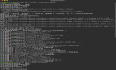
工具:Ubuntu ettercap driftnet sudo apt install ettercap-common sudo apt install driftnet ettercap shiff->第一个->无线网卡名字 ifconfig scanf for host hosts list 绑定 192.168.0.1 add to target2 19
1( 单选题 | 1 分)本课程的名称是A .需求工程B .需求分析C .需求建模D .需求获取正确答案: B 你的答案: B查看知识点 | 查看解析2( 单选题 | 1 分)本课程综合实践考核要提交的成果是A .一份PPTB .一份需求访谈记录C .一份需求规格说明文档D .什么都不需要正确答案: C 你的答案: C查看知识点 | 查看解析3( 单选题 | 2 分)以下哪项不属于需求工程活动?A
头插法voidHeadCreatList(ListL)//头插法建立链表{Lists;//不用像尾插法一样生成一个终端节点。Lnext=NULL;for(inti=0;i<10;i){s=(structList)malloc(sizeof(structList));//s指向新申请的节点sdata=i;//用新节点的数据域来接受isnext=Lnext;//将L指向的地址赋值给S;//头插法与尾插
环形缓冲区底层实现首先明白改过程发生在Map——Collect阶段:在用户编写的map()函数中,当数据处理完成后,一般会调用OutputCollector.collect()输出结果。在该函数内部,它会将生成的key/value分片(通过调用Partitioner),并写入一个环形内存缓冲区中。!(https://s4.51cto.com/images/blog/202202/08214024_
重载和重写的区别。【⭐⭐⭐⭐】重载就是同样的一个方法能够根据输入数据的(参数)不同,做出不同的处理;综上:重载就是同一个类中多个同名方法根据不同的传参来执行不同的逻辑处理。重写就是当子类继承自父类的相同方法,输入数据一样,但要做出有别于父类的响应时,你就要覆盖父类方法综上:重写就是子类对父类方法的重新改造,外部样子不能改变,内部逻辑可以改变。1.返回值类型、方法名、参数列表必须相同,抛出的异常范围
讲一下Java创建一个对象的过程。【⭐⭐⭐⭐】下图便是Java对象的创建过程,我建议最好是能默写出来,并且要掌握每一步在做什么。!Java创建对象的过程(https://s4.51cto.com/images/blog/202112/24111230_61c53a9ebfc8480032.png?xossprocess=image/watermark,size_14,text_QDUxQ1RP5Y
@toc1简单介绍一下HTTP的长连接和短连接?短连接:浏览器和服务器每进行一次HTTP操作,就建立一次连接,但任务结束就中断连接。长连接:当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的TCP连接不会关闭,如果客户端再次访问这个服务器上的网页,会继续使用这一条已经建立的连接。KeepAlive不会永久保持连接,它有一个保持时间,可以在不同的服务器软件(如Apache)中设定这个时间
@toc问答页面未解决问题!在这里插入图片描述(https://s4.51cto.com/images/blog/202112/21093535_61c12f675af0768327.png?xossprocess=image/watermark,size_14,text_QDUxQ1RP5Y2a5a6i,color_FFFFFF,t_100,g_se,x_10,y_10,shadow_20,ty
首页!在这里插入图片描述(https://s4.51cto.com/images/blog/202112/20154903_61c0356f184d377133.png?xossprocess=image/watermark,size_14,text_QDUxQ1RP5Y2a5a6i,color_FFFFFF,t_100,g_se,x_10,y_10,shadow_20,type_ZmFuZ3po
@toc设计规范逻辑架构数据采集数据采集层:数据采集层的任务就是把数据从各种数据源中采集和存储到数据库上,期间有可能会做一些ETL(抽取extra,转化transfer,装载load)操作。数据源种类可以有多种:日志:所占份额最大;存储在备份服务器上业务数据库:如Mysg、Oracle;来自HTTP/FTP的数据:合作伙伴提供的接口其他数据源:如Excel等需要手工录入的数据.数据存储数据计算HD
@[toc]项目展示首页访问地址 http://localhost/WISH/index.php添加许愿编辑许愿密码默认是:szm删除许愿数据准备代码│ index.php│ php_wish.sql│ save.php│├─common│ function.php│ init.php│├─css│ style.css│├─js│ common.js│
