
Calico在横向扩展或者云环境中,提供了数据终端(endpoint,后面直接使用英文原文)之间端到端的IP互连网络。为了做到这一点,它需要一个互连结构(interconnect fabric)为Calico的运行提供物理网络层连通性。
注:这个互连结构提供了Calico vRouter(大部分情况下是服务器,后称为宿主机)节点之间的连通性,以及vRouter和结构中其它设备(比如,其他物理服务器,边界路由器和应用程序等)的连通性。
虽然Calico被设计成可以与任何支持IP流量的底层互联结构协同工作,但是需要考虑事项最小的架构却是之前讨论过的以太网结构(Ethernet Fabric)。
在大部分情况下,以太网结构是一个合适的选择,但是当L3(一个IP 网络)已经被部署或者将要被部署的环境中,运行Calico就变得意义了。
Calico本身就是一个路由基础设施,尽管当它运行在一个IP路由互联结构中时,需要考虑更多的工程、架构和运行注意事项等诸多问题。但是,通过我们后面的介绍,你会发现Calico在IP互联结构中的表现与在以太网结构中的同样出色。
1 背景
1.1 Calico架构概述
在Calico网络中,每一台宿主机对于本身承载的endpoint来说都是一台路由器,我们称其为vRouter 。Linux内核为它提供数据路径,BGP协议提供控制平面服务,Calico的服务代理Felix负责管理平面的工作。
每个endpoint只能通过本地vRouter与外界建立通讯连接,任何Calico数据包路由第一跳和最后一跳都要经过vRouter。每个vRouter使用BGP协议将本地所有endpoints宣告给其他vRouter,以及物理网络,这个过程中经常会用到路由反射器去增加弹性。
访问控制列表及其他增强安全策略,和另外一些Calico架构组件,因为和互联网络架构无关,故不在本文讨论范围之内。
1.2 常见的IP扩展结构架构综述
到目前为止,使用IP结构构建可扩展基础设施的方法有两种,这两种方法都将机柜交换机(ToR Switch,后面简称为ToR)视作基础网络中的边界路由器。而在Calico网络中,边界路由器的功能被降到宿主机。
另外,在目前大部分虚拟环境中,工作状态的endpoint均不能被底层物理网络(underlay,后使用英文原文)寻址。如果endpoint是一个VM,会被封装到上层网络中(overlay,后面使用英文原文),如果endpoint是一个容器(container,后面使用英文原文),它可能被封装到overlay,也可能被一些代理NAT处理,比如Weave网络模型,或者标准docker网络中的路由器。
下面是对两种方法描述,我们在本文中将只讨论第二种方法,因为它更为常见。
- 基于某种IGP的路由基础设施。因为IGP网络规模的限制(参见《为什么Calico只是用BGP作为互连协议》一文中关于这个话题的讨论) ,Calico项目组不认为IGP协议路由分发能力可以支撑Calico环境承载endpoints的数量规模。然而,这种方法可能是在互联结构中将IGP和BGP混合使用,IGP负责下一跳路由器(在Calico中经常是宿主机)的可达性,BGP用于分发endpoint的路由信息。这是一个有效的模型,并且在大部分运营商骨干网络中被采用。这些网络的设计有些复杂,本文不予讨论。
- 完全基于BGP的路由基础设施。在这个模型中,IP网络要求足够紧凑的或者半径足够小,这样BGP就可以被用来分发endpoints路由,并且这些路由的下一跳路径是被网络中所有路由器知道的(包括物理网络中三层设备以及Calico网络的宿主机)
1.3 只运行BGP的互联结构
构建纯BGP互联架构网络有多种方法。我们将关注三个模型,以及每个模型的两个常见变体。 其中两个模型是:
- 每个ToR及其下联宿主机使用一个唯一的自治系统号(
AS Number),ToR之间可以使用spine交换机提供的以太网交换平面互联(假设这是一个Leaf/spine结构),或者通过一组使用不同AS号的spine交换机互联,我们称其为“AS Per Rack”(每机柜独立AS)模型。这个模型的细节在IETF RFC 7938中有所描述。 - 另一种BGP互联结构是:每台宿主机使用一个唯一的AS号,ToR扮演传输AS的角色。我们称这个是“AS per server”(每服务器一个AS号)模型。
每个模型都会有一个以太网或者IP spine节点。在以太网结构的spine情景,每个spine节点提供一个独立的以太网连接平面,ToR会连接到每个spine节点上面。 而IP互联结构的spine情景,每个spine交换机拥有一个唯一的AS号,ToR和每个spine交换机都是eBGP对等体关系。 两种情景下,ToR都会通过ECMP充分利用与每个活跃spine交换机之间所有可用链路,实现均衡负载流量。
1.4 BGP网络设计要点
与大家通常的观念不同,BGP实际上是一个非常简单的协议。比如,BGP在Calico宿主机上的配置信息大约只有60行(不包括注释)。让人觉得复杂的其实是使用BGP实现的那些具体事情。许多BGP的应用场景使用了复杂的策略规则,因为技术、商业、金融、法规等方面的要求,BGP对数据包的默认处理行为被修改了。而默认的Calico网络时不会涉及这些领域的,它更专注于直接转发。 即便如此,在Calico网络设计一张连接各个节点的IP网络时,BGP的一些设计规则也是需要铭记于心的,并且最好是由非常擅长高级BGP设计的人员来完成。 这些要点如下:
AS continuityAS连续性:一个AS号下的所有路由器之间的数据要求不穿越其他AS直接相互通讯。Next hop behavior下一跳行为:默认情况下,BGP路由器在收到同一AS号对等体宣告的路由不会修改下一跳。相反,BGP路由器从不同AS号对等体收到的路由会把下一跳地址改为自己。Router Reflection路由反射器:一个给定AS内的所有BGP路由器之间必须都建立对等体关系。这被称为BGP全互联。当自治系统内路由器数量增加这可能会成为一个问题。使用路由反射器可以减少BGP全互联需求,但是路由反射器也存在规模和扩展的考虑Endpoints数据终端:在calico网络每一个endpoint都是一条路由。硬件网络平台会受到设备路由表最大条目数的限制,这个限制通常是10000到100000条路由。路由聚合可以缓解路由条目数的压力,但是这要依赖于调度程序所使用编排软件的功能(例如 openstack)。 后面的附录里还会针对以上四点做深度讨论。
1.5 每机柜独立自治系统模型
这个模型与IETF RFC 7938中介绍的模型最为接近。
如前文所述,这个模型存在两种版本,一种是使用一系列以太网平面(作为核心)互联所有ToR,另一种核心平面则使用三层路由域。下面两张图可能会对理解有所帮助
图1.5-1:每机柜独立AS模型1:以太网交换互联
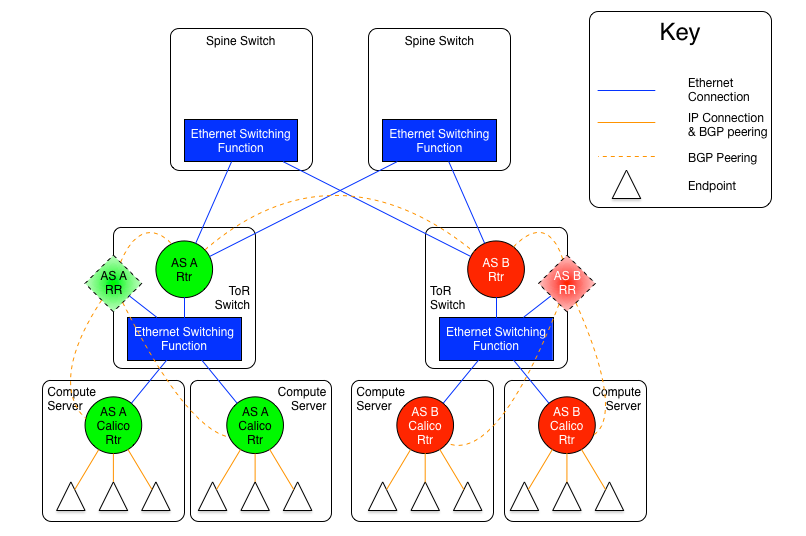 上图显示了每机柜独立AS模型之中,所有ToR,通过以太网交换平面全物理互联的变体。
上图显示了每机柜独立AS模型之中,所有ToR,通过以太网交换平面全物理互联的变体。
图1.5-2:每机柜独立AS模型2:IP路由互联
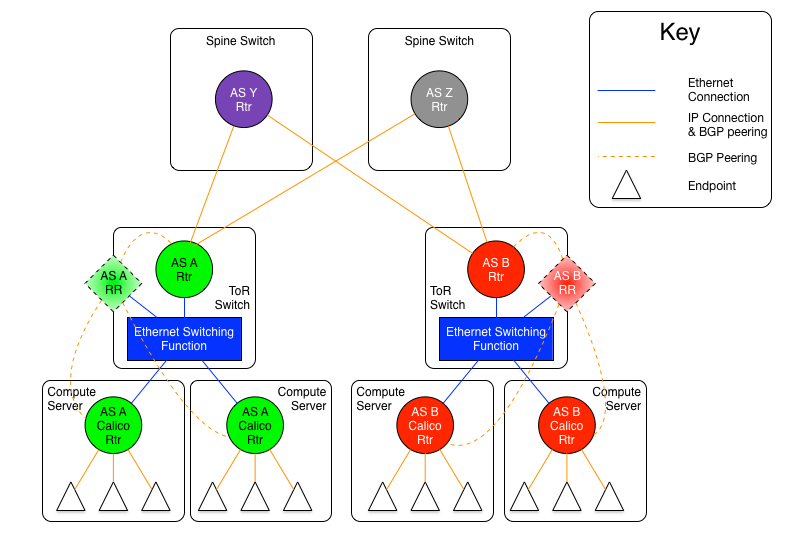 上图显示了每机柜独立AS模型之中,所有ToR通过一组各自拥有唯一AS号spine路由器使用三层路由互联的变体。
上图显示了每机柜独立AS模型之中,所有ToR通过一组各自拥有唯一AS号spine路由器使用三层路由互联的变体。
在这个方案中,ToR与ToR之间,或者ToR与Spine(上面第二张图的例子)之间的是EBGP对等体关系。
如果选择spine工作在2层的版本,那么结果就是每一个ToR必须与同一集群内其他ToR建立对等体关系。
如果选择spine各自拥有唯一AS号的路由版本,那么ToR只需要与每个spine建立对等体关系(一个Pod里通常是2个或者16个spine交换机)。但是spine交换机必须是所有ToR的对等体(再次说明,ToR的数量可能是数以百计的,但是通常spine交换机的控制平面容量要比ToR大的多,所以多数场景还是更易扩展的)。
在机柜内,两种变体的配置是相同的,只是ToR的北向(上联)配置有些许差异。
在Calico网络中,机柜内每台宿主机都被视为一台路由器,它们使用与同柜上联ToR相同的AS号,并且使用了ToR提供的以太网交换层直接互联,保持了AS连续性。TOR交换机的路由功能模块也被连接到自己提供的以太网交换层:通常ToR连接宿主机的接口被视为属于某个子网或者网络分段,ToR的路由功能模块在这些分段内也有一个单独虚拟接口。
在本模型中,每个宿主机使用ToR的交换功能相互连接,而没有用到TOR的路由模块。所以,宿主机与ToR的路由模块必须是全互联结构,或者在机柜中使用路由反射器,这可以在ToR交换机上开启,或者在同机柜一个或多个宿主机上部署虚机,承担路由反射器的作用。
ToR作为EBGP路由器,重分布(或者宣告)所有来自其他ToR以及数据中心外部的路由给自己自治系统内的宿主机。同时宣告本自治系统内的路由给其他ToR和外部网络。这就意味着每个宿主机去往外部路由的下一跳都是本机柜ToR,而机柜内部所有路由的下一跳都是每个具体的宿主机。
1.6 每服务器独立AS模型
前面提到的IETF RFC 7938中假设:ToR是整个模型第一具有路由角色,且可以执行路由汇总功能的层级。而在Calico网络中,具有路由角色的ToR也只能作为第二个层级去实现以上功能,因为对于一个Calico网络中的endpoint来说,宿主机永远都是路由过程的第一跳或者最后一跳,同时也是第一个/最后一个路由聚合点。 所以,在每服务器独立AS架构模型中,AS的边界是服务器而不再是ToR。下面两张图显示了它们的区别。
图1.6-1:每服务器独立AS模型1:Spine层以太网互联变体
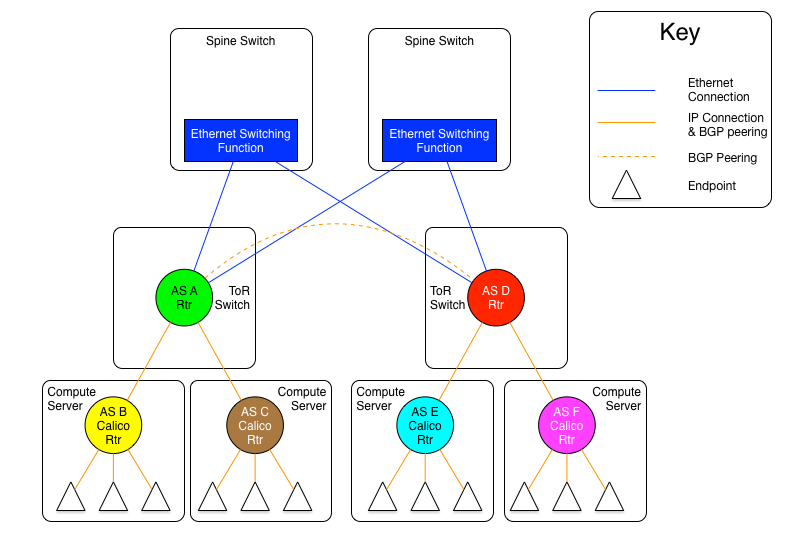 上面一张图是每服务器独立AS模型的其中一种变体,ToR通过一组以太网交换平面实现物理全互联。
上面一张图是每服务器独立AS模型的其中一种变体,ToR通过一组以太网交换平面实现物理全互联。
图1.6-2:每服务器独立AS模型2:Spine层IP路由互联变体
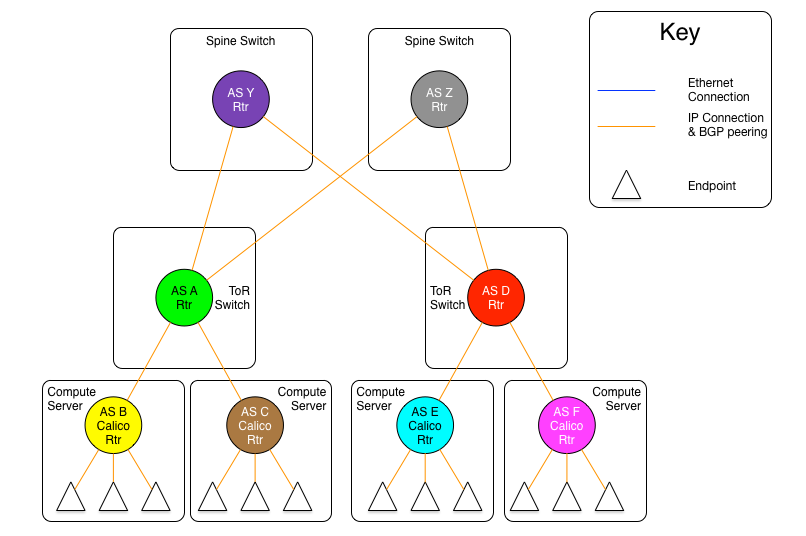 上面一张图是每服务器独立AS模型的另外一种变体,ToR交换机都被物理连接到一组独立路由平面.
