(1)含义:document.all的意思是文档的所有元素,也就是说它包含了当前网页的所有元素。它是以数组的形式保存元素的属性的,所以我们可以用document.all["元素名"].属性名="属性值"来动态改变元素的属性。
(2)访问文档中的特定元素
document.all["docid"]
document.all["docname"]
document.all.item("docid")
document.all.item("docname")
document.all[0]
document.all.tags("div")返回所有DIV数组,用document.all.tags("div")[0]访问元素
(3)在web标准下可以通过使用getElementById(), getElementsByName(), and getElementsByTagName()访问DOCUMENT中的任一个标签
document.getElementsByName()返回的是一个数组,用document.getElementsByName()[]返回数组中单个值
(2)访问文档中的特定元素
document.all["docid"]
document.all["docname"]
document.all.item("docid")
document.all.item("docname")
document.all[0]
document.all.tags("div")返回所有DIV数组,用document.all.tags("div")[0]访问元素
(3)在web标准下可以通过使用getElementById(), getElementsByName(), and getElementsByTagName()访问DOCUMENT中的任一个标签
document.getElementsByName()返回的是一个数组,用document.getElementsByName()[]返回数组中单个值
getElementsByTagName()同样返回的也是一个数组
例子:
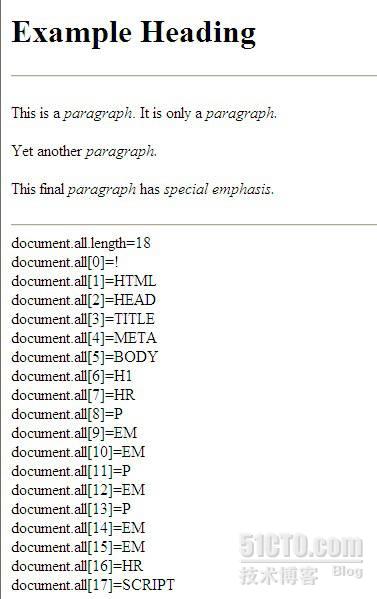
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" >
<head runat="server">
<title>document中All</title>
<meta http-equiv="content-type" content="text/html; charset=ISO-8859-1" />
</head>
<body>
<h1>Example Heading</h1>
<hr />
<p>This is a <em>paragraph</em>. It is only a <em>paragraph.</em></p>
<p>Yet another <em>paragraph.</em></p>
<p>This final <em>paragraph</em> has <em id="special">special emphasis.</em></p>
<hr />
<script type="text/javascript">
var i,origLength;
origLength = document.all.length;
document.write('document.all.length='+origLength+"<br />");
for (i = 0; i < origLength; i++)
{
document.write("document.all["+i+"]="+document.all[i].tagName+"<br />");
}
</script>
</body>
</html>
<html xmlns="http://www.w3.org/1999/xhtml" >
<head runat="server">
<title>document中All</title>
<meta http-equiv="content-type" content="text/html; charset=ISO-8859-1" />
</head>
<body>
<h1>Example Heading</h1>
<hr />
<p>This is a <em>paragraph</em>. It is only a <em>paragraph.</em></p>
<p>Yet another <em>paragraph.</em></p>
<p>This final <em>paragraph</em> has <em id="special">special emphasis.</em></p>
<hr />
<script type="text/javascript">
var i,origLength;
origLength = document.all.length;
document.write('document.all.length='+origLength+"<br />");
for (i = 0; i < origLength; i++)
{
document.write("document.all["+i+"]="+document.all[i].tagName+"<br />");
}
</script>
</body>
</html>
结果: