
# 自动驾驶中的多目标跟踪
在这篇文章里,笔者将试图对自动驾驶中多目标跟踪(Multi-Object Tracking, MOT)领域近几年代表性的论文进行整理,分析各项工作的思路和做法,以便读者能够迅速了解这个领域的前沿动态。顺便,我也对MOT领域的公开数据集、排行榜、评价指标等做了整理,以作为面向初学者或跨行业者的基础知识。
我们首先明确一下多目标跟踪的概念。多目标跟踪并不是一个新鲜词,二战期间雷达出现以后,利用雷达对敌方飞机进行跟踪和锁定,就是目标跟踪的早期应用;当前最为现代化的军用雷达,能够同时跟踪数十乃至数百个高速运动的敌方目标,其背后正是多目标跟踪算法的功劳。此外在多媒体分析领域,多目标跟踪技术也有着重要应用。
在自动驾驶领域,多目标跟踪是指对在不同时刻观测到的多个目标,进行关联和跟踪,以便获得每个目标的位置/轨迹、速度、方向等状态信息,服务于下游的规划、预测、决策等模块。因此,MOT是自动驾驶中最为基础和重要的能力之一。
通常来说,自动驾驶的感知系统会给出在时序上离散(且无序)的目标信息,通常体现为一定数量的含有语义标签的bounding box。在2D图像感知中,box是二维的,在3D点云感知中,box是三维的。一个理想的多目标跟踪算法,应该能够尽可能准确(accuracy)和精确(precision)地追踪同一个目标,并很好地解决目标新出现、被遮挡、消失、轨迹交错、目标检测结果不稳定、目标数量剧烈变化等情况。这些情况实际也是多目标跟踪领域的难点。如下图所示,是一个自动驾驶场景中MOT的例子(图片来自Waymo数据集),尽管现实中的MOT不会这么理想。

图1:waymo数据集中的多目标跟踪示例
多目标跟踪算法可以粗略分为两个类别:(1)传统的基于规则的方法,通常以IoU/马氏距离等结合匈牙利匹配算法进行目标关联、以卡尔曼滤波器(KF)结合匀速/匀加速运动学模型进行目标状态的预测和更新,最终实现目标跟踪。(2)基于深度学习的方法,通常使用训练过的神经网络来完成关联和追踪的任务,根据与目标检测的关系,又可以细分为若干种不同的类型;当然,目前端到端的做法也不是什么新鲜事儿了,一切环节都交给神经网络来隐式地处理。下面我们也会按照这两个类别,在每个类别里挑选代表性的论文进行综述。
数据集、排行榜网站
主要是自动驾驶中的这几个数据集,包括 KITTI,nuScenes,Waymo Open Dataset。还有一些在其它领域比较有名的数据集,比如MOTChallenge,MOT15/16/17/20等,但这些大体上关注 2D MOT。在自动驾驶领域我们主要考虑 3D MOT,因此还是以自驾中的三个数据集为主。
nuScenes 数据集 MOT 任务排行榜:nuScenes tracking task
KITTI 数据集 MOT 任务排行榜:kitti tracking
paperwithcode 网站 3D MOT 任务排行榜:3D Multi-Object Tracking,必读,必读!以下图为例,网页上清楚显示了在 nuScenes 数据集上,以 AMOTA 为评价指标,排行榜上的方案有哪些,及其结果。
paperwithcode网站:paperwithcode,汇总了各项数据集、挑战赛排行榜、前沿论文、开源实现等信息,相当全面。该网站的额外优势在于可以非常方便地跳转到排行榜上的各项工作的论文与代码,从业人员必备。
OpenDriveLab 网站:OpenDriveLab ,业内非常有名的实验室,也发布有 OpenLane Topology,Online HD Map Construction,3D Occupancy Prediction,nuPlan Planning 等挑战赛。
All Challenges 网站:All Challenges,一个非常全面的AI领域各项挑战赛汇总网站。
评价指标
读者在浏览各数据集和排行榜的时候,会经常发现MOTA、MOTP、AMOTA、AMOTP、HOTA、MT、ML、TP、FP、FN等评价指标,乍看起来眼花缭乱,不容易区分它们各自的含义。这里我们对常见指标的含义做出解释说明,其中会穿插铺垫一些基本概念。
- IoU:交并比,也即两个 bounding box 的交叉部分占两者总体的比例,也即 交集 / 并集
- GT:某一时刻目标检测得到的目标的总数量
- FP:False Positive,轨迹的预测没有对应的检测结果,轨迹丢失
- FN:False Negative,检测结果没有对应的轨迹预测,目标被missed
- IDS/IDSW:也即 ID 发生 switch,常见于两个或多个目标的轨迹交错时,ID发生变化的情形
- MOTA:多目标追踪的准确度(Accuracy),考虑所有时刻中,正确关联的目标的数量占GT的比例
- MOTP:多目标追踪的精度(Precision),考虑所有时刻中,正确关联的距离度量的均值
- AMOTA:MOTA在不同阈值上的均值
- AMOTP:MOTP在不同阈值上的均值
- HOTA:Higher Order Tracking Accuracy,更高阶的准确度度量,含有多个子度量,考虑了更多的评估要素
- MT:mostly tracked,意指多数跟踪数,跟踪部分比例超过80%的轨迹的数量
- ML:mostly lost,意指多数丢失数,丢失部分比例超过80%的轨迹的数量
请注意,所有这些指标都不是空穴来风,而是研究者们精心设计出来的评价指标,您可以参阅下方3篇论文,来了解这些指标的出处、和详细的解释。
- Bernardin, Keni, and Rainer Stiefelhagen. "Evaluating multiple object tracking performance: the clear mot metrics."EURASIP Journal on Image and Video Processing2008 (2008): 1-10.
- Weng, Xinshuo, et al. "3d multi-object tracking: A baseline and new evaluation metrics."2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2020.
- Luiten, Jonathon, et al. "Hota: A higher order metric for evaluating multi-object tracking."International journal of computer vision129 (2021): 548-578.
相关综述
与多目标跟踪相关的综述共有如下5篇(欢迎评论区补充),请注意每篇的侧重点都有所不同,对于自驾的同学并不一定都有用。
- Girao, Pedro, et al. "3D object tracking in driving environment: A short review and a benchmark dataset."2016 IEEE 19th international conference on intelligent transportation systems (ITSC). IEEE, 2016. //
- Luo, Wenhan, et al. "Multiple object tracking: A literature review."Artificial intelligence293 (2021): 103448. //
- Bashar, Mk, et al. "Multiple object tracking in recent times: a literature review."arXiv preprint arXiv:2209.04796(2022). //
- Peng, Yang. "Deep learning for 3D Object Detection and Tracking in Autonomous Driving: A Brief Survey."arXiv preprint arXiv:2311.06043(2023). //
- Zhang, Peng, et al. "3D Multiple Object Tracking on Autonomous Driving: A Literature Review."arXiv preprint arXiv:2309.15411(2023). //
传统方法
笔者将按照时间线由远及近的顺序,来综述传统方法下的经典工作,对应的时段为2018年 ~ 今(2024/01),涵盖了BeyondPixels、AB3DMOT、EagerMOT、SimpleTrack、PolarMOT、Poly-MOT等经典工作,其中不少至今仍在排行榜上位于前列。笔者在详细阅读完每篇论文之后,根据自己的理解、对每篇工作的主旨都做了整理,如下。
Sharma, Sarthak, et al. "Beyond pixels: Leveraging geometry and shape cues for online multi-object tracking."2018 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2018.
首先是这篇发表于 2018 年的论文,方案简称 Beyond pixels,当年在 KITTI 数据集 3D Multi-Object Tracking 排行榜上也是代表性的存在。这篇论文聚焦于道路场景下、基于单目图像的多目标追踪,其主要贡献是提出了一种复合了多种度量的匹配代价,来更好地完成目标的帧间关联。所提出的匹配代价包含的度量有:(1)将2D box结合地平面假设恢复出深度,提升到3D空间,再结合自车的运动估计(来自视觉里程计VO)将3D box投影到另一帧的2D图像平面上,与投影位置附近的所有目标,构建2D-2D的交并比度量,作者在论文中称之为 3D-2D Cost;(2)类似第一种度量,但是把两帧上的2D box都提升到3D空间,构建3D-3D的交并比度量,作者称之为 3D-3D Cost;(3)用CNN网络为每个目标计算一个外观描述子,计算描述子之间的一个相似性度量,作者称之为 Appearance Cost;(4)为每个目标计算一个形状描述子,该描述子直观上可以反映车辆的类别(比如SUV和轿车在形状上有差异),因此可以构建一个形状描述子的相似性度量;此外,每个目标都估计了一个姿态,因此也构建一个姿态的相似性度量,作者称这部分度量为 Shape and Pose Cost。最终的匹配代价是上述所有度量的加权线性组合。基于这种 Object-To-Object 的匹配代价,结合二分图匹配算法(比如匈牙利算法),来完成帧间的目标关联。在笔者看来,这篇工作的核心价值在于提出了一些新的度量,但由于使用了地面假设因此泛化能力可能不佳,对现实中的车身剧烈运动可能不够鲁棒,且需要同步运行额外的CNN网络和视觉里程计,因此计算开销可能较大。
项目主页:https://junaidcs032.github.io/Geometry_ObjectShape_MOT/
代码开源地址:https://github.com/JunaidCS032/

Beyond Pixels 论文图
Weng, Xinshuo, et al. "3d multi-object tracking: A baseline and new evaluation metrics."2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2020.
简称 AB3DMOT,2019年上传arxiv,正式发表在 IROS2020 上。这篇工作堪称简单好用的典范,个人认为非常适合新手入门,因为论文提供了新的参照基准,后续也被高频地引用。这篇工作以基于激光雷达的 3D MOT 为背景,因为激光雷达点云提供了精确的三维测量,因此 MOT 可以直接在三维空间中进行。作者使用已有的3D点云目标检测网络(PointRCNN/Mono3DPLiDAR)来进行detection,每一个detection结果表达为一个8维的向量,包含「位置、朝向角、box尺寸、置信度」信息。作者使用简单的「匀速模型+卡尔曼滤波器+匈牙利匹配」的范式来完成 3D MOT,其中卡尔曼滤波器维护的状态量为目标的「位置、朝向角、box尺寸、置信度、和速度」,构成了一个11维的向量。对比检测网络给出的结果,发现状态量多出了速度信息,这也正是卡尔曼滤波器做预测的依据。事实上,每一个卡尔曼滤波器都维护了某个目标的轨迹信息。
值得注意的是,AB3DMOT 不需要估计自车运动,所有的状态量都在LiDAR坐标系下表达,事实上是把自车的速度施加到了目标的速度中,好处是不需要显式估计 Ego Motion,使 MOT 任务更简单。针对目标检测结果中经常出现的180度跳变,作者也给出了简单有效的处理逻辑。在匈牙利匹配部分,匹配的依据就是简单的两个 3D box 之间的交并比。作者还设计了一些逻辑来处理目标的出现和消失,也即维护轨迹的生命周期,略过不表。在算法之外,作者的另一个贡献是提出了新的 MOT 评价指标,也即 AMOTA、AMOTP 和 sAMOTA,上文已经详细解释过了,略过不表。
项目主页:https://www.xinshuoweng.com/projects/AB3DMOT/
代码开源地址:https://github.com/xinshuoweng/AB3DMOT

AB3DMOT 论文图
Chiu, Hsu-kuang, et al. "Probabilistic 3d multi-object tracking for autonomous driving."arXiv preprint arXiv:2001.05673(2020).
接下来我们再看一篇 3D MOT 的文章(也记作 mahalanobis_3d_multi_object_tracking),该项工作的思路和 AB3DMOT 很像,时间上也接近并引用了前者,同样是基于「匀速模型+卡尔曼滤波器+匈牙利匹配」的基本结构,当时在 2019 nuScenes Tracking Challenges 挑战赛上取得了第一名的成绩。相比于 AB3DMOT,这篇工作的突出贡献是:建模了预测和观测中的不确定性,并使用考虑了不确定性的马氏距离(Mahalanobis Distance)来构建帧间匹配代价,而非像 AB3DMOT 那样直接使用 3D box 的交并比。其它的不同还有:这篇工作中卡尔曼滤波器的状态量虽然也是11维,但把置信度替换为了角速度、相比于前者的匀速运动模型,这里实际上使用了匀速+匀转速的运动模型。另外,这篇工作的大量篇幅都在于对不确定性的传播和收敛、以及卡尔曼滤波器细节的介绍,这和文章的重心是一致的。
代码开源地址:https://github.com/eddyhkchiu/m

Mahalanobis 3D MOT 论文图
Kim, Aleksandr, Aljoša Ošep, and Laura Leal-Taixé. "Eagermot: 3d multi-object tracking via sensor fusion."2021 IEEE International conference on Robotics and Automation (ICRA). IEEE, 2021.
EagerMOT —— 这是一项在各个排行榜上都效果不错的工作,原因之一在于,它事实上是融合了 2D 检测和 3D 检测的多模态 MOT 工作,在动机层面上主要是考虑到了两类观测的互补特性 —— 3D检测具有深度信息但对远处目标不敏感,2D检测不具有深度信息但可以检测到远处的目标。在算法逻辑上:(1)首先在同一时刻的2D检测和3D检测之间进行关联,关联的标准是将 3D box 投影到 2D 图像平面,计算和 2D box 的交并比,以贪婪的方式确定关联。(2)第一阶段关联:执行一次3D检测和3D轨迹之间的关联,但匹配代价使用的是作者自定义的一种距离(normalized cosine distance),主要考虑了 3D box 的朝向相似性。(3)第二阶段关联:2D检测和尚未发生关联的3D轨迹和2D轨迹进行关联,匹配代价是 2D box 的交并比。(4)轨迹状态更新:关联成功的3D轨迹按照卡尔曼滤波器+匀速运动模型的范式更新轨迹状态,未关联成功的3D轨迹进行纯预测更新,关联成功的2D轨迹也进行2D范式的更新。笔者评价:总体上的感觉是:有3D用3D,无3D用2D,在几乎所有环节,3D检测的优先级都高于2D检测,2D检测不存在时就退化为纯3D接着工作;3D和2D之间并没有想象中的深耦合。
代码开源地址:https://github.com/aleksandrkim

EagerMOT 论文图
Pang, Ziqi, Zhichao Li, and Naiyan Wang. "Simpletrack: Understanding and rethinking 3d multi-object tracking."European Conference on Computer Vision. Cham: Springer Nature Switzerland, 2022.
这篇文章由图森未来和UIUC发表在2022年的ECCV上,2021年上传arxiv。其工作主要有三块:(1)将现有 tracking-by-detection 范式下的 MOT 算法分解为「预处理、数据关联、运动模型、生命周期管理」四个模块,对各模块的常见方法做了对比和分析,并提出了改进的措施;(2)将改进措施集成到自己提出的 SimpleTrack 算法框架中,在 nuScenes 和 Waymo Open Dataset (WOD) 上实现了更好的表现;(3)对主流数据集 WOD 和 nuScenes 提供的目标检测频率和评价标准问题提出了疑问和讨论,对 SimpleTrack 的失效情形进行了分析并给出了未来工作的方向。笔者评价:这篇文章的第一部分工作对 MOT 各个模块的拆解和分析很值得借鉴,其中甚至分析了不同数据集“偏好”不同方法的问题。
代码开源地址:https://github.com/tusen-ai/SimpleTrack

SimpleTrack 论文图
Pang, Su, Daniel Morris, and Hayder Radha. "3d multi-object tracking using random finite set-based multiple measurement models filtering (rfs-m 3) for autonomous vehicles."2021 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2021.
这篇论文的作者是密歇根州立大学(MSU)的 Pang Su 博士,其整个博士期间的研究方向就是基于随即有限集(Random Finite Set, RFS)的多目标检测和跟踪,在网上也能找到其博士学位论文《3D Object Detection and Tracking for Autonomous Vehicles》的部分信息,这篇 ICRA 2021 论文正好对应其博士学位论文中的第六章。随即有限集也是数学上的一个集合,但具有元素个数有限、且数量随机的特性,某种程度上契合了MOT中目标数量有限和随机的特性,因此在目标检测和追踪中都有应用,但这个方向的研究似乎相对小众,笔者对其原理也是似懂非懂。这里推荐一些还不错的资源,供读者参考:缪天磊:随机有限集(Random Finite Set)-简介,智商为零:开源一个基于随机有限集(Random Finte Sets)的多源多目标跟踪框架,中国电子学会:深圳大学谢维信教授团队就扩展目标跟踪问题提出一种新型混合滤波器。
回到这篇文章,大体上来讲,作者提出了使用基于随机有限集 (RFS) 的多重测量模型滤波器 (称为RFS-M3) 来解决自动驾驶场景中的 3D MOT 问题。具体来说,作者使用的是泊松多伯努利混合滤波器(PMBM filter),并为之构建了多测量观测模型以适应不同的应用场景。整个滤波器能够以优雅和自然的方式来表达追踪中的不确定性。
代码开源地址:未开源

RFS-M3 论文图
Li, Xiaoyu, et al. "Poly-mot: A polyhedral framework for 3d multi-object tracking."2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2023.
这项工作来自哈工大,发表于 IROS 2023,在 nuScenes 数据集上取得了第一名的成绩。其动机是:现有的 3D MOT 方法通常使用单一的相似性度量和运动模型来建模所有的目标,但现实中目标的类型多种多样,不同类别目标的运动模式更是相差甚多(如行人、电瓶车、汽车、客运巴士等),因此作者提出为不同类型的目标使用不同的相似性度量、数据关联策略、和运动模型,从而提升 MOT 的性能。这项工作的核心内容有:(1)检测结果预处理部分使用了非极大值抑制和置信度阈值过滤;(2)提出了两种运动模型 CTRA 和 Bicycle,前者适合汽车和行人,后者适合电瓶车和摩托车等,运动模型内嵌到卡尔曼滤波器中执行预测和更新;(3)数据关联部分,作者认为对不同类别目标使用统一的相似性度量和阈值是不合理的,提出了多类别重复关联的策略,分为两个阶段执行,并使用了三种相似性度量;(4)轨迹的生命周期管理部分和其它工作没有本质差别,不再赘述。笔者评价:这篇工作的核心思想就是一点 —— 在 MOT 中对不同类别的物体使用不同的标准,这是符合直觉的,非常值得借鉴(ps: 为啥这个思路前边没人做过?),代码也开源了,数据集效果也非常好。Poly-MOT 是纯传统方法,因此效率也相对较高,使用 Intel 9940X CPU 在 nuScenes 数据集上可以做到 3 fps 的处理速度,而 SimpleTrack 是 0.51 fps。
代码开源地址:https://github.com/lixiaoyu2000/Poly-MOT

