
#Sin3DGen
最近有点忙 可能给忘了,贴了我只是搬运工 发这些给自己看, 还有下面不是隐藏是发布出去 ~
北京大学xxx团队联合山东大学和xxx AI Lab的研究人员,提出了首个基于单样例场景无需训练便可生成多样高质量三维场景的方法。

多样高质的三维场景生成结果
- 论文地址:https://arxiv.org/abs/2304.12670
- 项目主页:http://weiyuli.xyz/Sin3DGen/
使用人工智能辅助内容生成(AIGC)在图像生成领域涌现出大量的工作,从早期的变分自编码器(VAE),到生成对抗网络(GAN),再到最近大红大紫的扩散模型(Diffusion Model),模型的生成能力飞速提升。以 Stable Diffusion,Midjourney 等为代表的模型在生成具有高真实感图像方面取得了前所未有的成果。同时,在视频生成领域,最近也涌现出很多优秀的工作,如 Runway 公司的生成模型能够生成充满想象力的视频片段。这些应用极大降低了内容创作门槛,使得每个人都可以轻易地将自己天马行空的想法变为现实。
但是随着承载内容的媒介越来越丰富,人们渐渐不满足于图文、视频这些二维的图形图像内容。随着交互式电子游戏技术的不断发展,特别是虚拟和增强现实等应用的逐步成熟,人们越来越希望能身临其境地从三维视角与场景和物体进行互动,这带来了对三维内容生成的更大诉求。
如何快速地生成高质量且具有精细几何结构和高度真实感外观的三维内容,一直以来是计算机图形学社区研究者们重点探索的问题。通过计算机智能地进行三维内容生成,在实际生产应用中可以辅助游戏、影视制作中重要数字资产的生产,极大地减少了美术制作人员的开发时间,大幅地降低资产获取成本,并缩短整体的制作周期,也为用户带来千人千面的个性化视觉体验提供了技术可能。而对于普通用户来说,快速便捷的三维内容创作工具的出现,结合如桌面级三维打印机等应用,未来将为普通消费者的文娱生活带来更加无限的想象空间。
目前,虽然普通用户可以通过便携式相机等设备轻松地创建图像和视频等二维内容,甚至可以对三维场景进行建模扫描,但总体来说,高质量三维内容的创作往往需要有经验的专业人员使用如 3ds Max、Maya、Blender 等软件手动建模和渲染,但这些有很高的学习成本和陡峭的成长曲线。
其中一大主要原因是,三维内容的表达十分复杂,如几何模型、纹理贴图或者角色骨骼动画等。即使就几何表达而言,就可以有点云、体素和网格等多种形式。三维表达的复杂性极大地限制了后续数据采集和算法设计。
另一方面,三维数据天然具有稀缺性,数据获取的成本高昂,往往需要昂贵的设备和复杂的采集流程,且难以大量收集某种统一格式的三维数据。这使得大多数数据驱动的深度生成模型难有用武之地。
在算法层面,如何将收集到的三维数据送入计算模型,也是难以解决的问题。三维数据处理的算力开销,要比二维数据有着指数级的增长。暴力地将二维生成算法拓展到三维,即使是最先进的并行计算处理器也难以在可接受的时间内进行处理。
上述原因导致了当前三维内容生成的工作大多只局限于某一特定类别或者只能生成较低分辨率的内容,难以应用于真实的生产流程中。
为了解决上述问题,提出了首个基于单样例场景无需训练便可生成多样高质量三维场景的方法。该算法具有如下优点:
1,无需大规模的同类训练数据和长时间的训练,仅使用单个样本便可快速生成高质量三维场景;
2,使用了基于神经辐射场的 Plenoxels 作为三维表达,场景具有高真实感外观,能渲染出照片般真实的多视角图片。生成的场景也完美的保留了样本中的所有特征,如水面的反光随视角变化的效果等;
3,支持多种应用制作场景,如三维场景的编辑、尺寸重定向、场景结构类比和更换场景外观等。
方法介绍
研究人员提出了一种多尺度的渐进式生成框架,如下图所示。算法核心思想是将样本场景拆散为多个块,通过引入高斯噪声,然后以类似拼积木的方式将其重新组合成类似的新场景。
作者使用坐标映射场这种和样本异构的表达来表示生成的场景,使得高质量的生成变得可行。为了让算法的优化过程更加鲁棒,该研究还提出了一种基于值和坐标混合的优化方法。同时,为了解决三维计算的大量资源消耗问题,该研究使用了精确到近似的优化策略,使得能在没有任何训练的情况下,在分钟级的时间生成高质量的新场景。更多的技术细节请参考原始论文。

