
原文地址
1. 什么是信息?
信息的定义涉及概率论中的随机事件概率,如果待分类事物可能划分在多个分类之中,则符号 Xi的信息定义为:
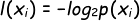
其中 p(xi) 是选择该分类的概率。(该定义来自于《机器学习实战》P35)
举个例子:已知事件 X 的概率分布如下,计算符号 X 的信息:
X | X0 | X1 |
p | 0.5 | 0.5 |
l(x0) = -log2p(x0) = -log2(0.5) = 1
l(x1) = l(x0) = 1
说明:
- 信息永远≥ 0;
- 确定事件(p = 1),信息 = 0;
这里引用香农《信息论》的一句话来帮助理解信息的物理含义:
“logn(q)表示具有总概率q的那些最可能序列为了描述序列所需要的二进制位数”。
可见信息的物理含义是通信编码所需要的比特数。结合上面的例子,X 有两种取值,用 1bit 就可以编码。与计算出的 信息 = 1
2. 什么是熵?
熵定义为:信息的数学期望。
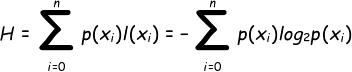
所以熵的本质也还是信息,信息的本质是编码所需的比特位数。所以熵也是来衡量编码位数的。
我们知道熵越大,就越无序,越混乱。直觉上一个确定的事件熵应该 = 0。
下面举几个例子
----------------------------------------------------------------------------------------------------
已知事件X
X | X0 | X1 |
p | 1 | 0 |
计算 X
根据公式,熵 H
l(x0) = -log2(p(x0)) = -log2(1) = 0
l(x1) = -log2(0) = -Infinity
所以 H = l(x0) * p(x0) + l(x1) * p(x1) = 0 * 1 - 0 * Infinity = 0,结果与确定事件熵为 0 相吻合。
----------------------------------------------------------------------------------------------------
已知事件 X
X | X0 | X1 |
p | 0.5 | 0.5 |
计算 X
l(x0) = l(x1) = -log2(0.5) = 1
H = 0.5 * 1 + 0.5 * 1 = 1,可见不确定事件比确定事件熵要大,即数据更混乱。
----------------------------------------------------------------------------------------------------
X
X | X0 | X1 | X2 |
p | 1/3 | 1/3 | 1/3 |
X
首先直觉上猜测一下这次 X
l(x0) = l(x1) = l(x2) = -log2(1/3) = 1.585
H = 3 * 1.585 * 1/3 = 1.585
----------------------------------------------------------------------------------------------------
可见:
- 确定事件熵最小 = 0;
- 随机事件 X
前边理解的熵其实也是一种编码所需的比特位数的一种度量参数。
例 1 中,确定事件无需编码,0 个bit位,与计算出的熵 = 0 吻合;
例 2 中,两种情形的等概率事件,1 个bit位就可以编码,与计算出的熵 = 1吻合;
例 2 中,三种情形的等概率事件,2 个bit位就可以编码,与计算出的熵 = 1.58 ≈ 2 也算吻合;(如果是四种情形的话就正好等于2!)
下面引用一些《信息论》中的图片和文字。
具有概率 p 和 q = 1 - p
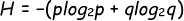
熵与 p

说明:
- 当且仅当所有概率pi 除了一个之外其余所有概率 = 0 时, H = 0。换句话说,仅仅在结果完全确定的情况下 H 才 = 0,否则 H > 0;
- 如果所有的 pi 相等,即 pi = 1/n,则 H 取得最大值 = logn。这对应着最不确定,最混乱的情形;
- 任何一种使概率p1, p2, ..., pn 趋于均等的变动,都会使 H 增大。
后记:
在 Tom M. Mitchell 著的《Machine Learning》P41 关于熵的解释写到:
“信息论中的熵的一种解释是,熵确定了要编码集合 S 中任意成员(即以均匀的概率随机抽取的一个成员)的分类所需要的最少的二进制位数。”


















