
#大模型对齐阶段的Scaling Laws
Scaling law不仅是一个好用的工具,它本身的存在也给出了能影响模型效果的关键因素,指导着算法的迭代方向,比如在预训练中,核心是数据量、模型尺寸,最近Deepseek的工作中也对batch size、learning rate这两个重要超参数进行了分析。
卷友们好,我是rumor。随着过去一年大模型技术的发展,数据、模型尺寸scale up后的能力已经不容置疑,scaling law也被越来越多研究者重视起来。在预训练资源消耗如此大的情况下,掌握scaling law有众多优点:
- 提前预测最终模型效果,知道每次训练的大概能到什么程度,要是不及预期可以根据预算再进行调整
- 在小尺寸模型上做置信的实验,进行数据、算法策略验证,降低实验的时间、资源成本
- 在真正的大规模预训练中,随时监测模型效果是否符合预期
目前对于scaling law的研究主要是在预训练阶段,而对齐阶段在数据、算法策略上的实验也会有很大成本,今天我们就来看两篇对齐阶段的工作,分别研究了SFT和RLHF阶段影响效果的重要因素,希望能给大家带来一些新的insight。
精调Scaling Law
When Scaling Meets LLM Finetuning - The Effect of Data, Model and Finetuning Method这篇文章来自Google,发表在ICLR2024。作者主要在文本翻译任务上,研究了精调数据数量、模型尺寸、预训练数据数量、PET参数量(prompt tuning、lora)对效果的影响。精调和预训练比较接近,得到的公式也较接近,可以用幂函数来表示:

其中是精调数据尺寸,是其他影响因子,都是需要拟合的参数,可以反应因子的重要程度。在这篇工作中,作者以精调数据量为核心因素,分别建模了精调数据量和其他因素的联合scaling law。
精调数据量+模型尺寸

上图中实线为作者拟合的曲线,圆点是拟合用的实验点,倒三角是held-out点,用来验证外推是否准确。可以看到,随着数据量和模型尺寸的增加,test ppl也展现了一定规律的下降。但实际推到16B尺寸时在PET方式下拟合程度一般,作者分析是16B本身在预训练阶段存在一些问题。
精调数据量+预训练数据量

可以看到,预训练数据量对下游精调确实也有一定影响,外推拟合的也比较好。不过对比模型尺寸可以发现,同样计算预算下,用更大的模型尺寸精调>用更多数据预训练。但作者也指出这可能是因为翻译任务对于多样性的要求不高。
精调数据量+PET参数量

可以看到,增加PET参数量的帮助很小。同时lora比prompt tuning的方式更加稳定,更容易拟合,prompt tuning甚至出现了inverse scaling的现象。
总结
由于这篇工作只在机器翻译任务上做了实验,同时外推到16B的偏差较大,因此参考意义有限。但作者的一些实验也有重要的参考意义:
- 精调数据存在scaling law,虽然现在大家都认同小数量高质数据能取得很好的效果,但当下游任务确定时怼量也是一种选择
- 对比全参数精调FMT和PET精调的结果可以发现,FMT需要更多的数据,也能取得更好的效果。而数据量少时更适合用PET,prompt tuning在数据量少的时候更好,lora在数据量多的时候更好更稳定。另外PET的精调方式很依赖模型尺寸和预训练数据,当基座很强时,PET和FMT的差距会缩小
- 同时作者也分析了一下精调模型在其他任务上的泛化效果,发现精调后模型可以泛化到相似的任务,由于PET对参数的改动较小,因此PET的方式泛化会更好
因此,对于有明确下游任务的场景,用强基座+小数量+PET精调是一个很明智的选择。但对于任务不明确的通用场景,正如作者所言:the optimal finetuning method is highly task- and finetuning data-dependent,要得到明确的规律还有一定难度。
RLHF Scaling Law
RLHF涉及到4个模型,变量非常多,想想都不知道怎么下手。但这并难不倒OpenAI,他们早在22年底就悄咪咪放出了一篇文章,一共只有三个作者,第二作者是PPO之父John Schulman,同时也是OpenAI Alignment的Lead,阵容非常强大。
相比于预训练和精调,Scaling law对于RLHF还有一项重要意义,因为在RLHF过程中,存在着一个很典型的问题:过优化(overoptimization)。当使用奖励模型(Reward Model,简称RM)去代替人类判断时,很难保证它是无偏的,而强化算法又会让模型走捷径,一旦发现哪个地方奖励高,立刻就朝着该方向优化,拿到更高奖励值。这一现象也可以称为Goodhart’s law:
When a measure becomes a target, it ceases to be a good measure.
所以真实的场景就很迷了,明明看着奖励曲线上升得很美妙,但评估出来效果不一定更好,所以到底挑哪个checkpoint去评估呢?如果有RLHF的scaling law,我们就可以预测模型真实的最优ckpt,适时停止训练,减少模型训练、评估成本。OpenAI这篇工作得到的结论则是:

其中,和是通过RM算出来的。

公式中的核心是RM尺寸和KL散度两个因素,有了这个公式之后,我们就可以:
- 根据当前模型偏离的KL散度,来预测模型何时到达最高的真实分数,提升评估效率
- 根据使用的RM,来预测模型能达到什么效果,或者根据效果倒推要用多大的模型
虽然最终的公式看起来非常简单,但作者也进行了很多的实验和分析。首先介绍一下实验设置,为了提升评估效率,作者使用了两个RM,一个时Gold RM,作为labeler的角色,标注一份数据后训练proxy RM,用来做RL实验:

对于RLHF的scaling law,如何挑选X和Y轴?
首先Y轴比较好选,预训练模型一般用loss,比较连续,且可以很好地反映模型效果,RL可以自然地用Reward,也具有同样的功能。但X轴就不一样了,设置成KL散度非常巧妙,因为RL不能像预训练/精调一样用计算量、过的Token数量等,如果RL也用训练时过的Token数量,会有一个问题:预训练和SFT只优化交叉熵损失这一个目标,而RL同时优化总奖励和KL惩罚两个目标,而且这两个目标是互相拉扯的,KL惩罚希望模型尽量不偏离太远,而模型要拿更多的奖励不可避免会有参数更新。于是作者看了一下不同KL惩罚系数下KL散度与步数的关系:

KL散度与步数的关系
如果系数过大,感觉模型就不更新了,那这时候Reward还能提吗?因此KL penalty在RLHF中其实起着early stopping的作用,为了研究训练步数的影响,作者实验时去掉了KL penalty。
除了RM尺寸,还有其他影响因素吗?
作者也对RM的训练数据量进行了实验,结果比较符合直觉,训练数据越多实际的gold score越大,但无法拟合出更清晰的规律。同时作者也尝试了不同的policy模型尺寸,更大的模型在相同RM下效果更好,比较符合直觉。但也有不符合直觉的地方,比如作者觉得更大的模型会更快过优化,实际上是和小模型在相同的KL点开始过优化的。同时不同尺寸下proxy和gold的分数gap也基本接近,没有比小模型更好拟合RM。

个人认为OpenAI的这篇工作非常值得一看,有很多实验细节,同时得到的结论简洁优雅。
总结
Scaling law不仅是一个好用的工具,它本身的存在也给出了能影响模型效果的关键因素,指导着算法的迭代方向,比如在预训练中,核心是数据量、模型尺寸,最近Deepseek的工作中也对batch size、learning rate这两个重要超参数进行了分析。而在对齐阶段,综合上面两篇工作,数据量、模型尺寸、RM尺寸都对效果有着规律清晰的影响,掌握这些规律十分重要,也希望后面能有更多Scaling law的相关工作。
#多模态大语言模型综述
去年 6 月底,我们在 arXiv 上发布了业内首篇多模态大语言模型领域的综述《A Survey on Multimodal Large Language Models》,系统性梳理了多模态大语言模型的进展和发展方向,目前论文引用 120+,开源 GitHub 项目获得 8.3K Stars。自论文发布以来,我们收到了很多读者非常宝贵的意见,感谢大家的支持!
- 论文链接:https://arxiv.org/pdf/2306.13549.pdf
- 项目链接(每日更新最新论文):https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models
去年以来,我们见证了以 GPT-4V 为代表的多模态大语言模型(Multimodal Large Language Model,MLLM)的飞速发展。为此我们对综述进行了重大升级,帮助大家全面了解该领域的发展现状以及潜在的发展方向。

MLLM 发展脉络图
MLLM 脱胎于近年来广受关注的大语言模型(Large Language Model , LLM),在其原有的强大泛化和推理能力基础上,进一步引入了多模态信息处理能力。相比于以往的多模态方法,例如以 CLIP 为代表的判别式,或以 OFA 为代表的生成式,新兴的 MLLM 展现出一些典型的特质:(1)模型大。MLLM 通常具有数十亿的参数量,更多的参数量带来更多的潜力;(2)新的训练范式。为了激活巨大参数量的潜力,MLLM 采用了多模态预训练、多模态指令微调等新的训练范式,与之匹配的是相应的数据集构造方式和评测方法等。在这两种特质的加持下,MLLM 涌现出一些以往多模态模型所不具备的能力,例如给定图片进行 OCRFree 的数学推理、给定图片进行故事创作和理解表情包的深层含义等。
本综述主要围绕 MLLM 的基础形式、拓展延伸以及相关研究课题进行展开,具体包括:
- MLLM 的基础构成与相关概念,包括架构、训练策略、数据和评测;
- MLLM 的拓展延伸,包括输入输出粒度、模态、语言和场景的支持;
- MLLM 的相关研究课题,包括多模态幻觉、多模态上下文学习(Multimodal In-Context Learning,M-ICL)、多模态思维链(Multimodal Chain of Thought,M-CoT)、LLM 辅助的视觉推理(LLM-Aided Visual Reasoning,LAVR)。
架构
对于多模态输入-文本输出的典型 MLLM,其架构一般包括编码器、连接器以及 LLM。如要支持更多模态的输出(如图片、音频、视频),一般需要额外接入生成器,如下图所示:

MLLM 架构图
其中,模态编码器负责将原始的信息(如图片)编码成特征,连接器则进一步将特征处理成LLM 易于理解的形式,即视觉 Token。LLM 则作为“大脑”综合这些信息进行理解和推理,生成回答。目前,三者的参数量并不等同,以 Qwen-VL[1]为例,LLM 作为“大脑”参数量为 7.7B,约占总参数量的 80.2%,视觉编码器次之(1.9B,约占 19.7%),而连接器参数量仅有 0.08B。
对于视觉编码器而言,增大输入图片的分辨率是提升性能的有效方法。一种方式是直接提升分辨率,这种情况下需要放开视觉编码器进行训练以适应更高的分辨率,如 Qwen-VL[1]等。另一种方式是将大分辨率图片切分成多个子图,每个子图以低分辨率送入视觉编码器中,这样可以间接提升输入的分辨率,如 Monkey[2]等工作。
对于预训练的 LLM,常用的包括 LLaMA[3]系列、Qwen[4]系列和 InternLM[5]系列等,前者主要支持英文,而后两者中英双语支持得更好。就性能影响而言,加大 LLM 的参数量可以带来显著的性能增益,如 LLaVA-NeXT[6]等工作在 7B/13B/34B 的 LLM 上进行实验,发现提升LLM 大小可以带来各 benchmark 上的显著提升,在 34B 的模型上更涌现出 zero-shot 的中文能力。除了直接增大 LLM 参数量,近期火热的 MoE 架构则提供了更高效实现的可能性,即通过稀疏计算的方式,在不增大实际计算参数量的前提下提高总的模型参数量。
相对前两者来说,连接器的重要性略低。例如,MM1[7]通过实验发现,连接器的类型不如视觉 token 数量(决定之后 LLM 可用的视觉信息)及图片的分辨率(决定视觉编码器的输入信息量)重要。
数据与训练
MLLM 的训练大致可以划分为预训练阶段、指令微调阶段和对齐微调阶段。预训练阶段主要通过大量配对数据将图片信息对齐到 LLM 的表征空间,即让 LLM 读懂视觉 Token。指令微调阶段则通过多样化的各种类型的任务数据提升模型在下游任务上的性能,以及模型理解和服从指令的能力。对齐微调阶段一般使用强化学习技术使模型对齐人类价值观或某些特定需求(如更少幻觉)。
早期工作在第一阶段主要使用粗粒度的图文对数据,如 LAION-5B,这些数据主要来源于互联网上的图片及其附带的文字说明,因此具有规模大(数 10 亿规模)但噪声多、文本短的特点,容易影响对齐的效果。后来的工作则探索使用更干净、文本内容更丰富的数据做对齐。如 ShareGPT4V[8]使用 GPT-4V 生成的详细描述来做更细粒度的对齐,在一定程度上缓解了对齐不充分的问题,获得了更好的性能。但由于 GPT-4V 是收费的,这种类型的数据规模通常较小(数百万规模)。此外,由于数据规模受限,其包含的世界知识也是有限的,比如是否能够识别出图像中的建筑为广州塔。此类世界知识通常储备于大规模的粗粒度图文对中。
第二阶段的微调数据一方面可以来源于各种任务的数据,如 VQA 数据、OCR 数据等,也可以来源于 GPT-4V 生成的数据,如问答对。虽然后者一般能够生成更复杂、更多样化的指令数据,但这种方式也显著地增加了成本。值得一提的是,第二阶段的训练中一般还会混合部分纯文本的对话数据,这类数据可以视为正则化的手段,保留 LLM 原有的能力与内嵌知识。
第三阶段的数据主要是针对于回答的偏好数据。这类数据通常由人工标注收集,因而成本较高。近期出现一些工作使用自动化的方法对来自不同模型的回复进行偏好排序,如 Silkie[9]通过调用 GPT-4V 来收集偏好数据。
其他技术方向
除了提升模型的基础能力(如支持的输入/输出形式、性能指标)外,还有一些有意思的问题以及待探索的方向。本综述中主要介绍了多模态幻觉、多模态上下文学习(Multimodal InContext Learning,M-ICL)、多模态思维链(Multimodal Chain of Thought,M-CoT)和 LLM 辅助的视觉推理(LLM-Aided Visual Reasoning,LAVR)等。
多模态幻觉的研究主要关注模型生成的回答与图片内容不符的问题。视觉和文本本质上是异构的信息,完全对齐两者本身就具有相当大的挑战。增大图像分辨率和提升训练数据质量是降低多模态幻觉的两种最直观的方式,此外我们仍然需要在原理上探索多模态幻觉的成因和解法。例如,当前的视觉信息的 Token 化方法、多模态对齐的范式、多模态数据和 LLM 存储知识的冲突等对多模态幻觉的影响仍需深入研究。
多模态上下文学习技术为少样本学习方法,旨在使用少量的问答样例提示模型,提升模型的few-shot 性能。提升性能的关键在于让模型有效地关注上下文,并将内在的问题模式泛化到新的问题上。以 Flamingo[10]为代表的工作通过在图文交错的数据上训练来提升模型关注上下文的能力。目前对于多模态上下文学习的研究还比较初步,有待进一步探索。
多模态思维链的基本思想是通过将复杂的问题分解为较简单的子问题,然后分别解决并汇总。相较于纯文本的推理,多模态的推理涉及更多的信息来源和更复杂的逻辑关系,因此要复杂得多。当前该方面的工作也比较少。
LLM 辅助的视觉推理方法探索如何利用 LLM 强大的内嵌知识与能力,并借助其他工具,设计各种视觉推理系统,解决各种现实问题。相比于通过端到端训练获得单一模型,这类方法一般关注如何通过免训练的方式扩展和加强 LLM 的能力,从而构建一个综合性的系统。
挑战和未来方向
针对 MLLM 的研究现状,我们进行了深入思考,将挑战与可能的未来发展方向总结如下:
- 现有 MLLM 处理多模态长上下文的能力有限,导致模型在长视频理解、图文交错内容理解等任务中面临巨大挑战。以 Gemini 1.5 Pro 为代表的 MLLM 正在掀起长视频理解的浪潮,而多模态图文交错阅读理解(即长文档中既有图像也有文本)则相对空白,很可能会成为接下来的研究热点。
- MLLM 服从复杂指令的能力不足。例如,GPT-4V 可以理解复杂的指令来生成问答对甚至包含推理信息,但其他模型这方面的能力则明显不足,仍有较大的提升空间。
- MLLM 的上下文学习和思维链研究依然处于初步阶段,相关的能力也较弱,亟需相关底层机制以及能力提升的研究探索。
- 开发基于 MLLM 的智能体是一个研究热点。要实现这类应用,需要全面提升模型的感知、推理和规划能力。
- 安全问题。MLLM 容易受设计的恶意攻击影响,生成有偏的或不良的回答。该方面的相关研究也仍然欠缺。
- 目前 MLLM 在训练时通常都会解冻 LLM,虽然在训练过程中也会加入部分单模态的文本训练数据,但大规模的多模态和单模态数据共同训练时究竟对彼此互有增益还是互相损害仍然缺乏系统深入的研究。
更详细内容请阅读
- 论文链接:https://arxiv.org/pdf/2306.13549.pdf
- 项目链接:https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models
#Mistral开源8X22B大模型
OpenAI更新GPT-4 Turbo视觉,都在欺负谷歌,真有围剿 Google 的态势啊!
在谷歌昨晚 Cloud Next 大会进行一系列重大发布时,你们都来抢热度:前有 OpenAI 更新 GPT-4 Turbo,后有 Mistral 开源 8X22B 的超大模型。
谷歌内心:南村群童欺我老无力。
第二大开源模型:Mixtral 8X22B
今年 1 月,Mistral AI 公布了 Mixtral 8x7B 的技术细节,并推出了 Mixtral 8x7B – Instruct 聊天模型。该模型的性能在人类评估基准上明显超过了 GPT-3.5 Turbo、Claude-2.1、Gemini Pro 和 Llama 2 70B 聊天模型。
短短 3 个月后,Mistral AI 开源了 Mistral 8X22B 模型,为开源社区带来了又一个性能强劲的大模型。
有人已经查看了 Mistral 8X22B 模型的细节,模型文件大小约为 262 GB。
由此,Mistral 8X22B 仅次于 xAI 此前推出的 Grok-1(参数量为 3140 亿),成为迄今为止第二大开源模型。
还有人惊呼,MoE 圈子又来了个「大家伙」。MoE 即专家混合模型,此前 Grok-1 也为 MoE 模型。
GPT-4 Turbo 视觉功能新升级
另一边,OpenAI 宣布 GPT-4 Turbo with Vision 现在可以通过 API 使用了,并且 Vision 功能也可以使用 JSON 模式和函数调用了。
下面为 OpenAI 官网细节。
虽然如此,各路网友对 OpenAI 的小修小补「并不感冒」。
参考链接:
https://platform.openai.com/docs/models/continuous-model-upgrades
#谷歌更新了一大波大模型产品
这次,谷歌要凭「量」打败其他竞争对手。
当地时间本周二,谷歌在 Google’s Cloud Next 2024 上发布了一系列 AI 相关的模型更新和产品,包括 Gemini 1.5 Pro 首次提供了本地音频(语音)理解功能、代码生成新模型 CodeGemma、首款自研 Arm 处理器 Axion 等等。
Gemini 1.5 Pro
Gemini 1.5 Pro 是 Google 功能最强大的生成式 AI 模型,现已在 Google 以企业为中心的 AI 开发平台 Vertex AI 上提供公共预览版。这是谷歌面向企业的 AI 开发平台。它能处理的上下文从 12.8 万个 token 增加到 100 万个 token。100 万个 token 大约相当于 70 万个单词,或者大约 3 万行代码。这大致是 Anthropic 的旗舰模型 Claude 3 能作为输入处理的数据量的四倍,也大约是 OpenAI 的 GPT-4 Turbo 最大上下文量的八倍。
官方原文链接:https://developers.googleblog.com/2024/04/gemini-15-pro-in-public-preview-with-new-features.html
该版本首次提供了本地音频(语音)理解功能和全新的文件 API,使文件处理变得更加简单。Gemini 1.5 Pro 的输入模态正在拓展,包括在 Gemini API 和 Google AI Studio 中增加对音频(语音)的理解。此外,Gemini 1.5 Pro 现在能够对在 Google AI Studio 中上传的视频的图像(帧)和音频(语音)进行推理。
可以上传一个讲座的录音,比如这个由 Jeff Dean 进行的超过 117000 个 token 的讲座,Gemini 1.5 Pro 可以将其转换成一个带有答案的测验。(演示已加速)
谷歌在 Gemini API 方面也进行了改进,主要有以下三个内容:
1. 系统指令:现在可以在 Google AI Studio 和 Gemini API 中使用系统指令来指导模型的响应。定义角色、格式、目标和规则,以针对您的特定用例指导模型的行为。
