
💯 作者: 俗世游子【谢先生】。 2014年入行的程序猿。多年开发和架构经验。专注于Java、云原生、大数据等领域技术。
💥 成就: 从CRUD入行,负责过亿级流量架构的设计和落地,解决了千万级数据治理问题。
📖 同名社区:51CTO、 github、掘金、gitee。
📂 清单: goku-framework、【更新中】享阅读II
📚 距离上次DevOps系列内容完结到现在已经有近一个月的时间,在这段时间里不摸鱼【刷沸点不算】
- 看了看Go的语法,找个典型案例玩玩
- 抽空开发享阅读2.0版本,点击了解1.0
💥 这里本人重点宣布:谢先生高调回归,本次将针对分布式流处理重点组件Kafka为大家继续分享
引言
在大数据时代下,数据已经贯彻到当今每一个行业和领域,近年来政策大力推送企业数据化转型也让大家意识到数据的重要性。
而随着互联网行业的不断发展,海量数据的挖掘与运营在各个行业所占比重越来越高。例如:
- 电商、新闻、娱乐平台等的推荐系统
- 算法模型预测也需要基于大量的数据
- 企业决策参考,数据安全等
- ....
而加快对数据的计算与处理进而推送了大数据计算引擎的发展,其中最广泛的三款计算引擎包括:
- MapReduce
- Spark
- Flink
不知道没关系,本人也不会详细介绍它们,大家对它们有一个了解即可。
慢慢往后看,大家就知道我介绍它们的意思
分布式流处理
分布式计算系统是将一组计算机通过网络互联的方式且协调单台资源的行为。当需要进行计算时
- 将整个数据分成小块,下分到不同的资源服务器中进行计算,等待计算完成之后再将结果汇总得到最终的结论
数据流属于不断到达的数据集,例如:收集用户行为所产生的行为数据等。这种数据集会在上层应用中以推送的方式暂存在某个中间介质中,且计算引擎通过中间介质获取数据进行计算。一般情况下这种方式的应用具有实时性要求。
Flink正是基于这种特性才能火的一塌糊涂。
QA:为什么数据流存储需要中间介质
- 数据多样性:在数据建模中,数据流汇集了上层应用的数据,数据种类、形式多变,故而无法进行物理存储
- 生命短:在计算中,除非特殊需要,数据流数据处理后即被丢弃,不需要被再次访问