有公式没有公式
十一月反馈说上传图片大小限制了,的确反馈有效了 ,提升了0.1M 哈哈哈~
@tocphp<?phpclassAskControlextendsCommonControl{publicfunctionask(){//thissearch();//调用顶级分类thistop_cate();//获取用户金币uid=this_SESSION('uid','intval');point=M('user')where(array('uid'=uid))getField('point
!docker(https://s4.51cto./images/blog/202111/28150126_61a3294699ed088593.png?xossprocess=image/watermark,size_14,text_QDUxQ1RP5Y2a5a6i,color_FFFFFF,t_100,g_se,x_10,y_10,shadow_20,type_ZmFuZ3poZW5na
请设计一个函数,用来判断在一个矩阵中是否存在一条包含某字符串所有字符的路径。路径可以从矩阵中的任意一格开始,每一步可以在矩阵中向左、右、上、下移动一格。如果一条路径经过了矩阵的某一格,那么该路径不能再次进入该格子。例如,在下面的3×4的矩阵中包含一条字符串“bfce”的路径(路径中的字母用加粗标出)。"a","b","c","e","s","f","c","s","a","d","e","e"但矩
题目用两个栈实现一个队列。队列的声明如下,请实现它的两个函数appendTail和deleteHead,分别完成在队列尾部插入整数和在队列头部删除整数的功能。(若队列中没有元素,deleteHead操作返回1)示例1:输入:"CQueue","appendTail","deleteHead","deleteHead",3,,输出:null,null,3,1示例2:输入:"CQueue","dele
题目剑指Offer04.二维数组中的查找在一个nm的二维数组中,每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序。请完成一个函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数。示例:现有矩阵matrix如下:1,4,7,11,15,2,5,8,12,19,3,6,9,16,22,10,13,14,17,24,18,21,23,26,30给定target=5,返回
题目剑指Offer03.数组中重复的数字在一个长度为n的数组nums里的所有数字都在0~n1的范围内。数组中某些数字是重复的,但不知道有几个数字重复了,也不知道每个数字重复了几次。请找出数组中任意一个重复的数字。示例1:输入:2,3,1,0,2,5,3输出:2或3限制:2<=n<=100000我的答案classSolution{publicintfindRepeatNumber(intnums){
摘 要大数据技术随着互联网的发展及信息量爆炸增长的趋势应运而生。面对异常庞 大的数据,多种分布式文件系统为大数据的存储提供了解决方案。其中 Hadoop 由于 自身高扩展性、高可靠性等优点被业界广泛使用。HDFS 作为 Hadoop 的核心组件, 为处理大数据提供了文件存储服务。然而 HDFS 更擅长处理流式的大文件,面对海量小文件存储时的表现不佳。原因:因为Hadoop中一个最小的存储单元叫做Block[16],默认存储文件阈值为64MB。 小文件在存储时被分割成若干个内容连续的数据文件进行
留个帖子记录我的博客专家之路2020-12-22很遗憾,你的「博客专家」申请未能通过。2020-12-22尊敬的 CSDN 用户,很遗憾你的「博客专家」申请未通过:博文整体较为系统完善,但仍偏基础理论层面,建议多丰富些工作学习中的一线实战经验分享,供开发者学习借鉴。请继续加油!。请继续加油,技术之路,我们共同成长!...
源码见:https://github.com/hiszm/hadooptrainYARN产生背景ApacheYARN(YetAnotherResourceNegotiator)是hadoop2.0引入的集群资源管理系统。用户可以将各种服务框架部署在YARN上,由YARN进行统一地管理和资源分配。ThefundamentalideaofMRv2istosplitupthetwomajorfuncti
源码见:https://github.com/hiszm/hadooptrainMapReduce概述是一个分布式计算框架,用于编写批处理应用程序。编写好的程序可以提交到Hadoop集群上用于并行处理大规模的数据集。MapReduce作业通过将输入的数据集拆分为独立的块,这些块由map以并行的方式处理,框架对map的输出进行排序,然后输入到reduce中源自于Google的MapReduce论文,
目前在科大讯飞实习,主要的方向是大数据——数据仓库方向;发表原创文章364篇,CSDN访问量42万+;
目前在科大讯飞实习, 发表原创文章364篇,CSDN访问量42万+; 
Copyright © 2005-2025 51CTO.COM 版权所有 京ICP证060544号