1、Spark处理数据是基于内存的,而MapReduce是基于磁盘处理数据的 2、Spark在处理数据时构建了DAG有向无环图,减少了shuffle和数据落地磁盘的次数 3、Spark比MapReduce快 4、Spark是粗粒度资源申请,而MapReduce是细粒度资源申请 5、MapReduce的Task的执行单元是进程,Spark的Task执行单元是线程
可回答:1)HBase一个节点宕机了怎么办;2)HBase故障恢复参考答案:1、HBase常见故障导致RegionServer故障的原因:FullGc引起长时间停顿HBase对Jvm堆内存管理不善,未合理使用堆外内存Jvm启动参数配置不合理业务写入或吞吐量太大写入读取字段太大HDFS异常读取写入数据都是直接操作hdfs的,若hdfs发生异常,会导致region server直接宕机机器宕机物理节点
寻址时间:HDFS中找到目标文件block块所花费的时间。 原理:文件块越大,寻址时间越短,但磁盘传输时间越长;文件块越小,寻址时间越长,但磁盘传输时间越短。
简单介绍Hadoop
面试题答案参考:https://blog.51cto.com/u_15553407/56030421、实习经历这点不多说了,根据自己的来就行2、工作中最难的点一般都会提前回顾之前自己遇到的问题,根据自己的来3、如何保证数据质量这里主要是阿里对数仓的一些数据质量保证原则1、数据质量保障原则阿里对数据仓库主要从四个方面评估数据质量1)完整性确保数据不存在缺失2)准确性确保数据不存在异常或错误3
阿里云大数据开发三面面经,已过,面试题已配答案
阿里云大数据开发二面面经,已过,面试题已配答案
阿里云大数据开发一面面经,已过,面试题已配答案
2、常规性能调优二:RDD优化1)RDD复用在对RDD进行算子时,要避免相同的算子和计算逻辑之下对RDD进行重复的计算,如下图所示对上图中的RDD计算架构进行修改,得到下图所示的优化结果2)RDD持久化在Spark中,当多次对同一个RDD执行算子操作时,每一次都会对这个RDD以之前的父RDD重新计算一次,这种情况是必须要避免的,对同一个RDD的重复计算是对资源的极大浪费,因此,必须对多次使用的R
1、常规性能调优一:最优资源配置Spark性能调优的第一步,就是为任务分配更多的资源,在一定范围内,增加资源的分配与性能的提升是成正比的 ,实现了最优的资源配置后,在此基础上再考虑进行后面论述的性能调优策略。资源的分配在使用脚本提交Spark任务时进行指定,标准的Spark任务提交脚本如代码清单所示/usr/opt/modules/spark/bin/spark-submit \ --c
1、数据倾斜Spark中的数据倾斜问题主要指shuffle过程中出现的数据倾斜问题,是由于不同的key对应的数据量不同导致的不同task所处理的数据量不同的问题例如,reduce点一共要处理100万条数据,第一个和第二个task分别被分配到了1万条数据,计算5分钟内完成,第三个task分配到了98万数据,此时第三个task可能需要10个小时完成,这使得整个Spark作业需要10个小时才能运行完成,
1、故障排除一:控制reduce端缓冲大小以避免OOM在Shuffle过程,reduce端task并不是等到map端task将其数据全部写入磁盘后再去拉取,而是map端写一点数据,reduce端task就会拉取一小部分数据,然后立即进行后面的聚合、算子函数的使用等操作reduce端task能够拉取多少数据,由reduce拉取数据的缓冲区buffer来决定,因为拉取过来的数据都是先放在buffer中
1.请列举出在 JDK 中几个常用的设计模式?单例模式(Singleton pattern)用于 Runtime,Calendar 和其他的一些类中。工厂模式(Factory pattern)被用于各种不可变的类如 Boolean,像 Boolean.valueOf,观察者模式(Observer pattern)被用于 Swing 和很多的事件监听中。装饰器设计模式(Decoratordesign
何谓悲观锁与乐观锁乐观锁对应于生活中乐观的人总是想着事情往好的方向发展,悲观锁对应于生活中悲观的人总是想着事情往坏的方向发展。这两种人各有优缺点,不能不以场景而定说一种人好于另外一种人。悲观锁总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁(共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程)。传
1、请解释一下什么是 Nginx?Nginx 是一个 web 服务器和反向代理服务器,用于 HTTP、HTTPS、SMTP、POP3 和 IMAP 协议。2、请列举 Nginx 的一些特性。Nginx 服务器的特性包括:反向代理/L7 负载均衡器嵌入式Perl 解释器动态二进制升级可用于重新编写URL,具有非常好的 PCRE 支持4、请解释 Nginx 如何处理 HTTP 请求。Nginx 使用反
大数据面试题——Flink面试题
