
引言
定义:帮助mysql高效获取数据的排好序的数据结构;
首先清楚数据在底层存储方式:向链表一样前后相连,而非数组的形式开辟一片相连的空间,这意味着我们看到的有序的相连的数据不一定在一起,当我们想要获取数据时,每一次读取就是一次io,当减少io次数时,就可以将获取数据的速度加快。
数据结构
二叉树:
缺点:递增索引下,高度会过高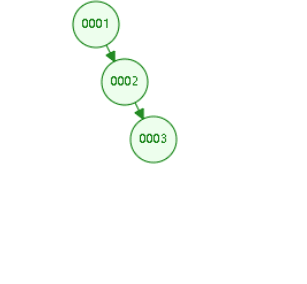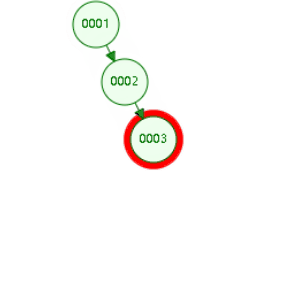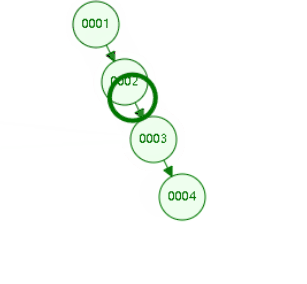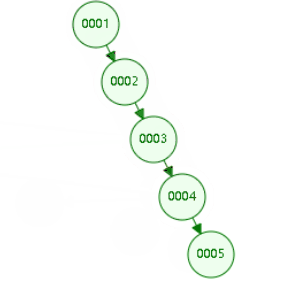
红黑树:
二叉平衡树,也会高度过高,递增索引下,高度过高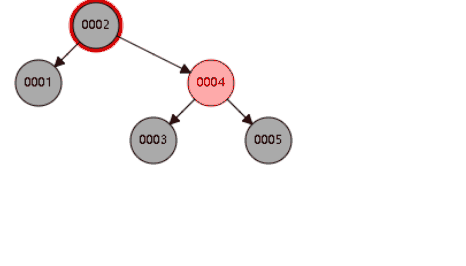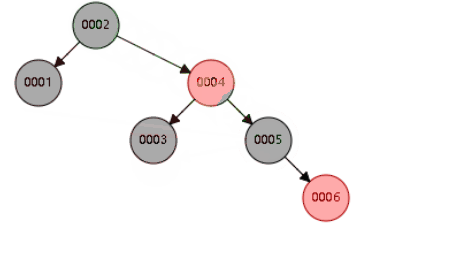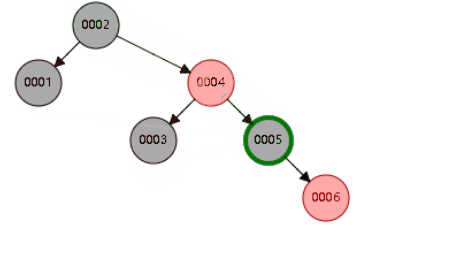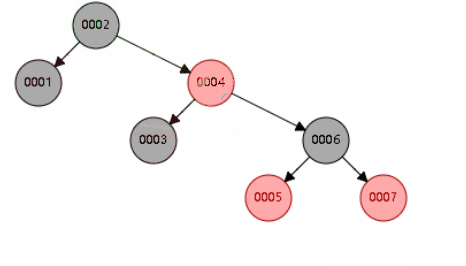
hash表:
会创建hash桶,对索引列进行hash计算,将数据存储位置依次放入桶中
缺点:hash冲突;仅能满足‘=‘查询,不支持范围查询(主因)
b-Tree:
增大红黑树根节点空间,使根节点横向增大
缺点:每个节点都带有数据,占用内存
