
2019年总算书印刷出来了。我最近很认真的读了一遍,虽然其中的大部分内容,自己已经在不同的场合宣讲过有近百次了。但再读一下还是依然会有些不同的收获,有点像在看看当时的初衷。毕竟我们交稿在17年初,定稿基本在16年中。而微众的整个架构的历史,差不多也就刚刚5年。所以这本书的内容,正好是我们到现在的半程。从现在回看,在架构上有坚持,有优化,也有重构。
对于微众银行的IT架构来说,我自己感觉非常值得骄傲的一件事,就是我们坚定的落实了自己原本的初衷,说到的,都做到了。在初期规划的时候,希望通过融合互联网和金融,找到一个自主可控的架构。这在银行行业,没有先验的经验可循,不过从技术的角度对于交易和账务的系统架构设计本身,还是有一些可以参考的例子。所以如同书中所讲,我们选择了“全流程系统”+“数据分布式”+“系统分布式” DCN(Data Center Node)来构建整个银行IT架构的创新方案。

从一开始上线,这样的架构就给我们带来了重要的科技优势:
1、通过业务全流程,很好的支持了创新,不同业务清晰隔离。降低了运维和变更代码的风险。
2、通过数据+系统的分布式,降低了绝大多数故障的影响面,即使对于单一业务,也没有出现过大面积不可用。
3、通过系统的分布式,引入的灰度发布,基本消除了程序Bug所引发的故障级事故。
4、标准的X86服务器和开源软件,带来的扩容和运行的成本降低。
但所有的事情都是有另外一面的,所以我们这几年一直在不停的优化和重构来改善我们的IT架构。当时17年的架构的核心问题体现在:
1、在两地三中心的架构下,在主备模式下故障的恢复是依赖主备切换的,这并不理想,而且通过高冗余带来的一致性保障,也不够经济,不利于做创新业务;
2、当数据库和中间件都构建在X86的物理服务器上时,X86服务器的故障率,导致我们时不时的要面对硬件故障引发的切换和隔离;
3、面对越来越多的部署单元,越来越多的服务器,运维难度逐渐变大。在自动化和人工确认之间要寻找一个平衡点。
一、多中心多活的总体架构
从17年开始,在书中也提到了,我们就开始落实同城三中心多活架构。这个架构下的2个重要的基础方案,一个是书中提到的的我们要把数据库部署从每个中心的一主两从,修改为三个中心三个节点,另外一个的核心技术方案就在于同城IDC之间的网络稳定性和流量的保障。
下面是我们多中心多活的总逻辑架构图
在这个架构下,我们在尽量消除任何单一中心的不可用带来的影响,所以是多层面的分布式和多活,从外联的接入开始,所有流量可以跨数据中心分配。到消息总线的多中心多活,以及刚刚提到的数据库三中心部署。
架构首先带来的好处,是没有主备架构,单个数据中心的局部故障,会自动由另外一个数据中心的服务承载,基本没有切换的动作。负载均衡服务和消息总线自动去跨数据中心流转流量。
其次,整体服务器的消耗降低了,我们大大减少了数据的冗余数量,在把可用性和一致性提高到了更高的等级的同时,降低了成本。
而这个多活的基础,首先就是网络,跨IDC的网络流量,会和传统的主备模式,完全不一样。
二、同城跨IDC多平面网络
我们通常关心的都是数据中心内部的网络服务,因为以往的很多线上服务,还是以IDC为边界的。一旦出IDC,都是要经过外联区,或者是核心防火墙。通常意味着要流量汇聚,但这会导致系统是要感知自己的调用是否跨IDC,并且要特殊处理,这是无法在跨数据中心的做多活架构的;或者有专门的中间件汇聚流量,而这会导致这部分中间件增加了故障的风险。
所以首先解决的是底层网络的问题,我们在同城的IDC之间,构建了一张多平面的网络。我们把它叫做MDTP多平面数据传输平台(Multi-Plane Data Transfer Platform)

在这样一个网络中,所有数据中心的相同网络区域被放在同一平面中,对于应用系统程序来说,是逻辑上的一个IDC,不用考虑跨数据中心和不跨数据中心的区分。一个城市里的IDC数据中心我们可以看成由一个个大规模数据中心网络集群来提供整体服务,即IDC As a Computer,而网络则为这台Computer提供高速的IO接口与通信管道,同时多平面网络有三个最为重要的特性:
1、每个IDC我们提供了在这个平面网上的400G的出口带宽能力,因为一旦我们把多个物理IDC组织成一个逻辑IDC互通,那么跨中心的流量会比常规的主备中心来说,高出很多。
2、每个IDC有4个不同路由光路接入多平面数据平台,任一个光路发生了抖动,我们可以在50ms内完成自动切换。
