
一.两种×××模型
×××网络中几个重要的角色
CE(Custom Edge): 直接与ISP相连的用户设备
PE(Provider Edge Router): 指ISP骨干网上的边缘路由器,与CE相连,主要负责×××业务的拉入。
P(Provider Router): 指骨干网上的核心路由器,主要完成路由的快速转发功能。
由于网络的规模的不同,网络中可能不存在P路由器,PE路由器也可能同时是P路由器。
C-Network: 用户网络
P-Network: ISP网络
×××网络中几个重要的角色
CE(Custom Edge): 直接与ISP相连的用户设备
PE(Provider Edge Router): 指ISP骨干网上的边缘路由器,与CE相连,主要负责×××业务的拉入。
P(Provider Router): 指骨干网上的核心路由器,主要完成路由的快速转发功能。
由于网络的规模的不同,网络中可能不存在P路由器,PE路由器也可能同时是P路由器。
C-Network: 用户网络
P-Network: ISP网络
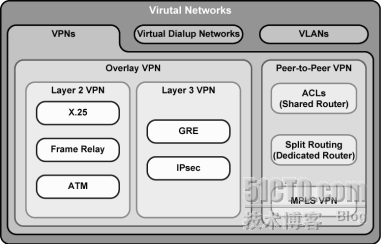
1. Overlay ×××
实现技术: X.25\FR\ATM; IP-over-IP(GRE、IPSEC)
①隧道建立在CE上
特点: CE之间通过ISP的P网络建立隧道传递路由信息,数据只在客户设备之间交换,ISP一无所知。
优点: 不同的客户地址空间可重叠,保密性、安全性好
缺点: ×××需要客户自己创建并维护,需要足够的技术力量
注: 此时PE和CE之间互联的地址是公网地址;ISP把CE看成一个普通的上网用户,与ADSL上网一样。
实现技术: X.25\FR\ATM; IP-over-IP(GRE、IPSEC)
①隧道建立在CE上
特点: CE之间通过ISP的P网络建立隧道传递路由信息,数据只在客户设备之间交换,ISP一无所知。
优点: 不同的客户地址空间可重叠,保密性、安全性好
缺点: ×××需要客户自己创建并维护,需要足够的技术力量
注: 此时PE和CE之间互联的地址是公网地址;ISP把CE看成一个普通的上网用户,与ADSL上网一样。
②隧道建立在PE上:
特点: PE为×××用户创建相应的GRE隧道,路由信息在PE之间传递,公网中P设备不知道私网路由;
优点: ×××由ISP维护,安全,保密性好;
缺点: 不同的×××用户不能共享相同的地址空间,即使共享,使用基于接口的策略路由,后期维护工程量大,现网中不太好实现。
特点: PE为×××用户创建相应的GRE隧道,路由信息在PE之间传递,公网中P设备不知道私网路由;
优点: ×××由ISP维护,安全,保密性好;
缺点: 不同的×××用户不能共享相同的地址空间,即使共享,使用基于接口的策略路由,后期维护工程量大,现网中不太好实现。
总结: Overlay ×××本质属于“静态”的×××,需要手工配置,所以他也具有类似于静态路由的所有缺陷:
①扩展性差
②无法反应网络的实时变化,隧道在CE,必须要求客户有足够的技术力量;在PE上则无法解决地址冲突问题。
①扩展性差
②无法反应网络的实时变化,隧道在CE,必须要求客户有足够的技术力量;在PE上则无法解决地址冲突问题。
2. Peer-to-Peer ×××
peer-to-peer解决了静态×××的弊端,但是需要CE和PE交换私网路由,然后在P网络中传播到达其他的PE上,进而解决了动态性问题(然后又出现安全性问题);往往CE和PE之间运行的路由协议和P网络中的路由协议是不同的,即使相同也要有很好的路由过滤和选择机制。
peer-to-peer解决了静态×××的弊端,但是需要CE和PE交换私网路由,然后在P网络中传播到达其他的PE上,进而解决了动态性问题(然后又出现安全性问题);往往CE和PE之间运行的路由协议和P网络中的路由协议是不同的,即使相同也要有很好的路由过滤和选择机制。
Peer-to-Peer ×××技术有:
共享PE接入技术
专用PE接入技术
①共享PE方式
问题: 地址空间重叠问题没有解决,无法现实区分不同客户(在PE上使用ACL将是一个非常繁琐的事)
②专用PE方式
问题:不用说了,价格无法接受,即使这样,这些PE还是要接到P设备上,还是无法区分!
共享PE接入技术
专用PE接入技术
①共享PE方式
问题: 地址空间重叠问题没有解决,无法现实区分不同客户(在PE上使用ACL将是一个非常繁琐的事)
②专用PE方式
问题:不用说了,价格无法接受,即使这样,这些PE还是要接到P设备上,还是无法区分!
总结:
没有使用隧道技术,私网路由在公网上跑,安全性很差。
×××的特性完全靠路由协议保证,导致CE无法配置缺省路由。
地址空间重叠问题依然存在。
没有使用隧道技术,私网路由在公网上跑,安全性很差。
×××的特性完全靠路由协议保证,导致CE无法配置缺省路由。
地址空间重叠问题依然存在。
3. 总结(主要问题):
①可以提供一种动态建立的隧道技术(MPLS中的LSP正好是一种动态的隧道)
②可以解决不同×××共享相同地址空间(使用动态路由协议BGP解决)
①可以提供一种动态建立的隧道技术(MPLS中的LSP正好是一种动态的隧道)
②可以解决不同×××共享相同地址空间(使用动态路由协议BGP解决)
二、MP-BGP
解决地址冲突的难题(方法)
①本地路由冲突问题,即:同一个台PE如何区分不同的×××的相同路由(VRF)
②路由传播过程中,两条相同的路由,对于接收者如何区分(RD )
③报文转发问题,即使成功的解决了路由表冲突,但PE接到一个IP报文时,又是怎么知道发到哪个×××(RT)
VRF(××× Routing & Forwarding Instance,×××路由转发实例): 每一个VRF可以看作一个虚拟的路由器,用于模拟一台专用的PE设备,该虚拟路由器包括4个元素:
a.一张独立的路由表,当然也包括了独立的地址空间。
b.一组归属于这个VRF的接口的集合。
c.一组只用于本VRF的路由协议。
d.一个RD和一组RT规则。
对于每个PE,可以维护一个或多个VRF,同时维护一个公网的路由表(也叫全局路由表),多个VRF实例相互分离独立。实现VRF并不困难,关键在于如何在PE上使用特定的策略规则来协调各VRF和全局路由表之间的关系。
a.一张独立的路由表,当然也包括了独立的地址空间。
b.一组归属于这个VRF的接口的集合。
c.一组只用于本VRF的路由协议。
d.一个RD和一组RT规则。
对于每个PE,可以维护一个或多个VRF,同时维护一个公网的路由表(也叫全局路由表),多个VRF实例相互分离独立。实现VRF并不困难,关键在于如何在PE上使用特定的策略规则来协调各VRF和全局路由表之间的关系。
RD(Route Distinguishers): 64bit,用来唯一区分IPV4路由(使重复的IPV4地址全局唯一),对SP(服务提供商)来说,如果有多个用户网络号都一样的话,用RD来区分不同的×××客户.
RD(64bit)+IPv4(32bit)=×××v4(96bit)
写法: AS:nn 或者A.B.C.D:nn
RD(64bit)+IPv4(32bit)=×××v4(96bit)
写法: AS:nn 或者A.B.C.D:nn
RT(Route Target):
RT是一种路由标记,当路由的导入和导出时,让接收端知道要发给哪些×××客户
发送端PE的export必须和接收端PE的import对应,只有对应上,接收端PE才会把路由加入VRF路由表
RT是一个扩展的communite属性,是用来过滤的。
可以分为两部分:
Export Target: 表示了我发出的路由属性.
Import Target: 表示了我对哪些路由感兴趣.
RT是一种路由标记,当路由的导入和导出时,让接收端知道要发给哪些×××客户
发送端PE的export必须和接收端PE的import对应,只有对应上,接收端PE才会把路由加入VRF路由表
RT是一个扩展的communite属性,是用来过滤的。
可以分为两部分:
Export Target: 表示了我发出的路由属性.
Import Target: 表示了我对哪些路由感兴趣.