Poly-MOT 论文图
Learning方法
笔者对深度学习类方法的理解深度有所欠缺,这里就不写每篇的要点了,个别文章随缘注解。
Yin, Tianwei, Xingyi Zhou, and Philipp Krahenbuhl. "Center-based 3d object detection and tracking."Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2021.
简称 CenterPoint,一篇很重要的参考文章。
项目开源地址:https://github.com/tianweiy/CenterPoint
Wu, Jialian, et al. "Track to detect and segment: An online multi-object tracker."Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2021.
在逻辑上比较别致,别人是先检测再追踪,这篇文章提出先追踪,并用追踪结果辅助检测,当然所有事情都是用神经网络完成的。作者也在文章中评价了不同的思路和实现结构。
项目主页:https://jialianwu.com/projects/TraDeS.html
项目开源地址:https://github.com/JialianW/TraDeS
Luo, Chenxu, Xiaodong Yang, and Alan Yuille. "Exploring simple 3d multi-object tracking for autonomous driving."Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
轻舟智行和约翰霍普金斯大学联合发表的工作,简称 SimTrack。
项目开源地址:https://github.com/qcraftai/simtrack
Chiu, Hsu-kuang, et al. "Probabilistic 3D multi-modal, multi-object tracking for autonomous driving."2021 IEEE international conference on robotics and automation (ICRA). IEEE, 2021.
基于多模态融合的多目标追踪工作,具有深度学习方法和传统方法的松耦合结构,来自于斯坦福大学和丰田研究院,没有开源。
Zeng, Yihan, et al. "Cross-modal 3d object detection and tracking for auto-driving."2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2021.
基于多模态融合的多目标追踪工作,来自于上海交大,似乎没有开源。
Koh, Junho, et al. "Joint 3d object detection and tracking using spatio-temporal representation of camera image and lidar point clouds."Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 36. No. 1. 2022.
未开源。
Liu, Zhijian, et al. "Bevfusion: Multi-task multi-sensor fusion with unified bird's-eye view representation."2023 IEEE international conference on robotics and automation (ICRA). IEEE, 2023.
项目开源地址:https://github.com/mit-han-lab/bevfusion
Wang, Li, et al. "Camo-mot: Combined appearance-motion optimization for 3d multi-object tracking with camera-lidar fusion."IEEE Transactions on Intelligent Transportation Systems(2023).
未开源。
Kim, Aleksandr, et al. "PolarMOT: How far can geometric relations take us in 3D multi-object tracking?."European Conference on Computer Vision. Cham: Springer Nature Switzerland, 2022.
与别的方法不同,这里是将目标与附近目标的相对空间关系构建为图(Graph),进而用神经网络来处理这种图的观测,实现多目标追踪的功能。
项目主页:PolarMOT
代码开源地址:https://github.com/aleksandrkim61/PolarMOT
Wang, Xiyang, et al. "DeepFusionMOT: A 3D multi-object tracking framework based on camera-LiDAR fusion with deep association."IEEE Robotics and Automation Letters7.3 (2022): 8260-8267.
未开源。
Pang, Ziqi, et al. "Standing Between Past and Future: Spatio-Temporal Modeling for Multi-Camera 3D Multi-Object Tracking."Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023.
端到端搞定一切。
项目开源地址:https://github.com/TRI-ML/PF-Track
Liu, Jianan, et al. "GNN-PMB: A simple but effective online 3D multi-object tracker without bells and whistles."IEEE Transactions on Intelligent Vehicles8.2 (2022): 1176-1189.
图神经网络。
项目开源地址:https://github.com/chisyliu/Gnn
# 鱼眼相机和超声波的强强联合!基于BEV空间的多模感知算法
目前,自动驾驶技术已经愈发的成熟,很多车企都已经在自家的车辆产品上配备了自动驾驶算法,使车辆具备了感知、决策、自主行驶的能力,下图是一个标准的自动驾驶算法流程图。

图一:标准自动驾驶流程图
通过上面展示出来的标准自动驾驶流程图可以清晰的看出,整个自动驾驶流程包括五个子模块:
- 场景传感器:采用不同的数据传感器对当前的周围场景进行信息的采集工作,对于自动驾驶车辆来说,常见的数据采集传感器可以包括:相机(Camera),激光雷达(Lidar),毫米波雷达(Radar),超声波传感器(Ultrasonics)等等。
- 感知和定位:在获得了来自场景传感器采集到各种数据信息之后,会将采集到的相关信息送入到不同的感知和模型当中输出对当前环境的感知和定位结果,这里会涉及到的相关感知算法可以包括:车道线检测感知算法(Lane Detection),目标检测感知算法(Object Detection),语义分割感知算法(Semantic Segmentation),定位和建图算法(SLAM),高精地图算法(HD Maps)等等。
- 周围环境建模:在得到上一步各种感知模型的预测结果后,目前主流的做法是将各类感知算法输出的预测结果以车辆自身(Ego)为坐标系进行融合,从而构建一个周围环境感知行为的BEV空间预测地图,从而方便下游的规划和控制任务。
- 规划:在得到上一步输出的当前周围环境的BEV感知结果地图后,自动驾驶车辆上配备的路径规划算法会根据当前的交通规则以及车辆自身位姿设计相关的行驶路径,并根据行驶路径输出一套完整的相关驾驶行为决策。
- 控制:控制模块也就是整个自动驾驶流程的最后一步,此时的车辆会根据规划模块输出的一整套完成的驾驶行为决策进行判断,从而采取如转向(Steer),汽车加速(Accelerate),汽车减速(Brake)等相关的行为,实现对车辆的控制。
以上就是大致介绍了一下整个自动驾驶流程包括的所有内容,基本说明了一辆自动驾驶汽车从收集数据开始到最终完成驾驶行为的全过程。相信大家也可以看出,如果一辆自动驾驶汽车想要做出准确的决策,周围环境信息数据的采集和感知和定位算法模型的预测结果扮演了整个驾驶流程中至关重要的角色。
那么你接下来,我们先重点介绍一下自动驾驶流程图的第一步:周围环境信息数据的采集模块:
相机传感器是目前自动驾驶中最常用的数据采集传感器之一,因其可以采集到具有丰富语义信息的图像数据,且价格低廉而被广泛采用。一般而言,相机传感器包括:针孔相机或者鱼眼相机。鱼眼相机在一些短范围内的感知具有广泛的应用前景,然而无论是哪种类型的相机传感器,在面对现实世界的驾驶场景当中,都面临着一些非常严峻的问题,相关问题列举如下:
- 相机传感器在光线较暗的情况下表现较差:因为相机这类图像传感器主要是利用光线照射到物体上进行成像,但是在这种有限的光照条件下,严重的阻碍了成像结果中物体语义表示的质量,从而影响模型最终输出的感知结果,直接影响了后续的规控等任务 。
- 相机会暴露在外部自然场景当中:目前的自动驾驶车辆中,普遍都是采用环视相机的采集方式,同时这类环视相机通常都是安装在自动驾驶车辆的外部,这就会导致环视相机会暴露在沙子,泥土,污垢,灰尘,雨雪或者杂草等环境中,对相机造成影响,从而间接的影响到相机的成像结果,或者外参矩阵,间接的影响后续的感知定位、规划、控制等任务中。
- 强烈太阳光的干扰:在某些自动驾驶场景当中,可能会存在着天气特别晴朗的情况,这就会导致太阳光线过于充足,太阳的眩光会导致相机传感器的镜头表面被过度的曝光,严重影响了相机传感器采集到的图像质量,阻碍了下游基于视觉的障碍物感知算法的预测效果, 进而直接影响到后续的规划、控制模块的决策结果。
通过上述提到的诸多现实问题可以看出,虽然相机传感器不仅价格低廉,而且可以为后续的障碍物感知算法提供丰富的目标语义信息,但是其受环境的影响是非常巨大的,这就表明我们需要在自动驾驶车辆上配备额外传感器的原因。我们发现超声波传感器具有低功耗,对物体的颜色、材料不敏感,还可以比相机传感器更好的抵抗环境中的强烈光线,同时可以进行比较准确的短距离目标检测,对自动驾驶的障碍物感知是具有很要的数据采集价值。
考虑到以上传感器因素,同时为了更好的匹配下游的规控任务,我们在本文中设计了一种端到端的基于CNN卷积神经网络的多模态感知算法,利用鱼眼相机传感器和超声波传感器作为输入,实现在BEV空间的障碍物感知任务。
论文链接:https://browse.arxiv.org/pdf/2402.00637.pdf;
网络模型的整体架构细节梳理
下图是我们提出的算法模型的整体框架图,在介绍本文提出的基于CNN卷积神经网络的多模态感知算法各个子部分的细节之前,我们先整体概括一下整个算法的运行流程。
- 首先是采用预处理步骤,将超声波传感器采集到的原始回波数据的幅度信息转换为卷积神经网络可以进行处理的2D图像形式的数据。
- 其次采用CNN卷积神经网络对每个模态传感器采集到的数据完成特征提取过程,并且将提取到的多个模态的特征进行融合,构建出最终的模态无关特征。
- 然后是将上一步得到的模态无关特征完成空间上的转换过程得到BEV空间下的特征。
- 最后是将BEV空间特征喂入到语义分割任务的解码器当中,得到像素级别的障碍物预测结果。

图二:基于CNN卷积神经网络的多模态感知算法整体流程图
单一模态特征提取编码器

图三:部分障碍物对应的鱼眼相机和超声波传感器的数据响应可视化结果

BEV空间坐标系的映射过程
因为我们要完成鱼眼相机的2D图像特征向3D的BEV空间特征的变换,我们采用了Kannala-Brandt相机模型来实现这一变换过程。相比于基于图像中心半径的距离来表示径向畸变不同,Kannala-Brandt算法模型将相机畸变看作为通过透镜的光入射角函数,如下图的公式(1)所示。

由于在BEV投影过程中,需要将2D的图像特征投影到3D的BEV空间中,这就需要确保世界坐标空间中特定的网格区域的表示是非常准确的。因此,我们考虑将每个来自特征金字塔的特征图进行裁剪,从而保证2D图像特征对应于现实世界空间中定义的最大边界的精确上下边界。因此为了更好的从特征图中裁剪出相应区域,我们从公式(2,3,4)中确定失真系数。通过使用具有相应焦距、失真参数、主点和世界坐标空间高度和深度的公式(1),我们可以获得表示现实世界空间坐标系的图像空间坐标(u, v),从而就可以确定变换过程中每个网格的最小和最大深度,从而完成特征金字塔不同尺度特征的裁剪过程,最后利用相机的外参矩阵实现将图像特征变换为BEV空间特征。
基于内容感知的膨胀和多模态特征融合
由于本文是多模态的感知算法,需要同时利用图像和超声波的光谱特征,这就会遇到多模态算法中无法避开的一个问题:由于不同传感器采集到的数据代表了不同形式的环境表示。鱼眼相机通过图像像素的方式来捕获当前环境中丰富的语义信息,但是会丢失掉目标的深度以及几何结构信息。超声波传感器通过接收发射信号打到物体后发射回来的回波信号来感知周围的环境。这种不同传感器采集到的数据模态上的差异增加了特征融合过程中的难度。除此之外,在前文也有提到,相机传感器通常会暴露在自动驾驶车辆的外部,这就会造成周围环境会使得传感器发生潜在的错位风险,导致不同传感器采集到的同一个目标可能会在BEV空间中落到不同的网格单元中,从而直接造成融合后的多模态特征出现歧义性的问题,影响最终的感知算法预测结果。
所以,综合考虑到上面提到的多模态特征表示存在的差异,以及还可能出现的传感器错位之间的风险,我们提出了基于内容感知的膨胀和多模态特征融合模块。该模块中的膨胀卷积可以根据卷积核所在特征图的不同位置自适应的调整膨胀率的大小,相应的自适应膨胀卷积的计算公式如下:

以上就是我们提出的基于内容的膨胀卷积,通过该卷积用于调整超声波BEV空间特征。随后,将膨胀后的BEV空间特征与鱼眼相机完成空间转换后的BEV空间特征合并起来,从而实现多模态特征信息的融合,从而实现更准确的障碍物感知任务。
语义占用预测头
在获得了多模态的BEV空间特征后,我们制定了一个双阶段的多尺度语义占用网格预测解码器来得到最终的网格地图占用预测。解码器的具体网络结构如图九所示,该结构有两个顺序级联的残差块组成。第一个残差块用于避免在相同的分辨率内损害目标的空间特征。第二个残差块通过利用上下文特征来学习不同障碍物类型的先验几何形状信息。将多模态的BEV空间特征在多组级联的卷积网络中作用后得到最终的分割结果。
实验结果和评价指标
评价指标
由于我们设计的障碍物感知算法需要涉及到二值分割来区分前景和背景区域的目标,所以我们采用了一下的相关指标来评价我们设计模型的好坏。
- 召回率指标:该指标可以很好的反映出系统对于障碍物的感知能力,同时该指标也广泛应用于2D、3D检测任务当中,这里就不过多介绍了。
- 欧几里得距离指标:该指标可以帮助我们评估预测障碍和地面真实障碍在空间位置方面的一致性程度。预测障碍物与实际障碍物之间的距离是关键信息,以确保系统准确地感知障碍物的位置。
- 绝对距离误差:该指标可以准确的反映出障碍物感知网络模型将障碍物相对于自车作为参考的接近程度。通过了解这种相对距离有助于对象回避、刹车或者在转向的过程中做出实施决策。
- 归一化距离指标:该指标可以更好的评价模型预测出来的障碍物与自车之间的距离性能好坏。
实验结果(定量指标)
首先,我们比较了提出的多模态障碍物感知算法模型在室内和室外两种环境空间以及不同传感器下的检测性能,具体定量的数据指标如下图所示:

所提出的算法模型在不同场景下的指标汇总
通过实验结果可以看出,在室内场景来看,由于采用了超声波传感器采集到的数据,障碍物感知算法模型在距离指标上有着非常出色的预测优势,同时在召回率方面也要大幅度的超过单模态(纯相机)的算法算法版本。对于室外场景而言,所提出的算法模型得益于多模态数据互补的优势,各个指标均都要大幅度领先于单模态视觉的感知算法版本。
接下来是针对当前的两种不同版本的算法模型在各个不同障碍物类别上的感知结果性能汇总,不同类别具体定量的实验数据汇总在下表当中

通过上表可以看出,对于绝大多数的障碍物目标,当前提出的多模态算法模型在召回率、精度、交并比、距离、归一化距离、欧氏距离等各个指标上均要明显的高于单模态纯图像的算法版本。由此说明,通过多种模态的数据进行信息互补,不仅提高算法模型对于障碍物的检测识别性能,同时还可以更加精确的定位障碍物的的具体位置。
为了进一步的展示我们提出的多模态感知算法模型在距离上的感知优势,我们对不同距离段的感知性能指标进行了统计,具体统计结果如下表所示。

我们将模型5.8米的感知范围分成了四个不同的距离段,通过实验数据可以看出,随着距离的变远,仅仅使用单模态纯视觉的算法版本其召回率,距离性能均是不断下降的,因为随着距离的变远,图像中的目标变得越来越小,模型对于目标的特征提取变得更加困难。但是随着超声波传感器采集的信息加入,可以明显的看出,随着距离的变远,模型的精度并没有明显的降低,实现了不同传感器信息的互补优势。
实验结果(定性指标)
下面是我们多模态算法模型感知结果的可视化效果,如下图所示。

提出的算法模型感知结果的可视化效果
结论
本文首次提出了利用鱼眼相机传感器以及超声波传感器进行BEV空间的障碍物感知算法,通过定量指标(召回率、精度、欧氏距离以及归一化距离等指标)可以证明我们提出算法的优越性,同时上文可视化的感知结果也可以说明我们算法出色的感知性能。
# 自动驾驶中的坐标变换
本文对线性代数中的坐标变换、基变换两个概念的引入、性质进行了详细推导,并以自动驾驶中的传感器外参标定验证场景举例,介绍了坐标变换和基变换在实际工程中的应用,相信看完本文大家能对坐标变换和基变换有更深的理解。
本文默认读者具备基础的线性代数知识,包括基、线性组合、线性变换等概念。
应用背景

车辆系和相机系都是右手坐标系,一般情况下:车辆系的X轴指向车辆前方,Y轴指向车辆左方,Z轴指向天空;相机为前视相机,其坐标系为X轴指向车辆右方,Y轴指向地面,Z轴指向车辆前方。

车辆坐标系和相机坐标系
为什么需要坐标转换矩阵 T 呢,假设我们在图像中检测到一个行人,此时我们可以通过相机内参并结合其他测距传感器,得出该行人在相机系下的位置,但我们并不知道这个人距离车辆有多远,在车辆的正前方还是左前方。因此就需要一个坐标转换矩阵,将相机系下的三维点转换到车辆系下,供下游任务使用。
问题引入

为什么要对 R^{-1} 进行分解才能得知如何从车辆坐标系旋转到相机坐标系?为什么这么巧刚好是 R^{-1} ?先别懵,我们先验证这个结论对不对,再来解释为什么。
实验验证
为了实验能更加直观和真实,我们先做出如下设置:

车辆、相机与人的位置关系

include <eigen3/Eigen/Core>
int main(){
float pi = 3.14159265358979;
Eigen::Matrix3f R_inv;
R_inv << 0, 0, 1, -1, 0, 0, 0, -1, 0;
Eigen::Vector3f euler_angle = R_inv.eulerAngles(0, 1, 2); // 0: X轴,1: Y轴,2: Z轴,前后顺序代表旋转顺序,旋转方式为内旋
std::cout << "先绕X轴旋转: " << euler_angle[0] * 180 / pi <<std::endl;
std::cout << "再绕Y轴旋转: " << euler_angle[1] * 180 / pi << std::endl;
std::cout << "最后绕Z轴旋转: " << euler_angle[2] * 180 / pi << std::endl;
}
// Console Output:
// 先绕X轴旋转: -0
// 再绕Y轴旋转: 90
// 最后绕Z轴旋转: -90
在不考虑平移的情况下,坐标变换矩阵 T 中只包含 R ,因此我们也可以称 R 为坐标变换矩阵,其描述了坐标间的变换关系;我们将 R^{-1} 成为基变换矩阵,其描述了坐标系之间的变换关系。
我们接下来采用线性代数,来分析为什么坐标变换矩阵和基变换矩阵刚好就是互为逆的关系。
线性代数解释(坐标变换和基变换的本质)