上面一张图是每服务器独立AS模型的另外一种变体,ToR交换机都被物理连接到一组独立路由平面.
从这些图中可以看到,和每机柜独立AS模型一样,每服务器独立AS模型也有两个变体,一个是采用独立交换平面互联所有ToR,另一个则是通过一组独立路由器互联所有ToR交换机。
而它们真正的不同是,在这个模型中宿主机与ToR都是独立的自治系统,为了解决规模性问题,这里使用了RFC 4893中介绍的4字节自治系统号。在不使用4字节自治系统号时,ToR和宿主机可用的AS号数量将被限制在5000个左右。而使用4字节AS号可以将这个数字增加到9200万个,已经可以满足Calico任何架构设计的需要了。
与每机柜独立AS模型相比另一个不同点是,这里不再需要路由反射器,因为所有的BGP对等体的类型都是EBGP。比如同机柜的宿主机与ToR之间也是EBGP对等体关系。同机柜两台服务器之间的通讯需要经过ToR路由。所以,每个服务器将同它所连接的每个ToR建立一个对等体连接,每个ToR也将对它所连接的宿主机有一个对等体连接(通常是机架中的所有宿主机)。
ToR之间的连接在规模和范围上与每机柜独立AS模型相同。
1.7 下发默认路由模型
最后的模型有点不同。在前面两个模型中,基础结构中的路由器都携带完整的路由表,并且保持它们的AS路径不变,而这个模型在路由路径的每一跳都会删除AS号。这是为了防止网络中其他节点的路由,因为它们来自本地(路由的源和目的IP都在相同的AS中)而不被安装到路由表中。
下图显示了这个模型中AS之间的关系
图1.7:向下默认模型拓扑图
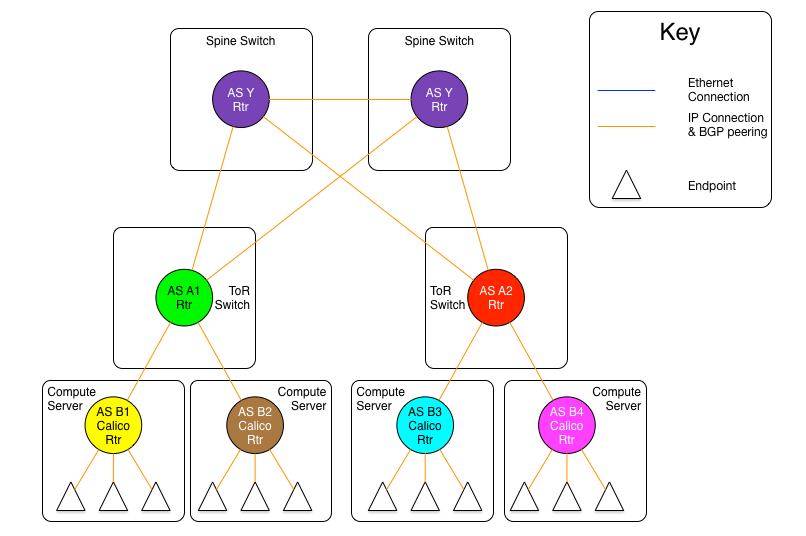 在上面的图中,我们看到所有Calico nodes 共享相同的AS号,ToR也是一样。但是他们的AS是不同的(A1和A1是不同的网络,尽管它们共享AS号 A)。
所有ToR只使用一个AS号,所与宿主机使用另外一个,这样不但简化了配置(使用标准化的配置),而且ToR路由表压力被卸载了。
在上面的图中,我们看到所有Calico nodes 共享相同的AS号,ToR也是一样。但是他们的AS是不同的(A1和A1是不同的网络,尽管它们共享AS号 A)。
所有ToR只使用一个AS号,所与宿主机使用另外一个,这样不但简化了配置(使用标准化的配置),而且ToR路由表压力被卸载了。
在这个模型中,每个路由器角色宣告它的所有路由信息给上游对等体(Calico路由器宣告给ToR,ToR宣告给Spine交换机)。而反向路径上,上游路由器只宣告默认路由给下游。这样,一个Calico路由器只会有自己承载的endpoints的路由和一条去往ToR的默认路由。ToR是Calico网络去往网络中其他位置的唯一通路,这与现实环境相符。ToR交换机与Spnine交换机之间的情形也类似,ToR只需要安装附着到它下游Calico node中的endpoints路由。即使我们每个Calico nodes上承载200个endpoints,每个机柜部署80个Calico nodes,每个ToR的路由表条目数也会被限制在16000条(普通数据中心交换机承载这种量级的路由数是没有压力的)。
因为默认路由初始是被Spine产生的,不存在Spine收到一条起源于接收方AS的默认路由的可能,防止了AS Puddling问题。
这个模型有一个小的缺点,那就是所有到无效目标地址的流量(目标IP不存在),在丢弃之前需要都被转发到spine交换机。
