作为早期的互联网、电子政务、商业管理、工业制造等行业领域,首先每天产生的数据量并不大,而且以高价值的结构化数据为主,例如:早期互联网Web1.0时代,一台SQLServer数据库就能支撑绝大多数的门户网站,一台小机搭配Oracle就能轻松应对在线金融业务系统;其次数据访问需求比较简单,主要是业务数据模型之间的关联设计,业务数据的插入、更新和删除,对于更复杂的数据需求主要还是对字段的分组查询形成多维统计和明细下钻。 但是这一切都被互联网的发展所打破,尤其是到了2010年移动互联网的爆发。大数据的名词和概念随着Google的定义席卷了全球,那么大数据最基本的一个特征就是信息服务所接收到的数据请求量非常庞大,这对于传统的RDBMS来讲是冲击性的。
# 分布式对象存储和分布式文件系统具有很强烈的对比性 分布式对象存储是key/value的存储模式,以restful访问方式为主,几乎处于扁平化的存储形式,通过地址作为主键,访问、更新的文件对象作为值。文件本身可以分布式分片,但是key/value的访问都是原子性,文件不能追加数据,亦不能随机访问文
分布式文件系统HDFS无索引就无K/V 首先分布式数据并不是绝对的喜欢使用kv存储模式,例如分布式数据库里面mongodb和elasticsearch是文档形式存储,若把HDFS也算进去的话,它是无索引的存储。 上图是HDFS作为分布式数据存储的文件分块存储模式,简单直接,并没有进行任何的kv索引建
通过看到一种火热的技术现象,会产生对事物的一种浅层认知后,然后再深入理解去获得一个比较深刻的认识。大数据具有社会化,技术性的重要特点。 1. 从社会化看 先说这个“大”,也就是大数据最早的定义:速度、类型和容量,所谓的3V。实际上大数据的发展早已经突破了这个定义。数据体现的不是所谓的“大小”,而是规
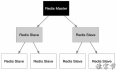
一、Redis的分布式结构解读 首先redis采用去中心化的设计这个理解是不到位的。redis分布式的模式,具有主从和集群两种,redis社区的集群方案redis cluster采用的是去中心化设计。我们先看看redis的演化过程: 上图是标准的Redis主从模式,只有Master接收写入请求,并将
Hadoop生态的分布式数据库 1、什么是分布式数据库? 从狭义的理解就是分布式关系型数据库,主要特指目前热门的NewSQL。 从广义的理解,分库分表的传统关系型数据库,传统关系型数据库集群,关系型数据库的主从架构,分布式KV数据库(例如:HBase),分布式文档数据库(例如:MongoDB),分布
最近刚入坑MongoDB,感觉比MySQL扩展性更强,一张表可以存储特别复杂的字段,这点我非常喜欢,最近需要用MongoDB存储一篇文章的数据,文章的评论和回复的数据存储是个大问题,设计了好久感觉我设计的字段好复杂,还不太合理,请求各位大佬指点一二,希望能参考你们的设计方案。 MongoDB的嵌套与
公司的项目数据量有限,获取行业线上线下消费数据也困难,没有足够的数据量,如何应用大数据?如何在公司现有情况下接触实际的高并发大数据项目? 就是想实操一下高并发的架构设计或者参与互联网级别项目的开发,但又不想舍弃现在的工作? 中小企业如何想办法破局 大数据本身就特别容易形成技术垄断,让长尾的中小企业无
Copyright © 2005-2025 51CTO.COM 版权所有 京ICP证060544号