权重系数。
模型的损失函数及优化
在讲解CBOW模型的损失函数和参数优化前,可以先看看训练数据是什么样子的。假设训练数据是一段文本,长度为T,则在CBOW模型下,训练样本的格式如下:
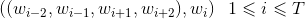
训练数据是从长度为T的文本中抽取的,可以抽取很多个上式表达的训练数据。有训练数据,同时我们又建立了概率模型,那么我们就可以定义一个似然函数,使得训练集中样本的似然概率最大。
生成这一段文本的似然概率如下:
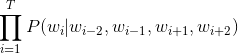
其中,
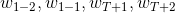
不存在,会用特殊的占位符替换。上式就是CBOW的目标函数,为了学习到合适的词向量,需要最大化上述似然函数的值,这等价于最小化如下损失函数的值:
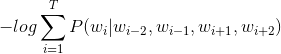
将具体的概率公式替换。可得
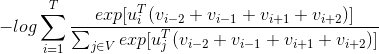
这个cost fucntion是关于
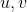
的函数,对上式求关于
的倒数,使用随即梯度下降方法,多次迭代,既可以找到最优值。



















