
目录
浅淡爬虫:
这次学习爬虫,个人认为,爬虫的过程像是我们通过手动访问网页,找到我们所需要的数据,然后在把数据下载并保存下来。当我们需要访问的网页过多,需要下载的数据过多时,手动逐章进行无疑是一件冗长繁琐的事情。爬虫的优势便体现了出来,它可以自动将网页上我们所需要的信息提取并保存下来,逐个访问页面上需要访问的链接,进入,下载并保存信息。爬虫的工作流程便类似手动逐个点击访问,了解了它的工作原理,再结合代码示例就有了更深层次的认识。
开发爬虫的步骤:
-目标数据
-网站
-页面
-分析数据加载流程
-分析目标数据所对应的url
-下载数据
-清洗,处理数据
-数据持久化
实例开发与踩坑总结
踩坑总结:
IDE : Pycharm
需要安装requests库。 解决方法: win+r 输入 cmd。在命令行输入 : pip install requests。
导入Pycharm(!坑)。之前安装好了requests库,但是在Pycharm中依旧无法运行,报错显示没有requests库。
解决方法:可能是没有导入该库。在File - Setting - Project Interpreter 中导入requests库。如下图中所示。导入成功之后开始正常启动运行。
开发实例:
这次的实例是要爬取小说内容并且保存至txt文档。

开发过程:
第一步,获取目标数据
首先我们定义获取的网页url
url = 'https://www.xs4.cc/dushizhiwozhendewudi/'
response = requests.get(url)
#目标小说主页源码
html = response.text
然而此时print(html)后发现如下情况

说明此网页的编码方式并非utf-8,
我们需要在重新定义一下网页的编码方式:
url = 'https://www.xs4.cc/dushizhiwozhendewudi/'
response = requests.get(url)
#编码方式
response.encoding = 'gbk'
#目标小说主页源码
html = response.text
print(html)
再次打印后正常:
此时,我们就获取了目标网页的源码。
第二步,分析数据加载流程
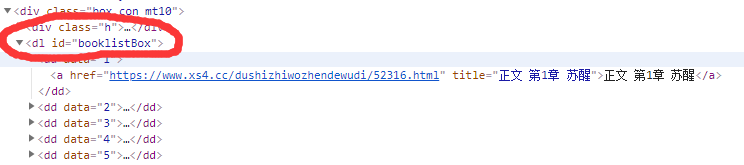
类比于人工访问。人工访问时,我们首先要点击“第一章”的链接,然后在页面上找到章节正文,把章节正文复制粘贴到要保存的txt文档。爬虫的工作步骤也是类似。在我们获悉的html数据中,首先找到各个章节所对应的部分。点击F12 查看网页源码,并且找到对应的位置,如下图示:
找到了对应的部分,但是要怎么提取呢。注意,我们已经通过第一步,把当前网页的html源码存入 变量html中,因此,我们需要在html中找到对应部分并把他们提取出来。
这就要用到正则表达式,通过python re库可以很方便实现这个功能:
首先我们来定位我们所需要的代码,我们所需要的章节信息是在这一部分中保存的。
-
<dl id="booklistBox">
-
***
-
</dl>
这时就可以确定,我么所需要提取的信息就在这一部分,我们用正则表达式中提取所需要的信息
#获取每一章节的信息
dl = re.findall(r'id="booklistBox".*?</dl>', html, re.S)
#注意:
# re.findall(r' ', 来源, 附加方法)
#re.findall() 帮助我们识别正则表达式。
# r'' 引号内存放 查找开头, 我们所需保存的数据, 查找的结尾。
# 由于我们所需要的章节url 和章节标题不同,因此用 .*? 代替。
# .*? 代表的是任意内容,相当于爬虫在查找html源码时,识别 查找开头,与查找结尾,把中间的东西全部保
# 存起来。
#re.S 是为了鉴别源文件中的 ‘ ’ ‘\n’ ,这些干扰有时会影响正则表达式的鉴别,加上re.S能无视其干扰
打印dl :