1、Kafka 都有哪些特点?高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个topic可以分多个partition, consumer group 对partition进行consume操作。可扩展性:kafka集群支持热扩展持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失容错性:允许集群中节点失败(若副本数量为n,则允许n
问过的一些公司:头条, 字节,阿里 x 3,腾讯,竞技世界参考答案:1、容错方式容错指的是一个系统在部分模块出现故障时还能否持续的对外提供服务,一个高可用的系统应该具有很高的容错性;对于一个大的集群系统来说,机器故障、网络异常等都是很常见的,Spark这样的大型分布式计算集群提供了很多的容错机制来提高整个系统的可用性。一般来说,分布式数据集的容错性有两种方式:数据检查点和记录数据的更新。面向大规模
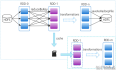
在执行Spark 的应用程序时,Spark 集群会启动 Driver 和 Executor 两种 JVM 进程,前者为主控进程,负责创建 Spark 上下文,提交 Spark 作业(Job),并将作业转化为计算任务(Task),在各个 Executor 进程间协调任务的调度,后者负责在工作节点上执行具体的计算任务,并将结果返回给 Driver,同时为需要持久化的 RDD 提供存储功能。下方内容中的
1、相关问题描述当我们使用spark sql执行etl时候出现了,可能最终结果大小只有几百k,但是小文件一个分区有上千的情况。这样就会导致以下的一些危害:hdfs有最大文件数限制;浪费磁盘资源(可能存在空文件);hive中进行统计,计算的时候,会产生很多个map,影响计算的速度。2、解决方案1) 方法一:通过spark的coalesce()方法和repartition()方法val rdd2 =
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据处理模型。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。RDD特点RDD表示只读的分区的数据集,对RDD进行改动,只能通过RDD的转换操作,由一个RDD得到一个新的RDD,新的RDD包含了从其他RDD衍生所必需的信息。RDDs之间存在依赖,RD
数仓分层介绍
1 Flink Job的提交流程用户提交的Flink Job会被转化成一个DAG任务运行,分别是:StreamGraph、JobGraph、ExecutionGraph,Flink中JobManager与TaskManager,JobManager与Client的交互是基于Akka工具包的,是通过消息驱动。整个Flink Job的提交还包含着ActorSystem的创建,JobManager的启动
1 Flink是如何支持批流一体的?本道面试题考察的其实就是一句话:Flink的开发者认为批处理是流处理的一种特殊情况。批处理是有限的流处理。Flink 使用一个引擎支持了DataSet API 和 DataStream API。2 Flink是如何做到高效的数据交换的?在一个Flink Job中,数据需要在不同的task中进行交换,整个数据交换是有 TaskManager 负责的,TaskMan
1、简单介绍一下FlinkFlink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。并且Flink提供了数据分布、容错机制以及资源管理等核心功能。Flink提供了诸多高抽象层的API以便用户编写分布式任务:DataSet API, 对静态数据进行批处理操作,将静态数据抽象成分布式的数据集,用户可以方便地使用Flink提供的各种操作符对分布式数据集进行处理,支持Java、Scala
大数据面试题V3.0,523道题,779页,46w字
Hadoop主要组件如上图,主要是<font color=red>HDFS、MapReduce、YARN、Common</font>HDFSHDFS是一个文件系统,用于存储文件,通过目录树来定位文件。其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。HDFS 的使用场景:适合一次写入,多次读出的场景。一个文件经过创建、写入和关闭之后就不需要改变
1、先说下Hadoop是什么Hadoop是一个分布式系统基础架构,主要是为了解决海量数据的存储<和海量数据的分析计算问题。2、说下Hadoop核心组件Hadoop自诞生以来,主要有Hadoop 1.x、2.x、3.x三个系列多个版本;Hadoop 1.x组成:HDFS(具有高可靠性、高吞吐量的分布式文件系统,用于数据存储),MapReduce(同时处理业务逻辑运算和资源的调度),Common
大数据面试题V2.0主要是从牛客上摘取一些别人分享的大数据面试题,然后给出一些参考答案,这件事还是一直都在坚持,从牛客上pa数据,然后被封号,然后再接再厉,最近终于完成了。
Copyright © 2005-2024 51CTO.COM 版权所有 京ICP证060544号