在 Google AI Studio 中轻松设置系统指令
2.JSON 模式:指示模型仅输出 JSON 对象。这种模式使从文本或图像中提取结构化数据成为可能。现在可以使用 cURL,Python SDK 支持即将推出。
3. 对函数调用的改进:现在可以选择模式来限制模型的输出,提高可靠性。选择文本、函数调用或仅函数本身。
此外,谷歌将发布下一代文本嵌入模型,其性能优于同类模型。从今天开始,开发者将能够通过 Gemini API 访问下一代文本嵌入模型。这个新模型,text-embedding-004(在 Vertex AI 中为 text-embedding-preview-0409),在 MTEB 基准测试中实现了更强的检索性能,并且超越了具有可比维度的现有模型。
在 MTEB 基准测试中,使用 256 dims 输出的 Text-embedding-004(又名 Gecko)优于所有较大的 768 dims 输出模型
不过,需要注意的是,Gemini 1.5 Pro 对于没有访问 Vertex AI 和 AI Studio 权限的人来说是不可用的。目前,大多数人通过 Gemini 聊天机器人来接触 Gemini 语言模型。Gemini Ultra 驱动了 Gemini Advanced 聊天机器人,虽然它功能强大,也能理解长命令,但它的速度不如 Gemini 1.5 Pro。
三大开源工具
在 2024 年的 Google Cloud Next 大会上,该公司推出多个开源工具,主要用于支持生成式 AI 项目和基础设施。其一是 Max Diffusion,它是各种扩散模型参考实现的集合,可在 XLA(加速线性代数)设备上运行。
GitHub 地址:https://github.com/google/maxdiffusion
其二是 Jetstream,一个运行生成式 AI 模型的新引擎。目前,JetStream 只支持 TPU,未来可能会兼容 GPU。谷歌声称,JetStream 可为谷歌自己的 Gemma 7B 和 Meta 的 Llama 2 等模型提供高达 3 倍的性价比。
GitHub 地址:https://github.com/google/JetStream
第三个是 MaxTest,这是一个针对云中的 TPUs 和 Nvidia GPUs 的文本生成 AI 模型的集合。MaxText 现在包括 Gemma 7B、OpenAI 的 GPT-3、Llama 2 和来自 AI 初创公司 Mistral 的模型,谷歌表示所有这些模型都可以根据开发人员的需求进行定制和微调。
GitHub 地址:https://github.com/google/maxtext
首款自研 Arm 处理器 Axion
谷歌云宣布推出其首款自主研发的 Arm 处理器,名为 Axion。其基于 Arm 的 Neoverse 2,专为数据中心设计。谷歌表示其 Axion 实例的性能比其他竞争对手如 AWS 和微软的基于 Arm 的实例高出 30%,与相应的基于 X86 的实例相比,性能提高了最多 50%,能效提高了 60%。
谷歌在周二的发布会上强调,由于 Axion 建立在一个开放的基础上,谷歌云的客户将能够将他们现有的 Arm 工作负载带到谷歌云,而无需任何修改。
不过,目前谷歌还没有发布对此进行详细介绍的内容。
代码补全、生成利器 ——CodeGemma
CodeGemma 以 Gemma 模型为基础,为社区带来了强大而轻量级的编码功能。该模型可分为专门处理代码补全和代码生成任务的 7B 预训练变体、用于代码聊天和指令跟随的 7B 指令调优变体、以及在本地计算机上运行快速代码补全的 2B 预训练变体。
CodeGemma 具有以下几大优势:
- 智能代码补全和生成:补全行、函数,甚至生成整个代码块,无论你是在本地还是云上工作;
- 更高准确性:CodeGemma 主要使用来自网络文档、数学和代码的 5000 亿 token 的英语语言数据进行训练,生成的代码不仅语法更正确,语义也更有意义,有助于减少错误和 debug 时间;
- 多语言能力:支持 Python、JavaScript、Java 和其他流行编程语言;
- 简化工作流程:将 CodeGemma 集成到你的开发环境中,以减少编写的样板代码,并更快地编写重要、有趣且差异化的代码。
CodeGemma 与其他主流代码大模型的一些比较结果如下图所示:
CodeGemma 7B 模型与 Gemma 7B 模型在 GSM8K、MATH 等数据集上的比较结果。
论文地址:https://storage.googleapis.com/deepmind-media/gemma/codegemma_report.pdf
开放语言模型 ——RecurrentGemma
Google DeepMind 还发布了一系列开放权重语言模型 ——RecurrentGemma。RecurrentGemma 基于 Griffin 架构,通过将全局注意力替换为局部注意力和线性循环(linear recurrences)的混合,在生成长序列时实现快速推理。
技术报告:https://storage.googleapis.com/deepmind-media/gemma/recurrentgemma-report.pdf
RecurrentGemma-2B 在下游任务上实现了卓越的性能,可与 Gemma-2B(transformer 架构)媲美。
同时,RecurrentGemma-2B 在推理过程中实现了更高的吞吐量,尤其是在长序列上。
视频编辑工具 ——Google Vids
Google Vids 是一款 AI 视频创建工具,是 Google Workspace 中添加的新功能。
谷歌表示,借助 Google Vids,用户可以与文档和表格等其他 Workspace 工具一起制作视频,并且可与同事实时协作。
企业专用代码助手 ——Gemini Code Assist
Gemini Code Assist 是一款面向企业的 AI 代码完成和辅助工具, 对标 GitHub Copilot Enterprise。Code Assist 将通过 VS Code 和 JetBrains 等流行编辑器以插件的形式提供。
图源:https://techcrunch.com/2024/04/09/google-launches-code-assist-its-latest-challenger-to-githubs-copilot/
Code Assist 由 Gemini 1.5 Pro 提供支持。Gemini 1.5 Pro 拥有百万 token 的上下文窗口,这使得谷歌的工具能够比竞争对手引入更多的上下文。谷歌表示,这意味着 Code Assist 能够提供更准确的代码建议,并具备推理和更改大段代码的能力。
谷歌表示:「Code Assist 使客户能够对整个代码库进行大规模更改,从而实现以前不可能实现的人工智能辅助代码转换。」
智能体构建器 ——Vertex AI
AI 智能体是今年一个热门的行业发展方向。谷歌现在宣布推出一款帮助企业构建 AI 智能体的新工具 ——Vertex AI Agent Builder。
谷歌云首席执行官 Thomas Kurian 表示:「Vertex AI Agent Builder 使人们能够非常轻松、快速地构建和部署可用于生产的、由人工智能驱动的生成式对话智能体,并且能够以指导人类的方式指导智能体,以提高模型生成结果的质量和正确性。」
参考链接:
https://techcrunch.com/2024/04/09/google-open-sources-tools-to-support-ai-model-development/
#android手机跑大模型
安卓手机上跑15亿参数大模型,12秒不到就推理完了
生成式 AI 上端侧,要用真正的技术。 早晚会有这一天,但它还是比想象来得早了一些:大模型在手机上运行的预言被实现了。
上个月的计算机视觉学术顶会 CVPR 上,生成式 AI 成了重要方向,高通会议中展示了一把未来有望成为「主流」的 AI 应用:用手机跑大模型 AI 画图。
CVPR 是 AI 领域最负盛名的重要会议,我们曾在其中见证过人工智能的几次重要突破,今年在获奖和入围的论文中,既有通用大模型,也有 AI 画图的研究,可谓一下进入了生成式 AI 的新时代。
在 CVPR 2023 上,高通共有八篇论文被主会议收录,并行的展示覆盖生成式 AI、计算机视觉、XR 和自动驾驶汽车等领域的理论创新,以及应用方向。
在这场最先进技术的碰撞中,有不少令人期待的未来图景。
15 亿大模型,手机 12 秒跑完
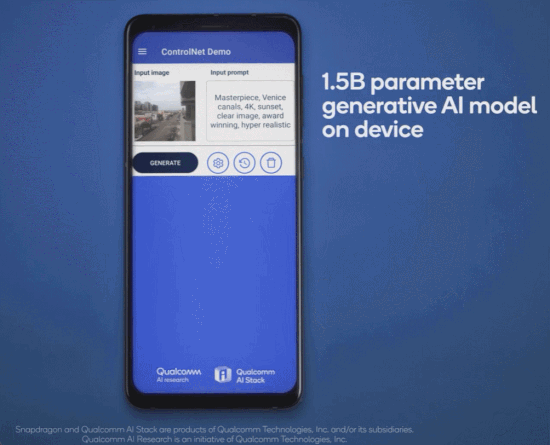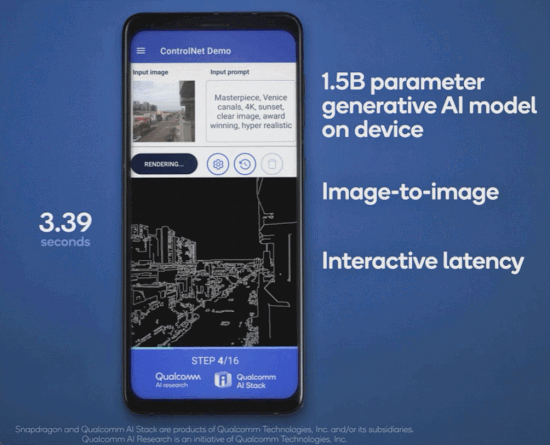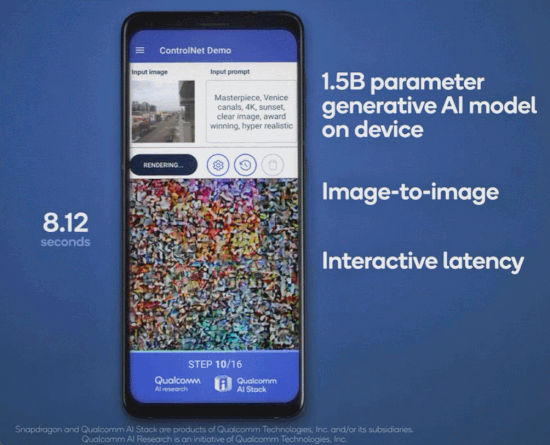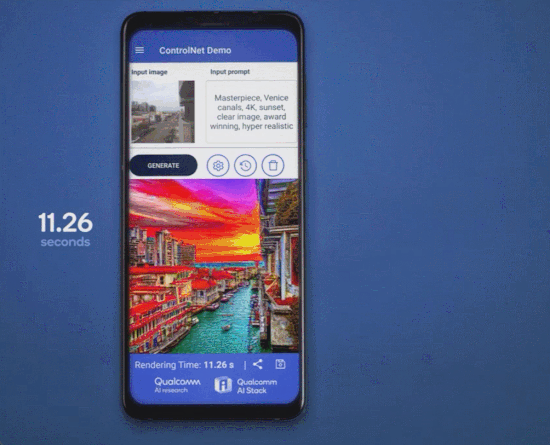
几个月前,高通就曾在巴塞罗那 MWC 通信展上玩了一把手机跑 Stable Diffusion。此次对于终端侧生成式 AI,高通首先展示了完全在安卓手机上运行 ControlNet 图像生成图像模型,并实现了速度「全球最快」。
用时是多少呢?不到 12 秒。要知道,ControlNet 拥有 15 亿参数,而二月份高通演示在手机上运行 10 亿参数的 Stable Diffusion,当时还花了 15 秒左右。
这让人不得不感叹,终端侧的生成式 AI 能力又进化了。
作为一种生成式 AI 绘画解决方案,ControlNet 被认为是扩散模型中的大杀器,它通过额外输入控制预训练大模型如 Stable Diffusion,可以精细地设定生成图像的各种细节。先输入一张参考图,然后根据输入的 prompt 进行预处理,就能对生成的图像进行精准控制。
此次在高通 AI Research 的展示中,普通安卓手机仅用 11.26 秒便可以运行 ControlNet 生成一张图片,并且无需访问任何云端,完全本地化,交互式体验良好且运行非常高效。下面是一个动图演示:
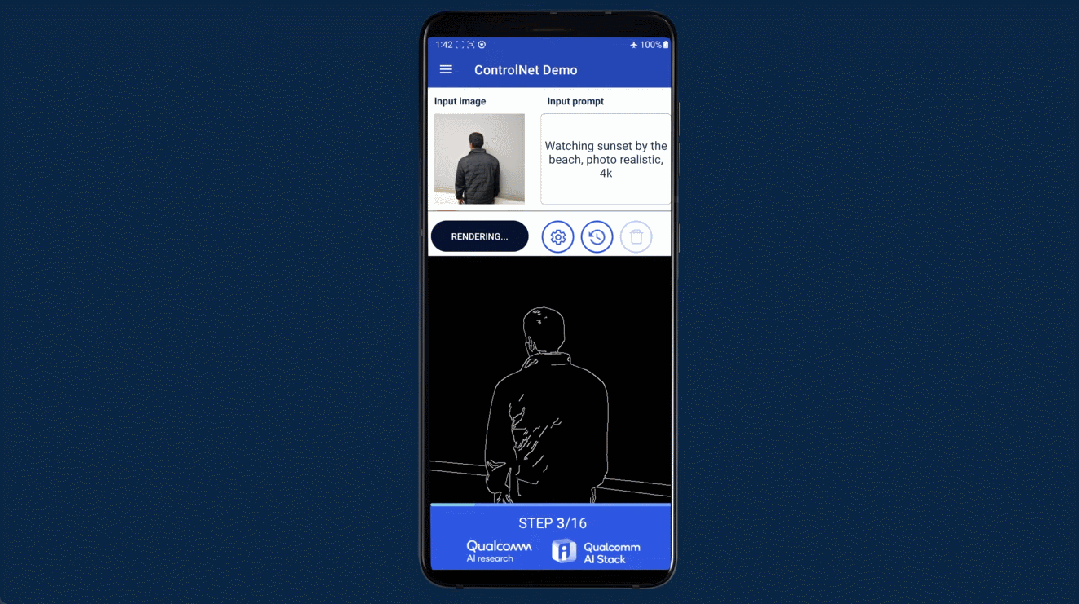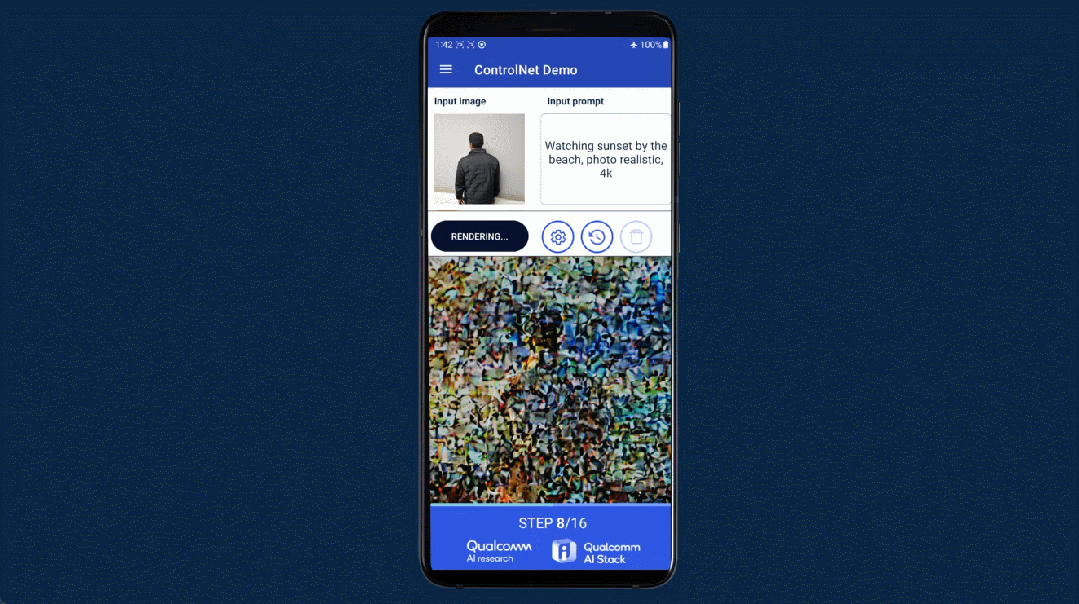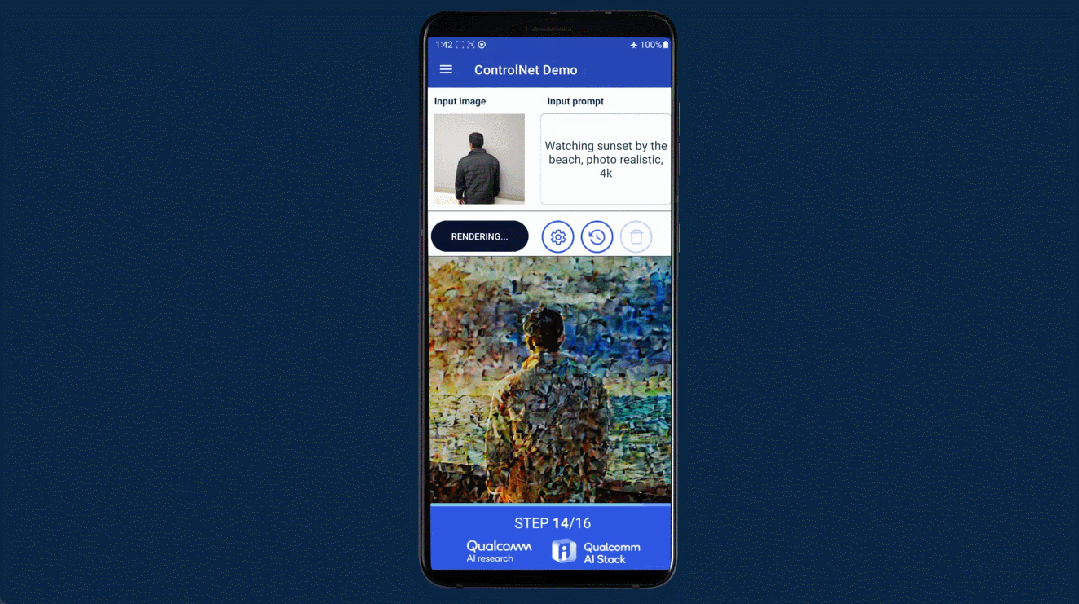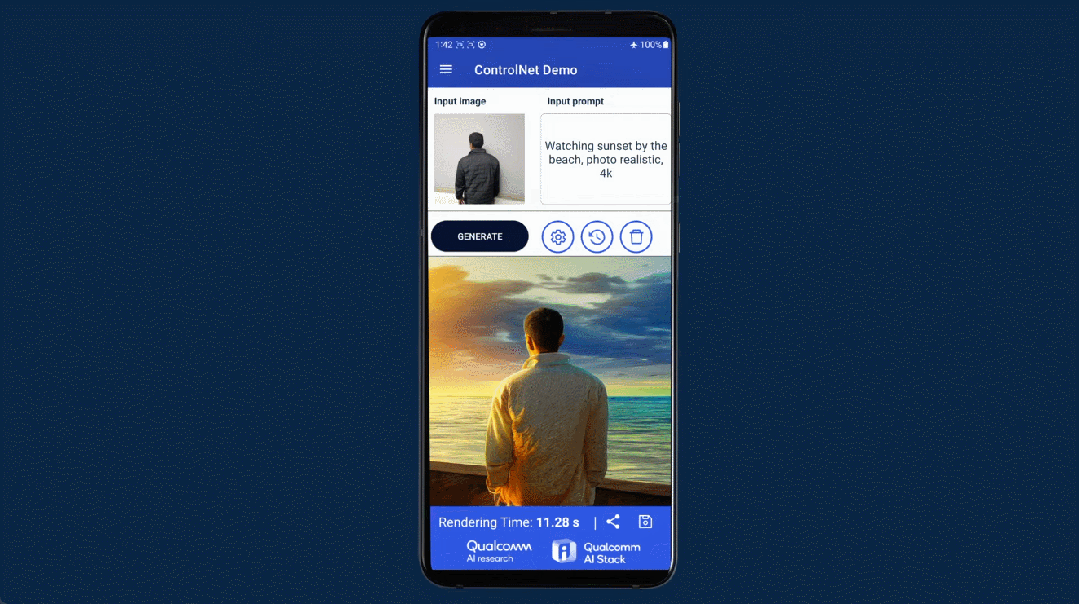
我们知道,AI 画图的教程里通常会有对计算机配置的建议,在 ControlNet 上训练需要 16G 显存的 GPU,而推理用 M1 芯片需要 5 到 10 分钟,高通却能让手机做到效率更高,这是如何实现的呢?
高通此次对 ControlNet 模型架构进行了软硬件全栈式 AI 优化,以低功耗、低延迟地实现高质量图像生成。其中用到的关键 AI 工具和软硬件包括了高通 AI 模型增效工具包(AIMET)、高通 AI 引擎和高通 AI 软件栈。我们一一来看。