随机场景生成

通过如左侧框内的单个三维样本场景,可以快速地生成具有复杂几何结构和真实外观的新场景。该方法可以处理具有复杂拓扑结构的物体,如仙人掌,拱门和石凳等,生成的场景完美地保留了样本场景的精细几何和高质量外观。当前没有任何基于神经网络的生成模型能做到相似的质量和多样性。
高分辨率大场景生成
视频发不了
该方法能高效地生成极高分辨率的三维内容。如上所示,我们可以通过输入单个左上角分辨率为 512 x 512 x 200 的三维 “千里江山图” 的一部分,生成 1328 x 512 x 200 分辨率的 “万里江山图”,并渲染出 4096 x 1024 分辨率的二维多视角图片。
真实世界无边界场景生成

作者在真实的自然场景上也验证了所提出的生成方法。通过采用与 NeRF++ 类似的处理方法,显式的将前景和天空等背景分开后,单独对前景内容进行生成,便可在真实世界的无边界场景中生成新场景。
其他应用场景
场景编辑

使用相同的生成算法框架,通过加入人为指定限制,可以对三维场景内的物体进行删除,复制和修改等编辑操作。如图中所示,可以移除场景中的山并自动补全孔洞,复制生成三座山峰或者使山变得更大。
尺寸重定向

该方法也可以对三维物体进行拉伸或者压缩的同时,保持其局部的形状。图中绿色框线内为原始的样本场景,将一列三维火车进行拉长的同时保持住窗户的局部尺寸。
结构类比生成

和图像风格迁移类似,给定两个场景 A 和 B,我们可以创建一个拥有 A 的外观和几何特征,但是结构与 B 相似的新场景。如我们可以参考一座雪山将另一座山变为三维雪山。
更换样本场景

由于该方法对生成场景采用了异构表达,通过简单地修改其映射的样本场景,便可生成更加多样的新场景。如使用同一个生成场景映射场 S,映射不同时间或季节的场景,得到了更加丰富的生成结果。
总结
这项工作面向三维内容生成领域,首次提出了一种基于单样本的三维自然场景生成模型,尝试解决当前三维生成方法中数据需求大、算力开销多、生成质量差等问题。该工作聚焦于更普遍的、语义信息较弱的自然场景,更多的关注生成内容的多样性和质量。算法主要受传统计算机图形学中纹理图像生成相关的技术,结合近期的神经辐射场,能快速地生成高质量三维场景,并展示了多种实际应用。
未来展望
该工作有较强的通用性,不仅能结合当前的神经表达,也适用于传统的渲染管线几何表达,如多边形网格 (Mesh)。我们在关注大型数据和模型的同时,也应该不时地回顾传统的图形学工具。研究人员相信,不久的未来,在 3D AIGC 领域,传统的图形学工具结合高质量的神经表达以及强力的生成模型,将会碰撞出更绚烂的火花,进一步推进三维内容生成的质量和速度,解放人们的创造力。
#OpenShape_code
三维点云的开放世界理解,分类、检索、字幕和图像生成样样行 , OpenShape 让三维形状的开放世界理解成为可能。
输入一把摇椅和一匹马的三维形状,能得到什么?

木马和坐在椅子上的牛仔!

木推车加马?得到马车和电动马;香蕉加帆船?得到香蕉帆船;鸡蛋加躺椅?得到鸡蛋椅。

来自UCSD、上海交大、高通团队的研究者提出最新三维表示模型OpenShape,让三维形状的开放世界理解成为可能。
- 论文地址:https://arxiv.org/pdf/2305.10764.pdf
- 项目主页:https://colin97.github.io/OpenShape/
- 交互demo: https://huggingface.co/spaces/OpenShape/openshape-demo
- 代码地址:https://github.com/Colin97/OpenShape_code
通过在多模态数据(点云 - 文本 - 图像)上学习三维点云的原生编码器,OpenShape 构建了一个三维形状的表示空间,并与 CLIP 的文本和图像空间进行了对齐。得益于大规模、多样的三维预训练,OpenShape 首次实现三维形状的开放世界理解,支持零样本三维形状分类、多模态三维形状检索(文本 / 图像 / 点云输入)、三维点云的字幕生成和基于三维点云的图像生成等跨模态任务。
三维形状零样本分类

OpenShape 支持零样本三维形状分类。无需额外训练或微调,OpenShape 在常用的 ModelNet40 基准(包含 40 个常见类别)上达到了 85.3% 的 top1 准确率,超过现有零样本方法 24 个百分点,并首次实现与部分全监督方法相当的性能。
OpenShape 在 ModelNet40 上的 top3 和 top5 准确率则分别达到了 96.5% 和 98.0%。

与现有方法主要局限于少数常见物体类别不同,OpenShape 能够对广泛的开放世界类别进行分类。在 Objaverse-LVIS 基准上(包含 1156 个物体类别),OpenShape 实现了 46.8% 的 top1 准确率,远超现有零样本方法最高只有 6.2% 的准确率。这些结果表明 OpenShape 具备有效识别开放世界三维形状的能力。
多模态三维形状检索
通过 OpenShape 的多模态表示,用户可以对图像、文本或点云输入进行三维形状检索。研究通过计算输入表示和三维形状表示之间的余弦相似度并查找 kNN,来从集成数据集中检索三维形状。

上图展示了输入图片和两个检索到的三维形状。

上图展示了输入文本和检索到的三维形状。OpenShape 学到了广泛的视觉和语义概念,从而支持细粒度的子类别(前两行)和属性控制(后两行,如颜色,形状,风格及其组合)。

上图展示了输入的三维点云和两个检索到的三维形状。

上图将两个三维形状作为输入,并使用它们的 OpenShape 表示来检索同时最接近两个输入的三维形状。检索到的形状巧妙地结合了来自两个输入形状的语义和几何元素。
基于三维形状的文本和图像生成
由于 OpenShape 的三维形状表示与 CLIP 的图像和文本表示空间进行了对齐,因此它们可以与很多基于 CLIP 的衍生模型进行结合,从而支持各种跨模态应用。

通过与现成的图像字幕模型(ClipCap)结合,OpenShape 实现了三维点云的字幕生成。

通过与现成的文本到图像的扩散模型(Stable unCLIP)结合,OpenShape 实现了基于三维点云的图像生成(支持可选的文本提示)。

训练细节
基于对比学习的多模态表示对齐:OpenShape 训练了一个三维原生编码器,它将三维点云作为输入,来提取三维形状的表示。继之前的工作,研究利用多模态对比学习来与 CLIP 的图像和文本表示空间进行对齐。与之前的工作不同,OpenShape 旨在学习更通用和可扩展的联合表示空间。研究的重点主要在于扩大三维表示学习的规模和应对相应的挑战,从而真正实现开放世界下的三维形状理解。

集成多个三维形状数据集:由于训练数据的规模和多样性在学习大规模三维形状表示中起着至关重要的作用,因此研究集成了四个当前最大的公开三维数据集进行训练。如下图所示,研究的训练数据包含了 87.6 万个训练形状。在这四个数据集中,ShapeNetCore、3D-FUTURE 和 ABO 包含经过人工验证的高质量三维形状,但仅涵盖有限数量的形状和数十个类别。Objaverse 数据集是最近发布的三维数据集,包含显著更多的三维形状并涵盖更多样的物体类别。然而 Objaverse 中的形状主要由网络用户上传,未经人工验证,因此质量参差不齐,分布极不平衡,需要进一步处理。

文本过滤和丰富:研究发现仅在三维形状和二维图像之间应用对比学习不足以推动三维形状和文本空间的对齐,即使在对大规模数据集进行训练时也是如此。研究推测这是由于 CLIP 的语言和图像表示空间中固有的领域差距引起的。因此,研究需要显式地将三维形状与文本进行对齐。然而来自原始三维数据集的文本标注通常面临着缺失、错误、或内容粗略单一等问题。为此,本文提出了三种策略来对文本进行过滤和丰富,从而提高文本标注的质量:使用 GPT-4 对文本进行过滤、对三维模型的二维渲染图进行字幕生成和图像检索。



在每个示例中,左侧部分展示了缩略图、原始形状名称和 GPT-4 的过滤结果。右上部分展示来来自两个字幕模型的图像字幕,而右下部分显示检索到的图像及其相应的文本。
扩大三维骨干网络。由于先前关于三维点云学习的工作主要针对像 ShapeNet 这样的小规模三维数据集, 这些骨干网络可能不能直接适用于我们的大规模的三维训练,需要相应地扩大骨干网络的规模。研究发现在不同大小的数据集上进行训练,不同的三维骨干网络表现出不同的行为和可扩展性。其中基于 Transformer 的 PointBERT 和基于三维卷积的 SparseConv 表现出更强大的性能和可扩展性,因而选择他们作为三维骨干网络。

困难负例挖掘:该研究的集成数据集表现出高度的类别不平衡。一些常见的类别,比如建筑,可能占据了数万个形状,而许多其他类别,比如海象和钱包,只有几十个甚至更少的形状,代表性不足。因此,当随机构建批次进行对比学习时,来自两个容易混淆的类别(例如苹果和樱桃)的形状不太可能出现在同一批次中被对比。为此,本文提出了一种离线的困难负例挖掘策略,以提高训练效率和性能。
#SPin-NeRF
神经辐射场(Neural Radiance Fields,简称 NeRF)已经成为一种流行的新视角合成方法。尽管 NeRF 迅速适应了更广泛的应用领域,但直观地编辑 NeRF 场景仍然是一个待解决的挑战。其中一个重要的编辑任务是从 3D 场景中移除不需要的对象,以使替换区域在视觉上是合理的,并与其上下文保持一致。本文提出了一种新颖的 3D 修复方法来解决这些挑战。
神经辐射场(NeRF)已经成为一种流行的新视图合成方法。虽然 NeRF 正在快速泛化到更广泛的应用以及数据集中,但直接编辑 NeRF 的建模场景仍然是一个巨大的挑战。一个重要的任务是从 3D 场景中删除不需要的对象,并与其周围场景保持一致性,这个任务称为 3D 图像修复。在 3D 中,解决方案必须在多个视图中保持一致,并且在几何上具有有效性。
本文来自三星、多伦多大学等机构的研究人员提出了一种新的三维修复方法来解决这些挑战,在单个输入图像中给定一小组姿态图像和稀疏注释,提出的模型框架首先快速获得目标对象的三维分割掩码并使用该掩码,然后引入一种基于感知优化的方法,该方法利用学习到的二维图像再进行修复,将他们的信息提取到三维空间,同时确保视图的一致性。
该研究还通过训练一个很有挑战性的现实场景的数据集,给评估三维场景内修复方法带来了新的基准测试。特别是,该数据集包含了有或没有目标对象的同一场景的视图,从而使三维空间内修复任务能够进行更有原则的基准测试。
- 论文地址:https://arxiv.org/pdf/2211.12254.pdf
- 论文主页:https://spinnerf3d.github.io/
下面为效果展示,在移除一些对象后,还能与其周围场景保持一致性:

本文方法和其他方法的比较,其他方法存在明显的伪影,而本文的方法不是很明显:
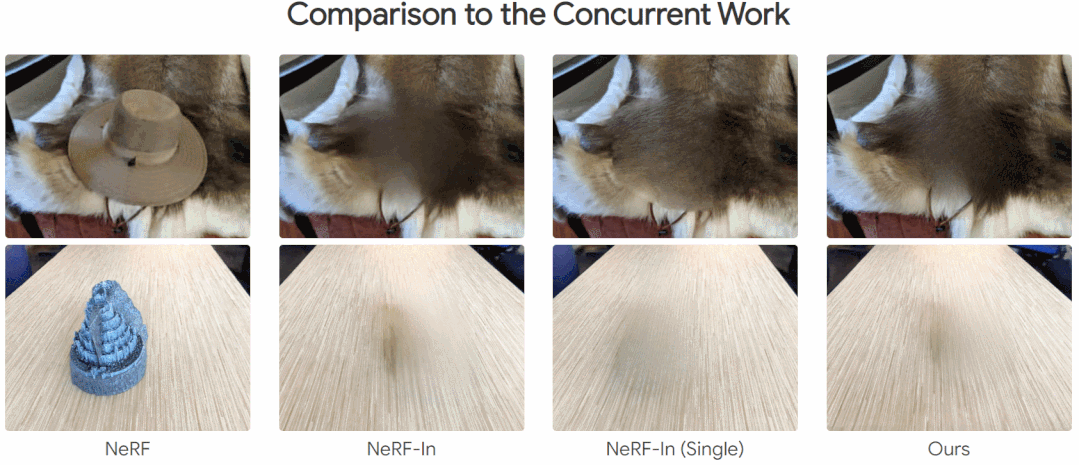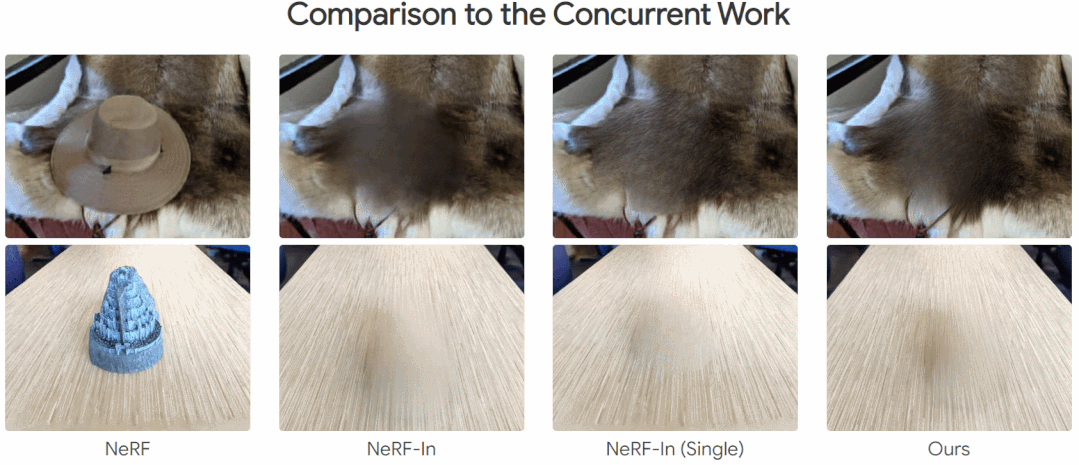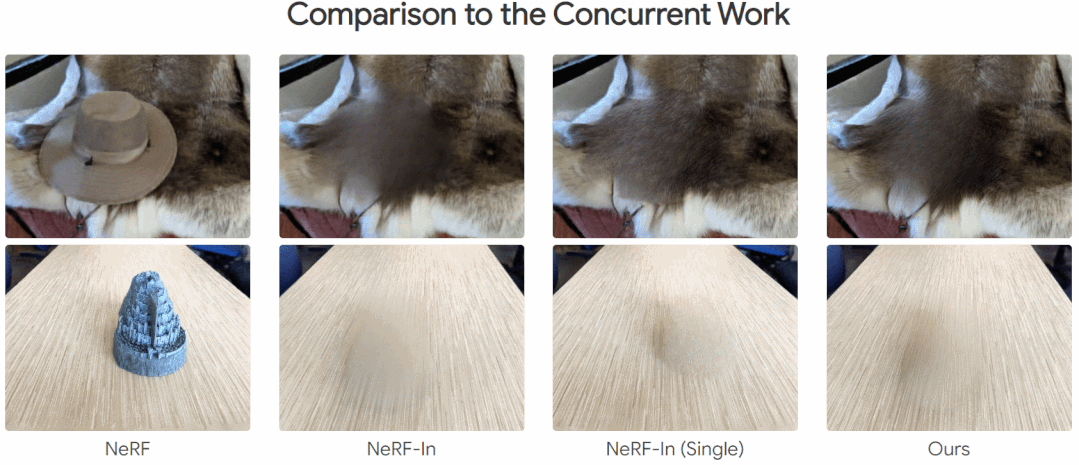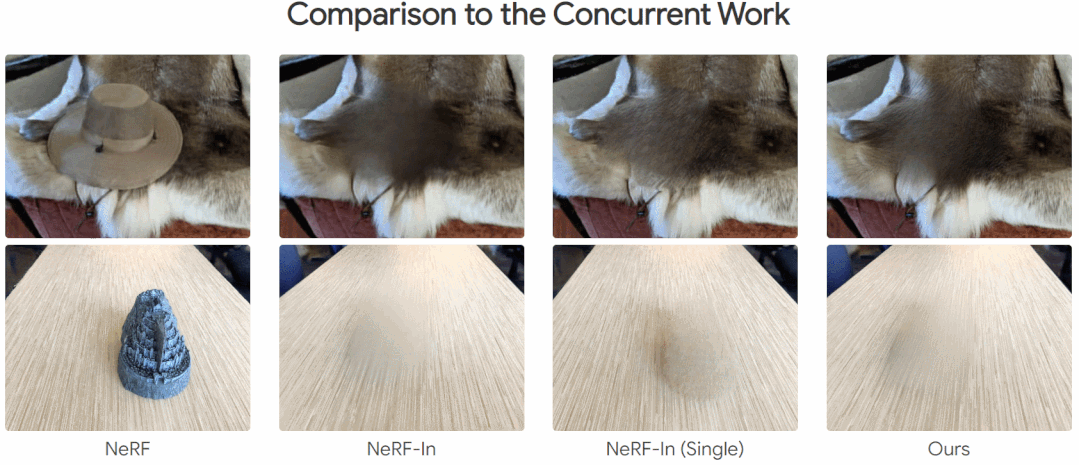
方法介绍
作者通过一种集成的方法来应对三维场景编辑任务中的各种挑战,该方法获取场景的多视图图像,以用户输入提取到的 3D 掩码,并用 NeRF 训练来拟合到掩码图像中,这样目标对象就被合理的三维外观和几何形状取代。现有的交互式二维分割方法没有考虑三维方面的问题,而且目前基于 NeRF 的方法不能使用稀疏注释得到好的结果,也没有达到足够的精度。虽然目前一些基于 NeRF 的算法允许去除物体,但它们并不试图提供新生成的空间部分。据目前的研究进展,这个工作是第一个在单一框架中同时处理交互式多视图分割和完整的三维图像修复的方法。
研究者利用现成的、无 3D 的模型进行分割和图像修复,并以视图一致性的方式将其输出转移到 3D 空间。建立在 2D 交互式分割工作的基础上,作者所提出的模型从一个目标对象上的少量用户用鼠标标定的图像点开始。由此,他们的算法用一个基于视频的模型初始化掩码,并通过拟合一个语义掩码的 NeRF ,将其训练成一个连贯的 3D 分割。然后,再应用预先训练的二维图像修复到多视图图像集上,NeRF 拟合过程用于重建三维图像场景,利用感知损失去约束 2 维画图像的不一致,以及画深度图像规范化掩码的几何区域。总的来说,研究者们提供了一个完整的方法,从对象选择到嵌入的场景的新视图合成,在一个统一的框架中对用户的负担最小,如下图所示。