基变换矩阵和坐标变换矩阵互为逆,推导完毕。
总结
基变换矩阵和坐标变换矩阵的关系之前也在矩阵论这门课中接触过,但当时完全不了解其应用场景,也对为什么这么取名一知半解。直到在实际应用中碰到了这个问题,才发现简简单单的两个公式,在使用时必须根据应用场景对齐进行区分,来选择究竟使用基变换矩阵还是坐标变换矩阵。
# 自动驾驶~BEV自动或半自动标注系统
这里提出了一种用于自动驾驶数据采集的自动或半自动标注系统,该系统既适用于研发阶段的车辆数据采集,也适用于量产阶段的客户数据采集。该方案同时为激光雷达和相机构建了一个3D场景半自动标注系统,它还允许独立运行激光雷达的点云标注或相机的视觉重建3D数据标注,以及两者(激光雷达和相机)的联合标注。本文提出的标注系统同时支持 BEV 感知和Occupancy(占用)感知,不仅适用于 BEV 网络的开发,也有助于占用网络的研究。自动驾驶量产阶段的BEV自动标注系统超实用指南
1.
现如今,自动驾驶已被公认为是一个“长尾分布”问题,需要不断发现极端案例数据,以提高解决方案的性能,获取有价值的数据、标注数据、模型训练、验证和部署等构成了开发自动驾驶的数据闭环。提供自动驾驶数据平台的云服务公司,都有半自动或自动标注业务功能,但大多侧重于2D图像,而非真实的3D场景。
Tesla在这一领域已经展现出强大的实力,自动标注能力突出。它充分利用纯视觉传感器数据构建整个自动标注大模型,通过深度学习方法从视觉重构中获取许多3D标注信息,如障碍物检测和道路(车道线)分割,以及运动、深度和本体车辆轨迹估计等。与此同时,谷歌 WayMo 和 Uber ATG 也推出了基于激光雷达数据的物体自动标注方法,可以从点云数据中分割出静态背景和动态车辆、行人,并分别细化静态背景和动态前景的结构。自制高清地图,标注车道标线、路沿、斑马线甚至箭头和文字等地图元素,也引起了更多关注。
目前,从传感器数据中标注静态背景大多通过 SLAM 或 SfM 方法完成 ,但对于移动物体而言,这仍然是一项挑战 。与视觉系统相比,激光雷达作为主动3D传感器具有天然优势。然而在实际中,视觉系统的3D标注存在明显问题,不能获得较好的准确性和鲁棒性。现有方法依旧存在一些薄弱环节:
1)自动驾驶场景数据的3D自动/半自动标注方法仍缺乏有效的开发模式,需要大量的人工工作来修正标注不准确的错误;
2)使用激光雷达和相机组合的自动驾驶数据3D自动/半自动标注系统相对较少,大多使用激光雷达或相机独立采集的数据标注任务;
3)在动态物体的3D自动/半自动数据标注方面仍然缺乏成熟的解决方案,尤其是在纯视觉领域;
4)目前,缺乏同时支持 BEV(鸟瞰)网络和Occupancy(占用)网络的标注工具设计和开发。
2. 数据获取和系统配置
作为自动驾驶数据采集系统,需要设置GNSS、IMU、摄像头、毫米波雷达和 LiDAR 等传感器。其中,激光雷达可能不是量产车辆的标准配置,因此量产车辆上获得的数据不包括三维激光雷达点云。摄像头的配置可以观测车辆附近的 360 度环境,6 个摄像头、5 个毫米波雷达和 1 个 360 度扫描 LiDAR。

图1|Nuscenes数据集车辆传感器配置
如果需要收集多模态传感器数据,则需要进行传感器校准,这涉及到确定每个传感器数据之间的坐标系关系,例如相机校准、相机-激光雷达校准、激光雷达-IMU校准和相机-雷达校准。此外,传感器之间需要使用统一的时钟(以全球导航卫星系统为例),然后使用特定信号触发传感器的操作。例如,激光雷达的传输信号可以触发照相机的曝光时间,而照相机的曝光时间是时间同步的。
作为自动驾驶开发平台,需要从车辆端和服务器云端支撑整个数据闭环系统,包括车辆端的数据采集和初步筛选、云端数据库基于主动学习的挖掘、自动标记、模型训练和仿真测试(仿真数据也可用于模型训练),以及模型部署回车辆端,数据选择和数据标注是决定数据闭环效率的关键模块。

▲图2|数据闭环架构
数据标注任务分为研发阶段和量产阶段:
1)研发阶段主要涉及开发团队的各种数据采集载体,其中包括激光雷达,这样激光雷达就能为相机的图像数据提供3D点云数据,从而提供3D真实值。例如,BEV(鸟瞰)视觉感知需要从二维图像中获取 BEV 输出,这就涉及到透视投影和3D信息推测;
2)在量产阶段,数据主要由乘用车客户或商用车运营客户提供。这些数据大多没有激光雷达数据,或者只是有限视场(如前方)的3D点云。因此,对于摄像头图像数据,需要估算或重建3D数据以进行标注。
3. 传感器数据标注的传统方法
3.1 激光雷达数据标注
深度学习模型算法需要数据进行训练,而传统方法可以进行无监督数据处理。首先,针对激光雷达数据,本文提出了3D点云标注的传统算法框架,如图 3 所示:

▲图3|激光雷达数据标注示意图
具体流程如下:
1)“预处理”模块包括点云数据的坐标转换(如极坐标表示法、测距图像或 BEV 图像)、去噪滤波和采样(包括“填补”缺失点云的“漏洞”)。在“SLAM”模块中优化点云和 IMU 数据序列,以进行激光雷达-IMU 测距估算和背景束调整 (BA),同时生成车辆运动轨迹;
2)由于激光雷达每次采集的视角不同且坐标变化较大,过多的障碍点会影响物体3D框架的提取。因此,“ROI extr”模块可从原始点云中筛选出感兴趣的区域;根据本体车辆的行驶轨迹和已知地图信息,可确定一个大致的道路区域作为 ROI;
3)每一帧点云数据都包含大量地面点,检测的目的是获取道路障碍物信息,这就需要对地面点云进行进一步分割。“grd seg”模块用于定位地面点云,路边也是行车道路的边界,这里可以采用分段平面拟合的方法,将点云沿 x 轴方向分为多段,然后应用 RANSAC 平面拟合方法提取每段中的地面点。检测道路边界时,设置距离阈值(15-30 厘米),以确保地面点包含所有道路边界点;
4)对于“grd seg”模块输出的非道路点云,在“clust”模块中,静态对象(障碍物)采用无监督聚类方法形成多个聚类,每个聚类代表一个障碍物(如交通锥和停车位)。聚类方法可以简单地使用欧氏距离进行聚类,如 K-means 或 DBSCAN;
5)在另一个“clust”模块中,移动物体(障碍物)也采用无监督聚类方法形成多个聚类,每个聚类代表一个障碍物(如车辆、行人、自行车等),算法与上一步相同;
对于运动物体,可在“Track”模块中使用3D卡尔曼滤波算法来确定物体在前一帧和后续帧中的点云关联和轨迹,从而获得更平滑的三维帧位置和姿态;根据物体的运动情况,可对多帧点云进行对齐,以构建更密集的点云输出(即刚性物体,如车辆;对于可变形物体,如行人,效果会减弱);
6)对于集群中的障碍物(包括静态和动态障碍物),可在两个不同的 "clust "模块中使用特征提取和分类器进行识别;此外,还可对每个集群进行三维立方体拟合,并计算障碍物的属性,如中心点、中心点、长度、宽度等;
7)“surf rec”模块对动态物体跟踪对齐的点云和静态物体聚类的点云处理,并运行形状恢复算法;
8)对于道路交通标线,如车道标线、斑马线和人行道标线,利用点云的反射值进行过滤,在“thre”模块中剔除路面上未标注的点云,在“clust”模块中将剩余的点连接到聚类中,并给出相应的车道标线和斑马线类别;
9)为了检测道路边界性,需要提取道路点云特征,如相邻点的高度差、平滑度和水平距离。然后,在“thre”模块中获得候选道路边界点,最后在“line fit”模块中对连接点进行片断逼近,并给出道路边界类别;
10)然后,在“Vect Rep”模块中用折线对这些路标进行分割和标记;
11)最后,将所有标注投影到车辆坐标系上,即单帧(激光雷达或摄像头),以获得最终标注。
如图 4 所示,激光雷达-IMU中关于“SLAM”模块的参考框架如下:
1)激光雷达的原始点在 10 毫秒(IMU 为 100Hz 更新)和 100 毫秒(激光雷达为 10Hz 更新)之间累积,累积的点云称为扫描数据;
2)为进行状态估计,新扫描的点云将使用紧耦合迭代卡尔曼滤波框架(IEKF)注册到大局部地图中维护的地图点(即里程测量)上;
3)地图使用增量 KD 树(ikd-tree)存储。 在状态估计方面,新扫描的点云与地图点(即odometry)通过一个紧密耦合的迭代卡尔曼滤波框架(IEKF)在一个大型局部地图中保持一致;
4)地图通过一个增量 kd-tree (ikd-tree)存储;观测方程是点云与地图之间的直接匹配;除了 k 近邻搜索(k-NN),它还支持增量地图更新(即点插入、向下平移);
5)在状态估计方面,新扫描的点云与地图点(即odometry)通过一个紧密耦合的迭代卡尔曼滤波框架(IEKF)在一个大型局部地图中保持一致。 如果激光雷达的当前 FoV 范围越过地图边界,则会从 ikd 树中删除离激光雷达姿态最远的地图历史点;
6)优化的姿态估计会将新扫描的点注册到全局坐标系,并以里程计速率将其插入 ikd 树(即映射),然后将其合并到地图中。

▲图4|激光雷达-IMU测距估算
3.2 多相机图像数据标注
对于多相机图像数据,本文提出了一种标注视觉数据的传统方法,即3D标注框架,具体流程如下:
1)首先,“SLAM/SFM”模块利用多相机视觉-IMU里程测量重建静态背景的特征点云;参考架构如图 6 所示(详细内容将在后面介绍);
2)同时,在“Mot Seg”模块中,根据运动轨迹选择运动与背景运动不同的匹配特征点对,并将其发送到“Clust”模块,以获得运动物体的不同特征点对(去除一些孤立的点对);
3)然后在“SLAM/SFM”模块中对特征点对进行聚类,以进行3D重建(其中 IMU 只负责自我车辆的运动,不参与动态物体的运动估计),其参考架构如图 7 所示(详细内容将在后面介绍);获得点云聚类后,将其拟合为3D物体(CAD 模型或矩形框);
4)为了恢复无特征图像区域中的遗漏点云,在“super-pixel seg.”模块中进行图像分割,并将带有重建特征点云的超像素反投影到3D空间(采用深度插值),形成密度更高的点云;然后将3D物体拟合到“Obj. Recog”模块进行分类(根据从超像素中提取的 RGB 特征,构建物体分类器,如基于 SVM 或 MLP 的分类器);
5)在“Grd. Det”模块对特征点云进行路面拟合,其中可选的“ROI Ext”模块能够用于根据估计的自我车辆轨迹选择路面作为感兴趣区域;然后将路面点云投影到图像中,并使用“reg.grow”模块中的泛洪填充算法获得路面面积;
6)在拟合路面的基础上,找到不在路面上的静态物体(障碍物)点云,然后在“clust”模块中生成特征点云簇,之后将其拟合为3D物体(CAD 模型或矩形框);同样,使用步骤 3) 中应用的“super-pixel seg”模块,可获得密度更高的重构;之后我们拟合3D物体,并进入“obj recog”模块进行分类;
7)动态物体 SLAM 和静态物体聚类得到的点云进入“surf recons”模块,运行形状恢复算法;
8)基于路面点云拟合得到路面方程,然后对路面标线进行处理:一种方法是首先在“Img Proc”模块中对路面区域进行灰度阈值二值化(如Otsu方法)、边缘检测(如Canny算子)和直线拟合(如Hough变换)。获取检测到的车道线、斑马线和道路边缘,然后将其投影回路面,称为IPM(逆投影映射); 另一种方式是先对路面图像逐像素进行IPM,然后在“Img Proc”中对IPM图像进行与上述类似的操作。 模块获取检测到的车道线、斑马线、道路边缘,这是路面的实际检测结果;
9)在“Vect Rep”模块中,对车道标线、斑马线和道路边缘进行分割,然后用分段折线进行标注;
10)最后,将所有标注投影到车辆坐标系上,即单帧上,得到最终标注。

▲图5|多相机数据标注
下述图 6 则是图 5 中多摄像机-IMU SLAM 的参考架构,由三个阶段组成。
前两个阶段的目的是线性初始化估计器,并在没有先验知识的情况下获得摄像机-IMU 校准的初始值;在第三阶段,利用前两个阶段的初始值,通过非线性优化开发紧密耦合的状态估计器。
初始化结构基本上是通过多次运行单目摄像头-IMU 系统的 VINS(视觉-惯性导航系统)来获得的。假设多个摄像头尚未校准(如果摄像头已经校准,则可以直接给出初始值),因此初始阶段不考虑摄像头之间的特征匹配。旋转校准与手眼校准过程类似,而平移校准将把 VINS 滑动窗口估计技术扩展到多台摄像机。在初始化步骤的基础上,根据摄像机之间的相对姿态,建立同一摄像机(时间)和不同摄像机(空间)之间的特征跟踪。直观地说,视场重叠的摄像头可以实现特征的三维三角测量。另一方面,如果摄像机之间没有重叠视场,或者特征点距离太远,系统就会退化为多个单目 VINS 配置。

▲图6|多相机-MU SLAM
前面所提到的多摄像头SLAM框架包括三个模块:多摄像头视觉定位、全景建图和闭环校正。
多摄像头视觉定位的目标是实时获取车辆的6D位姿。 基于多相机空间感知模型,可以通过多相机图像帧快速估计姿态。 定位过程可以分为三个状态:初始化、跟踪和重新定位。
地图系统根据匹配的特征点构建稀疏点云来创建地图,每个地图点由特征点描述符组成,从而使地图可重复使用。 为了避免地图太大,它只为满足特定条件的关键帧构建地图。 关键帧由从多相机图像中提取的特征组成。 为了表示关键帧之间的共视信息,以关键帧为节点,以两帧之间共享地图点的数量作为边的权重来构建共视图。 权重越大意味着更多的帧共享观察结果。 映射过程包括同步和异步两种。 同步映射使用任意一对摄像机参与3D场景构建过程。 异步映射利用公共视图中的当前和先前关键帧来对地图点进行三角测量。
闭环检测是系统检测是否回到之前场景的能力,基于闭环检测的修正可以大大提高系统的全局一致性。 基于闭环信息,可以同时修正轨迹和地图。

▲图7|多相机SLAM
3.3 激光雷达-多相机数据联合标注
基于提供的LiDAR点云和多相机图像数据,可以用传统方法对其进行联合标注,如图8所示:
1)输入的LiDAR数据经过“预处理”模块进行点云滤波处理,然后与多相机图像数据组合进入“SLAM”模块。 这里,LiDAR点云被投影到图像平面上形成深度网格,与用于车辆里程计的IMU联合估计,并重建3D密集点云图。 架构如图9所示(后面会详细介绍);
2)类似图3,然后进入“Mot Seg”模块获取运动物体和静止背景,同时运动物体还运行“Clust”模块、“Track”模块、“Obj Recog”模块获取运动障碍物 标注;
3)另一方面,在静止背景上运行“grd seg”模块会产生两部分:静态物体(障碍物)和路面:前者类似于图3,运行“clust”模块和“obj recog” ”模块获取静态障碍物标签,而后者类似于图5,运行“reg Growth”模块、“img proc”模块(基于路面方程的IPM)和“vect rep”模块获取折线 道路车道线、斑马线和道路边界的标记;
4)动态目标跟踪和静态目标聚类得到的点云进入“surf recon”模块并执行形状恢复算法;
5)最后将所有标注投影到单帧的车辆坐标系上,得到最终的标注。

▲图8|LiDAR+多相机数据标注
下述图 9 则显示了激光雷达-多摄像头-IMU SLAM 框架:
1)将激光雷达点云投射到每个相机上形成深度网格,同时对每个图像进行特征检测和跟踪以获得初始姿态;
2)深度网格和2D特征位置可结合在一起计算2D特征的深度(注:此处每个相机-激光雷达构成一个 SLAM 管道);
3)然后,使用特征跟踪数据和 IMU 数据初始化估计器;
4)之后,使用 IMU 的姿态、速度和来自 IMU 预积分的偏差以及相机帧特征创建滑动窗口。非线性优化过程用于执行状态估计;
5)获得滑动窗口的估计状态后,与闭环检测(位置识别)模块一起执行全局姿态图优化,最后获得3D点云图。

▲图9|LiDAR-相机-IMU SLAM
4. 传感器标注的半传统方法
上一节3中处理激光雷达点云和相机图像的传统方法存在一些问题,如激光雷达的点云聚类、基于反射阈值的检测和线拟合,以及图像的超像素分割、区域生长、二值化和边缘检测,这些方法在复杂场景中往往效果不佳。下面将引入一些深度学习模型来加以改进。
4.1 激光雷达数据标注
首先,针对LiDAR点云,本文提出了半传统的标注方法框架,具体流程如下:
1)与图3类似,这个框架也包括“预处理”模块、“SLAM”模块(其架构如图4所示)和“mot seg”模块。 然后,在“inst seg”模块中,直接对与背景不同的移动物体执行基于点云的检测,而神经网络模型用于从点云中提取特征图(例如PointNet 和PointPillar);
2)之后与图3类似,在“Track”模块中,我们对每个分割对象进行时间关联,以获得动态对象的3D边界框的标注;
3)对于静态背景,经过“Grd Seg”模块后,被判断为非路面的点云进入另一个“Inst Seg”模块进行物体检测,然后可以获得静态物体的bbox边界框;
4)对于路面的点云,输入到“Semantic Seg”模块,然后基于深度学习模型,我们利用反射强度对与图像相似的语义对象进行逐像素分类,即 车道标记、斑马线和道路区域。 通过检测道路边界得到路缘石,最后在“Vect Rep”模块中进行基于折线的标注;
5)跟踪的动态物体点云和实例分割得到的静态物体点云进入“surf recon”模块并运行形状恢复算法;
6)最后,将所有标注作为单帧投影到车辆坐标系上,得到最终的标注。

▲图10|LiDAR数据标注框架流程
4.2 多相机图像数据标注
对于来自多个相机的图像数据,本文提出了半传统的3D标注框架,具体流程如下:
1)首先在多相机的图像序列中使用“inst seg”、“深度图”和“光流”三个模块,分别计算实例分割图、深度图和光流图; “inst seg”模块使用深度学习模型来定位和分类一些对象像素,例如车辆和行人,“深度图”模块使用深度学习模型来估计两个连续的像素级运动 基于单目视频的帧形成虚拟立体视觉来推断深度图,“光流”模块使用深度学习模型直接推断两个连续帧的像素运动; 三个模块尝试使用无监督学习的神经网络模型;
2)基于深度图估计,“SLAM/SFM”模块可以获得类似于RGB-D+IMU传感器的密集3D重建点云,(类似于激光雷达+相机+IMU的SLAM框架,如 如图9所示,仅省略了将激光雷达点云投影到图像平面上的步骤); 同时,实例分割结果实际上允许从图像中去除障碍物,例如车辆和行人,同时基于本体车辆里程计和光流估计进一步区分“mot seg”模块中的静态和动态障碍物 ;
3)实例分割得到的各种动态障碍物将在接下来的“SLAM/SFM”模块中重建,类似于RGB-D传感器的SLAM架构,可以是单目的扩展 SLAM,如图7所示; 然后,它将“inst seg”的结果传输到“obj recog”模块并标注对象点云的3D边界框;
4)对于静态背景,“grd det”模块将区分静态物体和道路点云,以便静态障碍物(如停车车辆和交通锥)将“inst seg”模块的结果传输到“obj recog” ”模块,标注点云的 3D 边界框;
5)从“SLAM/SFM”模块获得的动态物体点云和从“grd det”模块获得的静态物体点云进入“Surf Recon”模块运行形状恢复算法;
6)路面点云仅提供拟合的3D路面。 从图像域“inst seg”模块中可以获得路面面积。 基于自我里程计,可以进行图像拼接。 在拼接的路面图像上运行“seman seg”模块后,可以获得车道标线、斑马线和道路边界。 然后,使用“vectrep”模块进行多线标记;
7)最后,将所有标注作为单帧投影到车辆坐标系上,得到最终的标注。

▲图11|多相机图像数据的3D标注框架流程
4.3 激光雷达-多相机数据联合标注
因此针对LiDAR和摄像头的数据,本文提出了一种半传统的联合数据标注方法框架,具体流程如下:
1)当多相机图像和LiDAR点云同时存在时,将图11中的“光流”模块替换为“场景流”模块,该模块基于深度学习模型估计3D点云的运动; 将“深度图”模块替换为“深度复杂”模块,该模块使用神经网络模型来完成将点云投影(插值和“孔填充”)到图像平面上获得的深度, 然后反投影回3D空间生成点云; 将“inst seg”模块替换为“seman. seg.” 模块,使用深度学习模型根据对象类别来标记点云;
2)随后,密集的点云和IMU数据将进入“SLAM”模块来估计里程计(其架构如图4所示),并选择标记为障碍物(车辆和行人)的点云。 同时,预估的场景流量也会进入“mot seg”模块,进一步区分移动障碍物和静态障碍物;
3)之后,与图10类似,一旦运动物体经过“inst seg”模块和“track”模块,就获得了运动物体的标注; 同样,经过“grd seg”模块后,静态障碍物被“inst seg”模块标记; 地图元素,例如车道标记、斑马线和道路边缘,是通过运行“seman. 段。” 模块中的拼接路面图像和对齐的点云,然后进入“vectrep”模块进行折线标记;
4)跟踪获得的动态物体点云和实例分割获得的静态物体点云进入“surf recon”模块,该模块运行形状恢复算法;
5)最后,将所有标注作为单帧投影到车辆坐标系上,得到最终的标注。

▲图12|LiDAR和相机联合标注框架
5. 基于深度学习的数据标注方法
最后,基于一定数量的标注数据,系统能够构建完整的深度学习神经网络模型来标注激光雷达点云和相机图像数据,包括独立的激光雷达点云标注模型、独立的相机图像标注模型、 以及LiDAR点云和多相机图像数据的联合标注模型。
5.1 激光雷达数据标注
本文为完整的深度学习模型设计了LiDAR点云标注系统,具体流程如下:
1)首先,在“voxe-lization”模块中,点云被分成均匀间隔的体素网格,生成3D点和体素之间的多对一映射; 然后进入“Feat Encod”模块,将体素网格转换为点云特征图(使用PointNet 或PointPillar);
2)一方面,在“视图变换”模块中,将特征图投影到BEV上,其中组合了特征聚合器和特征编码器,然后在BEV空间中进行BEV解码,划分成两个头:一个头检测“Map Ele Det”模块中道路地图元素的关键点和类别(即回归和分类),例如车道标记、斑马线和道路边界,其结构类似于基于Transformer架构的DETR模型,同样使用可变形注意力模块,输出关键点的位置及其所属元素的ID; 这些关键点被嵌入到“PolyLine Generator”模块中,该模块也是基于 Transformer 架构的模型。 基于BEV特征和初始关键点,折线分布模型可以生成折线的顶点并获得地图元素的几何表示; 另一个头通过“obj det”模块进行BEV物体检测,其结构类似于PointPillar模型;
3)另一方面,3D点云特征图可以直接进入“3D Decod”模块,通过3D反卷积获得多尺度体素特征,然后在“Occup”中进行上采样和类别预测。 生成体素语义分割的模块。

▲图13|LiDAR数据标注框架
5.2 多相机图像数据标注
然后本文设计了一个完整的深度学习模型的多相机图像标注系统,具体流程如下:
1)多相机图像首先通过“backbone”模块进行编码,例如EfficientNet或RegNet加FPN/Bi-FPN,然后分为两条路径;
2)一方面,图像特征进入“视图变换”模块,通过深度分布或Transformer架构构建BEV特征,然后分别转到两个不同的头:类似于图13,一个 head通过“地图元素检测器”模块和“折线生成器”模块输出地图元素的矢量化表示; 另一个头通过“BEV obj Detector”模块获取obj BEV边界框,可以使用Transformer架构或类似的PointPillar架构来实现;
3)另一方面,在“2D-3D变换”模块中,2D特征编码根据深度分布投影到3D坐标,其中高度信息被保留; 获得的相机体素特征然后进入“3D解码”模块以获得多尺度体素特征,然后进入“Occupancy”模块进行类别预测以生成体素语义分割。

▲图14|多相机数据标注框架
5.3 激光雷达-多相机数据联合标注
最后本文设计了一个激光雷达点云+相机图像数据联合标注的深度学习系统,其详细模型架构如下:
1)相机图像进入“backbone”模块,获取2D图像编码特征;
2)LiDAR点云进入“voxe-lizat”和“feat encod”模块获取3D点云特征;
3)之后分为两条路:
-通过“视图变换”模块将点云特征投影到BEV,同时通过另一个“视图变换”模块基于Transformer或深度分布提取图像特征; 然后我们在“Feat concat”模块中将这两个特征连接在一起; 接下来,转到两个不同的头:一个头通过“BEV obj Detector”模块,类似于PointPillar架构,并获取BEV对象边界框; 另一个头通过“Map Ele Detector”模块和“polyLine Generator”模块输出地图元素的矢量化表示;
-图像特征通过“2D-3D变换”模块投影到3D坐标上,保留高度信息,然后在另一个“feat concat”模块中与点云特征连接以形成体素特征; 接下来,进入“3D Decod”模块和“Occup”模块,得到体素语义分割。

▲图15 LiDAR-多相机数据联合标注模型架构
6. 结语
本文提出的自动驾驶数据标注系统实施指南,结合了传统方法和深度学习方法,可以满足研发阶段和量产阶段的需求。 同时,传统方法需要一些人工辅助,为下一步的全深度学习方法提供训练数据。
# 自动驾驶技术の进化
自动驾驶技术的进化:从SLAM+DL到BEV+Transformer 讲起~~
自动驾驶技术在20世纪初的概念和实验主要集中在车辆自动化和遥控方面。到了20世纪80年代和90年代,随着计算机技术和人工智能的发展,自动驾驶技术开始取得显著进展。这一时期,一些大学和研究机构开始开发原型车辆,能够在特定条件下实现自动驾驶。
进入21世纪,自动驾驶技术迎来了快速发展期。随着传感器、算法、计算能力和大数据技术的进步,多家科技公司和汽车制造商开始投入巨资研发自动驾驶车辆。
目前,自动驾驶技术正处于逐步成熟阶段,虽然还面临着技术、法律、伦理和安全等多方面的挑战,但其发展潜力仍然不可小觑,将对交通安全、效率、环境保护等产生深远影响。
这里梳理自动驾驶技术的进化与发展。
1. 自动驾驶的经典框架
如图1是自动驾驶的经典框架,其中,最为重要的任务是场景理解任务,这一任务在学术文章中常常称之为感知任务,伴随AI技术蓬勃发展,感知任务也在不断刷新其性能上限。为辅助车辆控制系统,以及理解周围环境,自动驾驶系统使用了各种感知技术,最为重要且广为人知的就是:SLAM(同步定位与建图)和BEV(鸟瞰视图)技术。这些技术赋予车辆无论在静止还是移动的状态下,理解自身位置、检测周围障碍物、以及估计障碍物方向和距离的能力,这些能力为后续驾驶决策提供信息。

图1|经典的自动驾驶框架
2. SLAM+DL 第一代自动驾驶感知技术
2.1 简介
开门见山,第一代自动驾驶感知技术,是以SLAM算法结合深度学习技术相结合为代表的。第一代自动驾驶感知技术框架中的多种任务,例如:目标检测和语义分割任务,都必须和输入数据处于相同坐标系统下实施。如下图2所示,唯一例外的是相机感知任务,它是在2D图像的透视空间中运行的。但是,为了从2D空间升级到3D空间,2D检测任务需要很多关于传感器融合的手动规则,例如使用雷达或者激光雷达等传感器进行3D测量。因此,传统感知系统通常需要在与车载摄像机图像相同的空间内进行处理。为了将2D空间中的位置信息更新到3D空间,后续的预测和规划任务常常用于多传感器融合,如借助毫米波雷达或激光雷达等有源传感器。

图2 SLAM+DL的自动驾驶技术框架
■2.2问题和挑战
但是,上述基于SLAM+DL的第一代自动驾驶技术暴露出越来越多的问题:
1)整个自动驾驶系统最上游的是感知模块,尤其当传感器的类型和数量变的越来越复杂,如何融合持续输入的多模态和不同视图数据,并实时输出下游所需的一系列任务结果,成为自动驾驶的核心挑战。
2)感知环节通常会消耗车辆的大部分算力。在感知过程中,系统需要融合不同视角摄像头的视觉数据以及毫米波雷达、激光雷达等传感器的数据,这给模型设计和工程实现带来了挑战。在传统的融合后处理方法中,每个传感器对应一个神经网络,无法充分发挥多传感器融合的优势,而且计算量大、耗时长。此外,如果多个任务简单地共享一个骨干网络,很容易导致每个任务难以同时获得优异的性能,如图3所示。

图3|一种多模态融合算法示意图
3. BEV+Transformer 第二代自动驾驶感知技术
3.1 BEV方案基本流程
·简介
BEV(鸟瞰视图)模型基于多个摄像头甚至不同传感器,可以被视为解决上述SLAM+DL第一代自动驾驶技术问题的潜在技术方案,本文将BEV+Transformer结合技术成为自动驾驶感知2.0时代。如图4所示,BEV以鸟瞰图视角呈现车辆信息,是自动驾驶系统中跨摄像头和多模态融合的体现。其核心思想是将传统的2D图像感知转为3D感知。对于BEV感知来说,关键在于将2D图像作为输入并输出3D感知帧,而如何在多摄像头视角下高效优雅地获得最佳特征表示仍是一个难题。

图4|BEV视图
目前,基于多视角相机的BEV3D物体检测感知任务,受到越来越多的关注。如图5所示,在BEV视图下,统一和描述不同视角的信息是非常直观自然的,这为后续规划和控制模块的任务提供了便利。此外,BEV视图下的物体在2D视角下不存在遮挡和比例问题,有助于提高检测性能。BEV模型还有助于提高感知融合的性能,并通过统一的模型实现从纯视觉感知到多传感器融合解决方案的逻辑一致性,从而降低额外的开发成本。

图5|纯视觉的端到端规划框架
· BEV技术方法
目前为止,BEV研究主要基于深度学习方法。根据BEV特征信息的组织方式,主流方法可分为不同架构的模式。
■3.2 自底向上 vs. 自顶向下
· 自底向上方法
自底向上法采用了从2D到3D的模式:
1)首先,在2D视图下估计每个像素的深度信息,然后基于相机内外参数将图像映射到BEV空间。
2)然后,通过融合多个视图生成BEV特征。
这种方法的早期代表方法是LSS(Lift、Splat、Shoot),如图6所示,它构建了一个简单而有效的处理过程:
1)将2D相机图像投射到3D场景中;
2)然后从上帝视角把得到的3D场景“压扁”,形成BEV视图。

图6|Lift-Splat-Shoot架构
平面场景符合人们对地图的直观感觉,虽然已经获得了三维场景数据,但并不是完整的三维数据,因为从 BEV 的角度来看,无法获得准确的三维高度信息,所以需要将其扁平化。自下而上法的核心步骤是:
1)拉升----在对每幅相机图像进行图像平面下采样后,准确估计特征点的深度分布,并获得包含图像特征的视锥(点云);
2)拍打----结合摄像机的内部和外部参数,将所有摄像机的视锥(点云)分布到 BEV 网格中,并对每个网格中的多个视锥点进行求和汇集计算,形成BEV 特征图;
3)拍摄----使用任务头处理 BEV 特征图,输出感知结果。
LSS 和 BEVDepth等算法基于 LSS 框架进行了优化,是 BEV 算法的经典之作。
· 自顶向下方法
自顶向下法采用了从3D到2D的模式:
1)这类方法首先初始化BEV空间中的特征;
2)然后通过一个多层的Transformer与每个图像特征进行交互,得到与之对应的BEV特征。
Transformer 是谷歌在 2017 年提出的一种基于注意力机制的神经网络模型。与传统的 RNN 和 CNN 不同,Transformer 通过注意力机制挖掘序列中不同元素之间的联系和关联,从而适应不同长度和结构的输入。Transformer 首先在自然语言处理(NLP)领域取得了巨大成功,随后被应用于计算机视觉(CV)任务,并取得了显著效果。
这种自顶向下的方法逆转了 BEV 的构建过程,利用 Transformer 的全局感知能力从多个透视图像的特征中查询相应信息,并将这些信息融合和更新到BEV 特征图中。特斯拉在其 FSD Beta 软件视觉感知模块中采用了这种自上而下的方法,并在特斯拉 AI-Day上展示了有关 BEVFormer的更多技术理念。
■3.3 纯视觉还是多传感器融合?
BEV 目前已经是自动驾驶领域一个庞大的算法家族,包括不同方向的算法选择。其中,以视觉感知为主的流派由特斯拉主导,核心算法建立在多个摄像头上。另一大流派是融合派,利用激光雷达、毫米波雷达和多个摄像头进行感知。许多自动驾驶公司都采用了融合式算法,谷歌的 Waymo 也是如此。从输入信号的角度来看,BEV 可分为视觉流派和激光雷达流派。
· BEV相机
BEV 相机指的是基于多个视角的图像序列,算法需要将这些视角转换为 BEV 特征并对其进行感知,例如输出物体的三维检测帧或在俯视图下进行语义分割。与激光雷达相比,视觉感知具有更丰富的语义信息,但缺乏精确的深度测量。此外,BEV 的 DNN 模型需要在训练阶段指出照片中的每个物体是什么,并在标注数据上标注各种物体。如果遇到训练集中没有的物体类型,或者模型表现不佳,就会出现问题。
为了解决这个问题,Occupancy Network改变了感知策略,不再强调分类,而是关注道路上是否有障碍物。这种障碍物可以用三维积木来表示,有些地方称之为体素(voxel)。这种方法更为贴切,无论障碍物的具体类型如何,都能保证不撞击障碍物。
特斯拉正在经历从 BEV 技术(鸟瞰图)到新技术--occupancy network(占用网络)的过渡,从二维到三维。无论是二维还是三维,它们都致力于描述车辆周围空间的占用情况,但使用的表示方法不同。在二维 BEV 中,我们使用类似棋盘的方法来表达环境中的占用情况;而在三维占用网络中,它们使用类似积木的体素来表达。
具体来说,在 BEV 技术中,深度学习模型(DNN)通过概率来衡量不同位置的占用率,通常将物体分为两类:
1)不经常变化的物体,如车辆可通过区域(Driveable)、路面(Road )、车道(Lane)、建筑物(Building)、植被(Foliage/Vegetation)、停车区域(Parking)、信号灯(TrafficLight)以及一些未分类的静态物体(Static),这些类别可以相互包含。
2)另一类是可变物体,即会移动的物体,如行人(Pedestrian)、汽车(Car)、卡车(Truck)、锥形交通标志/安全桶(TrafficCone)等。
这种分类的目的是帮助自动驾驶系统进行后续的驾驶规划和控制。在BEV的感知阶段,算法根据物体出现在网格上的概率进行打分,并通过Softmax函数对概率进行归一化处理,最后选择概率最高的物体类型对应的网格作为占据网格的预测结果。

图7|BEVFormer流程
BEVFormer的详细流程如下:
1)使用基干和脖颈模块(使用 ResNet-101-DCN + FPN)从环视图像中提取多尺度特征。
2)编码器模块(包括时间自注意力模块和空间交叉注意力模块)使用本文提出的方法将环视图像特征转换为 BEV 特征。
3)与可变形 DETR 的解码器模块类似,它完成三维物体检测的分类和定位任务。
4)使用匈牙利匹配算法定义正负样本,并使用 Focal Loss + L1 Loss 作为总损失来优化网络参数。
5)计算损失时使用 Focal Loss 分类损失和 L1 Loss 回归损失,然后执行反向传播并更新网络模型参数。
在算法创新方面,BEVFormer 采用 Transformer 和时间结构来聚合时空信息。它利用预定义的网格状 BEV 查询与空间/时间特征进行交互,以查找和聚合时空信息。这种方法能有效捕捉三维场景中物体的时空关系,并生成更强大的表征。这些创新使 BEVFormer 能够更好地处理环境中的物体检测和场景理解任务。
· BEV融合

图8|奔驰智能驾驶配备的传感器套件
BEV 融合学派在自动驾驶领域的主要任务是融合各种传感器的数据,如图 8所示,包括摄像头、激光雷达、GNSS(全球导航卫星系统)、里程表、高精度地图(HD-Map)、CAN总线等。这种融合机制可以充分利用各个传感器的优势,提高自动驾驶系统对周围环境的感知和理解能力。
除了摄像头,融合学派还关注激光雷达的数据。与毫米波雷达相比,激光雷达的数据质量更高,因此毫米波雷达逐渐退出了主要用途,在一些车辆中继续充当停车雷达。然而,毫米波雷达仍有其独特的价值,尤其是在自动驾驶领域技术日新月异的背景下。新算法可能会让毫米波雷达重新发挥作用。
激光雷达的优势在于可以直接测量物体的距离,其精度远高于视觉推测的场景深度。激光雷达通常将测量结果转化为深度数据或点云,这两种数据形式的应用历史悠久,成熟的算法可以直接借鉴,从而减少开发工作量。此外,激光雷达在夜间或恶劣天气条件下仍能正常工作,而相机在这种情况下可能会受到很大影响,导致无法准确感知周围环境。
总之,融合学派的目标是有效整合多传感器数据,使自动驾驶系统在各种复杂条件下获得更全面、更准确的环境感知,从而提高驾驶的安全性和可靠性。融合技术在自动驾驶领域发挥着关键作用。它融合了来自不同传感器的信息,使整个系统能更好地感知和理解周围环境,做出更准确的决策和计划。
4. 下一代驾驶技术为什么是BEV+Transformer
4.1 为什么是BEV感知?
首先,自动驾驶是一个 3D 或 BEV 感知问题。使用 BEV 视角可以提供更全面的场景信息,帮助车辆感知周围环境并做出准确决策。在传统的二维视角中,由于透视效应,物体可能会出现遮挡和比例问题,而 BEV 视角可以有效解决这些问题。
与以往自动驾驶领域基于正视图或透视图进行检测、分割、跟踪等任务的大多数模型相比,BEV 表示法能使模型更好地识别遮挡的车辆,有利于后续模块(如预测、规划控制)的开发和部署。同时,它还能将二维图像特征精确转换为三维特征,并能将提取的 BEV 特征应用于不同的探测头。
另一个重要原因是促进多模态融合。自动驾驶系统通常使用多种传感器,如摄像头、激光雷达、毫米波雷达等。BEV视角可以将不同传感器的数据统一表达在同一平面上,这使得传感器数据的融合和处理更加方便。在现有技术中,将单视角检测扩展到多视角检测是不可行的。
这是因为单视角检测器只能处理单个摄像头的图像数据,而在多视角的情况下,检测结果需要根据相应摄像头的内外部参数进行转换,才能完成多视角检测。然而,这种简单的后处理方法无法用于数据驱动训练,因为变换是单向的,无法反向区分不同特征的坐标系原点。这使得我们无法轻松地使用端到端训练模型来改进自动感知系统。为了解决这些问题,基于变换器的 BEV 感知技术应运而生。
总之,对于摄像头的感知而言,转向 BEV 将大有裨益:
1)直接在 BEV 中执行摄像头感知可直接与雷达或激光雷达等其他模式的感知结果相结合,因为它们已在 BEV中表示和使用。BEV 空间中的感知结果也很容易被预测和规划等下游组件使用。
2)纯粹通过手工创建的规则将 2D 观察结果提升到 3D 是不可扩展的。BEV 表示法有助于向早期融合管道过渡,使融合过程完全由数据驱动。
3)在没有雷达或激光雷达的纯视觉系统中,通过BEV 执行感知任务几乎是强制的,因为在传感器融合中没有其他三维线索可用于执行这种视图转换。之所以选择从 BEV 的角度进行感知,是为了提高感知的准确性和稳定性,并为多模态融合和端到端优化创造条件,从而推动自动驾驶技术的发展。
■4.2 为什么是BEV+Transformer?
为什么 "BEV+Transformer "会成为主流模式?其背后的关键在于 "第一原则",即智能驾驶应该越来越接近 "像人一样驾驶",而映射到感知模型本身,BEV 是一种更自然的表达方式,由于全局注意力机制,变形器更适合进行视图转换。目标域中的每个位置访问源域中任何位置的距离都是相同的,克服了 CNN 中卷积层感受野的局部局限性。此外,与传统的 CNN 相比,视觉转换器还有几个优势:更好的可解释性和更好的灵活性。随着产学研的推进,BEV+Transformer 最近已从普及走向量产,这在当前智能驾驶的商业颠覆背景下或许是一个难得的亮点。
5. BEV+Transformer的学术研究趋势
1. 数据采集和预处理 BEV 透视需要进行大量的数据采集和预处理,这对场景感知的性能和效果有着重要影响。其中,需要解决多相机图像融合、数据对齐、畸变校正等问题。同时,变换器需要海量数据,如何获取高质量的海量数据也是一个重要的研究课题。
2. Transformer是暴力美学,模型体积惊人,其计算会消耗大量的存储和带宽空间。对于芯片而言,除了相应的运算器适配和底层软件优化外,还需要对缓存和带宽进行优化,要求也随之提高。与此同时,还需要对模型进行优化。

图9|模型优化性能对比图
3. 更多传感器融合: 目前,BEV 透视技术主要使用激光雷达和摄像头等传感器进行数据采集和处理,但仍需要更多传感器的融合,如图10所示的毫米波雷达、GPS等,以提高数据的准确性和全面性。

图10|更多的传感器数据融合
4. 稳健优化:BEV 在复杂环境中的应用面临诸多挑战,如天气变化、光照变化、目标遮挡、对抗性攻击等。未来有必要加强算法的鲁棒优化,以提高系统的稳定性和可靠性。

图11|复杂场景下的BEV感知
5. 应用场景更多:BEV 技术的应用场景非常广泛,包括自动驾驶、智能交通、物流配送、城市规划等领域,如图12中的机器人。自动驾驶与 BEV 的融合可以提供全方位的场景信息,有利于车辆准确感知周围的物体和环境,实现高效、安全的自动驾驶。BEV视角下的智能交通可以提供更直观、更全面的路况信息,有利于实现高效的路况监测和交通管理,提高城市交通的效率和安全性。物流配送与 BEV 的结合可以提供更准确、更全面的货物位置和空间信息,有利于实现高效的物流配送,提高物流效率和服务质量。未来,应用领域还可以进一步拓展,如农业、矿业等领域,满足不同领域的需求。

图12|BEV在机器人领域中的应用
6. 总结
从行业发展趋势来看,BEV 模式及其应用或将成为主流趋势。这意味着从芯片开始,传感器芯片、摄像头、软件算法等都需要快速适应,快速实现解决方案。
综上所述,BEV 是继深度学习之后的又一新高度,它解决了以往多传感器变化和异构带来的各种融合感知算法的发展难题。从原理上讲,与传统的感知算法相比,BEV 的输入相同,都是多通道传感器信息,最后直接输出三维空间规划和控制所需的输出形式。BEV 基于二维数据,提供鸟瞰视角,与 SLAM 相辅相成,为自动驾驶的发展和实现带来了更多可能。随着技术的不断进步,感知模块也将不断发展,更高效、更精准的感知技术将推动自动驾驶技术走向更广阔的未来,为人类社会的进步贡献更多价值。
# 特斯拉の“纯视觉”

BEV+Transformer+占用网络技术路线的大热,再次将激光雷达推向风口浪尖。
激光雷达该不该被抛弃?
对车企来说,这是一个艰难的抉择:是坚定不移跟随特斯拉走具有「性价比」的纯视觉路线,还是采用看起来「成本稍高」的激光雷达融合方案?
要回答这个问题并不难——尤其是当你洞悉事情的真相是反常识的时候。
比如,去除激光雷达,看起来减掉的是智能驾驶系统的 BOM 成本,整车成本也随之下降了,但冰山之下的隐性成本增加了多少,你计算过吗?
再比如,占用网络的白名单可以覆盖包括机动车、行人、两轮车、锥桶、水马、路面、树木等十几个常见的「道路物体」,但白名单之外的物体,它能看见吗?
在城市 NOA 大规模落地前夕,整个智能驾驶行业需要重新审视纯视觉方案背后的成本和技术难易程度,以及激光雷达的核心价值。
「抄特斯拉作业」是否是最佳选择?在城市 NOA 落地浪潮下,车企如何集中优势发挥所长?
这些都是需要被优先考虑的问题。
01 模仿特斯拉 不该忽略纯视觉路线背后的「隐性成本」
「4 颗以下,请别说话。」这可能是此前汽车行业「卷」激光雷达最出圈的表达。
到今天,激光雷达仍然是绝大部分头部车企新车的标配。从蔚小理,再到华为(问界、阿维塔)、极氪、零跑,激光雷达在国内能够快速量产上车,很大程度上是由他们直接或间接推动的。
激光雷达的风靡,来自其带给消费者的科技感和安全感。
而当「降本」的旋风刮来,在特斯拉跑通纯视觉方案之后,「去激光雷达」的声音又此起彼伏。
短期看,拿掉激光雷达,「降本效果」立现。
然而从长期看,车企需要为这一选择投入更多的研发资源。

禾赛科技战略负责人施叶舟认为,「在考虑成本的时候,不能够只看到硬件成本,实际上更要考虑背后所需要各种研发服务和资源投入,也就是『全成本』——除了冰山上面的显性成本(硬件、BOM 成本),还有大量被忽视的隐性成本。」
这里所称的纯视觉技术路线中的「隐性成本」,包括算法、路测、云计算、数据标注、仿真训练和系统软件等。
特斯拉前 AI 高级总监 Andrej Karpathy 曾在公开演讲时说到:「纯视觉能够精准感知深度、速度、加速度信息,实现纯视觉是一件困难的事情,还需要大量数据。」
换句话说,特斯拉作业并不好抄,门槛和壁垒极高。

这主要体现在三个方面:
一是海量数据。
特斯拉的自动驾驶算法是业内公认能力最强、投入最大、研发最早的。截至目前,特斯拉 FSD 累积行驶里程已超 5 亿英里,Autopilot 使用里程已经超过 90 亿英里。
特斯拉的自动驾驶系统每天可以接收到车队回传的 1600 亿帧视频数据,支持神经网络训练。众所周知,数据积累取决于累计交付量和行驶里程,如此大的数据体量,也意味着需要投入大量的时间成本。
其次是自研芯片。
特斯拉自 2014 年开始自研芯片之路,2019 年发布了 FSD 自研芯片。
为了提升数据处理能力,为进一步的深度学习量身定制,2021 年 8 月,特斯拉发布了用于神经网络训练的自研芯片 D1,D1 芯片基于 7nm 工艺打造,算力可达 362TFLOPS。
D1 芯片具备较强的可扩展性,25 个芯片可组成一个计算模块,而 120 个计算模块可以组成外界熟知的「Dojo ExaPOD」超级计算机。
第三是围绕算法训练搭建的超算中心。
在特斯拉自建的大数据中心中,使用了 14,000 片 GPU 芯片,其中 10000 片用于 AI 训练的 H100,4000 片用于数据标注。
据了解,一片 H100 芯片官方售价 3.5 万美元,尽管在黑市被炒到 30~40 万元人民币,依然是「一片难求」。
特斯拉上线 H100 GPU 集群的同时,还激活了自研的超级计算机群组 Dojo ExaPOD,开启云端算力竞赛,以支持自动驾驶技术的更新迭代。
Dojo 于 2023 年 7 月开始生产部署,马斯克曾表示,到 2024 年,特斯拉还将向 Dojo 再投资 10 亿美元。预计到 2024 年 10 月,Dojo 算力会达到 100Exa-Flops。
从这个角度看,光是算法训练的芯片投入就十分惊人,达到数十亿元。
基于这样的数据,我们可以做一个简单的数学推算:
假设要开发一个特斯拉式纯视觉路线的高阶智能驾驶系统,这个方案总投入大约在 200 亿元。
试想一下,要压低这个成本需要多大规模的销量?
——当汽车销量到 2000 万辆时,每辆车的自动驾驶成本可以降到 1000 元。
——而当汽车销量只有几十万、上百万辆时,这笔投入该如何摊销?
当前,特斯拉累计销量超过 400 万辆,其所释放的规模效应让友商们难以企及。因此,特斯拉选择视觉路线,不只是「算法能力强」,更是建立在巨大的保有量、车载芯片自研、数据回环和自动化标注、自建超算中心训练模型等一系列能力之上的综合实力。
02 占用网络不是「万能钥匙」 激光雷达仍是「最佳助攻」
2016 年 1 月 20 日,在辅助驾驶状态下,一辆特斯拉撞上了一堵静止的水泥隔离墙上。这是特斯拉首起「自动驾驶」事故。
当时,对特斯拉的唱衰之声不绝于耳。但经过 7 年探索,特斯拉如今在自动驾驶领域一骑绝尘。当特斯拉跑通自动驾驶之后,其他车企开始转向了「大模型」路线,沿着特斯拉从 BEV 向占用网络迭代之路进化。
不过,即便不惜成本投入堆起来的「占用网络」,对于通用障碍物的识别仍然无法做到「天衣无缝」。

占用网络,是一套基于神经网络的算法,是在时序对齐、多帧数据融合下构建的 4D 网络。
「因为拼接了很多算法,涉及到多帧融合。不可避免就会有一定程度的延时。」对于国内车企来说,在车端有限的算力之下,如何兼顾「高精度」和「低延时」存在诸多考验。
更重要的是,占用网络技术会因视觉缺失 3D 信息而导致漏检、误检。
为了视觉算法输出结果比较准确,需要源源不断的数据输入和迭代以提高精准度。
在车辆覆盖没有到一定规模前,尚且无法获得更多数据——这正是不少车企现阶段对「去掉激光雷达」保持谨慎,而选择「摄像头+激光雷达」融合感知路线的原因。
相比于算法,激光雷达具备「硬件本能」,不需要经过大量复杂的计算和假设,以及数据训练就可以得到纯视觉方案需要的某些数值。
相比纯视觉方案,激光雷达能够应对不易处理的 corner case(边缘场景),弥补摄像头可能出现的误判。

在融合方案中,激光雷达存在多个公认的核心优势:
一是「抗干扰」,不惧夜间环境。
据 MIT 团队 2022 年的研究结果表明,配备了激光雷达的融合方法将夜间的感知精度提高 3 倍。
二是「真三维」,精度更高。
激光雷达基于三维坐标,能精确到厘米级别为算法提供地面和物体的相对位置。地面上的高低不平的路况,一些低矮物体,激光雷达也能够捕捉到。

三是「高置信度」,识别物体数量更多。
纯视觉方案会建立覆盖常见「道路物体」(机动车、行人、两轮车、锥桶、水马、路面、树木等)的白名单。白名单之外,可能「视而不见」。
通过激光雷达直接获取实时 3D 数据后,车辆可以直接判断障碍物是否存在,为占用网络提供真值输入,在融合方案里作有力补充,提升系统安全性。

此外,激光雷达的反应速度更快。在中国城市内存在复杂路况,比如闹市区里车辆突然的加塞、变道等,激光雷达相比摄像头的反应速度更快,能够准确判断对方移动速度。
值得一提的是,在最近行业大热的话题「如何降低 AEB 的误触发率」上,激光雷达也可以帮助避免一些常见的安全隐患。
施叶舟表示,「AEB 的误触发,背后的本质原因是感知精度不够高。在激光雷达加持下,周围感知精度的提升,误触发可以大大减少」。以搭载激光雷达的理想 L9 Max 为例,采用多传感器融合方案之后,每 10 万公里的误触发次数远远低于行业均值。
综合来看,占用网络技术不是一个解锁通用障碍物识别的万能钥匙,而激光雷达在提升安全性的过程中,有着举足轻重的作用。
03 激光雷达融合方案 高阶智能驾驶落地的「助跑器」
城市 NOA 正在迎来一个高光时刻——问界新 M7 累计大定已超过 8 万台,其中超过 60% 用户选择了智驾版(激光雷达版);小鹏新 G9 激光雷达版本选配比例高达 80%。
在此之前,一款车的智能驾驶搭载率只能达到 20%~30% 左右。问界和小鹏新车的智能驾驶选配率,远远超过了行业预期。
城市 NOA 迅速落地的背后,给广大的消费者体验带来根本变化是最主要的驱动力。
要实现更大范围的自动驾驶的覆盖,要切入真正的高频和刚需场景,先走到距离用户最近的地方。
数据显示,汽车平均有 71% 的里程是在城市道路行驶,对应时间占车主总驾车时长的 90%。而华为和小鹏得以更快落地城市 NOA,激光雷达功不可没。

智能驾驶权威测评机构 nuScences 的数据显示:
截止 2023 年上半年,纯视觉方案(摄像头)和融合方案(激光雷达+摄像头)对目标物追踪准确度(AMOTA)上仍有较大差距:二者相差接近 20 个百分点(56% VS. 75%)。
预计到 2025 年,纯视觉方案准确度的均值会达到 70%~71%。这一数字相比配备激光雷达的融合方案在 22 年的准确度落后了 3 年时间。
换个角度来看,激光雷达融合方案可以让高阶智能驾驶落地时间缩短 3 年。

轻舟智航产品负责人许诺直言,现阶段单纯依靠视觉方案,很难应对中国城市道路中的各类 Corner Case。「激光雷达,是以投入换时间,加速城市 NOA 落地的捷径。」
「当你做视觉方案时,系统遇到未知或者通用障碍物识别时,激光雷达方案的优势是突出的。像路上突然掉下来的物体,例如纸箱、木箱等,通过激光雷达能够感应到。而且激光雷达可以告诉你,前面有障碍物,也会告诉你做分类处理。」许诺说道。
由此看来,激光雷达不仅是智能汽车里的「隐形安全气囊」,更是辅助车企量产落地城市 NOA 的捷径。
在国内市场,蔚来、理想、小鹏、仰望、智己、极氪、问界、阿维塔等汽品牌,在已经量产或即将上市的车型中,都配备了激光雷达。
在海外,布局 L3 智能驾驶功能的头部车企也都配备了激光雷达,包括已经获得 L3 监管批准的奔驰,以及正在布局的宝马、沃尔沃等。
下一步,高阶辅助驾驶若要向大众市场持续渗透,系统成本有望继续下探。
施叶舟表示,禾赛正在通过核心零部件芯片化等技术降本手段,以及放大规模效应的优势,为城市 NOA 持续落地服务。目前,禾赛已将激光雷达的价格从几年前的几十万元,降到了现在的几千元,做到了十倍以下。
到那时,激光雷达的高成本,或许也不再是阻碍其大规模上车的门槛。
车企是否都要走特斯拉的纯视觉方案,最终要量力而为。而从现阶段来看,激光雷达不仅可以成为城市 NOA 落地的「助跑器」,在未来也能够继续发挥其独特价值,做自动驾驶领域的「最强助攻」。
# 智能驾驶~重感知,轻地图
2023年智驾领域的热门话题是“重感知,轻地图”方案,也称“无图”方案(无图指不依赖离线高精地图),这种方案降低了对传统离线建图和在线高精定位技术的需求,让包括我自己在内的很多SLAM技术从业者担心自己要被“卷没了”,对智驾的技术发展是否仍然长期需要SLAM技术产生了疑惑。本文是对这个问题的调研和思考。
一 从智驾系统框架说起
智驾系统分为规划控制,地图定位和实时感知三个核心模块,其中感知提供实时车辆周围的动静态信息,为规划控制的行为决策和执行动作的推演提供局部环境的实时约束。如果只是让车辆在局部空间内自主移动,并假设在线感知能力足够强,是不需要地图定位模块的,但是在智驾系统目前经典的技术栈中,定位和建图却是非常重要的一环。理解清楚规划控制对地图定位的需求,是分析重感知轻地图下SLAM技术需求的“变”与“不变”的一把钥匙。

智驾系统框架[1]
二 规控对地图和定位的需求
按照规划控制经典的子模块划分,本质上可以理解为一个仿生系统,它类比了人类开车的整个的行为过程。一个典型的驾驶行为如下:
- 早上你要开车去公司上班,上车之后的第一个动作是呼叫车载语音助手导航到xxx公司,语音助手唤起车载的高德地图,提供一条或者多条导航路线显示给你做选择。(全局路径规划)
- 当你沿着导航路线朝着公司方向行进时,语音助手提示你前方路口需要左转,你发现前方只有最左侧车道是可以左转的,并且左侧前方有车,同时前方路口时红灯,你决定提前变换到左侧车道,并控制油门和前车保持一定距离,在路口提前决定刹车以等待红绿灯,当左转绿灯亮起,你知道可以左转了。这里的变道,跟车,左转在规划控制中被定义为行为决策
- 在上述变道的切换中,你无意识地朝向左侧车道前方某个大概位置,根据自车和那个大概位置的距离和方位,不断地调整油门和左打方向盘的角度,完成变道的决策。画出一条丝滑的切换轨迹。在这个过程中,我们的大脑其实假象了一条从当前自车位置到左侧目标位置的一条局部轨迹,并不断的动态调整车辆位置让其沿着这条局部轨迹驶向目标点。在规控中,将一条局部轨迹的跟踪问题定义为局部规划或者运动规划模块。局部规划模块给出一系列动作期望的油门,转向等控制指令,运动控制器则负责实施期望的油门和转向等指令。

规控系统框架[1]
为了实现上述过程的自动驾驶,产生了规划控制模块对地图定位的需求。其中,全局路径规划仅需要规格稍低的SD地图(即高德地图等手机导航级别的地图)和米级精度的全局定位,以实现从起点(由全局定位模块提供)到终点(在SD地图里指定)的全局路径规划。对于行为决策和局部规划模块,需要局部环境更为丰富和精确的道路信息,比如道路的拓扑结构,停止线,道路曲率等。如果感知能力足够强,是可以直接在线提供这些信息,但是早期感知能力有限时,则通过额外高精度设备离线采集环境数据,离线计算并保存这些信息的方式提供,即离线高精地图(HDMap)。
规控对离线高精地图的使用,产生了对高精地图定位的需求,即矢量地图定位。高精地图构建了一个由各种道路元素组成的虚拟世界,规控其实是在这个虚拟的世界进行决策控制。而矢量地图定位是实现虚拟地图世界和真实世界的映射,以保证规控在地图上的行为动作结果和实际世界一一对应。具体来说,矢量地图定位通过感知提供的单帧语义矢量(真实世界)如车道线,路灯杆等,结合GNSS组合导航提供的定位初值,和离线高精地图中的对应语义矢量进行匹配。由此可见,离线高精地图和矢量定位是一对锁和钥匙,两者依赖对方的存在才有意义。

规控各个子模块对地图和定位的需求[1]
三 重感知轻地图的技术趋势
高精地图的不足
以上分析可以发现,离线高精地图是对实时感知能力不足的一种弥补。离线高精地图的主要问题是鲜度变化导致的维护成本。当道路结构发生变化时,高精地图需要持续更新,目前智驾一般把场景分为高速,城区和低速三类。高速是智驾落地的第一个场景,它总里程相对有限(全国高速里程数30多万公里[5]),且道路维护较好,道路变更发生比例较小,通过一两家图商为所有业务方提供离线高精度地图的方式,更新和维护成本基本可控。
但是随着高速智驾落地,大家目光转向城区的智驾时,鲜度和采集成本问题变得突出,导致高速场景依赖离线高精地图实现高阶智驾的方案基本不可行。首先城区的道路里程相对于高速场景里程有数量级的增加(全国城区道路总里程1000多万公里[5]),且道路信息变更频繁。而随着传感器和感知能力的提升,通过实时感知方式生成道路信息的“重感知,轻地图”方案成为各家追求的避开高精地图实现高阶智驾的实现方式。
图商和部分车企通过运营车辆采集进行离线高精地图更新和扩场的方式,还存在一个明显的问题是它造成建图能力和单机能力的脱离,限制了汽车规模化制造可以平摊各项成本的优势。建图和定位统一为单机能力的一部分,是未来机器人能力研发的趋势,“重感知,轻地图”符合这个趋势。让建图能力成为单机能力的一部分,实现的路径是众包建图,或者一些特殊场景下适用的单机单用的车端建图。众包建图可以实现低成本的高精地图更新,也是充分发挥主机厂数据闭环优势的场景之一,在感知能力不能cover住全部城区场景(如复杂或异形道路拓扑结构等场景),且传统运营采集成本高到无法负担的情况下,会发挥非常核心的作用。众包建图的核心支撑是数据闭环,数据闭环能力对于众包建图甚至是比建图算法本身更重要的基础能力,同时目前高阶智驾硬件在各家新车型的标配,也让众包建图不再是无米之炊的幻想。众包建图让每辆汽车都成为了数据源,从这个角度理解,车企尤其是新势力车企,是城区高阶智驾真正的主角。图商除了偶尔站出来喊两句世道变了,不再会有太大的作为。

蔚来NT2车型 高阶智驾硬件
高精地图除了以上问题外,在出海销售时也存在很大问题,由于法律法规的限制,要么只能适配国外本土的高精地图;要么像一些非洲国家,短期内不太可能有高精地图,导致智驾功能无法使用。所以,特斯拉在很早之前就坚定的走不依赖离线高精地图的方案。马斯克牛逼。
实时Local Map的生成
重感知轻地图最核心的逻辑,简单来说就是在感知能力cover住的场景,把规控制需要高精道路元素,由加载离线高精地图的方式改变为通过在线感知能力生成,进而避免了鲜度和规模化的问题。实时感知提供高精地图元素的功能通过在线构建局部环境地图(LocalMap)的方式实现。而智驾的整体架构从规控角度并没有发生本质变化,行为决策和局部规划模块需要的道路要素的精度和规格没有太大变化,只是从离线加载演变为实时生成。
这里的LocalMap存在两种技术方案,一种是偏传统的在线将单帧感知结果进行局部语义矢量建图,并进行道路拓扑推理,技术栈上仍然依赖传统的SLAM建图方法。一种则是端到端直接生成局部地图,在这方面,清华大学的赵行老师做了一些很不错的开创性工作[8]。
视频发不了...
HDMAPNet 端到端生成的LocalMap [9]
而实时感知cover不住的复杂场景,则通过众包方式构建离线的高精地图,在地图规模上,相对于全量构建全国城区的高精地图,里程数降低了很多。而这些城区复杂场景的离线高精地图,除了在智驾系统中弥补感知能力的不足,也成为感知离线训练的真值标注数据,进一步反哺提升感知的模型能力,实现数据驱动的感知能力的闭环迭代。
以上,是笔者理解的“重感知,轻地图”方案。市场上目前也出现了一些“记忆行车”类产品功能,如大疆车载的“记忆行车”,理想汽车的“城市通勤NOA”,小鹏的“AI代驾”。以目前方案公开度较高的理想的“通勤NOA”为例,它使用深度学习特征先验替代传统的地图元素[10],但本质上仍然是一种离线地图,这种地图既丢失了离线高精地图的规范性和可解释性,又没有根本上避免传统离线高精地图的缺陷。笔者认为只是一种在当前无图能力或算力不足情况下,配合商业宣传的短暂形态,不会长久存在。

想汽车的NMP先验地图[10]
四 SLAM有长期需求的业务
根据以上分析,笔者分析存在以下3类业务,即使在重感知轻地图的技术趋势下,对经典SLAM技术仍然会有长久需求。

智驾中对经典SLAM方法存在长久需求的业务
需求场景1: 多传感器的离线和在线标定
多传感器内外参标定是机器人和智能硬件一直存在的需求,在智驾上也是,主要分为出厂的离线标定和出厂后的在线标定。多传感器的内外参标定,可以看成是建图定位的镜像问题,他们共用相似的观测方程,只是定义的状态量发生了镜像,建图和定位是假设内外参已知的情况下,估计各个时刻的位姿,而内外参标定则是在假设位姿已知的情况下,估计系统的内外参。
出厂的离线标定,借助高精度的辅助设备,可以获取精度较高的出厂参数。但是车辆出厂之后,由于碰撞等导致的结构形变,传感器的老化等,会造成车辆的内外参发生动态变化,使得出厂参数不再适用,因此需要在线标定系统对车辆的内外参进行实时或者半实时的估计。

离线标定[11]
在线标定和离线标定最大的区别是没有高精度的位姿真值估计系统作为参考,而是借助车端的定位和感知系统的中间结果,构建观测约束,实现参数的估计。
在很多经典的SLAM论文中,在线标定的实现方式是把内外参作为状态向量的子状态之一,和位姿等状态进行联合优化。但在现实工程系统中,其实并不是一个很好的方式。理由有以下几点:
- 首先,内外参的估计一般依赖较强的观测约束和运动激励,这往往意味着较大算力的需求,这和定位等实时状态估计系统要朝着低延迟的需求相违背。而且,由于车辆很多时候是二维平面的匀速运动,导致系统部分状态处于欠激励的不可观状态,使得内外参的在线估计无法收敛。
- 内外参是低时变的,保证一个天级或周级的更新就基本满足需求,让这样一个低时变的参数以几十毫秒级别随着定位系统进行状态估计和更新,是一种浪费算力的非必要行为。
- 内外参的估计是非实时的需求,完全可以在车辆停泊等空闲状态时再启动,实现算力的分时复用。一种是让在线标定需求每时每刻都占据定位系统0.3核的算力,一种是在车辆闲置时,让在线标定系统占据系统1个核的算力,显然后者更容易实现更高精度的结果。
以上,在线标定更合理的方式是做成一个独立的非实时或半实时模块,它不断的收集运动激励较好情况下的定位和感知系统的数据片段,在车辆空闲时,进行一次算力较重的联合优化,保证内外参估计的精度。

在线标定[11]
需求场景2: 低速无GNSS场景的定位建图
无GNSS的低速场景,主要是指地下停车场环境,它和高速以及城区环境相比,存在一些特殊性。回顾上述提到的无图方案,它并没有脱离对米级全局定位和SD地图进行全局路径规划的需求。但是在地下停车场,由于没有GNSS提供全局定位,就需要另外一种替代品,为全局路径规划提供全局定位能力,目前主流的替代方案则是通过SLAM方式构建定位地图,使用地图定位的方式提供全局定位。同时,很多非公共商场的地下停车场,数量庞大且图商无法提供SD地图,也需要以众包建图的方式构建SD地图。这些都是图商没有先发优势,而主机厂能做而且可以做的更好的地方。
下面的视频,是华为在阿维塔上线的AVP代客泊车功能,通过一次性的单车单用的车端建图,构建从地库入口到车主停车位的矢量地图。地图构建完成之后,则可以实现自动将车辆开到指定或者沿途停车位的功能。产品体验上,基本达到了让用户愿意买单的程度。这是一个令人兴奋的事情,它已经证明了在AVP场景,智驾大有可为,SLAM技术大有可为。
以下是我整理的低速无GNSS场景下的定位建图技术栈,它分为车端和云端两部分。是一个非常典型的传统SLAM技术栈发挥作用的场景。在具体的技术方案的实施上,会有2个主要分歧,一个是建图是采用单车单用的单次车端建图还是选择多车众包的云端聚合,另外就是定位方案是采用矢量地图定位还是基于传统几何特征的特征地图定位。在这里介绍下自己的一些思考。

低速无GNSS场景建图定位技术栈
首先关于地图形式,单次车端建图的形态,华为和一些记忆泊车类产品采用的是类似方式,这种方式优点是所见即所得,可以比较快速的获取一张停车场局部的地图,缺点是没有充分利用车辆间共享的地图信息,这种方法适合有长期固定车位的小区停车场。多车众包的云端聚合的地图形态,实现方式是车端单次几何和矢量建图结果,在云端进行多车的地图聚合,是一种众包形式的建图方法,优点是可以生成一张范围更完整的地图,地图质量更有保障。缺点是依赖数据闭环能力,链路较长,地图做不到所见即所得,适合没有固定车位但范围较大的公共停车场,比商场和办公场景的地下停车场。同时,建图方案也需要考虑数据复用的问题,以上两种方式都有可以实现的路径,前者可以在车端保存一份原始的建图数据,在建图算法更新时,重新“训练”更新一张新地图,后者则可以通过回传更加原始形态的数据来实现。
在定位方案上,矢量地图定位是目前主流的一种定位方案,优点是地图规模和算力消耗都较小,缺点是依赖感知,新旧停车场内部环境差异较大,感知存在泛化性问题,导致部分停车场定位退化。另外一种方式是选择SLAM中的几何特征地图,又细分为基于视觉几何特征和基于激光几何特征的地图,几何特征摆脱了对感知泛化性的依赖,但主流观点是基于几何特征的地图规模和算力占用会明显高于矢量定位。且两者都存在通用性的问题,视觉特征地图存在依赖镜头模型,导致相机镜头老化或型号变化导致镜头畸变产生较大差异时,特征匹配效果退化的问题。激光特征地图存在依赖车辆需要配置激光雷达,且地图形态在无激光雷达车型上较难复用的问题。具体采用何种方式,是见仁见智的选择。笔者认为如果能够很好地解决无激光雷达车型复用激光特征地图的问题,基于激光特征地图的定位方式在泛化性上和稳定性上可以做到比矢量定位更优,且算力和地图规模和矢量定位相似的水平。
地下停车场尤其是大型停车场和多层停车场,对SLAM的建图和定位都有比较大的挑战,地下停车场无GNSS信号,建图更加依赖相对里程计和回环匹配的效果,且因为没有GNSS的全局约束,建图轨迹存在局部的扭曲变形,导致局部环境的失真。在相对里程计精度有限存在Drift的情况下,对初值和视角偏差较大的回环能力有较大的依赖。同时在多层停车场,多层的高度一致性也是一个非常大的挑战。此外,由于地库视野遮挡比室外严重,在内部路不可能完全遍历一遍的情况下,导致地图的局部缺失。
地库地图的局部的缺失和质量退化问题,是定位在系统设计上需要消化的问题,这就给地库的定位提出了挑战。但地库定位的挑战远不止于此,由于地库内部没有GNSS信号,所以目前上线的产品中,多是需要先从室外启动,以借助GNSS组合导航获取定位初值;而地库内部的定位初始化,以及定位失败下的初始化,在车端算力有限的情况下要做出很好的效果,是一个非常有挑战性的事情。对于多层停车场,也存在多层的定位高度稳定性问题,是影响定位稳定性的关键因素,高度的drift会导致地图匹配效果的急剧退化和错楼层匹配。
此外,部分图商也在尝试提供地下停车场地图,但和高速高精地图不同的是,室内停车场地图,在定位图层上并未完全统一,各家的定位方式都不太相同,也依赖各家车厂的传感器方案,目前较难统一。且车厂有众包优势,停车场场景下的定位和建图的任务,笔者认为短期内还是个家自研为主。

百度手机地图提供的停车场车位地图
需求场景3: 4DGT 感知标注
4DGT是2021年Tesla AI Day首次提出的一种新的感知数据标注方法,与传统的直接在2D 图片上进行标注不同,它借助SLAM技术为核心的三位重建方法,构建出2D感知语义的精确3D模型,然后将3D模型投影到图片上,实现低成本高效率的标注。4DGT服务于位感知提供真值训练数据,是目前SLAM定位建图技术应用的非常好的一个业务场景。同时,针对于不同的感知任务,4DGT技术也有一些新的发展,具体信息可以参考前段时间地平线隋伟大哥的一个报告[14],对这里涉及的技术栈和细节介绍的已经非常详细,这里不做赘述。

4D GT Pipeline[13,14]
The Last Choice:打不过就加入
虽然技术手段不断地更新迭代,但帮助机器人理解3D世界的目标没有发生变化,保持一颗迎接变化的心态会给自己带来更开阔的思路。除了继续深耕经典SLAM技术,目前行业也涌现出一些新的基于Learning 3D技术的方向,如Occupancy Network,3D Objects Detection,以及NeRF,这些方向非常依赖扎实的状态估计等传统SLAM技术基础,是SLAM从业者可以发挥优势的技术方向。

earning 3D的技术方向[15,16,17,18]
智驾之外: 通用机器人
令人兴奋的是,2023年也是通用机器人行业新机会涌现的一年。在通用机器人潜在应用场景,智驾上的大部分技术栈,从底层芯片,传感器,到软件层面的感知,地图定位和规划控制,都可以迁移进来,这给相关智驾从业者更多的选择,未来大有可为。

Tesla Optimus 机器人,使用和Tesla电动汽车一样的Occupancy Network[19]
五 典型公司

# CoBEVFlow
协同感知技术能够有效解决单体感知中存在的障碍物遮挡、视角受限、以及远距离感知能力弱等问题。然而实际场景中存在着网络用塞、延迟等问题,协同感知受此影响,性能会严重下降,甚至低于单体感知效果。NeurIPS 2023的最新研究文章 《Asynchrony-Robust Collaborative Perception via Bird’s Eye View Flow》将协同信息时间戳不对齐的协同感知任务定义为时序异步的协同感知(Asynchrony Collaborative Perception),来自上海交通大学、南加州大学、和上海人工智能实验室的研究者们在本文中提出了CoBEVFlow:基于鸟瞰图流(BEV Flow)的时序异步鲁棒的协同感知系统。实验效果表明,CoBEVFlow能有效缓解时序异步带来的影响。
- 论文链接:https://arxiv.org/abs/2309.16940
- 代码链接:https://github.com/MediaBrain-SJTU/CoBEVFlow
- 项目主页:https://sizhewei.github.io/projects/cobevflow/
CoBEVFlow的出发点
近年来,自动驾驶领域在学术界和工业界都受到了极大的关注。但真实世界中道路情况复杂多变,且存在着行人、非机动车、不遵守交通规则的道路参与者甚至少数情况下会出现动物等情况,这些特殊情况都会给自动驾驶技术的应用带来极大挑战。对于在单车部署传感器(如相机、激光雷达、毫米波雷达等),基于单车传感器的目标检测的方法称为单体感知。尽管单体感知在目前的多数情况下表现尚可,但这种感知方式存在固有的局限性。单体感知依赖自身的传感器,其感知能力受限于传感器的视角、有效距离和精度。例如,当传感器遭受遮挡,视角受限时,感知能力就会大幅下降,为智能体后续的认知和决策带来安全隐患。此外,对于远处的物体,激光雷达产生的点云过于稀疏,无法提供有效的位置信息,导致感知系统很难对远距离的环境进行感知。下图就是一个真实场景中由于视线遮挡,对于人类驾驶员也非常头痛的“鬼探头”问题。

图 1. 视线遮挡造成的“鬼探头”问题令人类驾驶员也非常头痛!
多智能体之间的协同感知为单体感知存在的这些问题提供了解决方案。随着通信技术的发展,多个智能体之间可以利用通信共享彼此的信息,每个智能体可以结合自身传感器信息与其他智能体的信息,对周围环境进行感知。通过智能体之间的协作,每个智能体可以获取自身视野盲区与可视距离以外的信息,有助于提升每个智能体的感知以及决策能力。此外,协同感知也能减少智能体对于高精度长距离传感器的依赖,通过多个使用低精度、低成本传感器的智能体相互协作,达到甚至超过单个装配高精度传感器的感知能力。在现实世界中,由于通信延迟、拥塞、中断、时钟错位、以及采样频率不一致等等问题,智能体接收到的协作信息所带有的时间戳不一致是不可避免的。如图所示,蓝色车辆代表元智能体(ego agent),而另外两辆车在连续时间轴上的不同时刻传递协作信息。在这种情况下,元智能体收集到的信息发生在不对齐的时间戳上。说到这里还是v2x发展的慢了 要不不会有这种问题把 我想

图 2. 异步通信示意图。来自不同智能体的协作信息带有的时间戳是连续时间轴上的任意值。
这个问题会导致多智能体融合过程中信息不匹配——来自不同智能体的协作信息中对同一个移动目标的位置信息是不同的,从而导致协同感知得到的感知结果甚至比单个智能体感知结果更差。如果忽视这个问题,仍然使用传统的协作感知方法,得到的协作感知结果如图所示。

图 3. 协作信息时间戳不一致对协作感知造成的影响。红色表示感知结果,绿色表示真实值。左图为协作不一致的情况下,不使用CoBEVFlow的结果,右图为经过CoBEVFlow处理过的结果。
红色框表示检测结果,绿色框表示真实值,“错误的”协作信息会干扰元智能体的单体感知信息,导致结果甚至比单体感知结果。这也就意味着时间戳不对齐问题导致协作失去了意义。
为此,研究者们定义了异步协作感知(Asynchrony Co-Perception)任务。其中异步表示来自参与协作的智能体所传递的协作信息带有的时间戳不一致,而且来自同一个智能体的连续两帧信息之间的时间间隔是不固定的。基于这个问题,该文提出了基于鸟瞰流图(BEV Flow)的时序异步鲁棒的协同感知系统:CoBEVFlow。
CoBEVFlow的问题定义
研究者们首先对异步协同感知任务给出了数学定义:

CoBEVFlow的方法介绍
异步协作感知的本质问题是,来自多个智能体的协作信息可能给同一个移动目标记录不同时刻的位置信息。因此研究者们提出的CoBEVFlow用两个核心思路来解决这个问题:
- 生成一个感兴趣区域(ROI)集,后续只针对这些集合中的特征进行操作;
- 捕捉历史帧中这些感兴趣区域的运动趋势,根据运动趋势将对应位置的特征重新对齐到当前时刻的位置。
通过这两个思想,避免了直接修改特征,并保持了背景特征,所以CoBEVFlow不会引入不必要的噪声。
CoBEVFlow的总体框架

信息打包模块(Message Packing)
生成BEV特征图上的ROI集合,然后发送这些集合以及对应的稀疏特征。其中ROI生成器采用的网络架构和解码器一致,但是网络参数并不需要保持一致。这样做的目的是,让ROI生成器学习到更多关于单体感知的特征分布。
信息融合模块(Message Fusion)
捕捉这些ROI的运动趋势,叫做BEV Flow Map,利用BEV Flow来将异步的信息对齐到当前时刻,再进行融合。BEVFlow的生成包括两个关键步骤:
- 相邻时间戳的ROI匹配;
- BEVFlow估计。

图 5. BEV Flow Map生成包括:ROI匹配和Flow生成过程。
相邻帧的ROI匹配:目的是匹配同一智能体在连续两个时间戳上发送的信息中的感兴趣区域(ROI)。匹配上的ROI本质上就是在不同时间戳下的同一个目标。匹配包含三个过程:成本矩阵构建、贪婪匹配和后处理。首先构建成本矩阵,其中每个值表示两个时间戳下两个ROI之间的匹配成本,矩阵中的每个值是基于角度和距离计算的。接着使用贪婪匹配策略来搜索配对的ROI。最后,后处理中通过删除匹配对中过大的值所代表的配对来避免无效匹配。

图 6. BEV Flow 估计示意图。
BEV Flow估计:检索每个ROI在一系列不规则时间戳下的历史位置。这个模块是一个基于注意力机制的模块,使用这些不规则的轨迹段来预测元智能体的当前时间戳下这些ROI的位置和方向,并生成相应的BEV Flow。与使用循环神经网络处理常规通信延迟的方法SyncNet(ECCV'22) 相比,生成的BEV Flow具有两个优点:i)它通过基于注意力机制的估计和适当的时间编码来处理不规则的异步情况;ii)它基于运动趋势的来移动特征,避免了重新生成整个特征图。
实验效果
为了验证CoBEVFlow的效果,研究者们在两个数据集上进行了实验,分别是IRV2V和DAIR-V2X。其中IRV2V是本文提出的首个异步协作感知数据集,其包含不同程度的时间异步性,而DAIR-V2X是真实数据集。实验的任务是基于点云的目标检测。使用交并比(Intersection-over-Union,IoU)阈值为 0.50 和 0.70 对检测性能进行评估,采用平均精度(Average Precision,AP)作为评价指标。
CoBEVFlow (红实线) 在异步情况下显著鲁棒

图 7. 在时间间隔期望值从 0 到 500 毫秒的情况下,CoBEVFlow 与其他基准方法的性能进行了比较。CoBEVFlow 在两个数据集上表现优于所有基准方法,并展现了在任何异步水平下的出色鲁棒性。
研究者们对比了现有的协同感知SOTA方法与CoBEVFlow在不同的异步程度下的感知结果。如图,红色虚线表示没有协作的单体检测,红色实线表示CoBEVFlow。所有方法均使用基于 PointPillars 的特征编码器。为了模拟时间异步性,研究者们使用二项分布对接收到的消息的帧间隔进行采样,以获取随机的不规则时间间隔。图中展示了在 IRV2V 和 DAIR-V2X 上,所提出的 CoBEVFlow 和SOTA方法在不同程度时间异步性下的检测性能(AP@IoU=0.50/0.70)比较,其中 x 轴是最新接收信息的延迟时间间隔和相邻帧之间的间隔的期望值,y 轴是检测结果。需要注意的是,当 x 轴为 0 时,表示为标准的协作感知没有任何异步性。可以看出:i)在所有异步程度下, CoBEVFlow 在模拟数据集(IRV2V)和真实世界数据集(DAIR-V2X)中均实现了最佳性能。在 IRV2V 数据集上,在 300ms期望间隔下,CoBEVFlow 在 AP@0.50 和 AP@0.70 方面分别比最好的SOTA方法提高了 23.3% 和 35.3%。类似地,在 500ms 间隔期望下,分别实现了 30.3% 和 28.2% 的提升。在 DAIR-V2X 数据集上,CoBEVFlow 依旧效果领先。ii)CoBEVFlow 表现出了显著的异步鲁棒性。如图中的红线所示,在不同的异步情况下,CoBEVFlow 在 IRV2V 数据集上仅出现 4.94% 和 14.0% 的 AP@0.50 和 AP@0.70 下降。这些结果远超过了单一目标检测的性能,甚至在极端的异步情况下也是如此。

图 8. CoBEVFlow与SOTA方法在IRV2V数据集上的可视化对比,红色是预测结果,绿色是真实值。

图 9. CoBEVFlow与SOTA方法在DAIR-V2X 数据集上的可视化对比。红色是预测结果,绿色是真实值。
Asynchronous Co-Perception (135) With CoBEVFlow (246)
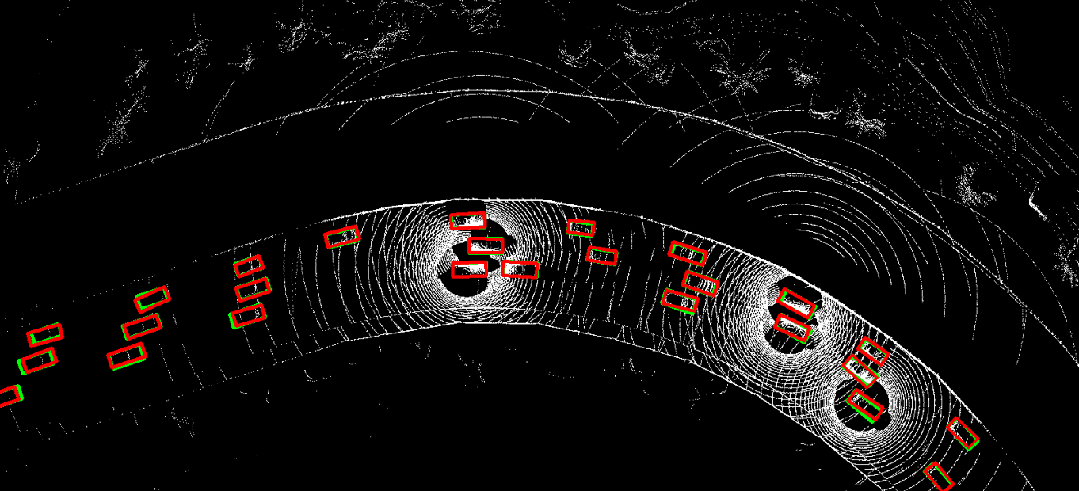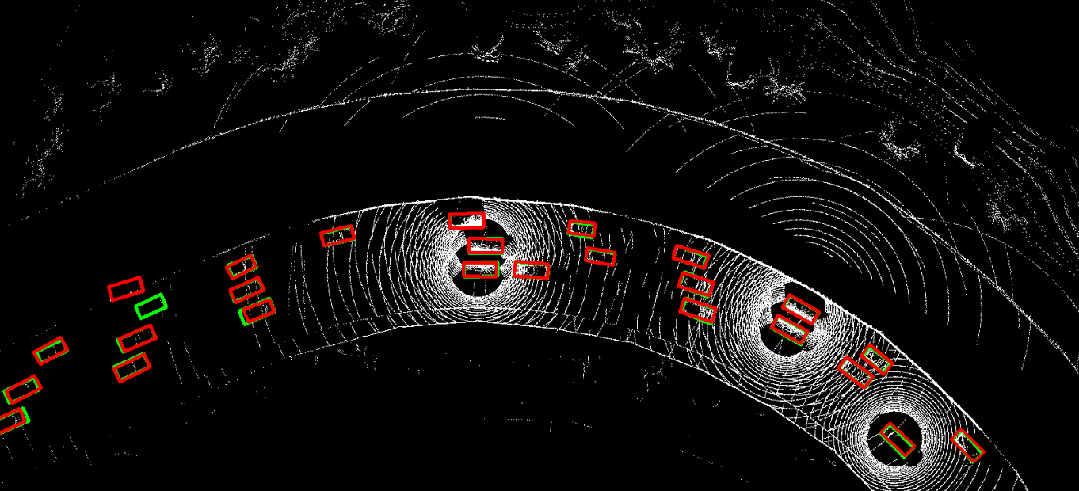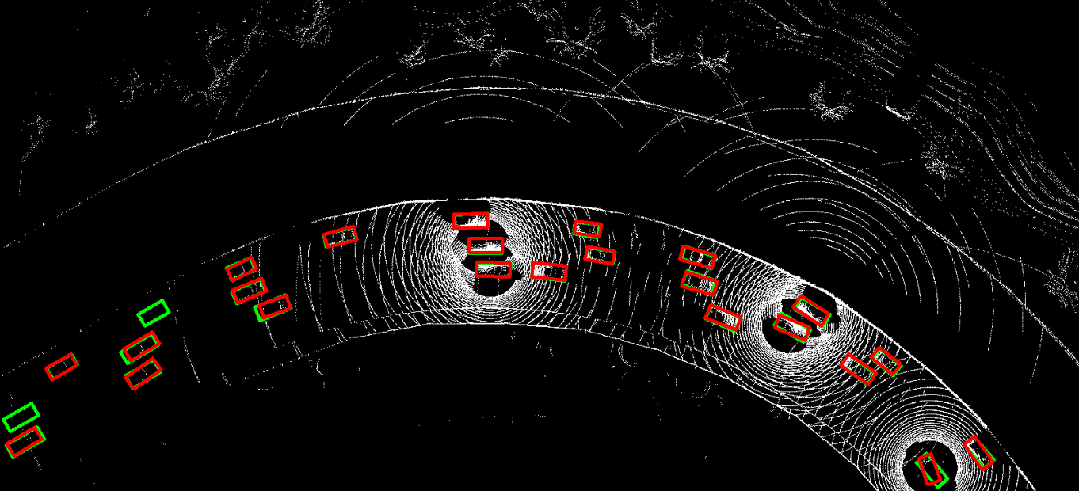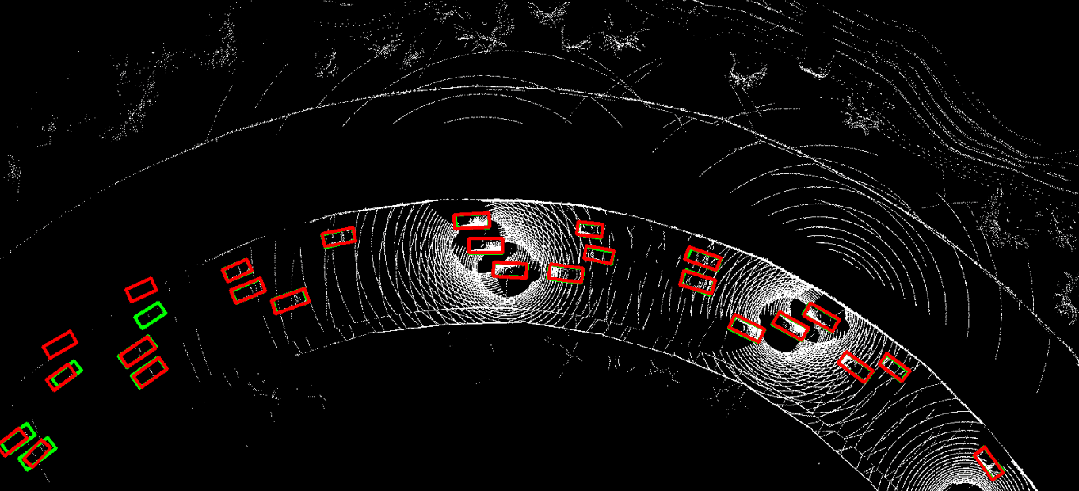

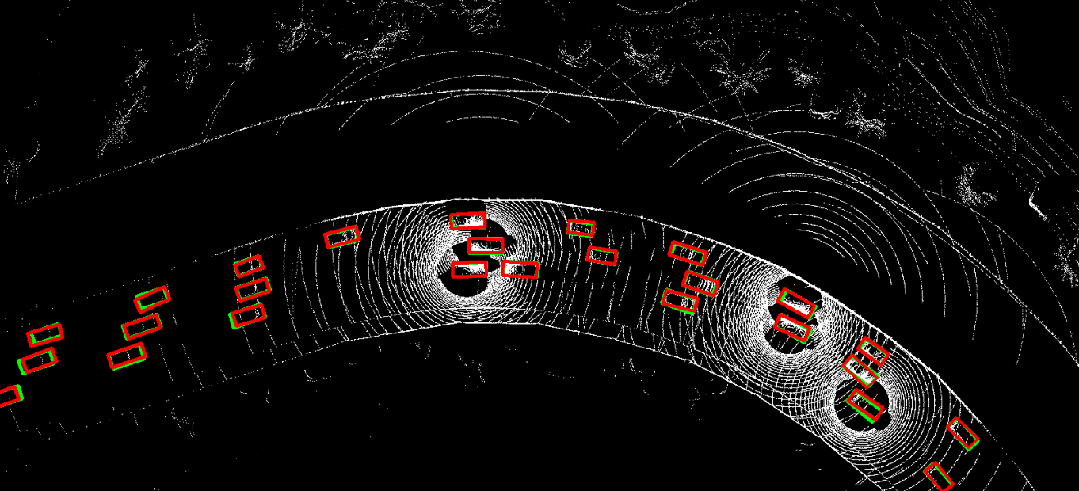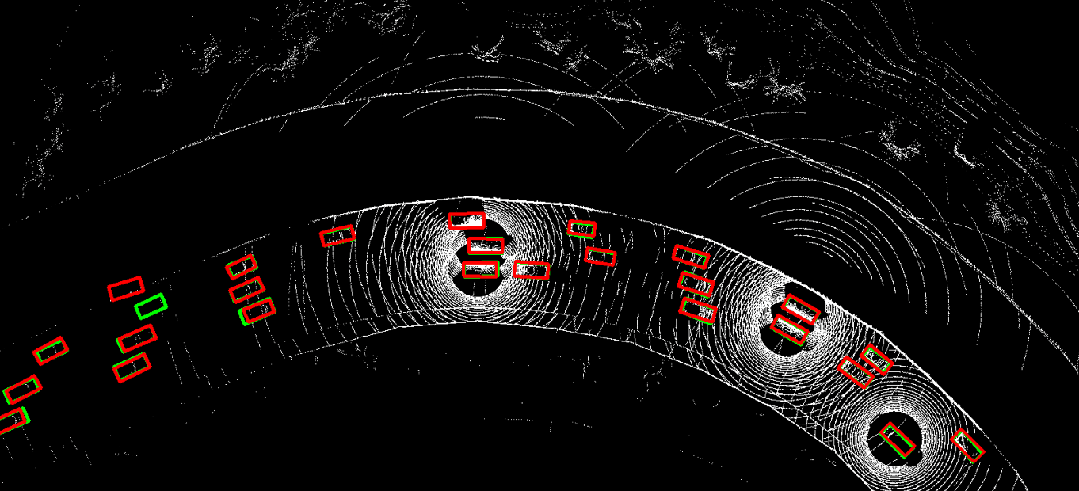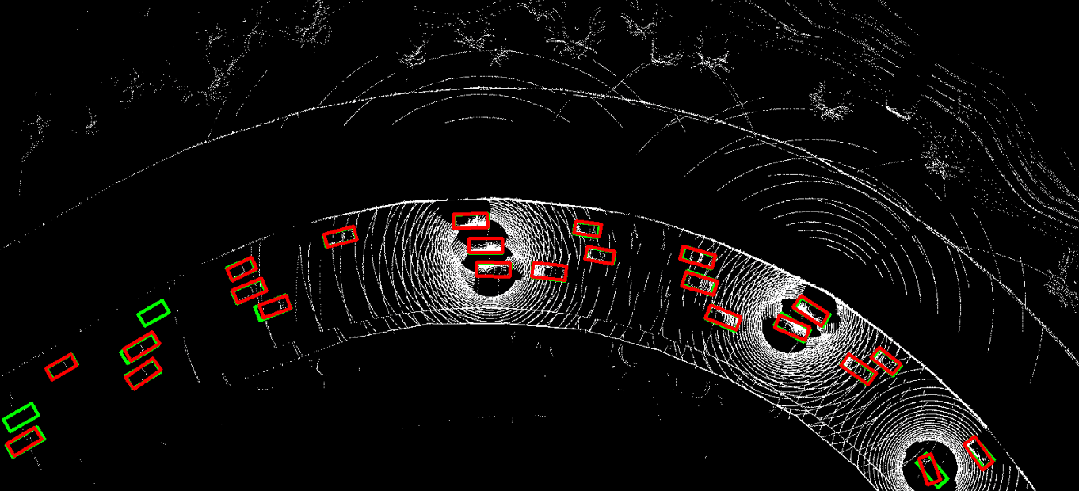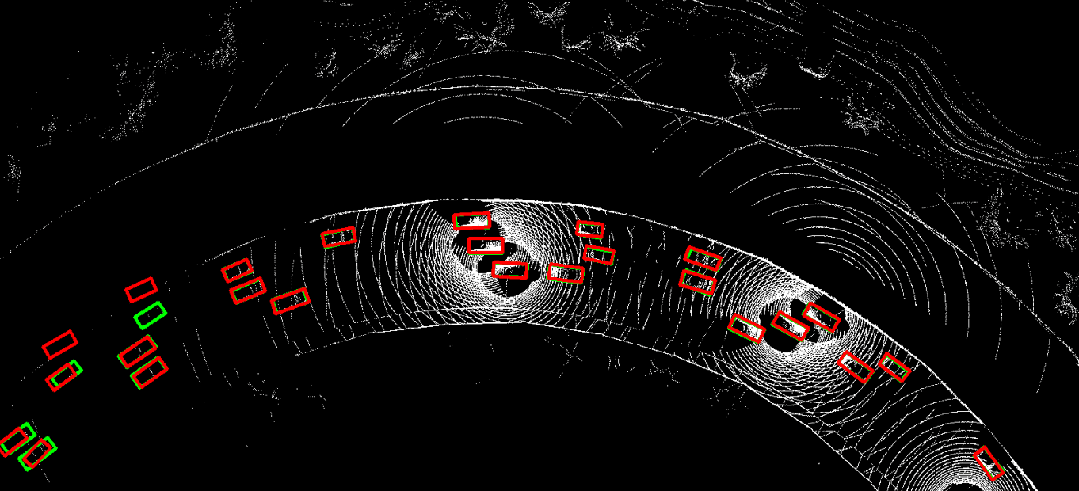
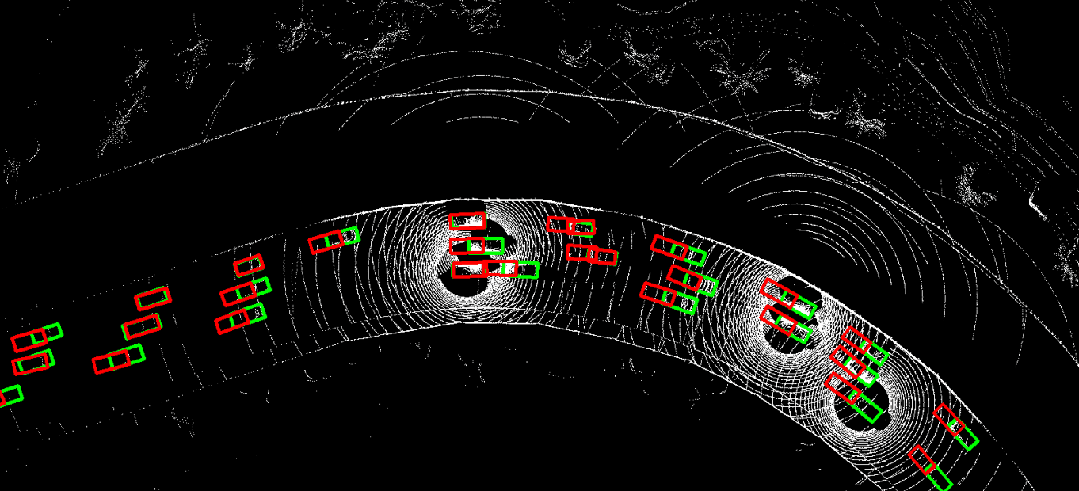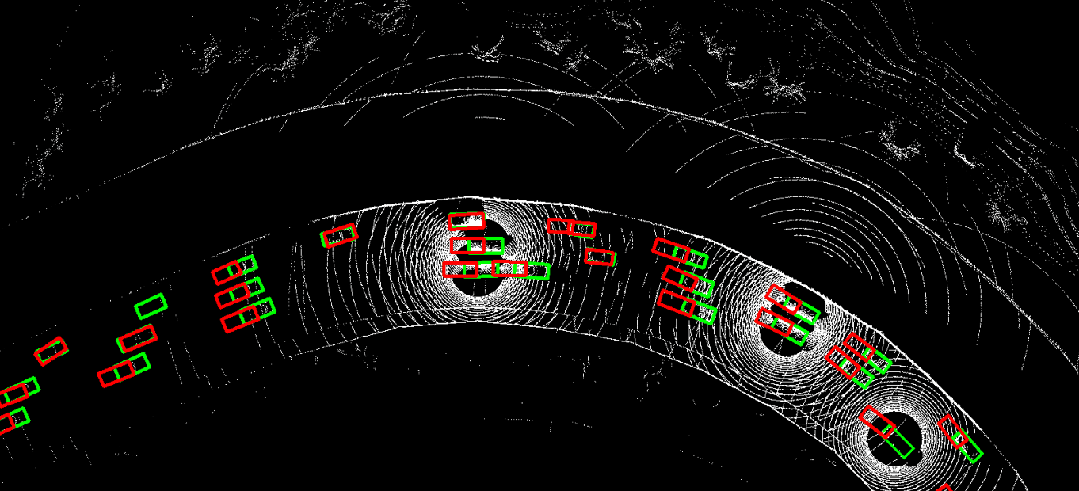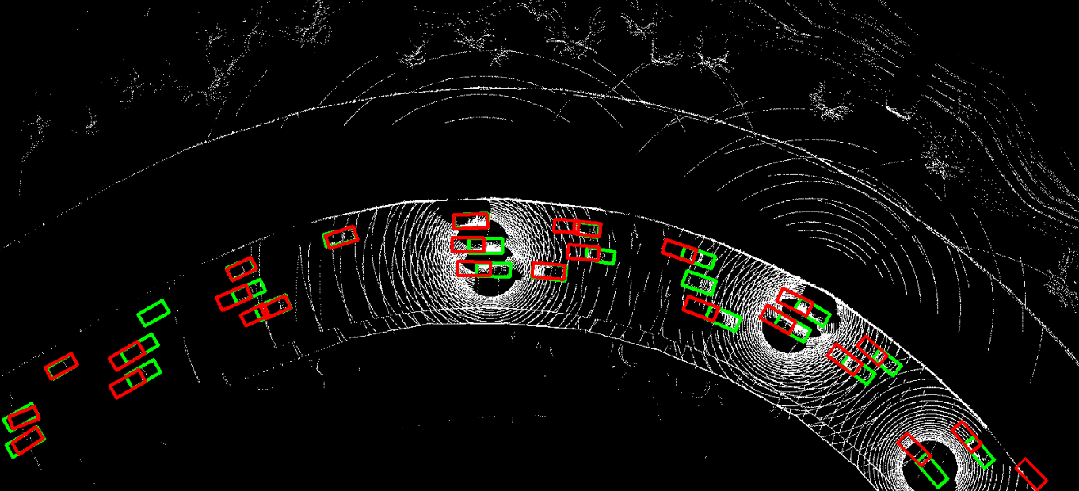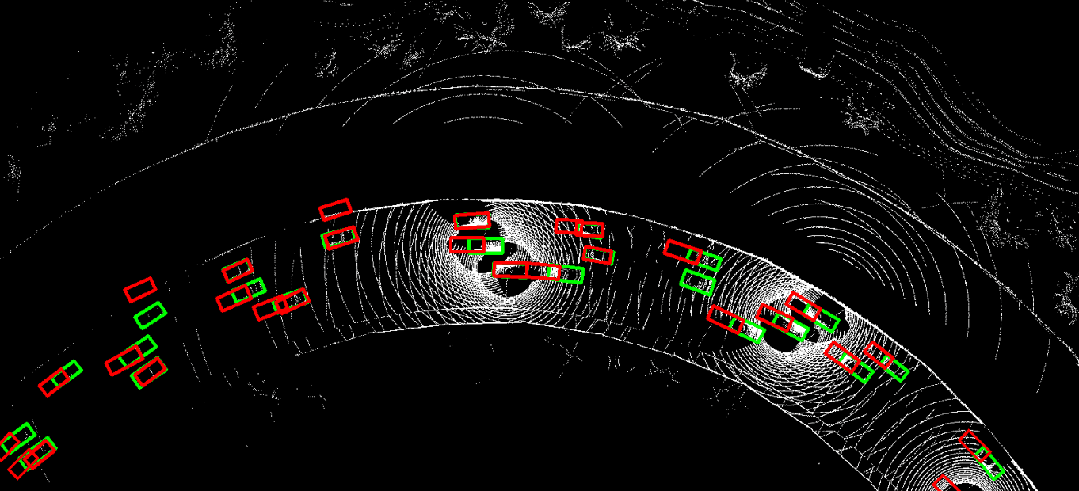
图 10. 时序异步情况下采用where2comm(左)直接进行协同感知的结果,与利用CoBEVFlow(右)进行协同感知的结果对比。红色为预测结果,绿色为真实值。
CoBEVFlow (红实线) 显著节省通信带宽