首先是 AIMET,它是高通创新中心推出的端侧 AI 模型效率工具包,能够提供模型量化和压缩服务,通过量化感知训练,将浮点运算模型转化为整数运算模型。此处高通利用 AIMET 及 Qualcomm AI Studio 完成 ControlNet 模型的 INT8 量化压缩,节省更多功耗,提升运行效率。
其次是高通 AI 引擎,它是高通终端侧 AI 优势的核心,采用异构计算机构,包括高通 Hexagon 处理器、Adreno GPU 和 Kryo CPU。目前高通第二代骁龙 8 搭载了迄今最快、最先进的高通 AI 引擎。ControlNet 正是在第二代骁龙 8 的高通 Hexagon 处理器上,完成了 AI 加速。
还有高通 AI 软件栈负责应用的构建、优化和部署。在跑 ControlNet 时,高通 AI 引擎 Direct 框架基于 Hexagon 处理器的硬件架构和内存层级进行运算排序,提升性能并最小化内存溢出,降低运行时延和功耗。

这么一套集 AI 模型压缩工具、硬件和软件框架于一体的全栈式优化下来,在手机上十几秒跑大模型的不可能变成了可能。
接近落地,可以展示
除了给 AI 绘画做移动版优化,高通还在数字人、神经网络视频编解码等其他技术方向进一步探索 AI 能力的延展。
在 CVPR 上,利用基于视觉的大语言模型(LLM),高通打造了一个「数字健身教练」,它能够与用户实时互动,像真人教练一样给予鼓励,还能纠正并帮助达成自己的健身目标。既然是大模型驱动,AI 教练实现了极强的互动性,看起来健身私教要开始焦虑了。