需要注意的是,spine交换机仍然需要承载所有Calico网络的路由,就像前面例子中路由架构spine所做的那样。简而言之,这个模型比起其他两个没有增加spine的负载压力,却大幅度减少了ToR路由表占用空间。也减少了Calico nodes的路由数量,但是这对现在的服务器计算能力再说,不是问题,完整路由表所使用的内存量是服务器内存的很小一部分。
2 推荐意见
- Calico工程团队建议,在考虑到了业务量增长的前提下,如果ToR和spine可以承载估算过的路由规模,那么推荐使用“AS per rack”模型。
- 如果在ToR交换机上遇到了路由表容量的问题,建议使用“Downward Default”模型。
- 如果ToR和Spine交换机都遇到了路由表容量的问题,或者对Calico nodes仅提供简单的L2交换网络架构,建议参考之前文章介绍的以太网架构。
- 如果Calico用户对“AS per compute server”模型感兴趣,Calico工程团队将非常有乐意介绍它的部署情况(但是本文中并没有提到)
3 附录
3.1 其他选项
在本文和之前以太网互联的文章介绍的架构中,一条给定路由的下一跳,对收到该路由的设备来说总是直连的。这就不需要再有其他协议帮助分发下一跳路由信息。 然而,很多(可以说大部分)广域网BGP网络,一个给定AS中的路由器之间可能不是直连邻居。所以,一个路由器可能收到一条路由,它的下一跳并不是自己直连的。这时候,路由器需要使用一种IGP比如OSPF或者IS-IS,去帮助确定去往BGP下一跳的路径。 在某些Calico架构中某些类似模型中,可能的确存在一个AS中的路由器是非直连的,这时候就需要使用到IGP,但这超出了本文的范围。
3.2 IP架构设计注意事项
3.2.1 AS puddling AS混淆
第一条注意事项是AS必须保持连续,这意味着一个给定AS的两个node之间必须能够直接通讯,而不需要经过任何传输AS.如果这个规则被打破了,影响是会导致AS混乱(AS Puddling),网络不能正常运行。
这个注意事项的一个延伸是:任意两个共享同一个AS号管理域,将被视为同属于这个AS中,尽管这不是设计者的初衷。因为BGP除了AS号外没有其它方式区分一个自制系统是本地的还是外部的。所以,如果不对BGP路由器实施大量策略修改,那么两个非直连(经过其它传输AS互通)却复用同一个AS号的网络是不能正常工作的。
另外一个延伸是BGP路由器不会将一条AS-PATH属性中包含对等体AS号的路由 发送给该对等体。这是一种EBGP防环机制,效果是防止两个同一自治系统内的路由器,通过一个传输路由器(可能是其他AS的)相互通讯。
3.2.2 Next hop behavior 下一跳行为
另一个需要考虑的问题是iBGP和eBGP的区别。BGP有两种运行模式,如果两个路由器是BGP对等体,共享相同的AS号码,那么它们被称为iBGP对等体关系。如果它们使用不同的AS号码,则被称为外部或者EBGP关系。
BGP的原始设计模型是:在一个给定AS内,所有BGP路由器都知道如何去往其它BGP路由器(通过静态路由,IGP路由协议,或其他类似协议),而不同AS之间的路由器是不知道如何到达另外一个AS的,除非它们之间是直连的。
基于上面的设计原则,在一个给定AS内处于iBGP对等体关系的路由器,它们之间传输流量是不需要通过其他iBGP路由器的(比如,A与C之间的通讯是不需要B去路由的),所以是不需要改变BGP下一跳属性的。(---- 译者注:作者的观点是建立在iBGP对等体之间全互联结构基础上的。)
