Flink使用 DataSet 和 DataStream 代表数据集。DateSet 用于批处理,代表数据是有限的,而 DataStream 用于流数据,代表数据是无界的。数据集中的数据是不可以变的,也就是说不能对其中的元素增加或删除。我们通过数据源创建 DataSet 或者 DataStream ,通过 map,filter 等转换(transform)操作对数据集进行操作产生新的数据集。
编写
转载
2020-03-15 17:25:00
53阅读
2评论
上一篇介绍了编写 Flink 程序的基本步骤,以及一些常见 API,如:map、filter、keyBy 等,重点介绍了 keyBy 方法。本篇将继续介绍 Flink 中常用的 API,主要内容为:
1.指定 transform 函数2.Flink 支持的数据类型3.累加器
1、指定 transform 函数——转换操作许多 transform 操作需要用户自定义函数来实现,Flink 支持多种自
转载
2020-03-24 11:37:00
87阅读
2评论
输入: 1689999831,test,31.25。
原创
2024-03-29 16:29:15
25阅读
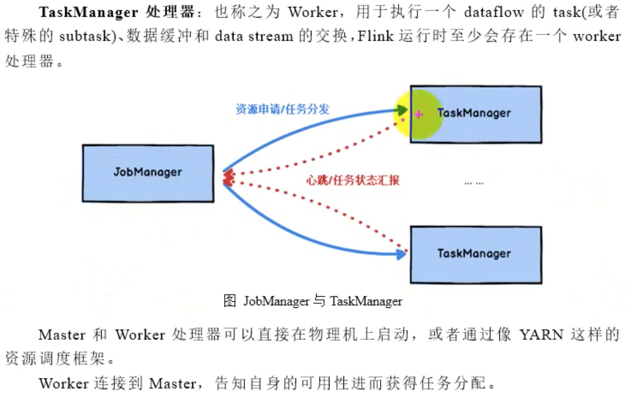
一、Flink 整体架构 Flink 集群整体遵循 Master ,Worker 这样的架构模式。JobManager 是管理节点,有以下几个职责:接受 application,包含 StreamGraph(DAG),JobGraph(优化过的)和 JAR,将 JobGraph 转换为 Execution Graph申请资源,调度任务,执行任务,保存作业的元数据,如Checkpoint协调各个
转载
2024-07-28 14:12:58
46阅读

本文分享自天翼云开发者社区《Flink
与Flink可视化平台StreamPark教程(DataStreamApi基本使用)》,作者:l****nDataStreamApidataStreamApi是一切的基础,处于调度flink程序处理任务的起点。Flink 有非常灵活的分层 API 设计,其中的核心层就是 DataStream/DataSet API。由于新版本已经实现了流批一体,DataSe
Queryable StateArchiectureClient连接其中的⼀个代理服务器然后发送查询请求给Proxy服务器,查询指定key所对应的状态数据,底层Flink按照KeyGroup的⽅式管理Keyed State,这些KeyGroup被分配给了所有的TaskMnager的服务。每个TaskManage服务有多个KeyGroup状态的存储。为了找到查询key所在的KeyGroup所属地Ta
转载
2024-09-25 20:16:59
31阅读
1 Flink简介Apache Flink® — Stateful Computations over Data StreamsApache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。1.1 处理无界和有界数据任何类型的数据都可以形成一种事件流。信用卡交易、传感器测量、机器日志、网
转载
2024-03-08 15:26:46
31阅读
PS: 这里常说的 Job = 一个应用Task = 一个任务总的来讲:1.Flink应用程序会首先提交给JobClient,做解析和算子链化2.然后会提交给JobManager,进行资源分配,将任务分给TaskManager3.TaskManager会启动相应的Slot线程,进行任务处理,在处理过程中会持续向JobManager,返回任务状态(任务开始,进行中,已完成等)4.任务执行完以后,执行
转载
2023-07-18 13:19:15
191阅读
、逻辑数据流图(logical dataflow graph)和打包了所有的类、库和其
转载
2024-03-25 05:04:44
69阅读
只支持AudioFormat.ENCODING_PCM_8BIT(8bit)和AudioFormat.ENCODING_PCM_16BIT(16bit)两种,后者支
转载
2023-11-17 16:01:50
513阅读
Flink的简介和简单的使用Flink的简介创建项目编写代码批处理流处理打包运行图形界面画的运行命令行运行Flink的简介Apache Flink 是一个框架和分布式处理引擎,用于对无界和有界数据流进行状态计算。Flink的主要特点事件驱动基于流的世界观:在 Flink 的世界观中,一切都是由流组成的,离线数据是有界的流;实时数据是一个没有界限的流:这就是所谓的有界流和无界流分层API:➢越顶层越抽象,表达含义越简明,使用越方便,越底层越具体,表达能力越丰富,使用越灵活创建项目.