综上所述,这篇工作的贡献如下:
- 一个完整的 3D 场景操作过程,从用户交互的对象选择开始,到 3D 修复的 NeRF 场景结束;
- 将二维的分割模型扩展到多视图情况,能够从稀疏注释中恢复出具有三维一致的掩码;
- 确保视图一致性和感知合理性,一种新的基于优化的三维修复公式,利用二维图像修复;
- 一个新的用于三维编辑任务评估的数据集,包括相应的操作后的 Groud Truth。

多视图分割模块获取输入的 RGB 图像、相应的相机内在和外部参数,以及初始掩码去训练一个语义 NeRF 。上图描述了语义 NeRF 中使用的网络;对于点 x 和视图目录 d,除了密度 σ 和颜色 c 外,它还返回一个 pre-sigmoid 型的对象 logit,s (x)。为了其快速收敛,研究者使用 instant-NGP 作为他们的 NeRF 架构。与光线 r 相关联的期望客观性是通过在等式中呈现 r 上的点的对数而不是它们相对于密度的颜色而得到的:

最后,采用两个阶段进行优化,进一步改进掩码;在获得初始三维掩码后,从训练视图呈现掩码,并用于监督二次多视图分割模型作为初始假设(而不是视频分割输出)。

上图显示了视图一致的修复方法概述。由于数据的缺乏妨碍了直接训练三维修改修复模型,该研究利用现有的二维修复模型来获得深度和外观先验,然后监督 NeRF 对完整场景的渲染拟合。这个嵌入的 NeRF 使用以下损失进行训练:

该研究提出具有视图一致性的修复方法,输入为 RGB。首先,该研究将图像和掩码对传输给图像修复器以获得 RGB 图像。由于每个视图都是独立修复的,因此直接使用修复完的视图监督 NeRF 的重建。本文中,研究者并没有使用均方误差(MSE)作为 loss 生成掩码,而是建议使用感知损失 LPIPS 来优化图像的掩码部分,同时仍然使用 MSE 来优化未掩码部分。该损失的计算方法如下:

即使有感知损失,修复视图之间的差异也会错误地引导模型收敛到低质量几何(例如,摄像机附近可能形成 “模糊” 几何测量,以解释每个视图的不同信息)。因此,研究员使用已生成的深度图作为 NeRF 模型的额外指导,并在计算感知损失时分离权值,使用感知损失只拟合场景的颜色。为此,研究者使用了一个对包含不需要的对象的图像进行了优化的 NeRF,并渲染了与训练视图对应的深度图。其计算方法是用到相机的距离而不是点的颜色代替的方法:


实验结果
多视图分割:首先评估 MVSeg 模型,没有任何编辑修复。在本实验中,假设稀疏图像点已经给出了一个现成的交互式分割模型,并且源掩码是可用的。因此,该任务是将源掩码传输到其他视图中。下表显示,新模型优于 2D(3D 不一致)和 3D 基线。此外研究者提出的两阶段优化有助于进一步改进所得到的掩码。

定性分析来说,下图将研究人员的分割模型的结果与 NVOS 和一些视频分割方法的输出进行了比较。与 3D 视频分割模型的粗边相比,他们的模型降低了噪声并提高了视图的一致性。虽然 NVOS 使用涂鸦(scribbles)不是研究者新模型中使用的稀疏点,但新模型的 MVSeg 在视觉上优于 NVOS。由于 NVOS 代码库不可用,研究人员复制了已发布的 NVOS 的定性结果(更多的例子请参见补充文档)。

下表显示了 MV 方法与基线的比较,总的来说,新提出的方法明显优于其他二维和三维修复方法。下表进一步显示,去除几何图形结构的引导会降低已修复的场景质量。

定性结果如图 6、图 7 所示。图 6 表明,本文方法可以重建具有详细纹理的视图一致场景,包括有光泽和无光泽表面的连贯视图。图 7 表明, 本文的感知方法减少了掩码区域的精确重建约束,从而在使用所有图像时防止了模糊的出现,同时也避免了单视图监督造成的伪影。


#FF3D~
3D 人像合成一直是备受关注的 AIGC 领域。随着 NeRF 和 3D-aware GAN 的日益进步,合成高质量的 3D 人像已经不能够满足大家的期待,能够通过简单的方式自定义 3D 人像的风格属性成为了更高的目标,例如直接使用文本描述指导合成想要的 3D 人像风格。
但是 3D 人像的风格化存在一个普遍的问题,当一个高质量的 3D 人像合成模型训练好后(例如训练一个 EG3D 模型),后续往往很难对其进行较大的风格化改变。基于模型隐空间编辑的方法会受限于预训练 3D 人像合成模型的数据分布;直接对 3D 人像不同视角进行风格化会破坏 3D 一致性;自己收集创建一个风格化的多视角人像数据集成本很高。以上这些问题使得大家难以简单的创建风格化 3D 人像。
中科院、阿里出品作者们提出一种简单高效的风格化 3D 人像合成方法,能够快速实现基于文本描述的自定义 3D 人像风格化。,创建自定义风格化3D人像只需三分钟
- 论文地址:https://arxiv.org/pdf/2306.15419.pdf
- 项目网站:https://tianxiangma.github.io/FF3D/
视频发不了 就别看了..
方法框架
该方法的核心步骤有两个:1. 小样本风格化人像数据集构建,2. Image-to-Triplane 模型微调。方法框架如下。