另一方面,处于eBGP对等体关系的路由器,认为它的eBGP邻居不知道如何去往下一条路由,将使用它自己拥有的地址替换到原有下一跳字段的内容,这种行为被称为“下一跳自我” 在Calico以太网互联模型中,所有服务器(Calico网络中的路由器)之间都是通过一个或者多个以太网络直接互联的,直连可达。因此Calico网络中的路由器是不需要设置下一跳自我的。
在本文我们所展示的模型中,已确保所有可能通过非Calico路由器传递的路由都是eBGP路由,所以下一跳自我是会被自动正确设置的。但是客户在一个IP互连网络中部署Calico,而没有遵从模型约束条件时,则必须确保“下一跳自我”被适当的配置。
3.2.3 Route reflection 路由反射
如上所述,BGP期望网络中所有iBGP路由路由之间可以直接连接,这被称为BGP全互联结构。如果在一个小型网络中可能不是一个问题,但当路由器的数量不断增加时,就变得有趣了。举例来说,如果在一个AS内原有99台BGP路由器在运行,现在需要新增一台,你就不得不让新路由器与已经存在的99台逐一建立对等体关系。这不仅仅是配置时间的问题,而且还会极大的消耗路由器有限的资源。当只有100台路由器的时候可能还是一个“有趣”的问题,当路由器是1000台或者10000台的规模呢(Calico网络极有可能达到这种规模)?这将成为一个不可能完成的任务。 在差不多20年前,大型互联网规模的网络中通过使用BGP路由反射器( 'RFC 1966' 中定义)很容易的解决了这个问题。目前这已经是被大部分BGP路由器支持的技术。在一个大型网络中,路由反射器是合理分布的,每个IBGP路由器都与1个或者多个(通常是2-3个)路由反射器建立对等体关系,每个路由反射器可以为10+或者100+路由反射器客户端(Calico网络中就是一个服务器)提供服务,实际数量取决与所使用的反射器规格。这些路由反射器之间也是对等体体关系。这就比全互联的结构节省很多对等体连接,每个反射器客户端只与2-3个路由反射器客户端建立对等体关系。这就更加容易管理了。
当然也存在其他路由反射器的架构设计,但是这些已经超出了本文的范围。
3.2.4 Endpoints 数据终端
最后一个建议是关于Calico网络中endpoint的数量的。在以太网互联的场景下endpoints的规模不会受到互联结构容量的制约,因为互联结构不关心活跃的endpoints,它只能看到vRouters。而且IP互联场景下情况就不一样了。IP网络是按照数据包中的目标地址转发,在Calico网络中目标地址是endpoints。这时候IP互联节点(比如ToR和/或者Spine交换机)就必须知道去往网络中每个endpoints的路由。它们通过作为BGP 路由反射器的客户端可以学到这些路由,就像Calico vRouter/服务器所做的一样。
然而,物理交换机不像服务器一样有大量可用内存,它的性价比非常低。这决定了物理交换机可以处理的路由条目数量是有限的。当前业界标准商业交换机的路由表规格是128k,使用IP互联结构的Calico是受到所使用网络硬件路由表规格限制的,比较合理的上限是128K个endpoints。
原文链接:https://docs.projectcalico.org/v3.0/reference/private-cloud/l3-interconnect-fabric




















