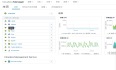
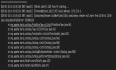
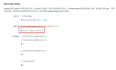
背景:一个监控告警的项目,执行了一条非常复杂的sql,但是执行完6S后报错如下:1064 - StarRocks planner use long time 3000 ms, This probably because 1. FE Full GC, 2. Hive external table fetch metadata took a long time, 3. The SQL is very
背景:在调度中出现这个报错,但是在后台执行的时候是成功的,每次在调度上执行6分钟即360S的时候出现了这个报错,排查后发现使用的nginx代理中设置的timeout设置的是360s,所以才会出现这个报错ERROR 2013 (HY000) at line 3: Lost connection to MySQL server during query解决方案:nginx中的timeout的时间调整到
报此问题的主要原因是因为Agent的通信问题导致的解决方案:重启agent服务systmectl restart cloudera-scm-agent稍等2分钟后问题解决
升级集群您可以通过滚动升级的方式平滑升级 StarRocks。StarRocks 的版本号遵循 Major.Minor.Patch 的命名方式,分别代表重大版本,大版本以及小版本。注意由于 StarRocks 保证 BE 后向兼容 FE,因此您需要先升级 BE 节点,再升级 FE 节点。错误的升级顺序可能导致新旧 FE、BE 节点不兼容,进而导致 BE 节点停止服务。StarRocks 2.0 之
Starrocks默认是100个表分区,如果超过这个时间,动态分区创建之后会被自动删除解决方案:ALTER TABLE dwd_iov_test SET ("dynamic_partition.start" = "-2000");使用表分区漂移变成2000动态分区动态分区功能开启后,您可以按需为新数据动态地创建分区,同时 StarRocks 会⾃动删除过期分区,从而确保数据的时效性。创建支持动态分
现象:FE节点上安装了KVM之后,虚拟网卡多了一个192.168.12.1的地址,导致FE在重启的时候无法找到元数据的故障,报错如下2023-02-15 09:53:22,082 WARN (UNKNOWN 10.172.128.77_9015_1667993591722(-1)|1) [BDBJEJournal.open():319] catch exception, retried: 0 co
ERROR 1105 (HY000): errCode = 2, detailMessage = NoClassDefFoundError: Could not initialize class org.apache.doris.catalog.PrimitiveType这个报错是jar包的问题1.下载此java-udf-jar-with-dependencies.jarhttps://jia
解决办法:CDH-6.2.1-1.cdh6.2.1.p0.1425774-el7.parcel.sha1此文件没有变更到CDH-6.2.1-1.cdh6.2.1.p0.1425774-el7.parcel.shacd /opt/cloudera/parcel-repomv CDH-6.2.1-1.cdh6.2.1.p0.1425774-el7.parcel.sha1 CDH-6.2.1-1.cdh
报错日志JAVA_HOME=/usr/java/jdk1.8.0_181-clouderaVerifying that we can write to /etc/cloudera-scm-serverWed Jan 18 22:11:22 EST 2023 WARN: Establishing SSL connection without server's identity verificatio
2023-01-13 09:50:07,603 ERROR (main|1) [BDBEnvironment.setup():233] error to open replicated environment. will exit.com.sleepycat.je.EnvironmentFailureException: (JE 7.3.7) 10.179.110.250_9015_1653712
[root@hdp03 hive]# cat hive-server2.errError: VM option 'UseG1GC' is experimental and must be enabled via -XX:+UnlockExperimentalVMOptions.Error: Could not create the Java Virtual Machine.Error: A fat
#!/usr/bin/bash # 获取当前脚本所在路径 cur_dir="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)" cd ${cur_dir} # 导出所有hive数据库名 hive -e "show databases;" > ${cur_dir}/all_database.db # 删除导出文件中的警告信息 sed
科目四超全考试知识点总结!备考学员必看!一 、判断对与错:1.不准你做的事情都是对的(不准、不得、不应、不能、严禁、紧止、应当)2.让对方先走的都是对的(减速让行、停车让行、礼让通行、减速避让)3.慢的都是对的(缓慢通过、减速、平稳、逐渐、慢慢通过、将速度降低、匀速下降)4.观察的都是对的(提前观察、仔细观察、认真观察、瞭望)5.安全的都是对的(间断轻踏、保证安全、确保安全、安全通过)6.不听话的
package com.itheima_112;/* 字节流写数据的两个小问题: 1:字节流写数据如何实现换行呢? windows:\r\n linux:\n mac:\r 2.字节流写数据如何实现追加写入呢 public FileOutputStream(
package com.itheima_111;import java.io.FileNotFoundException;import java.io.FileOutputStream;import java.io.IOException;/* FileOutputStream:文件输出流用于将数据写入File FileOutputStream(String name);创建文件输出流
package com.itheima_111;import java.io.File;/*需求: 需求:指定一个路径,请通过递归完成遍历该目录下的所有内容,并把所有文件的绝对路径输出在控制台思路: 1.根据给定的路径创建一个File对象 2.定义一个方法,用于获取给定目录下的所有内容,参数为第1个步骤创建的File对象 3.获取给定的File目录下所有文件或者目录的File
package com.itheima_111;/*案例:递归求阶乘需求:用递归求5的阶乘,并把结果在控制台输出分析:1.阶乘:一个正整数的阶乘是所有小于及等于该数的正整数的积,自然数n的阶乘写作n! 5!=5*4*3*2*12.递归出口:1! = 13.递归规则:n! = n*(n - 1 ) 5! = 5* 4!思路:1.定义一个方法,用于递归求阶乘,参数为一个int类型的变量2.在方法
递归概述:以编程的角度来看,递归指的是方法定义中调用方法本身的现象.递归解决问题的思路:把一个复杂的问题层层转化为一个与原问题相似的规模较小的问题来求解递归策略只需少量的程序就可以描述出解题过程所需要的多次重复计算递归解决问题要找到两个内容 递归出口:否则会出现内存滚出 递归规则:与原问题相似的规模较小的问题package com.itheima_111;/* 递归概述:
public boolean delete()删除由此抽象路径名表示的文件或目录绝对路径和相对路径的区别绝对路径:完整的路径名,不需要任何其他信息就可以定位它所表示的文件,例如:/Users/Steven/soft/java/java.txt相对路径:必须使用取自其他路径名的信息进行解释 例如:test\java.txt删除目录注意事项:如果一个目录中有内容(目录\文件),不能直接删除,应该先删除
Copyright © 2005-2024 51CTO.COM 版权所有 京ICP证060544号