1、单一职责原则就一个类而言,应该仅有一个引起它变化的原因。如果一个类承担的职责过多,就等于把这些职责耦合在一起,一个职责的变化可能会削弱或者抑制这个类完成其他职责的能力。这种耦合会导致脆弱他的设计,当变化发生时,设计会遭受到意想不到的破坏;软件设计真正要做的许多内容就是发现职责并把那些职责相互分离。2、开放-封闭原则软件实体应该可以扩展,但不可修改。该原则是面向对象设计的核心所在,遵循这个原则可
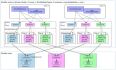
在深入学习大数据平台技术之前,需要对大数据平台的整体架构有一定的了解。本文将以目前主流的Lambda架构来介绍大数据平台的整体架构。大数据平台的架构还有另一种实现形式,即Kappa架构。Kappa架构的核心思想是使用流处理取代批处理,因此Kappa架构在处理离线数据时将会显得力不从心。基于这样的原因,目前大数据平台的主流架构依然是Lambda架构。大数据平台的总体架构可以分为五层,分别是:数据源层
1.Solr5.2.1安装1.1 Solr版本要求必须是5.2.1,见官网1.2 Solr下载:http://archive.apache.org/dist/lucene/solr/5.2.1/solr-5.2.1.tgz1.3 解压solr-5.2.1.tgz到/opt/module/目录下面 [kris@hadoop2 module]$ tar -zxvf solr-5.2.1.tgz -C
为什么说 CDC 是SeaTunnel平台中的一个重要功能特性?今天这篇文章跟大家分享一下 CDC 是什么?目前市面上的 CDC 工具现有的痛点有哪些?SeaTunnel面对这些痛点设计的架构目标是什么?另外包括社区的展望和目前在做的一些事情。总体来说,市面上已经有这么多 CDC 工具了,我们为什么还要重复去造一个轮子?带着这个疑问,我先给大家简要介绍下 CDC 是什么! CDC 的全称是 Cha
1. 实时需求日趋迫切目前各大公司的产品需求和内部决策对于数据实时性的要求越来越迫切, 需要实时数仓的能⼒来赋能 。传统离 线数仓的数据时效性是 T+1,调度频率以天为单位,⽆法⽀撑实时场景的数据需求 。即使能将调度频率设置成⼩时,也只能解决部分时效性要求不高的场景,对于实效性要求很高的场景还是⽆法优雅的⽀撑 。因此实时使&n
1.涉及内容:背景提取颜色过滤边缘检测用于对象识别的特征匹配一般对象识别你将需要两个主要的库,第三个可选:python-OpenCV,Numpy 和 Matplotlib。2.加载图片首先,我们正在导入一些东西,我已经安装了这三个模块。接下来,我们将img定义为cv2.read(image file, parms)。默认值是IMREAD_COLOR,这是没有任何 alpha 通道的颜色。如果你不熟
1. 概述数字化时代,数据正在以超凡的速度渗Tou到每个行业的业务领域,成为重要的生产要素。合理利用数据不仅能够提升企业竞争力,甚至还可以再造企业的商业模式。然而,拥有了数据并不等于就拥有了数据价值,只有实施有效的数据治理策略,才能持续输出高质量数据,释放数据价值。2. 什么是数据治理2.1 从管理者视角看数据治理是企业发展战略的组成部分,是指导整个集团进行数字化变革的基石,要将数据治理纳入企业的
1.Azure Data Lake StoreThe Azure Data Lake Store destination writes data to the Microsoft Azure Data Lake Store. You can use the Azure Data Lake Store destination in standalone and cluster batch pipel
1.Amazon S3The Amazon S3 destination writes data to Amazon S3. To write data to an Amazon Kinesis Firehose delivery system, use the Kinesis Firehose destination. To write data to Amazon Kinesis Stream
1. 基本概念1.1 什么是注册中心?注册中心主要有三种角色:服务提供者(RPC Server):在启动时,向 Registry 注册自身服务,并向 Registry 定期发送心跳汇报存活状态。服务消费者(RPC Client):在启动时,向 Registry 订阅服务,把 Registry 返回的服务节点列表缓存在本地内存中,并与 RPC Sever 建立连接。服务注册中心(Registry):
下载地址:https://github.com/qingduyu/roe1. 基本需求1.1 系统推荐配置生产建议使用:8核以上(python相当消耗cpu),16G以上内存 (数据传输很大的),磁盘 350G 以上测试建议使用:cpu 4核以上,ram 8G以上,disk 50G以上1.2 基础软件需求python2.7 (自编译), mysql 5.6以上(暂时不做安装教程
DestinationsA destination stage represents the target for a pipeline. You can use one or more destinations in a pipeline.You can use different destinations based on the execution mode of the pipeline.
1.1.DirectoryThe Directory origin reads data from files in a directory. The origin can use multiple threads to enable the parallel processing of files.The files to be processed must all share a file n
1.Amazon S3The Amazon S3 origin reads objects stored in Amazon S3. The object names must share a prefix pattern and should be fully written. To read messages from Amazon SQS, use the Amazon SQS
1.File TailThe File Tail origin reads lines of data as they are written to an active file after reading related archived files in the same directory. File Tail generates a record for each line of data
1.Data Formats1.1.Data Formats OverviewData formats - such as Avro, JSON, and log - are methods to encode data that adhere to generally accepted specifications.The way that stages process data can be
1.1. Pipeline Designer UIThe following image shows the Pipeline Designer UI when you configure a pipeline: AREA/ICONNAMEDESCRIPTION1Pipeline canvasDisplays the pipeline
1. 管道概念和设计1.1.设计数据流你能在 pipeline 中分支或者合并一个数据流.1.1.1. 数据流分叉When you connect a stage to multiple stages, all data passes to all connected stages. You can configure required fields for a stage t
udf也称作user define function,即用户自定义函数,是一个统称,主要分为三类操作单个数据行,产生单个数据行 ---- udf操作单个数据行,产生多个数据行作为一个表输出 ---- udtf (table)操作多个数据行,产生一个数据行 ---- udaf(aggregate)https://cwiki.apache.org/confluence/displa
1Data Analytics简介Data Analytics是由DataHunter(北京数猎天下科技有限公司)自主研发的一款企业级业务数据可视化分析产品。其基于探索式分析技术,以最新的数据自服务理念为核心,具备操作简单、部署灵活、秒级响应等特点。Data Analytics可广泛应用于各行各业,从百亿级数据量的企业到各垂直中小企业,专注解决各行业的业务数据分析需求。Data Analytics
先说大致的结论(完整结论在文末):在语义相同,有索引的情况下:group by和distinct都能使用索引,效率相同。在语义相同,无索引的情况下:distinct效率高于group by。原因是distinct 和group by都会进行分组操作,但group by可能会进行排序,触发filesort,导致sql执行效率低下。基于这个结论,你可能会问:为什么在语义相同,有索引的情况下,group
1.功能介绍 metabase是一款开源的BI分析工具,开发语言clojure+React为主、也有高阶的收费版。 官网:https://www.metabase.com/ 可以利用Metabase进行数据分析,数据可视化,报表生成等。开源地址:https://github.com/metabase/metabase官网学习地址:https:/
1、DataSophon是谁开源的?国内某大厂2、DataSophon想干嘛?致力于快速实现部署、管理、监控以及自动化运维大数据服务组件和节点的能力,帮助您快速构建起稳定,高效的大数据集群服务。3、DataSophon是什么?DataSophon是致力于自动化监控、运维、管理大数据基础组件和节点的,帮助您快速构建起稳定,高效的大数据集群服务。4、DataSophon都有哪些特性?极易部署,1小时可
1、概述在大数据领域,肯定有很多小伙伴跟笔者一样为了让生产中数据执行速度更快、性能更高而去使用Spark,当我们用Spark程序实现功能开发并使程序正常稳定运行起来的时候,一定是非常有成就感的;但是随着数据量的增加以及需求的完善,我们就开始关注我们这个程序能否做到在运行起来的时候让数据查询更快、让页面响应更快、尽可能的节省空间占用率;而前面提到这些"美好的设想"其实是由很多方面决定的,由很多部分组
1、MySQL8新建用户create user 'firestone'@'%' identified by '123456';2、给用户授予test库所有权限grant all privileges on firestone_pretank.* to 'firestone'@'%' ;3、刷新权限flush privileges;4、使用navicat链接测试5、点击右键新建表6、弹出异常如下,1
RGB代表红绿蓝。大多数情况下,RGB颜色存储在结构或无符号整数中,蓝色占据最不重要的“区域”(32位和24位格式的字节),绿色第二少,红色第三少。BGR是相同的,除了区域顺序颠倒。红色占据最不重要的区域,绿色占第二位(静止),蓝色占第三位。示例:#FF0000在读取为RGB十六进制颜色(#rrggbb)时为纯红色,因为第三个区域(数字从右向左读取!)为FF(最大值,全彩色),其他两个区
1、前言1950年,图灵发表了具有里程碑意义的论文《计算机器与智能》(Computing Machinery and Intelligence),提出了一个关于机器人的著名判断原则——图灵测试,也被称为图灵判断,它指出如果第三者无法辨别人类与AI机器反应的差别, 则可以论断该机器具备人工智能。2008年,漫威《钢铁侠》中的AI管家贾维斯,让人们知道了AI是如何精准地帮助人类(托尼)解决丢过来的各种
1、简介DataSophon是近日开源的一款国产自研大数据管理平台,致力于快速实现部署、管理、监控以及自动化运维大数据服务组件和节点的能力,帮助你快速构建起稳定、高效的大数据集群服务。2、主要有以下特性:极易部署,1小时可完成300节点的大数据集群部署 国产化兼容,兼容ARM服务器和常用国产化操作系统 监控指标全面丰富,基于生产实践展示用户最关心的监控指标 灵活便捷的告警服务,可实现用户自定
1、本内容你将获得ELK 单机版本安装启动并配置 logstash 配置(此处只为 demo)1.1docker快速体验以下快速体验只为开发过程临时使用,数据未做安全配置,方便用于开发过程docker run \ --name acp-es \ --restart always -d \ -p 9200:9200 \ -p 9300:9300 \
Copyright © 2005-2024 51CTO.COM 版权所有 京ICP证060544号