在技术上,数字健身教练将用户的运动视频流交给动作识别模型进行处理,根据识别的动作提供提示并反馈给大模型。然后健身教练通过一个文本生成语音的数字化身,将 AI 的答复反馈回用户。
得益于大模型的能力,数字化身能够实时、不间断地为用户提供相关的健身反馈,比如「你的形体看起来棒极了」、「你的双臂应与肩膀同宽」。
现在看起来和 AI 训练就不能偷懒了,它会对用户的健身互动进行评估,给出你的耐力、强度和形体分数,还告诉完成了多少组动作。同时也会给用户提出相关建议。

与此同时,在神经网络视频编码这一技术方向,高通又实现一个「全球首次」。同样是在手机端,高通首创了 1080p 的视频编码和解码过程。
对于神经网络编解码而言,它可以针对特定视频需求进行定制,并运行在通用 AI 硬件上。在计算能力有限的终端设备上实现高分辨率(如 1080p、2k 等),则要借助 AI 算法的创新。
高通全新设计了高效的神经网络视频帧间压缩架构,在搭载骁龙芯片的手机设备上,实现了 1080p 的视频编解码,视频解码速率也来到了每秒 35 帧上下,并且能够保留丰富的视觉结构和复杂动作。

看起来,移动端生成式 AI、神经视觉编码领域的很多技术已接近应用层,落地的速度追上了 GPT 系列更新的速度。高通在做的事,解决了生成式 AI 面临的大问题。
生成式 AI 的未来在端侧
我们知道,生成式 AI 有重塑所有行业的潜力,人工智能正在经历自己的闪耀时刻,问题在于:生成式 AI 虽然更聪明,但也更耗费算力。
有研究表示,每次基于生成式 AI 的网络搜索查询(query),其成本是传统搜索的 10 倍。全球每天都有超过 100 亿次搜索请求,而且,移动端的搜索占比超过了 60%。
除了要买更多 GPU,我们更要考虑的是如何能让大模型跑在手机上 —— 毕竟大家每天在用的都是端侧设备。
对此,高通已有一个整体的规划。今年 4 月,高通通过介绍「混合 AI」的概念,提出了大模型等 AI 任务处理在云端和终端共同进行的范式。
所谓混合 AI,是指充分利用边缘侧终端算力支持生成式 AI 应用的方式,相比仅在云端运行的 AI,前者能够带来高性能、个性化且更安全的体验。
在其愿景下,我们根据 AI 模型和查询需求的复杂度等因素,选择不同方式在云端和终端侧之间分配负载:如果模型、提示或生成内容的长度小于某个限定值,且精度足够,推理就可以完全在终端侧进行;如果任务相对复杂,则可以部分依靠云端模型;如果需要更多实时内容,模型也可以接入互联网获取信息。

在未来,不同的生成式 AI 用不同分流方式的混合 AI 架构,AI 也能在此基础上持续演进:
- 大量生成式 AI 的应用,比如图像生成或文本创作,需求 AI 能够进行实时响应。在这种任务上,终端可通过运行不太复杂的推理完成大部分任务。
- 在终端设备充当「感知器官」的任务中,终端负责初步处理任务,云端运行大模型将生成的内容发回端侧,这种操作节省了算力需求和带宽。
- 终端和云端的 AI 计算也可以协同工作来处理 AI 负载。在大模型的工作过程中,每次推理生成的标记(token)都需要读取全部参数才能完成,使用闲置算力通过共享参数来推测性并行运行大语言模型,可以提升性能并降低能耗。
最后,混合 AI 还支持模型在终端侧和云端同时运行,也就是在终端侧运行轻量版模型时,在云端并行处理完整模型的多个 token,并在需要时更正终端侧的处理结果。
混合 AI 覆盖的边缘终端包括智能手机、汽车、个人电脑和物联网终端设备,或许会成为未来生成式 AI 应用的标准。
但如何做到混合 AI ?对此,必须对 AI 的全栈进行优化。在生成式 AI 出现以前,高通就在推动 AI 处理向边缘进行转移。很多的日常功能,都是利用终端侧 AI 进行支持的,如暗光拍摄、降噪和人脸解锁。
如今,高通已构建起业界领先的硬件和软件解决方案,从端侧芯片上的高通 AI 引擎,云端专用芯片,到将其统一在一起的异构计算机制,在运行 AI 负载时,高通现在已可以充分利用硬件和软件来加速终端侧 AI 的推理速度。
而在部署时,利用高通 AI 软件栈,开发者可以充分发挥高通 AI 引擎性能,并实现多端部署,模型构建一次,就可以应用到多种不同硬件上。

在高通的业务中,低功耗、高性能的 AI 已经形成了横跨智能手机、汽车、XR、PC 和企业级 AI 等领域的庞大终端 AI 生态系统。从拍照,语音助手,到增强 5G 信号的黑科技,持续利用先进 AI 技术,让这家公司保持了市场领先的地位。
在这背后,是高通 AI Research 对 AI 研究超过 15 年的持续投入。高通一直致力于 AI 基础技术的研究,从感知、推理再到认知,我们见证了终端 AI 技术的不断拓展。而在这个过程中,由高通发表的 AI 论文也逐渐影响了整个行业。
仅在生成式 AI 上,最初高通探索了生成式模型的压缩方式,并进一步提升了生成痕迹(Artifact)的感知效果,其利用 VAE 技术创建的视频和语音编解码器,将模型规模控制在了 1 亿参数以下。高通还将生成式 AI 理念延伸到无线领域来替代信道模型,提高了手机通信的效率。
CVPR 2023 上展示的技术,是高通生成式 AI 布局的重要一环。随着端侧 AI 计算能力的持续优化,混合 AI 的潜力将会进一步被释放。预计在未来几个月,高通还要在手机上部署超过 100 亿参数的大模型。
生成式 AI 可以打造全新体验,变革生产力水平,高通在边缘侧以低功耗运行生成式 AI 的独特专长,让生成式 AI 具有了融入人们日常生活的可行性。这些能力将会跟随全球出货的数十亿块芯片,很快进入到人们的手中。
在本周上海举行的世界人工智能大会 WAIC 上,高通将会有多位高管参与演讲,并有望在现场展示移动端运行 Stable Diffusion、ControlNet 等能力,让来看展的人可以近距离接触一下未来。
#回归LLM
「任何认为自动回归式 LLM 已经接近人类水平的 AI,或者仅仅需要扩大规模就能达到人类水平的人,都必须读一读这个。AR-LLM 的推理和规划能力非常有限,要解决这个问题,并不是把它们变大、用更多数据进行训练就能解决的。」
一直以来,图灵奖得主 Yann LeCun 就是 LLM 的「质疑者」,而自回归模型是 GPT 系列 LLM 模型所依赖的学习范式。他不止一次公开表达过对自回归和 LLM 的批评,并产出了不少金句,比如:
「从现在起 5 年内,没有哪个头脑正常的人会使用自回归模型。」
「自回归生成模型弱爆了!(Auto-Regressive Generative Models suck!)」
「LLM 对世界的理解非常肤浅。」
让 LeCun 近日再次发出疾呼的,是两篇新发布的论文:

「LLM 真的能像文献中所说的那样自我批判(并迭代改进)其解决方案吗?我们小组的两篇新论文在推理 (https://arxiv.org/abs/2310.12397) 和规划 (https://arxiv.org/abs/2310.08118) 任务中对这些说法进行了调查(并提出了质疑)。」
看起来,这两篇关于调查 GPT-4 的验证和自我批判能力的论文的主题引起了很多人的共鸣。
论文作者表示,他们同样认为 LLM 是了不起的「创意生成器」(无论是语言形式还是代码形式),只是它们无法保证自己的规划 / 推理能力。因此,它们最好在 LLM-Modulo 环境中使用(环路中要么有一个可靠的推理者,要么有一个人类专家)。自我批判需要验证,而验证是推理的一种形式(因此对所有关于 LLM 自我批判能力的说法都感到惊讶)。
同时,质疑的声音也是存在的:「卷积网络的推理能力更加有限,但这并没有阻止 AlphaZero 的工作出现。这都是关于推理过程和建立的 (RL) 反馈循环。我认为模型能力可以进行极其深入的推理(例如研究级数学)。」

对此,LeCun 的想法是:「AlphaZero「确实」执行规划。这是通过蒙特卡洛树搜索完成的,使用卷积网络提出好的动作,并使用另一个卷积网络来评估位置。探索这棵树所花费的时间可能是无限的,这就是推理和规划。」
在未来的一段时间内,自回归 LLM 是否具备推理和规划能力的话题或许都不会有定论。
接下来,我们可以先看看这两篇新论文讲了什么。
论文 1:GPT-4 Doesn’t Know It’s Wrong: An Analysis of Iterative Prompting for Reasoning Problems
第一篇论文引发了研究者对最先进的 LLM 具有自我批判能力的质疑,包括 GPT-4 在内。
论文地址:https://arxiv.org/pdf/2310.12397.pdf
接下来我们看看论文简介。
人们对大型语言模型(LLM)的推理能力一直存在相当大的分歧,最初,研究者乐观的认为 LLM 的推理能力随着模型规模的扩大会自动出现,然而,随着更多失败案例的出现,人们的期望不再那么强烈。之后,研究者普遍认为 LLM 具有自我批判( self-critique )的能力,并以迭代的方式改进 LLM 的解决方案,这一观点被广泛传播。
然而事实真的是这样吗?
来自亚利桑那州立大学的研究者在新的研究中检验了 LLM 的推理能力。具体而言,他们重点研究了迭代提示(iterative prompting)在图着色问题(是最著名的 NP - 完全问题之一)中的有效性。
该研究表明(i)LLM 不擅长解决图着色实例(ii)LLM 不擅长验证解决方案,因此在迭代模式下无效。从而,本文的结果引发了人们对最先进的 LLM 自我批判能力的质疑。
论文给出了一些实验结果,例如,在直接模式下,LLM 在解决图着色实例方面非常糟糕,此外,研究还发现 LLM 并不擅长验证解决方案。然而更糟糕的是,系统无法识别正确的颜色,最终得到错误的颜色。
如下图是对图着色问题的评估,在该设置下,GPT-4 可以以独立和自我批判的模式猜测颜色。在自我批判回路之外还有一个外部声音验证器。

结果表明 GPT4 在猜测颜色方面的准确率低于 20%,更令人惊讶的是,自我批判模式(下图第二栏)的准确率最低。本文还研究了相关问题:如果外部声音验证器对 GPT-4 猜测的颜色提供可证明正确的批判,GPT-4 是否会改进其解决方案。在这种情况下,反向提示确实可以提高性能。

即使 GPT-4 偶然猜出了一个有效的颜色,它的自我批判可能会让它产生幻觉,认为不存在违规行为。

最后,作者给出总结,对于图着色问题:
- 自我批判实际上会损害 LLM 的性能,因为 GPT-4 在验证方面很糟糕;
- 来自外部验证器的反馈确实能提高 LLM 的性能。
论文 2:Can Large Language Models Really Improve by Self-critiquing Their Own Plans?
在论文《Can Large Language Models Really Improve by Self-critiquing Their Own Plans?》中,研究团队探究了 LLM 在规划(planning)的情境下自我验证 / 批判的能力。
这篇论文对 LLM 批判自身输出结果的能力进行了系统研究,特别是在经典规划问题的背景下。虽然最近的研究对 LLM 的自我批判潜力持乐观态度,尤其是在迭代环境中,但这项研究却提出了不同的观点。
论文地址:https://arxiv.org/abs/2310.08118
令人意外的是,研究结果表明,自我批判会降低规划生成的性能,特别是与具有外部验证器和 LLM 验证器的系统相比。LLM 会产生大量错误信息,从而损害系统的可靠性。
研究者在经典 AI 规划域 Blocksworld 上进行的实证评估突出表明,在规划问题中,LLM 的自我批判功能并不有效。验证器可能会产生大量错误,这对整个系统的可靠性不利,尤其是在规划的正确性至关重要的领域。
有趣的是,反馈的性质(二进制或详细反馈)对规划生成性能没有明显影响,这表明核心问题在于 LLM 的二进制验证能力,而不是反馈的粒度。
如下图所示,该研究的评估架构包括 2 个 LLM—— 生成器 LLM + 验证器 LLM。对于给定的实例,生成器 LLM 负责生成候选规划,而验证器 LLM 决定其正确性。如果发现规划不正确,验证器会提供反馈,给出其错误的原因。然后,该反馈被传输到生成器 LLM 中,并 prompt 生成器 LLM 生成新的候选规划。该研究所有实验均采用 GPT-4 作为默认 LLM。

该研究在 Blocksworld 上对几种规划生成方法进行了实验和比较。具体来说,该研究生成了 100 个随机实例,用于对各种方法进行评估。为了对最终 LLM 规划的正确性进行真实评估,该研究采用了外部验证器 VAL。
如表 1 所示,LLM+LLM backprompt 方法在准确性方面略优于非 backprompt 方法。

在 100 个实例中,验证器准确识别了 61 个(61%)。

下表显示了 LLM 在接受不同级别反馈(包括没有反馈)时的表现。

#LLM360
开源模型正展现着它们蓬勃的生命力,不仅数量激增,性能更是愈发优秀。图灵奖获得者 Yann LeCun 也发出了这样的感叹:「开源人工智能模型正走在超越专有模型的路上。」我们需要更全面和深入地共享。全方位、无死角的开源,让大模型实现真正的透明
专有模型在技术性能和创新能力上展现了非凡的力量,但是它们不开源的性质成为 LLM 发展的阻碍。一些开源模型虽然为从业者和研究者提供了多样化的选择,但大多数只公开了最终的模型权重或推理代码,越来越多的技术报告将其范围限制在顶层设计和表面统计之内。这种闭源的策略不仅限制了开源模型的发展,而且还在很大程度上阻碍了整个 LLM 研究领域的进步。
这意味着,这些模型需要更全面和深入地共享,包括训练数据、算法细节、实现挑战以及性能评估的细节。
Cerebras、Petuum 和 MBZUAI 等的研究者们共同提出了 LLM360。这是一项全面开源 LLM 的倡议,主张向社区提供与 LLM 训练相关的一切,包含训练代码和数据、模型检查点以及中间结果等。LLM360 的目标是让 LLM 训练过程透明化,使每个人都能复现,从而推动开放和协作式的人工智能研究的发展。
- 论文地址:https://arxiv.org/pdf/2312.06550.pdf
- 项目网页:https://www.llm360.ai/
- 博客:https://www.llm360.ai/blog/introducing-llm360-fully-transparent-open-source-llms.html
研究者们制定了 LLM360 的架构,重点关注其设计原则和完全开源的理由。他们详细规定了 LLM360 框架的组成部分,包含数据集、代码和配置、模型检查点、指标等具体细节。LLM360 为当前和未来的开源模型树立了透明度的样本。
研究者在 LLM360 的开源框架下发布了两个从头开始预训练的大型语言模型:AMBER 和 CRYSTALCODER。AMBER 是基于 1.3T token 进行预训练的 7B 英语语言模型。CRYSTALCODER 是基于 1.4T token 预训练的 7B 英语和代码语言模型。在本文中,研究者们总结了这两个模型的开发细节、初步评估结果、观察结果以及从中汲取的经验和教训。值得注意的是,在发布时,AMBER 和 CRYSTALCODER 在训练过程中分别保存了 360 个和 143 个模型检查点。

接下来,就一起看看文章的具体内容吧。
LLM360 的框架
LLM360 将为 LLM 预训练过程中需要收集哪些数据和代码提供一个标准,以确保已有的工作能更好地在社区中流通、共享。它主要包含以下几个部分:

1. 训练数据集和数据处理代码
预训练数据集对大型语言模型的性能至关重要。因此,了解预训练数据集,用以评估潜在的行为问题和偏见非常重要。此外,公开的预训练数据集有助于提高 LLM 在后续微调和适应各领域时的可扩展性。最近的研究表明,在重复数据上进行训练会不成比例地降低模型最终的性能。因此,公开原始预训练数据,有助于避免在下游微调或继续在特定领域进行预训练时使用到重复的数据。综合以上原因,LLM360 倡导公开大型语言模型的原始数据集。在合适的情况中,还应公开关于数据过滤、处理和训练顺序的详细信息。
2. 训练代码、超参数与配置
训练代码、超参数和配置对 LLM 训练的性能和质量有重大影响,但并不总是公开披露。在 LLM360 中,研究者开源预训练框架的所有训练代码、训练参数以及系统配置。
3. 模型检查点
定期保存模型检查点也相当有用。它们不仅对训练过程中的故障恢复至关重要,而且对训练后的研究也很有用,这些检查点可以让后来的研究者从多个起点继续训练模型,无需从头开始训练,有助于复现和深入研究。
4. 性能指标
训练一个 LLM 往往需要花费数周至数月,训练期间的演化趋势可以提供有价值的信息。然而,目前只有亲历者才能获得训练的详细日志和中间指标,这阻碍了对 LLM 的全面研究。这些统计数据往往包含了难以察觉的关键见解。即使是对这些衡量标准进行方差计算这样的简单分析,也能揭示重要的发现。例如,GLM 的研究团队就是通过分析梯度规范行为,提出了一种有效处理损失尖峰和 NaN 损失的梯度收缩算法。
Amber
AMBER 是 LLM360 「大家庭」的第一位成员,同时发布的还有它的微调版本:AMBERCHAT 和 AMBERSAFE 。
数据及模型细节
表 2 列出了 AMBER 包含 1.26 T token 的预训练数据集的详细信息,包括数据的预处理、格式、数据混合比例,以及 AMBER 的架构细节和特定的预训练超参数。具体请在项目主页参阅 LLM360 代码库。

AMBER 采用了与 LLaMA 7B4 一致的模型架构,表 3 总结了 LLM 的详细架构配置。

在预训练过程和超参数方面,研究者们尽可能地遵循了 LLaMA 的预训练超参数。AMBER 使用 AdamW 优化器进行训练,超参数为:β₁= 0.9,β₂= 0.95。同时,研究者还发布了几个 AMBER 的微调版本:AMBERCHAT 和 AMBERSAFE 。AMBERCHAT 是基于 WizardLM 的指令训练数据集微调得出的。更多参数细节,请阅读原文。
实验及结果
研究者们采用了 Open LLM 排行榜上的四个基准数据集来评估 AMBER 的性能。如图 4 所示,在 HellaSwag 和 ARC 中, AMBER 的得分在预训练期间单调增加,而在 TruthfulQA 的得分随着训练的进行而降低。在 MMLU 数据集中, AMBER 的得分在预训练的初始阶段下降,然后开始上升。

在表 4 中,研究者将 AMBER 的模型性能与 OpenLLaMA、RedPajama-INCITE、Falcon、MPT 等类似时间段内训练出的模型进行了比较。许多模型的设计灵感都来自 LLaMA 。可以发现,AMBER 在 MMLU 的得分较为出色,但在 ARC 上的表现稍逊一筹。与其他类似模型相比,AMBER 的表现相对较强。

CRYSTALCODER
LLM360 「大家庭」的第二位成员是 CrystalCoder。
CrystalCoder 是一个基于 1.4 T token 训练的 7B 语言模型,实现了编码和语言能力之间的平衡。与大多数之前的代码 LLM 不同,CrystalCoder 是通过精心混合文本和代码数据进行训练的,以最大化在这两个领域的实用性。与 Code Llama 2 相比,CrystalCoder 的代码数据在预训练过程中较早引入。此外,研究者在 Python 和 Web 编程语言上训练了 CrystalCoder,以提高其作为编程助手的实用性。
模型架构
CrystalCoder 采用了与 LLaMA 7B 非常相似的架构,加入了最大更新参数化(muP)。除了这种特定的参数化,研究者还进行了一些修改。另外,研究者还使用 LayerNorm 代替 RMSNorm,因为 CG-1 架构支持高效计算 LayerNorm。
实验及结果
如图 6 所示,研究者在 Open LLM Leaderboard 中的四个基准数据集以及编码基准数据集上对该模型进行了基准测试。

从表 5 中可以看出,CrystalCoder 在语言任务和代码任务之间取得了很好的平衡。

ANALYSIS360
Pythia 等先前的工作表明,通过分析模型的中间检查点,可以进行深入研究。研究者希望 LLM360 还能为社区提供有用的参考和研究资源。为此,他们发布了 ANALYSIS360 项目的初始版本,这是一个对模型行为进行多方面分析的有组织存储库,包括模型特征和下游评估结果。
作为对一系列模型检查点进行分析的示例,研究者对 LLM 中的记忆化进行了初步研究。最近的研究显示,LLM 可能会记忆大部分训练数据,通过适当的提示可以提取这些数据。这种记忆化不仅存在着泄露私人训练数据方面的问题,而且如果训练数据包含重复或特殊性,还会降低 LLM 的性能。研究者发布了所有检查点和数据,因此他们可以对整个训练阶段的记忆化进行全面分析。
以下为本文所采用的记忆化得分方法,该得分表示在长度为 k 的提示后续长度为 l 的 token 的准确性。具体记忆化得分设置,请参阅原文。

图 7 展示了 10 个选定检查点的记忆化分数分布情况。

研究者根据所选检查点对数据块进行分组,并在图 8 中绘制每个检查点的每个数据块组的记忆化分数。他们发现 AMBER 检查点对最新数据的记忆化程度超过之前的数据。此外对于每个数据块,记忆化分数在额外训练后会略有下降,但之后会持续上升。

图 9 展示了序列之间在记忆化得分和可提取 k 值的相关性。可见,检查点之间存在很强的相关性。

总结
研究者总结了对 AMBER 和 CRYSTALCODER 的观察结果和一些启示。他们表示,预训练是一项计算量巨大的任务,许多学术实验室或小型机构都无力承担。他们希望 LLM360 能够提供全面的知识,让用户了解 LLM 预训练过程中发生的情况,而无需亲自动手。
#llm_unlearn
随着大型语言模型(LLM)的发展,从业者面临更多挑战。如何避免 LLM 产生有害回复?如何快速删除训练数据中的版权保护内容?如何减少 LLM 幻觉(hallucinations,即错误事实)? 如何在数据政策更改后快速迭代 LLM?这些问题在人工智能法律和道德的合规要求日益成熟的大趋势下,对于 LLM 的安全可信部署至关重要。如何让 LLM “忘记” 学到的有害内容?用RLHF 2%的算力让LLM停止有害输出,字节提出遗忘学习
目前业界的主流解决方案为 LLM 对齐 (alignment),即通过建立对比数据(正样本和负样本)用强化学习的方式来对 LLM 进行微调 (Finetuning),也就是 RLHF (Reinforcement Learning from Human Feedback)[1] ,从而保证 LLM 输出符合人类预期和价值观。但对齐过程往往受到 (1) 数据收集;(2) 计算资源的限制。
字节跳动提出让 LLM 进行遗忘学习的方法来进行对齐。本文研究如何在 LLM 上进行 “遗忘” 操作,即忘记有害行为或遗忘学习(Machine Unlearning),作者展示了遗忘学习在三种 LLM 对齐场景上取得的明显效果:(1) 删除有害输出;(2) 移除侵权保护内容;(3) 消除大语言 LLM 幻觉。
遗忘学习有三个优势:(1) 只需负样本(有害样本),负样本比 RLHF 所需的正样本(高质量的人工手写输出)的收集简单的多(比如红队测试或用户报告);(2) 计算成本低;(3) 如果知道哪些训练样本导致 LLM 有害行为时,遗忘学习尤为有效。
作者证明,如果从业者只有较少的资源,因此优先考虑的是停止产生有害输出,而不是试图产生过于理想化的输出,遗忘学习尤为便利。尽管只有负样本,研究表明,和 RLHF 相比,只使用 2% 的计算时间下,遗忘学习仍可以获得更好的对齐性能。
- 论文地址:https://arxiv.org/abs/2310.10683
- 代码地址:https://github.com/kevinyaobytedance/llm_unlearn
使用场景
本方法可以在资源有限的情况下,最大程度发挥优势。当没预算请人员写优质样本,或计算资源不足时,应当优先停止 LLM 产生有害输出,而不是试图让其产生有益输出。
有害输出造成的损害远不是有益输出能弥补的。如果一个用户问 LLM100 个问题,他得到一个有害答案,就会失去信任,不管后来 LLM 能给多少有益答案。有害问题的预期输出可以是空格、特殊字符、无意义字符串等,总之,一定要是无害文本。
文中展示了 LLM 遗忘学习的三个成功案例:(1) 停止生成有害回复(图一);这与 RLHF 情境相似,区别是本方法目标是生成无害回复,而不是有益回复。当只有负样本时,这是能期望的最好结果。(2) LLM 使用侵权数据训练后,在作者要求下,成功删除数据,且考虑到成本因素不能重训 LLM;(3) LLM 成功忘记 “幻觉”。

图一
方法
在微调 step t,LLM 更新如下:

同 RLHF 类似,在预训练 LLM 上计算 KL 散度能更好保持 LLM 性能。
此外,所有的梯度上升和下降都只在输出(y)部分做,而不是像 RLHF 在提示 - 输出对(x, y)上。
应用场景:忘却有害内容等
本文用 PKU-SafeRLHF 数据作为遗忘数据,TruthfulQA 作为正常数据,图二显示了遗忘学习后 LLM 在忘却的有害提示上输出的有害率。文中使用的方法为 GA(梯度上升和 GA+Mismatch:梯度上升 + 随机误配)。遗忘学习后的有害率接近于零。

图二
图三显示了未见过的有害提示(未被忘却过)上的输出。即使在没有忘却过的有害提示上,LLM 的有害率也接近于零,证明 LLM 忘记的不仅仅是具体见过的样本,而是泛化到了包含有害这个概念的内容。

图三
同时 LLM 在正常样本上的性能和忘却前保持类似。
表一展示了生成的样本。可以看到在有害提示下,LLM 生成的样本都是无意义字符串,即无害输出。

表一
该方法在其他场景(如忘却侵权内容和忘却幻觉)的应用原文中有详细描述。
RLHF 比较
表二显示了该方法和 RLHF 的比较,这里 RLHF 已经用了正例,而遗忘学习的方法只有负例,所以比较一开始本方法就占劣势。但即便如此,遗忘学习也能取得和 RLHF 相似的对齐性能。