使用两种先验模型构建小样本风格化人像数据集
人工收集多视角风格化人像数据是困难的,但是研究团队可以利用已有的预训练模型来间接构建这种数据。本文采用两个预训练先验模型 EG3D 和 Instruct-pix2pix (IP2P) 来实现这一目标。

mage-to-Triplane 模型微调
构建出 Ds 后,需要学习一个符合该数据集人像风格的的 3D 模型。针对这个问题,研究团队提出一个 Image-to-Triplane (I2T) 网络,它可以建立人像图像到 Triplane 表征到映射。研究将预训练的 EG3D 模型的 Triplane 合成网络替换为本文提出的的 I2T 网络,并复用剩余的渲染网络。
因为 Ds 数据集的不同视角风格化肖像是 3D 不一致的,所以首先需要对 I2T 网络进行预训练,来预先建立人像到 Triplane 表征的准确映射关系。研究团队利用 EG3D 的合成数据来预训练 I2T 网络,训练损失函数如下:

该模型微调是十分高效的,可以在 3 分钟左右完成。至此,就能够得到一个自定义风格(使用文本提示 t 指定)的 3D 人像模型。
实验
在本文的首页所展示的就是一系列高质量的风格化 3D 人像合成结果。为了验证本文方法的可扩展性,研究团队构建了一个多风格多身份人像数据集。他们利用 ChatGPT 生成 100 种不同风格类型的问题提示,包含艺术风格、电影角色风格、游戏角色风格、以及基础属性编辑风格。对于每种风格使用本文的人像风格化 pipeline 合成 10*10 张不同视角的风格化人像,进而构建出包含 10,000 张图像的多风格单身份人像数据集(MSSI)。此外,在 MSSI 的基础上扩展每种风格的身份属性,即随机采样不同的 w 向量,得到多风格多身份人像数据集(MSMI)。该方法在这两个数据集上的微调模型的 3D 人像合成结果如下:


在 I2T 的 ws 隐空间进行插值即可实现 3D 人像的风格变化:

该方法与 baseline 方法的对比结果如下:

#PointGST
本文提出了一种全新的点云参数高效微调算法—PointGST,在极大地降低微调训练开销的同时,还展现出了优异的性能。仅凭 2M 可训练参数(仅为此前 SOTA 方法的 0.6%),PointGST 在多个点云分析数据集上均取得了 SOTA 结果,并首次在 ScanObjectNN OBJ_BG 数据集上实现了超过 99% 的准确率,几乎宣告了该数据集的性能达到了饱和。
近年来,点云分析技术在自动驾驶、虚拟现实、三维重建等领域得到了广泛应用。尽管点云预训练模型展现出了优越的性能,但随着模型参数量的急剧增加,对其进行微调的内存和存储开销也同步增加。为了缓解这一问题,本文提出了一种全新的点云参数高效微调算法——PointGST,在极大地降低微调训练开销的同时,还展现出了优异的性能。仅凭 2M 可训练参数(仅为此前 SOTA 方法的 0.6%),PointGST 在多个点云分析数据集上均取得了 SOTA 结果,并首次在 ScanObjectNN OBJ_BG 数据集上实现了超过 99% 的准确率,几乎宣告了该数据集的性能达到了饱和。

图1:近年来点云分析模型的训练参数大小和性能的发展趋势

论文地址:https://arxiv.org/abs/2410.08114
代码地址:https://github.com/jerryfeng2003/PointGST
单位:华中科技大学,百度
提出了一种全新的三维预训练模型微调算法:PointGST,它主要包含以下创新点:
1、构建了一套参数高效谱域微调方法,通过冻结预训练模型的参数并引入轻量级可训练模块,显著降低了模型在微调过程中的显存占用,同时实现了高性能。
2、通过图傅里叶变换,有效地消除了预训练模型内部点云tokens之间的混淆,并进一步引入点云几何结构信息,使得模型在不同数据集上的泛化能力显著增强。此外,PointGST采用了一种新的多层次点云图构建方法,能够更好地捕捉点云数据的内在特征。在实验中,PointGST在多个点云分析任务上展现出优异的准确性和鲁棒性,超越了目前所有同类方法。
三维点云分析是计算机视觉的基础任务之一,广泛应用于自动驾驶、机器人和三维重建等领域。近年来,探索通过新的预训练方法提升点云分析模型性能已成为热门研究课题,这些方法通常通过对全部参数进行微调,然后将模型部署于下游任务中。
然而,由于需要更新全部参数,并且不同下游任务需要独立训练和存储,全微调带来了较高的GPU显存和存储开销,且随着现有模型参数量的逐渐增加而变得愈发显著。为了解决这一问题,一些研究者开始探索将参数高效微调(Parameter-Efficient Fine-Tuning)应用于点云分析领域,并取得了一定的成果。
但这些方法直接在空间域微调时缺乏下游任务的先验知识,难以消除预训练模型内部 token 的混淆;且这些方法未明确引入点云的固有内在结构,仅靠冻结参数的预训练模型来捕获结构信息存在缺陷。
针对上述问题,文章提出了一种基于谱域的三维预训练模型微调方法PointGST(Point Graph Spectral Tuning),用于进一步减轻预训练模型微调中的显存和存储开销问题,同时有效提升参数高效微调算法的性能。
PointGST通过冻结预训练模型的参数,并向其中并行地插入轻量级的可训练模块,点云谱适配器(PCSA),在谱域内进行微调。通过图傅里叶变换(GFT),PointGST将点云tokens从空间域转换为谱域,使得各个token之间的相关性得以有效去除,缓解了预训练模型内部tokens的混淆。
与此同时,PointGST通过基于点云数据关键点构建多层次的点云图,再分别生成图傅里叶变换的基向量,由此引入点云数据的几何结构信息,使得在对下游任务进行微调时,能够通过谱域微调更好地捕捉到点云数据的固有信息。这使得PointGST在显著减少可学习参数量的同时,在多个点云数据集上实现了优异性能。模型整体的pipeline如下图所示:

图2:PointGST整体框架图
PointGST的核心在于将点云tokens从空间域转换到谱域进行处理。具体流程如下:
1、构建点云全局和局部图:通过Farthest Point Sampling (FPS)从原始点云中抽取n个关键点,作为全局图;利用空间填充曲线扫描,将点云中的关键点排序后划分出k组,作为k个点云局部图。通过文章提出的数据依赖放缩策略,由点云得到图的邻接矩阵W,并计算拉普拉斯矩阵L,对原始点云数据提取全局和局部点云的图结构,再加入模型由各个子层共用,在引入了全局和局部空间几何信息的同时,共用的基向量矩阵也显著减小了计算开销。
再对其进行特征值分解得到基向量U,传入各个Transformer子层中。具体过程如下图:

图3:全局和局部的图傅里叶变换基向量构建过程
2、图傅里叶变换(GFT):利用全局和局部图的基向量,对输入适配器并降维后的tokens做GFT,得到点云谱域tokens。此过程能够有效解耦点云数据的复杂空间关系,使得各个token在谱域内得到独立表示。图傅里叶变换即基向量矩阵乘输入图信号。其中,为了和局部图的点云分组对应,在对其进行图傅里叶变换前先由上一阶段关键点排序的索引对点云空间域tokens排序后分组,再对各组进行变换。
3、谱域微调:使用轻量级的点云谱适配器(PCSA)对谱域内的tokens进行微调。该适配器包括简单的线性层和残差连接,通过共享的线性层进行全局和局部谱域tokens的调整。
4、图傅里叶逆变换(iGFT):经过微调的谱域tokens通过逆傅里叶变换返回空间域,即乘以基向量矩阵的转置。随后将局部图点云tokens重排序后,各组tokens相加,升维并输出。为了使训练初始时不改变原有子层的输出,并维持图傅里叶正逆变换前后的一致性,对共享线性层和升维矩阵做零初始化,并加入残差连接结构。
通过这一完整的处理流程,PointGST在显著减少可训练参数的同时,实现了较高的微调性能。
PointGST在真实世界点云分类数据集ScanObjectNN以及模拟数据集ModelNet40中取得了优异的性能。实验结果显示,相较于之前的点云参数高效微调方法,PointGST在显著减少了微调参数量和显存开销的同时,对于五种不同的baseline,在几乎所有任务上超过全微调并得到点云参数高效微调的SOTA结果。

表1:点云分类任务上参数高效微调方法对比
以PointGPT-L为baseline进行微调训练,超过以往的点云分析方法,实现了多个的SOTA结果,并首次在ScanObjectNN OBJ_BG数据集实现超过99%的准确率。

表2:点云分类任务上性能对比
下图展现了在NVIDIA 3090显卡上,不同批次大小下PointGST相比全微调和现有方法能极大地减小内存开销。与以往方法相比,PointGST采用了更加精简的网络结构,从而能够在保持性能的同时,显著降低显存需求,使得模型在实际应用中更加高效和灵活。

图4:微调训练中显存占用大小对比
与此同时,当只使用部分训练数据进行训练,PointGST在不同比例数据下得到了最优的结果,体现其在微调训练中能更好地收敛,并证明了其在鲁棒性上的优越性。

图5:部分数据进行微调训练性能对比
PointGST作为一种全新的点云参数高效微调方法,通过引入谱域微调,有效缓解了传统全微调在显存开销和存储占用上的问题。其在多个数据集上的性能表现证明了该方法的优越性,特别是对大型点云预训练模型进行微调的潜力。PointGST为高效、精确和廉价的三维信息处理提供新的解决方案和可能思路。



