- 数据量:数据流的大小和数据量基于上层应用的并发情况,中间介质需要能够保证在处理过程中的性能和稳定性

以上是最近刚处理的用户行为采集中的数据流走向
介绍了那么多,接下来终于要引出本次内容的主角:Kafka。大家欢迎!!!
Apache Kafka
传统将Kafka定义为高吞吐量的基于分布式的发布/订阅模式的消息队列,主要应用于大数据实时处理范围。
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
官方对Kafka最新的定义为:分布式事件流平台,主要应用于高性能数据管道、流分析、数据集成和关键任务应用
消息队列
我们介绍到最开始Kafka被定义为消息队列,同类型产品还包括:
- ActiveMQ
- RabbitMQ
- RocketMQ
这里我们也简单介绍一下关于消息队列的概述。
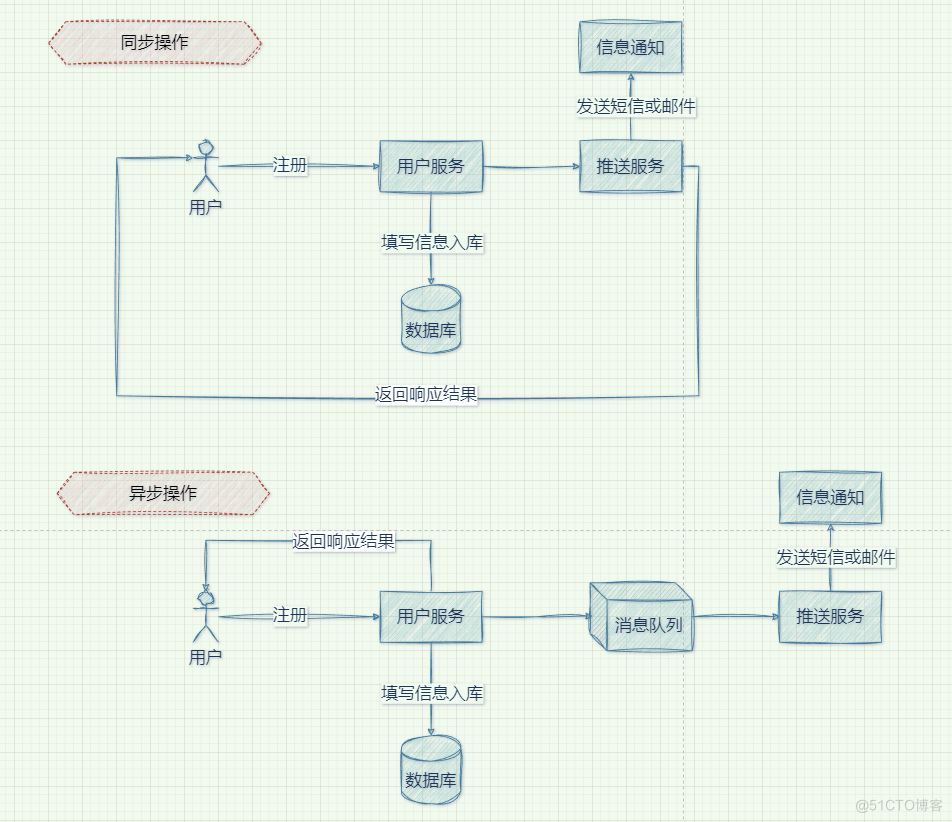
队列是一种数据结构,具有先进先出的特点。而消息队列是消息在传输过程中用来保存消息的容器,一般传递与平台系统无关的数据流。如果消息队列中的消息没有被消费,那么消息队列将保留消息,直到可以正确被消费。
消息队列的处理模式
点对点消费
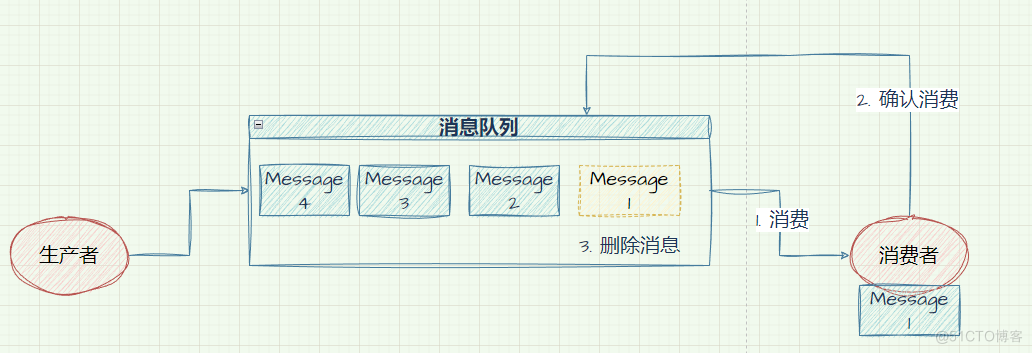
消息队列的处理模式都是针对消息来讲的
- 消息生产者将消息发送到消息队列后,消费者从消息队列中主动拉取消息来处理,
- 当消息消费完成之后,消息队列中将删除已经被消费的消息
- 支持存在多个消费者,但是消息只能被一个消费者来处理
发布/订阅消费

而发布/订阅模式下,有多个topic,消费者在消费成功数据之后消息队列并不会删除数据。同时每个消费者之前是相互独立,消费者的进度互相不受到影响。
消息队列场景
一般情况下,消息队列主要应用在如下场景中:
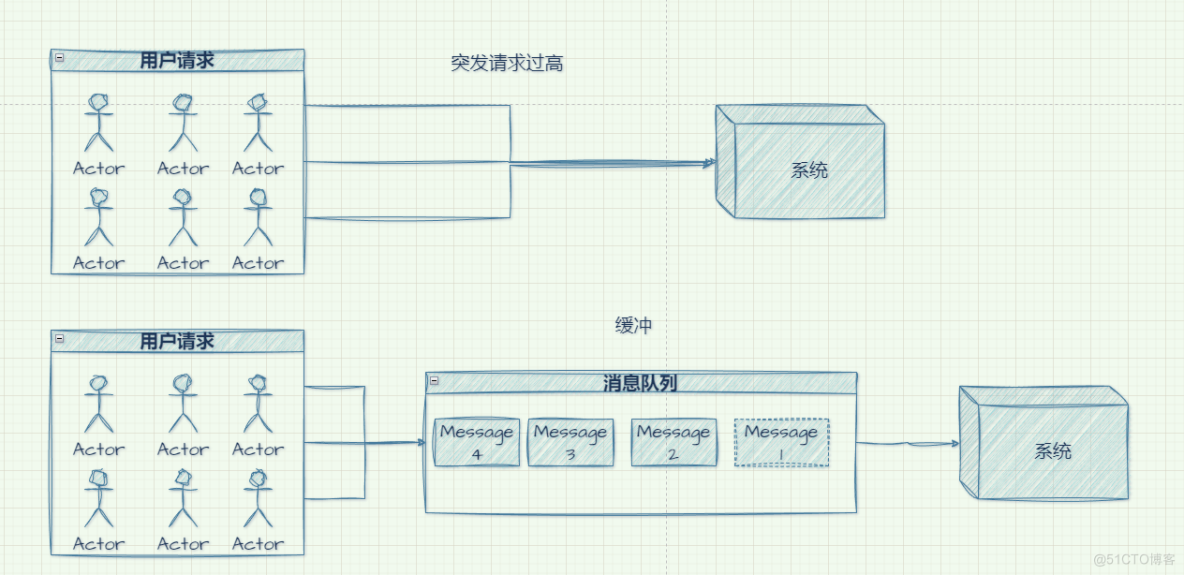
- 缓冲/削峰
用来处理突如其来的流量请求,优化数据流经过系统的速度,从而将流量控制在系统能够平滑处理的范围内,保证系统的平稳执行。
秒杀系统、广告投放展示属于该场景下的典范