原创
2022-03-23 10:21:19
372阅读
一、Flink概述1、什么是FlinkApache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算。Flink起源于2008年柏林理工大学的研究性项目Stratosphere2014年该项目被捐赠给了Apache软件基金会Flink一跃成为Apache软件基金会的顶级项目之一Flink的Lo
转载
2023-09-26 15:40:43
9阅读
文章目录窗口的概念窗口的分类按照驱动类型分类(1)时间窗口(2)计数窗口(Count Window)按照窗口分配数据的规则分类(1)滚动窗口(Tumbling Windows)(2)滑动窗口(Sliding Windows)(3)会话窗口(Session Windows)(4)全局窗口(Global Windows)窗口API概览按键分区窗口(Keyed)和非按键分区(Non-Keyed)代码中
转载
2024-01-29 23:59:41
78阅读
Flink简介 Apache Flink是一个分布式大数据处理引擎,可对有限数据流和无限数据流进行有状态或无状态的计算,能够不上在各种集群环境,对各种规模大小的数据进行快速计算。 Flink 是一个分布式的流处理框架,它能够对有界和无界的数据流进行高效的处理。Flink 的核心是流处理,当然它也能支持批处理,Flink
转载
2024-03-20 12:49:04
47阅读
DataStream API 开发1.Time 与 Window1.1 Time在 Flink 的流式处理中,会涉及到时间的不同概念,如下图所示: Event Time:是事件创建的时间。它通常由事件中的时间戳描述,例如采集的日志数据中, 每一条日志都会记录自己的生成时间,Flink 通过时间戳分配器访问事件时间戳。 Ingestion Time:是数据进入 Flink 的时间。 Processi
转载
2024-03-25 20:51:36
25阅读
程序与数据流 所有的Flink 程序都是由三部分组成:Source,Transformation 和Sink Source: 负责读取数据源数据 Transformation:利用各种算子进行处理加工 Sink:负责输出。Map 算子:对DataStream进行操作,返回一个新的DataStream将DataStream类型 转化为 DataStream类型。package com.lei.api
转载
2024-05-08 11:33:49
28阅读
Window是Flink的核心功能之一,使用好Window对解决一些业务场景是非常有帮助的。今天分享5个Flink Window的使用小技巧,不过在开始之前,我们先复习几个核心概念。Window有几个核心组件:Assigner,负责确定待处理元素所属的Window;Trigger,负责确定Window何时触发计算;Evictor,可以用来“清理”Window中的元素;Function,负责处理窗口
转载
2024-04-28 17:40:10
92阅读
(1)事件驱动型 1、什么是事件驱动型应用程序:事件驱动的应用程序是有状态的应用程序,它从一个或多个事件中提取事件,并通过触发计算,状态更新或外部操作来对传入的事件做出反应。 2、事件驱动型应用程序与传统应用程序的区别: 1)程序与数据的位置:传统应用程序不要求程序和程序使用的数据位于相同的机器上,数据的位置对程序来说无关紧要;事件驱动程序则要求数据本地性,这有利于数据的快速计算 2)
转载
2024-08-03 16:04:41
92阅读
探索如何使用Flink CEP写在前面前言的前言在学习Flink的过程中,我看过很多教程。无论是视频还是博文,几乎都把Flink CEP作为进阶内容来讲授。究其原因,大概是CEP涉及到的计算机基础知识很多,而我对于诸如NFA、DFA之类名词的印象,基本只停留在很多年前编译原理的课本上。那么如何在仅了解有限的基础知识的情况下,快速使用Flink CEP完成开发呢?实际上,在我的学习过程中,最大的困难
原创
2023-05-31 12:17:56
209阅读