三、BGP/MPLS ×××
1. CE与PE之间如何交换路由
①在PE上配置VRF
②PE维护独立的路由表,包括公网和私网(VRF)路由表
公网路由表:包含全部PE和P路由器之间的路由,由骨干网的IGP产生。
私网路由表:包含本×××用户可达信息的路由和转发表。
公网路由表:包含全部PE和P路由器之间的路由,由骨干网的IGP产生。
私网路由表:包含本×××用户可达信息的路由和转发表。
③PE和CE通过标准的EBGP,OSPF,RIP或者静态路由交换路由信息
(1)静态路由,RIP都是标准的协议,但是每个VRF运行不同的实例,相互之间没有干扰。与PE的MP-IBGP之间只是简单的redistribute操作。
(2)EBGP也是普通的EBGP,而不是MP-EBGP,只交换经过PE过滤后的本×××路由。
(3)OSPF则做了很多修改,可以将本SITE的LSA放在BGP的扩展community属性中携带,与远端×××中的OSPF之间交换LSA。每个SITE中的OSPF都可以存在area 0,而骨干网则可以看作是super area 0。此时的OSPF由两极拓扑(骨干区域+非骨干区域)变为三级拓扑(超级骨干区域+骨干区域+非骨干区域)。
(2)EBGP也是普通的EBGP,而不是MP-EBGP,只交换经过PE过滤后的本×××路由。
(3)OSPF则做了很多修改,可以将本SITE的LSA放在BGP的扩展community属性中携带,与远端×××中的OSPF之间交换LSA。每个SITE中的OSPF都可以存在area 0,而骨干网则可以看作是super area 0。此时的OSPF由两极拓扑(骨干区域+非骨干区域)变为三级拓扑(超级骨干区域+骨干区域+非骨干区域)。
2. VRF路由注入到MP-IBGP
PE路由器需要对一条路由进行几个操作:
①加上RD(手工配置),变为一条×××-IPv4路由
②更改下一跳属性为自己(通常是自己的loopback地址),类似于BGP的nexthop-self
③加上私网标签(随机自动生成,无需要配置)
④加上RT属性(手工配置),携带的RT为export属性
⑤发送给所有PE邻居
PE路由器需要对一条路由进行几个操作:
①加上RD(手工配置),变为一条×××-IPv4路由
②更改下一跳属性为自己(通常是自己的loopback地址),类似于BGP的nexthop-self
③加上私网标签(随机自动生成,无需要配置)
④加上RT属性(手工配置),携带的RT为export属性
⑤发送给所有PE邻居
3. MP-iBGP路由注入到VRF
远端PE收到路由后会将×××v4路由变为Ipv4路由,并且根据本地VRF的import RT属性加入到相应的VRF中,私网标签保留,做转发时使用。再由本VRF的路由协议引入并转发给相应的CE。
远端PE收到路由后会将×××v4路由变为Ipv4路由,并且根据本地VRF的import RT属性加入到相应的VRF中,私网标签保留,做转发时使用。再由本VRF的路由协议引入并转发给相应的CE。
此时的私网标签在进入VRF中时是保留的,为了与以后的路由更新比较,来判断是否是相同的。但路由给CE的时候是没有私网标签的。
4. 公网标签分配过程
①PE和P路由器通过骨干网IGP学习到BGP邻居下一跳的地址
②通过运行LDP协议,分配标签,建立LSP通道。
③标签栈用于报文转发,外层标签用来指示如何到达BGP下一跳,内层标签表示报文的出接口或者属于哪个VRF(属于哪个×××)。
④MPLS节点转发是基于外层标签,而不管内层标签是多少。
①PE和P路由器通过骨干网IGP学习到BGP邻居下一跳的地址
②通过运行LDP协议,分配标签,建立LSP通道。
③标签栈用于报文转发,外层标签用来指示如何到达BGP下一跳,内层标签表示报文的出接口或者属于哪个VRF(属于哪个×××)。
④MPLS节点转发是基于外层标签,而不管内层标签是多少。
所有的公网标签内的路由信息一般都是PE路由器的Loopback地址。由它将这个路由信息给第二跳P路由器,由它做第二跳标签弹出。一般这个第一跳路由器发送的这个路由信息是以一个特殊的标签3来给第二跳的路由器做为OUT LABEL的,有时也称这个特殊的标签3为implicit-null,它指示第二跳路由器它应该做第二跳标签弹出操作。
5. 报文转发 – CE >>> Ingress PE
①CE将报文发给与其相连的VRF接口,PE在本VRF的路由表中进行查找,得到了该路由的公网下一跳(即:对端PE的loopback地址)和私网标签。
②再把该报文封装一层私网标签后,在公网的标签转发表中查找下一跳地址,再封装一层公网标签后,交与MPLS转发。
①CE将报文发给与其相连的VRF接口,PE在本VRF的路由表中进行查找,得到了该路由的公网下一跳(即:对端PE的loopback地址)和私网标签。
②再把该报文封装一层私网标签后,在公网的标签转发表中查找下一跳地址,再封装一层公网标签后,交与MPLS转发。
6. 报文转发 - Ingress PE >>> Egress PE >>> CE
①该报文在公网上沿着LSP转发,并根据途径的每一台设备的标签转发表进行标签交换
②在倒数第二跳处,将外层的公网标签弹出,交给目的PE设备
③PE设备根据内层的私网标签判断该报文的出接口和下一跳
④去掉私网标签后,将报文转发给相应的VRF中的CE
①该报文在公网上沿着LSP转发,并根据途径的每一台设备的标签转发表进行标签交换
②在倒数第二跳处,将外层的公网标签弹出,交给目的PE设备
③PE设备根据内层的私网标签判断该报文的出接口和下一跳
④去掉私网标签后,将报文转发给相应的VRF中的CE


