表二
图四显示了计算时间的比较,本方法只需 RLHF 2% 的计算时间。

图三
尽管只有负样本,遗忘学习的方法仍能达到和 RLHF 相似的无害率,而且只使用 2% 的算力。因此如果目标是停止输出有害输出,遗忘学习比 RLHF 更高效。
结论
该研究首次探索了 LLM 上的遗忘学习。本文的结果表明,遗忘学习是一种有希望的对齐方法,特别是当从业者没有足够的资源时。论文展示了三种情境:遗忘学习可以成功删除有害回复、删除侵权内容和消除错觉。研究表明,尽管只有负样本,遗忘学习仍可在只用 RLHF 计算时间的 2% 的情况下,获得和 RLHF 相近的对齐效果。
#LLM in a flash
苹果这项新工作将为未来 iPhone 加入大模型的能力带来无限想象力。CPU推理提升4到5倍,苹果用闪存加速大模型推理,Siri 2.0要来了?
近年来,GPT-3、OPT 和 PaLM 等大型语言模型(LLM)在广泛的 NLP 任务中表现出了强大的性能。不过,这些能力伴随着大量计算和内存推理需求,毕竟大型语言模型可能包含数千亿甚至万亿参数,使得高效加载和运行变得有挑战性,尤其是在资源有限的设备上。
当前标准的应对方案是将整个模型加载到 DRAM 中进行推理,然而这种做法严重限制了可以运行的最大模型尺寸。举个例子,70 亿参数的模型需要 14GB 以上的内存才能加载半精度浮点格式的参数,这超出了大多数边缘设备的能力。
为了解决这种局限性,苹果的研究者提出在闪存中存储模型参数,至少比 DRAM 大了一个数量级。接着在推理中,他们直接并巧妙地从闪存加载所需参数,不再需要将整个模型拟合到 DRAM 中。
这种方法基于最近的工作构建,这些工作表明 LLM 在前馈网络(FFN)层中表现出高度稀疏性,其中 OPT、Falcon 等模型的稀疏性更是超过 90%。因此,研究者利用这种稀疏性, 有选择地仅从闪存中加载具有非零输入或预测具有非零输出的参数。
论文地址:https://arxiv.org/pdf/2312.11514.pdf
具体来讲,研究者讨论了一种受硬件启发的成本模型,其中包括闪存、DRAM 和计算核心(CPU 或 GPU)。接着引入两种互补技术来最小化数据传输、最大化闪存吞吐量:
- 窗口:仅为前几个 token 加载参数,并重用最近计算的 tokens 的激活。这种滑动窗口方法减少了加载权重的 IO 请求数量;
- 行列捆绑:存储上投影和下投影层的串联行和列,以读取闪存的更大连续块。这将通过读取更大的块来增加吞吐量。
为了进一步最小化从闪存传输到 DRAM 的权重数量,研究者还设法预测 FFN 稀疏性并避免加载归零参数。结合使用窗口和稀疏性预测可以为每个推理查询仅加载 2% 的闪存 FFN 层。他们还提出了静态内存预分配,最大限度减少了 DRAM 内的传输并减少了推理延迟。
本文的闪存加载成本模型在加载更好数据与读取更大块之间取得了平衡。与 CPU 和 GPU 中的 naive 实现相比,优化该成本模型并有选择地按需加载参数的闪存策略可以运行两倍于 DRAM 容量的模型,并将推理速度分别提升 4-5 倍和 20-25 倍。

有人评价称,这项工作会让 iOS 开发更加有趣。
闪存和 LLM 推理
带宽和能量限制
虽然现代 NAND 闪存提供了高带宽和低延迟,但仍达不到 DRAM 的性能水准,尤其是在内存受限的系统中。下图 2a 说明了这些差异。
依赖 NAND 闪存的 naive 推理实现可能需要为每个前向传递重新加载整个模型,这一过程非常耗时,即使是压缩模型也需要几秒时间。此外将数据从 DRAM 传输到 CPU 或 GPU 内存需要耗费更多能量。

在 DRAM 充足的场景中,加载数据的成本有所降低,这时模型可以驻留在 DRAM 中。不过,模型的初始加载仍然耗能,尤其是在第一个 token 需要快速响应时间的情况下。本文的方法利用 LLM 中的激活稀疏性,通过有选择地读取模型权重来解决这些挑战,从而减少了时间和耗能成本。
读取吞吐量
闪存系统在大量连续读取场景下表现最佳,例如配备 2TB 闪存的 Apple MacBook Pro M2 基准测试表明,对未缓存文件进行 1GiB 线性读取的速度超过 6GiB/s。然而由于这些读取固有的多阶段性质,包括操作系统、驱动程序、中端处理器和闪存控制器,较小的随机读取无法复制这种高带宽。每个阶段都会出现延迟,从而对较小读取造成较大的影响。
为了规避这些限制,研究者提倡两种主要策略,它们可以同时使用。
第一种策略是读取较大的数据块。虽然吞吐量的增长不是线性的(较大的数据块需要较长的传输时间),但初始字节的延迟在总请求时间中所占的比例较小,从而提高了数据读取的效率。图 2b 描述了这一原理。一个与直觉相反但却有趣的观察结果是,在某些情况下,读取比需要更多的数据(但数据块较大)然后丢弃,比只读取需要的部分但数据块较小更快。
第二种策略是利用存储堆栈和闪存控制器固有的并行性来实现并行读取。研究结果表明,在标准硬件上使用多线程 32KiB 或更大的随机读取,可以实现适合稀疏 LLM 推理的吞吐量。
最大化吞吐量的关键在于权重的存储方式,因为提高平均块长度的布局可以显著提高带宽。在某些情况下,读取并随后丢弃多余的数据,而不是将数据分割成更小的、效率更低的数据块,可能是有益的。
从闪存加载
受上述挑战的启发,研究者提出了优化数据传输量和提高读取吞吐量的方法,以显著提高推理速度。本节将讨论在可用计算内存远远小于模型大小的设备上进行推理所面临的挑战。
分析该挑战,需要在闪存中存储完整的模型权重。研究者评估各种闪存加载策略的主要指标是延迟,延迟分为三个不同部分:从闪存加载的 I/O 成本、管理新加载数据的内存开销以及推理操作的计算成本。
苹果将在内存限制条件下减少延迟的解决方案分为三个战略领域,每个领域都针对延迟的特定方面:
1、减少数据负载:旨在通过加载更少的数据来减少与闪存 I/O 操作相关的延迟。


2、优化数据块大小:通过增加加载数据块的大小来提高闪存吞吐量,从而减少延迟。
以下是研究者为提高闪存读取效率而增加数据块大小所采用的策略:
- 捆绑列和行
- 基于 Co-activation 的捆绑

3、有效管理加载的数据:简化数据加载到内存后的管理,最大限度地减少开销。
虽然与访问闪存相比,在 DRAM 中传输数据的效率更高,但会产生不可忽略的成本。在为新神经元引入数据时,由于需要重写 DRAM 中的现有神经元数据,重新分配矩阵和添加新矩阵可能会导致巨大的开销。当 DRAM 中的前馈网络(FFN)有很大一部分(约 25%)需要重写时,这种代价尤其高昂。
为了解决这个问题,研究者采用了另一种内存管理策略。这包括预分配所有必要的内存,并建立相应的数据结构进行有效管理。如图 6 所示,该数据结构由指针、矩阵、偏置、已用数和 last_k_active 等元素组成:

图 6:内存管理,首先将最后一个元素复制到删除神经元,以保持内存块的连续性,然后将所需元素堆栈到最后,这样可以避免多次复制整个数据。
值得注意的是,重点并不在过程的计算方面,因为这与本文工作核心无关。这种划分使研究者能够专注于优化闪存交互和内存管理,从而在内存受限的设备上实现高效推理。
实验结果
OPT 6.7B 模型的结果
预测器。如图 3a 所示,本文的预测器能准确识别大多数激活的神经元,但偶尔也会误识数值接近于零的非激活神经元。值得注意的是,这些接近零值的假负类神经元被排除后,并不会明显改变最终输出结果。此外,如表 1 所示,这样的预测准确度水平并不会对模型在零样本任务中的表现产生不利影响。

延迟分析。当窗口大小为 5 ,每个 token 需要访问 2.4% 的前馈网络(FFN)神经元。对于 32 位模型,每次读取的数据块大小为 2dmodel × 4 字节 = 32 KiB,因为它涉及行和列的连接。在 M1 Max 上,从闪存加载每个 token 的延迟为 125 毫秒,内存管理(包括神经元的删除和添加)的延迟为 65 毫秒。因此,与内存相关的总延迟不到每个 token 190 毫秒(参见图 1)。相比之下,基线方法需要以 6.1GB/s 的速度加载 13.4GB 的数据,导致每个 token 的延迟约为 2330 毫秒。因此,与基线方法相比,本文的方法有了很大改进。
对于 GPU 机器上的 16 位模型,闪存加载时间缩短至 40.5 毫秒,内存管理时间为 40 毫秒,由于从 CPU 向 GPU 传输数据的额外开销,时间略有增加。尽管如此,基线方法的 I/O 时间仍然超过 2000 毫秒。
表 2 提供了每种方法对性能影响的详细比较。

Falcon 7B 模型的结果
延迟分析。在本文的模型中使用大小为 4 的窗口,每个 token 需要访问 3.1% 的前馈网络(FFN)神经元。在 32 位模型中,这相当于每次读取的数据块大小为 35.5 KiB(按 2dmodel ×4 字节计算)。在 M1 Max 设备上,从闪存加载这些数据所需的时间约为 161 毫秒,内存管理过程又增加了 90 毫秒,因此每个 token 的总延迟时间为 250 毫秒。相比之下,基线延迟时间约为 2330 毫秒,本文的方法大约快 9 到 10 倍。



