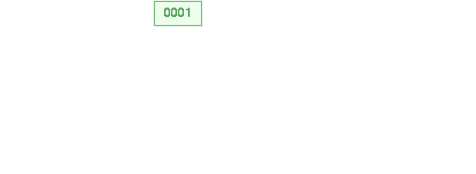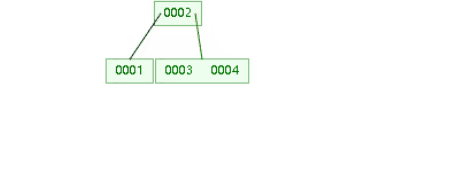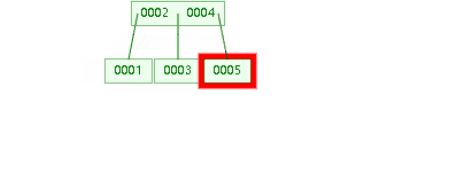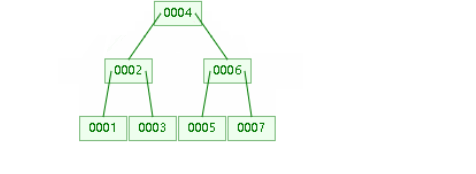
b+Tree:
将b-树非叶子节点的数据统一安排到叶子结点,叶子结点将有所有数据和索引,非叶子节点只放索引(冗余索引);
共同点:
- 从左到右递增,查找时可以使用二分查找法快速定位横向节点;
- 快速查找时横向查找将会把数据放入内存,内存大小为16k;
不同点:
- b+Tree假设非叶子节点上一个索引占(8+6)B全部存满,1100 * 1100 * 16大概三层可以快速查找两千万内数据;B-Tree每一个索引下都有数据,若每一个索引的数据按照1kb算,将索引和数据放入内存,每一次只能放16个数据,按三层数据高度算,16x16x16远远低于B+Tree的存储;
- b+tree相比b-tree叶子结点多一个双向指针,指针会记录下一节点位置,当出现范围查找时,不需要重新根节点查找元素,直接得到位置,将数据取出即可;当b-tree范围查找,叶子结点出现断层,需要重新返回根节点去查找元素位置;
注:MySQL叶子节点指向是双向的,且只有最下面的叶子节点有数据

MYSQL存储引擎
MyISAM存储引擎:建表后由三个文件组成(同一文件名,不同后缀)
- .frm:框架表结构
- .MYI:索引
- .MYD:数据
InnoDB存储引擎:两个文件组成(同一文件名,不同后缀)
- .frm:框架表结构
- .ibd:索引+数据
聚集索引:叶子节点包含完整的数据记录;