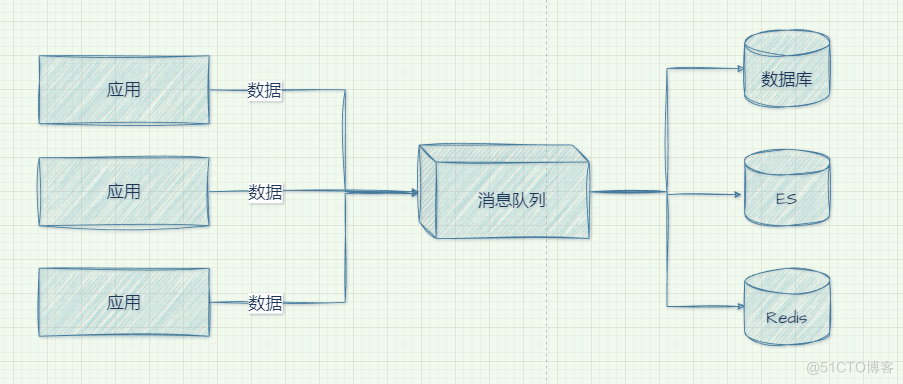
- 解耦
将毫不相关业务在系统中进行拆分,涉及到扩展或修改只需要保证遵守相同的约束
- 异步通信
允许用户把一个处理逻辑放到消息队列中,但是不立即进行处理。等待在需要的时候再去处理
安装
本次我们采用当前最新版本3.3.1作为实验体,虽然Kafka在2.8.0之后提出可以去掉对Zookeeper的依赖,但是我们在本次安装中不会涉及到KRaft模式的操作,继续沿用原始的安装方式
故而我们还是需要安装Zookeeper
这里没有介绍JDK的安装过程,但是机智的大家肯定都清楚
环境规划
工欲善其事必先利其器,实际工作中也是一样的,如果我们需要安装某个技术组件,一定要对拿到的服务资源做规划, 也方便记录
还是准备三台机器,直接采用集群的安装方式
IP | Host | Zookeeper | Kafka |
192.168.10.101 | node01 | ⭕ | ⭕ |
192.168.10.102 | node02 | ⭕ | ⭕ |
192.168.10.103 | node03 | ⭕ | ⭕ |
⭕ : 安装
Zookeeper安装
接下来的每个操作我们都优先在
node01上完成,随后向其他节点进行分发
ZK初始配置
执行如下操作将安装包
接下来解压开始进行配置
zoo.cfg
进入到apache-zookeeper-3.8.0/conf下,将zoo_sample.cfg复制并重命名为zoo.cfg,在其中进行配置修改
核心配置已经列出,为了防止配置过程不清晰,这做一个简单的介绍
- 修改dataDir主要是因为默认在
/tmp目录下,而/tmp目录下的内容在某种条件下会被清空。所以我们的数据不能存放到这里 - server.N主要配置的是集群的节点,2888和3888主要是通信和选举端口
除此配置之外,还需要在/var/data/zookeeper下配置myid,内容就是server.N中的N。
一定要注意,不要出现配置错误的现象
配置环境变量
之前配置环境变量我们都是在/etc/profile下修改,这次我们换一种方式