图 11. 感知性能与通信带宽之间的关系(时序异步期望为300ms)。
研究者们对比了不同方法的性能与通信带宽之间的关系。如图,红色实线表示CoBEVFlow。在时间异步的期望值为300毫秒的情况下,随着通信量的增加,CoBEVFlow的性能持续稳定提高,而where2comm和SyncNet的性能由于异步信息而导致性能波动。CoBEVFlow能够显著节省通信带宽的原因是,其协作信息只包含ROI区域中的稀疏特征以及ROI集,而不用整个特征图进行协作。
CoBEVFlow能够避免引入额外噪声

图 12 BEV Flow Map的效果可视化。(a)(b)分别是经过矫正前后的中间特征可视化,(c) 为BEV flow map的可视化,(d) 为匹配结果的可视化。
CoBEVFlow利用历史协作信息生成鸟瞰流图——BEV Flow Map,并根据流图,将BEV特征图上的“网格”特征找到新的对应的索引。这个过程的思想是“挪动”异步的特征到当前时刻对应的位置上,不涉及对于特征的数值变换,避免了引入额外的噪声(事实上,在挪动特征的过程中,用到了PyTorch内置的函数进行warp操作,存在着微小的差值误差)。研究人员们将原始的特征和挪动后的特征分别进行可视化,如图中的子图(a)、(b)。同时,将生成额BEV Flow Map以及ROI区域的配对结果进行了可视化,如图中的子图(c)、(d)。能从图中看出,该文提出的鸟瞰流图生成器对于不同帧中的ROI区域能够有效配对,也因此可以捕捉到ROI区域的运动趋势,并生成流图,用来矫正特征图。
图 13. 鸟瞰流图的连续多帧可视化结果。
BEV Flow Map 作用在中融合优于后融合

表 1 IRV2V数据集上的消融实验结果。
既然生成的BEV Flow Map能够准确捕捉ROI的运动趋势,那为什么不直接对检测框的位置进行矫正?研究人员们针对这个问题也在消融实验的部分进行了实验验证。如表格中的第3行和第5行的对比,能够看出,对于特征的矫正比对于检测框位置的矫正效果要好。研究人员猜测,可能是感兴趣区域对于单车检测未必是一个完整的物体,但是经过多车融合后的特征图,包含了来自多个协作者的信息,因此对于一些在单车视角下“不确定”的目标,中融合对于中间特征进行操作将更有优势。此外,消融实验中也进行了关于时间编码和不同的匹配算法的效果验证。
总结
CoBEVFlow关注解决协同感知中存在的时序异步问题。其提出的核心思路有两个:一是每个智能体发送的协作信息中应包含感兴趣区域与其对应的稀疏特征图。二是在协作感知时,基于收集到的历史信息生成BEV Flow,并用其“矫正”时序异步的特征。通过这两两个关键思路,CoBEVFlow能够有效处理包含延迟、中断、采样频率不一致等原因导致的时序异步问题,同时不会对特征图引入额外的噪声。
# Cam4DOcc
刚出炉的Cam4DOcc,上交&国防科大&毫末联合出品!Cam4DOcc首先讨论了在自动驾驶中理解周围环境的重要性,以及目前依赖视觉图像的占用估计技术的局限性。进一步提出了Cam4Occ,这是一种用于纯视觉4D占用预测的新基准,用于评估在不久的将来周围场景的变化。为了全面比较本文的benchmark,Cam4Occ介绍了来自不同基于相机的感知和预测实现的四种基线类型,包括静态世界占用模型、点云预测的体素化、基于2D-3D实例的预测,以及本文提出的新的端到端4D占用预测网络(OCFNet)。代码即将开源~纯视觉4D占用预测新基线,面向端到端一体化的纯视觉新方案
较新颖的部分
- 数据的重组:
数据集被重组为一种新颖的格式,该格式考虑了关于其运动特性的两类,即⼀般可移动物体(GMO)和⼀般静态物体(GSO),作为占⽤体素⽹格的语义标签。与 GSO 相⽐,GMO 通常具有更⾼的动态运动特性,出于安全原因,在交通活动期间需要更多关注,准确估计 GMO 的⾏为并预测其潜在的运动变化会显着影响⾃我车辆的决策和运动规划。 - 新数据集格式:
如图2所示:论文提出了一个新的数据集格式,该格式基于现有的数据集如nuScenes、nuScenes-Occupancy和Lyft-Level5,但进行了扩展和调整,以适应4D占用预测的需求。特别是,它关注于序列化占用状态和3D向后心向流的表示。
(1)⾸先将原始nuScenes数据集分割成时间⻓度为过去,现在和未来的序列;
(2)然后为每个序列提取可移动物体的顺序语义和实例注释并收集到GMO类中;
(3)把过去,现在和未来的帧都转换到当前坐标系(t = 0)之后对当前 3D 空间进⾏体素化,并使⽤边界框注释将语义/实例标签附加到可移动目标的网格上,在这个过程中进行了红色框内的条件删除;
(4)最后,使⽤标注中的实例关联⽣成 3D 向⼼流( 3D backwardcentripetal flow)
补充:Cam4DOcc还说了标不仅是预测 GMO 的未来位置,还要估计 GSO 的占⽤状态和安全导航所需的⾃由空间,因此,进⼀步将原始 nuScenes 中的顺序实例注释与从nuScenes-Occupancy 转换到当前帧的顺序占⽤注释连接起来。这种组合平衡了⾃动驾驶应⽤中下游导航的安全性和精度。

3. 四级占用预测任务的评估协议: Cam4DOcc为4D占用预测任务定义了一套标准化的评估协议,包括多种任务和评估指标。
(1)预测膨胀的 GMO:所有占⽤⽹格的类别分为 GMO 和其他,其中来⾃ nuScenes 和Lyft-Level5 的实例边界框内的体素⽹格被注释为 GMO;
(2)预测细粒度GMO:类别也分为GMO和其他,但GMO的注释直接来⾃nuScenes-Occupancy的体素标签;
(3)预测膨胀的GMO、细粒度GSO和⾃由空间:类别分为来⾃边界框注释的GMO、遵循细粒度注释的GSO和⾃由空间;
(4)预测细粒度GMO、细粒度GSO和⾃由空间:类别分为GMO和GSO,均遵循细粒度注释和⾃由空间
解析:不要看到这么以上只是作者对于模型的评估标准而已,再者说作者也说到了由于 Lyft-Level5 数据集缺少占⽤标签,因此我们仅对其第⼀个任务进⾏评估。

更接近当前时刻的时间戳IoU对最终IoUf的贡献更大。这符合近时间戳的占用预测对后续运动规划和决策更重要的原则
4.四种方法作为 Cam4DOcc 中的基线: Cam4DOcc基准从占用预测、点云预测、2D实例预测的扩展,以及我们的端到端4D占用预测网络,提出了四种类型的基线:

(1)静态世界占⽤模型:最直接的基线之⼀是假设环境在短时间内保持静态,因此,可以使⽤当前估计的占⽤⽹格作为基于静态世界假设的所有未来时间步的预测,如图3a所⽰;
(2)点云预测的体素化:使⽤环视深度估计来⽣成跨多个camera的深度图,然后通过光线投射来⽣成 3D 点云,将其与点云预测⼀起应⽤以获得预测的未来伪点,然后应用基于点的语义分割来获得每个体素的可移动和静态标签,从而产生最终的占用预测,如图3b所⽰;
(3)基于 2D-3D 实例的预测:许多现成的基于BEV的2D实例预测方法可以用周围视图相机图像预测不久的将来的语义,第三种基线是通过将BEV生成的网格沿z轴复制到车辆的高度来获得3D空间中的预测GMO,如图3c所示,可以看出,该基线假设驾驶表面是平的,所有移动物体都具有相同的高度,我们不评估预测GSO的基线,因为与GMO相比,通过复制提高2D结果不适合模拟具有更复杂结构的大规模背景。
(4)端到端占⽤预测⽹络OCFNet:OCFNet 接收连续的过去环视camera图像来预测当前和未来的占⽤状态。它利⽤多帧特征聚合模块来提取扭曲的 3D 体素特征,并利⽤未来状态预测模块来预测未来的占⽤情况以及 3D 向后向心流,如图3d 所示。
端到端占⽤预测⽹络OCFNet(重点!!!):



其中^D0、D0分别是2D-3D提升模块估计的深度图像和激光雷达数据投影的地面实况距离图像给出。λ1、λ2和λ3是平衡占用预测、流量预测和深度重建优化的权重
5.CAM4DOCC实验: 评估了提议基线(包括OCFNet)在自动驾驶场景中的四个任务的占用率估计和预测性能:

提出的OCFNet对膨胀GMO进行预测。从时间戳1到Nf的预测结果和GT被赋予从暗到亮的颜色。每个运动物体的运动趋势用红色箭头表示,OCFNet和CFNet预测的nuScenes GMO占用率的结果,这表明仅使用有限数据训练的OCFNet仍然可以合理地捕捉GMO占用网格的运动
Cam4DOcc:自动驾驶纯视觉的4D占用预测基准补充材料
A.数据集设置详细信息:
如图6所示,大多数一般可移动对象(GMO)出现在我们基准测试中的至少两个历史观测和所有未来观测([−2,4]和[−1,4])中。长实例持续时间导致占用预测模型的有效训练策略。此外,两个数据集中超过30%的实例首先出现在当前帧中(t=0),这使得模型仅根据对象当前位置和周围条件学习预测对象运动

Cam4DOcc中定义的膨胀GMO和细粒度GMO的详细说明,如图7所示。与细粒度标签相比,膨胀的边界框式注释总体上为占用预测模型提供了更全面的训练信号。此外,来自实例边界框的结构化格式的GMO的运动更容易捕获。从图7的第二行我们还可以看到,有时细粒度体素注释不能准确地表示GMO的复杂形状,而边界框式注释可以完全涵盖整体GMO实例网格。图7的第三行还提出,与原始实例边界框标签相比,细粒度注释可能会遗漏一些被遮挡的对象,影响对这些场景进行训练和评估的合理性。因此,Cam4DOcc建议使用膨胀的GMO注释来训练当前阶段基于相机的模型,以实现更可靠的4D占用预测和更安全的自动驾驶导航。

B. OCFNET模型细节:
提出的OCFNet接收6张尺寸为900×1600的图像,这些图像由安装在车辆上的环视相机拍摄。使用ResNet50在ImageNet上进行预训练,并使用FPN作为OCFNet中的图像编码器。基于LSS的2D-3D提升模块将来自多个相机图像的图像信息转换和融合为统一的体素特征。使用3D-ResNet18作为体素编码器,并在未来状态预测模块的占用预测头和流量预测头中使用3D-FPN作为体素解码器。包含堆叠残差卷积块的预测模块对历史3D特征进行有序编码,根据未来时间视界Nf扩展通道维度,并产生未来3D特征,如图8所示。参考PowerBEV的设置,预测模块中三种残差卷积块的数量设置为2、1和2,内核大小为(3、3、1)

为了将我们的占用预测模型扩展到3D实例预测,OCFNet预测了t ∈ [0, Nf ]上的占用和3D流,对应于工作中的5个连续估计。首先从PowerBEV之后t=0处的估计占用概率中提取局部极大值,确定实例的中心。然后,以下未来帧中的实例与预测流连续关联,为了使用公式(4)中定义的损失来训练我们的OCFNet,我们设置λ1=λ3=0.5和λ2=0.05来平衡占用预测、深度重建和3D向心流预测的优化。OCFNet的总参数数为370 M,GFLOP为6434,训练时GPU内存为57 GB。
C.未来时间视界研究
进一步进行了一项关于预测不同未来时间范围内性能下降的研究。由于静态目标的占用网格在未来时间步长中不会改变,除非GT抖动,因此在这里,我们只关注预测可移动目标未来占用状态的能力。在本实验中,发布了Openoccupancy-C、PowerBEV-3D和我们的OCFNet在第一级任务和第二级任务中的性能,因为基线SPC未能预测膨胀的GMO(在实验中)。如下图所示,OCFNet在两个任务的不同时间范围内仍然是最佳性能。此外,所有基线方法在Lyft-Level5上显示出比nuScenes更好的性能,因为在Lyft-Level5上进行评估的时间相对较短。时间戳越接近当前时刻,所有基线就越容易预测占用状态

D.3D flow预测:
从图9中可以看出,运动物体的预测flow向量近似地从新帧的体素网格指向属于同一实例的过去帧的体素网格。因此,预测flow可以通过显式捕捉GMO在每个时间间隔内的运动来进一步指导占用预测。由于Cam4DOcc预测的flow向量,可以进一步关联相邻未来帧之间的一致实例,从而导致超越占用状态预测的3D实例预测。

预测的3D后向流的等值化(t ∈ [1, Nf ])。从时间戳1到Nf的输出流向量和地面实况占用分别被分配从暗到亮的颜色。每个选定运动物体的运动趋势用红色箭头表示
E.3D实例预测:
大多数现有的实例预测方法只能预测感兴趣目标在BEV表示上的未来位置,而我们的工作将这一任务扩展到更复杂的3D空间。首先在t=0时通过非最大抑制(NMS)提取实例的中心,然后使用预测的3D向后向心流在时间t ∈ [1, Nf ]上关联按像素划分的实例ID。为了报告实例预测质量,我们将度量视频全景质量(VPQ)从之前的2D实例预测扩展到我们的3D实例预测,该预测由

OCFNet在Lyft-Level5上显示出比PowerBEV-3D更好的3D实例预测能力,而PowerBEV-3D在nuScenes上优于OCFNet的方法。此外,OCFNet在nuScenes和Lyft-Level5上分别将OCFNet的预测提高了30.2%和13.7%。基于2D-3D实例的预测基线在nuScenes上呈现出良好的实例预测能力,因为2D向后向心流比3D对应物更容易预测。相反,在Lyft-Level5上产生了更好的预测结果,主要是OCFNet的GMO占用预测质量要好得多。
F. 在LYFT-LEVEL5的未来预测 GMO占据的可视化演示
OCFNet在Lyft-Level5小规模场景中预测膨胀GMO:

OCFNet在Lyft-Level5的大规模场景中预测膨胀的GMO:




