3、每个IDC的互联网出口流量可以快速的精准的按需在IDC间平滑调度,不依赖商业硬件多中心多活解决方案。
多平面解决的是应用系统对跨IDC的流量的无感,但底层PaaS的组件,是必须清楚自己所在的物理IDC和运行状态的,这样才能简化应用的开发;不仅如此,PaaS要解决的核心的问题是多IDC的IaaS层的稳定性带来的挑战。
三、自研的分布式消息总线DeFiBus
多活的前提,就是系统间的调用流量可以自动跨数据中心调度,当然,在本数据中心服务可用的情况下,应该优先通过本数据中心提供服务,因为跨数据中心带来的是每次额外1ms的调用延迟的增加。要保证这个跨IDC的调度,需要做到很多特性,例如:支持多中心多活,支持多种调用方式;平滑升级扩容,能够对故障自动隔离;系统自我保护,在故障时保证消息送达。我着重介绍其中两点:
1、消息总线要屏蔽数据中心之间的差异,所以消息总线要自己能够跨数据中心调度消息,这样每个数据中心的系统,默认只需要连接本数据中心的消息总线服务器,可以让部署和运维更加简单。调用方和服务方不需要知道彼此在哪个不同的位置。这就是要求消息总线的集群要能够做跨数据中心多活。
2、消息总线要保证同步调用类的消息的送达,因为对金融交易来说,最麻烦的是不确定状态,以及丢失消息,这和互联网的接受有损服务是有本质不同的,所以即使服务可以很快的从一个数据中心的主机上切换到另外一个数据中心,切换时间内的超时交易和丢失交易,对账务系统来说也是很难接受的。所以消息总线要自己有分布式的消息保证送达机制,当消息总线的服务器自身故障,或者业务系统服务器故障的时候,要能够有异常消息处理能力,降低切换到带来的交易损失。
下面是我们的DeFiBus的总体架构图:
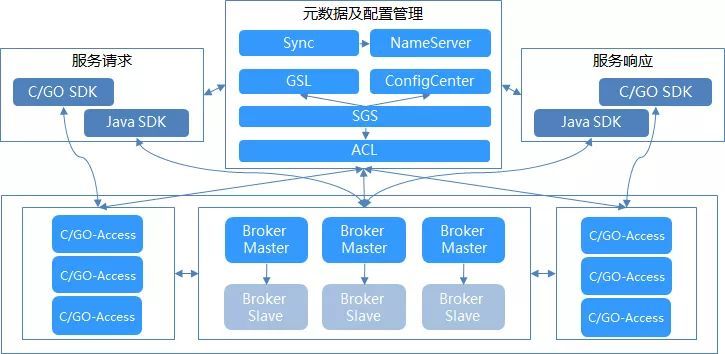
我们通过消息总线的几年的迭代和优化,逐步解决了大部分应用服务器的X86硬件故障带来的影响。但面临越来越多的服务器,越来越多的系统,使用自动化工具有效的处理事件和故障,就显得尤为重要。但整体的运维工具和运维方法又密切相关,在今后的文章中,我们可以单独就分布式核心架构的运维方法和工具进行介绍。
四、优化和重构后的架构效果
从16年中到19年底,我们的IDC已经从两地三中心发展成两地七中心,在深圳的同城五中心里面,应用三中心多活架构。在18年我们投产其中一个中心后,在晚上19:02进行了数据中心断网演练,一个承载了业务的数据中心,直接从生产网络中隔离,整体的交易没有丢失和超时,交易耗时在经历了大致几分钟的一个突增后,逐步稳定到正常状态。交易耗时的增加,是因为一个数据中心的隔离,会导致非常多的负载均衡和消息总线服务进行重平衡。这个过程需要一定的时间。但不会影响正在进行的交易。而且19年我们在另一个数据中心,选择了2个机架的断网,这次整体的业务表现就更加平稳,DefiBus重平衡所带来的交易耗时增加的时间,只是18年的十分之一以内。对于大部分TPS不高的系统来说,完全做到平滑无感的切换。
目前数据中心之间的流量,最大的已经超过50G,尽管交易已经多中心多活,但如上面所说离线分析的大数据平台和各种管理类应用,必须是集中主备式的,所以最大流量最终会体现在其中一两个数据中心。我们的全网的DeFiBus,生产上数十套集群,每日处理消息总和数已经达到了十亿级的规模。生产上每日都有几台物理的服务器发生故障,而这些故障,在DeFiBus的容错机制下,对应用的影响越来越小。我们规模越来越大,但是因为基础设施的硬件故障引发的事件的频次和数量越来越少。整体基础架构的运维工作,越来越多人力投入到工具的开发和主动预防工作之中。
在2018年的年报中,我们当年的每账户科技运维成本下降了45%,提升了对业务开展的支持力度,在普惠金融的长尾客群中,我们的服务成本每降低一点,可以覆盖的人群就会多出很多。
五、写在最后
任何一个银行的系统,实际上是分成两大部分的,一部分是实时交易的账务处理系统,一部分是离线的分析系统。在《新一代银行IT架构》一书中,我们重点介绍了实时交易的在线交易系统的架构思路和方案。对于IT基础设施的重要成本构成的离线分析系统的架构,微众银行同样摸索出了一条安全可控,金融级,一站式,低成本的解决方案。这部分虽然不及核心系统的复杂度和分布式的重要意义,但解决方案的确是各个金融机构不可或缺的,也是在现在这个大数据时代,最有痛点的部分。我们会在以后专门介绍这部分的内容出来。


