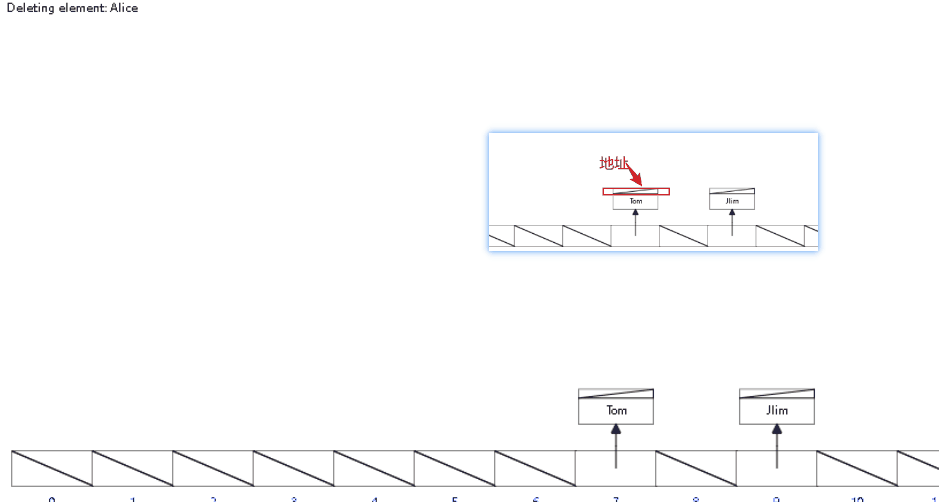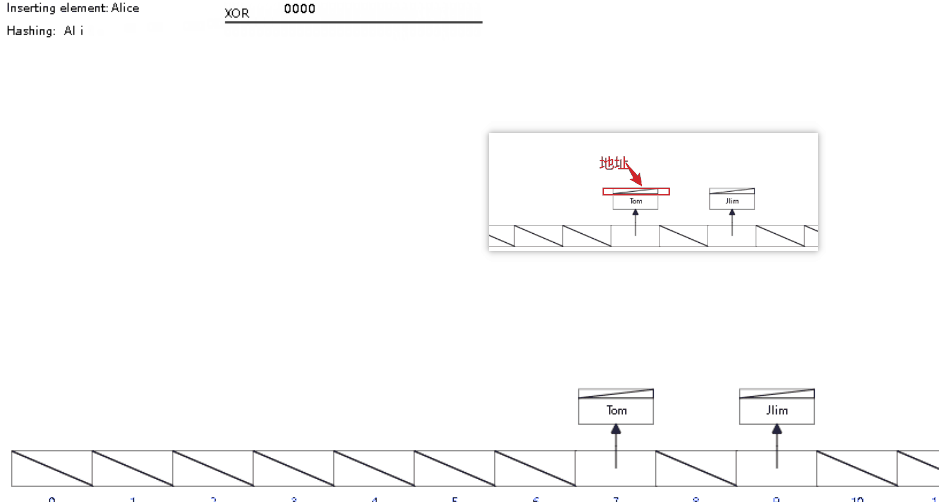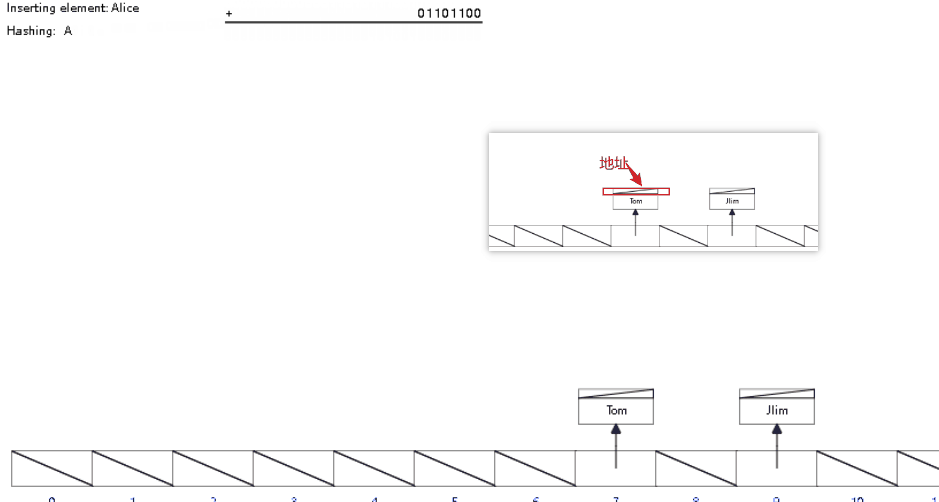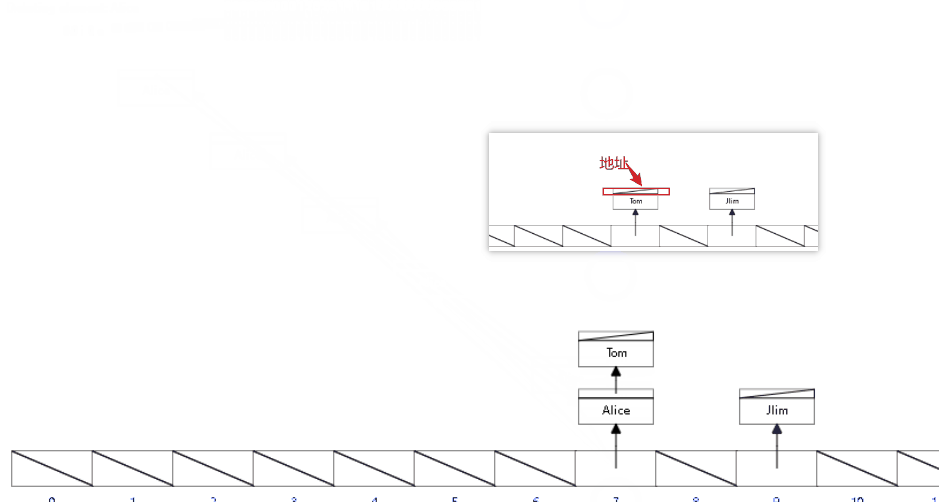
非聚集索引:MyISAM在叶子结点不放入数据,只放入地址,之后根据地址去数据表查找数据,速度变慢
为什么InnoDB建议建主键,并且推荐整数类型自增主键
前提:建立表时必须由b+Tree去创建表,b+Tree必须得有索引
- 为什么建主键
当开始建表是会从第一页查找不存在重复数据的列,若存在则当前列为索引,若不存在,会重建一个隐藏不重复数据列,作为该表的索引列;
- 为什么整数类型
假如使用uuid做主键,必须先要将uuid转换为asic码,再进行大小比较,浪费时间、性能,同时uuid占用内存也会比整型占用空间大;
- 为什么自增
当建立表时,数据根据b+Tree结构添加索引,主键递增,非叶子节点会往后添加,若不是递增,则会进行一个平衡再自加,特别是大数据时,会直接变更已经定好的树结构;
普通索引
采用b+Tree结构,叶子结点的数据层将会存储表的主键值,然后根据主键值回表查询数据行。
为什么非主键索引结构叶子结点存储的是主键值?
- 一致性:当进行数据修改和插入时,如果都是数据的话,需要多次修改或添加,使用主键只需要改变主键索引下的数据;
- 节省空间:若每一个非主键索引的叶子结点都存入数据,将会占用很大内存空间(主因)
联合索引数据结构
按照索引最左前缀原理,当联合索引有三个元素时,按照第一个排序,后第二第三个元素依次排序,得到主键后直接得到数据



