接着我们把dl 变成列表,
用同样的方法,我们再在 dl 中提取下一步需要的信息,即各章节的题目与url
#获取每一章节的信息
dl = re.findall(r'id="booklistBox".*?</dl>', html, re.S)[0]
#获取章节信息列表
chapter_info_list = re.findall(r'<a href="(.*?)" title="(.*?)">', dl)
#获取每一章节的标题
title = re.findall(r'title="(.*?)">', dl)
#print(title)
打印title :

把title 变成列表。
第三步、下载数据
对于每个章节,我么首先要提取其url 与 章节标题。再对应每个章节分别下载其内容。
#循环每个章节,分别去下载
for chapter_info in chapter_info_list:
#chapter_url, chapter_title = chapter_info
chapter_url = chapter_info[0]
chapter_title = chapter_info[1]
#下载章节内容
chapter_response = requests.get(chapter_url)
chapter_response.encoding = 'gbk'
chapter_html = chapter_response.text
#提取章节内容
chapter_content = re.findall(r'id="content">(.*?)</div>', chapter_html, re.S)[0]
————————————————
打印 chapter_content :

第四步、清洗数据
我们发现下载的数据中有很多字符,比如<br/> 、 &nsbp 等这是不可避免的情况,打印完成后,我们就需要来清洗数据,就是把不需要的字符,用空字符代替即可。
具体需要清洗的内容需要具体分析。
清洗代码:
#清洗数据
chapter_content = chapter_content.replace('<br/><br/>', '')
chapter_content = chapter_content.replace('<br />', '')
chapter_content = chapter_content.replace(' ', '')
#print(chapter_content)
再次打印,:

清洗数据成功!
第五步、数据持久化
听起来很厉害,其实就是把数据保存下来例如保存到txt文档。
首先我们要创建一个文件,将内容存放进去。
-
#新建一个文件,保存小说内容
-
fb = open('%s.txt' % title, 'w', encoding='utf-8')
利用文件存放函数,保存对应章节内容。
-
#数据持久化
-
fb.write(chapter_title)
-
fb.write('\n')
-
fb.write(chapter_content)
-
fb.write('\n')
再次运行。


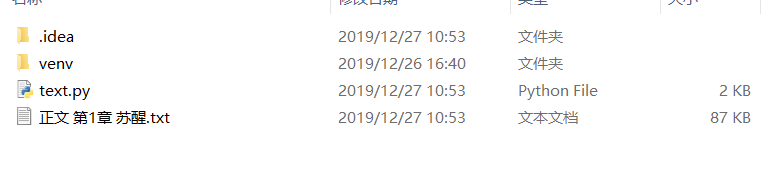
爬虫成功。
完整代码:
import requests
import re
url = 'https://www.xs4.cc/dushizhiwozhendewudi/'
response = requests.get(url)
#编码方式
response.encoding = 'gbk'
#目标小说主页源码
html = response.text
#获取每一章节的信息
dl = re.findall(r'id="booklistBox".*?</dl>', html, re.S)[0]
#获取章节信息列表
chapter_info_list = re.findall(r'<a href="(.*?)" title="(.*?)">', dl)
#获取每一章节的标题
title = re.findall(r'title="(.*?)">', dl)[0]
#print(title)
#新建一个文件,保存小说内容
fb = open('%s.txt' % title, 'w', encoding='utf-8')
#循环每个章节,分别去下载
for chapter_info in chapter_info_list:
#chapter_url, chapter_title = chapter_info
chapter_url = chapter_info[0]
chapter_title = chapter_info[1]
#下载章节内容
chapter_response = requests.get(chapter_url)
chapter_response.encoding = 'gbk'
chapter_html = chapter_response.text
#提取章节内容
chapter_content = re.findall(r'id="content">(.*?)</div>', chapter_html, re.S)[0]
#清洗数据
chapter_content = chapter_content.replace('<br/><br/>', '')
chapter_content = chapter_content.replace('<br />', '')
chapter_content = chapter_content.replace(' ', '')
#print(chapter_content)
#数据持久化
fb.write(chapter_title)
fb.write('\n')
fb.write(chapter_content)
fb.write('\n')
#print(title)
————————————————
版权声明:本文为CSDN博主「辞树 LingTree」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/l18339702017/article/details/103726786




