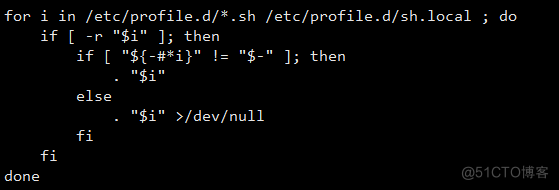
通过查看profile脚本我们会发现,它本身还会去加载/etc/profile.d下的脚本文件,那么我们就可以这样做
随后和其他的没有太多的区别,执行source /etc/profile使环境变量生效

分发并启动
随后向其他节点分发,只需要做如下配置:
- 在对应dataDir目录下生成myid文件
- 使环境变量生效
此时启动或停止就变的非常简单

整个ZK安装的过程其实是比较简单的
Kafka安装
继续node01上操作,和Zookeeper的安装一模一样,就不再多介绍
初始配置
找到server.porperties中,主要修改如下配置
以上为最小改动配置,其中:
- broker.id和ZK的myid是一样的性质,必须唯一且不能重复
- zookeeper是以目录树来存储数据的,而
zookeeper.connect之后的/kafka可以将kafka中的数据全部集中在一个目录下,便于管理和查看
环境变量
在/etc/profile.d/kafka.sh下编辑
执行source /etc/profile使环境变量生效
分发并启动
随后就是通过scp命令向其他机器上分发程序包
执行如下命令将kafka启动
验证
接下来就是见证奇迹的时刻
先来查看整个集群中的Topic列表
这里的
bootstrap-server并不一定要写全部的地址,只需要有几个能够让程序做负载即可
第一次查看必然是空的,接下来开始创建
创建成功之后再次查看必然是存在的。其实到这里就已经能验证出Kafka的安装是否成功,那接下来我们再来看看收发消息


kafka-console-producer.sh和kafka-console-consumer.sh是kafka为我们提供的脚本,用来处理收发消息。
通过上述的验证,已经证明我们kafka安装时非常成功的。
下期预告
本节到这里就结束了,大家针对本章的练习如果遇到任何问题,都可以在评论区留言。
下期针对Kafka的架构做具体的分析,并且针对常用的命令我们来做学习。


















