
MySQL索引
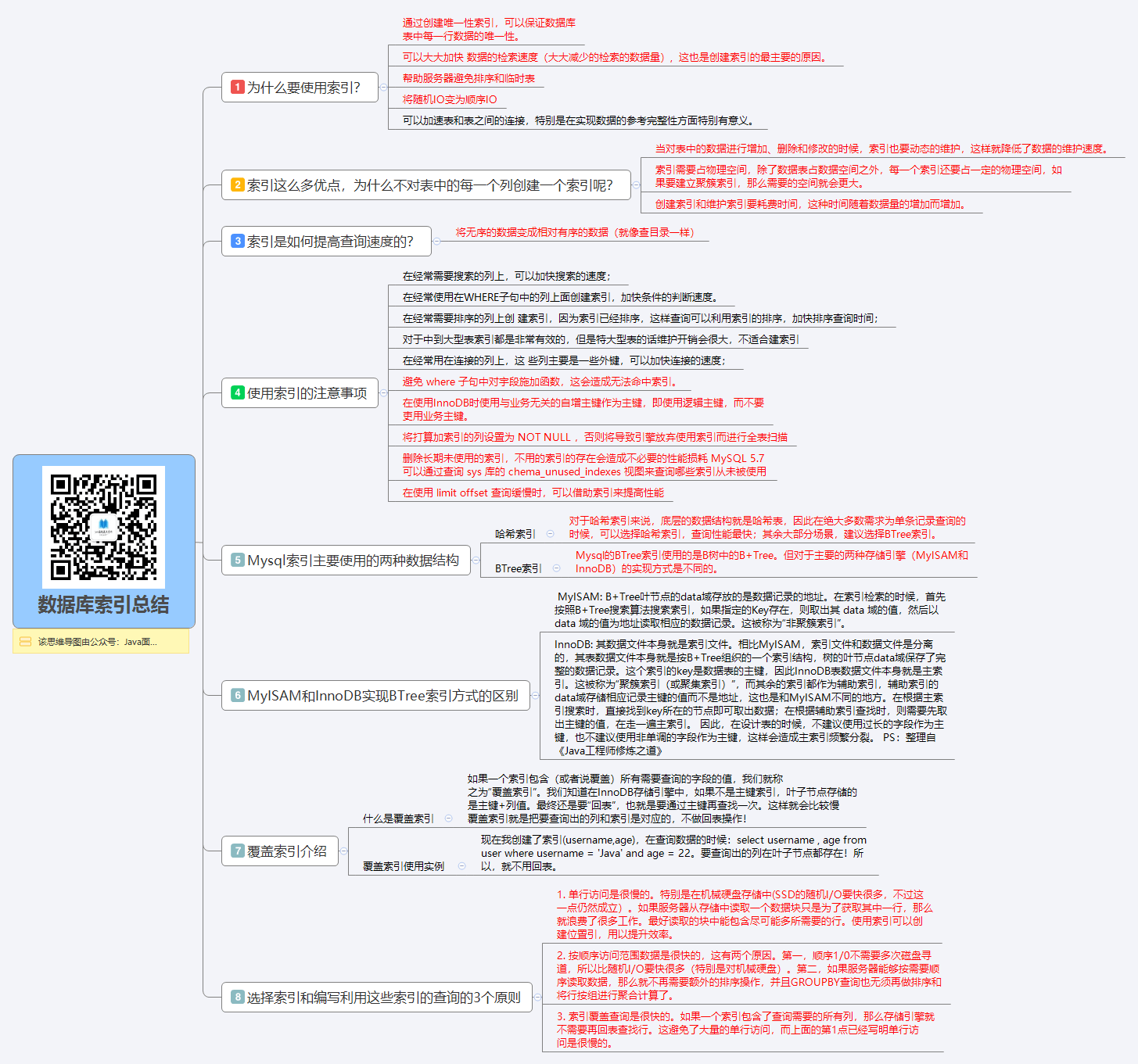
- MySQL索引使用的数据结构主要有BTree索引 和 哈希索引 。对于哈希索引来说,底层的数据结构就是哈希表,因此在绝大多数需求为单条记录查询的时候,可以选择哈希索引,查询性能最快;其余大部分场景,建议选择BTree索引。
- MySQL的BTree索引使用的是B树中的B+Tree,但对于主要的两种存储引擎的实现方式是不同的。
- MyISAM: B+Tree叶节点的data域存放的是数据记录的地址。在索引检索的时候,首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其 data 域的值,然后以 data 域的值为地址读取相应的数据记录。这被称为“非聚簇索引”。
- InnoDB: 其数据文件本身就是索引文件。相比MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按B+Tree组织的一个索引结构,树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。这被称为“聚簇索引(或聚集索引)”。而其余的索引都作为辅助索引,辅助索引的data域存储相应记录主键的值而不是地址,这也是和MyISAM不同的地方。在根据主索引搜索时,直接找到key所在的节点即可取出数据;在根据辅助索引查找时,则需要先取出主键的值,再走一遍主索引。 因此,在设计表的时候,不建议使用过长的字段作为主键,也不建议使用非单调的字段作为主键,这样会造成主索引频繁分裂。
索引思维导图 :索引导图(图片太大,下载到自己桌面吧)。
为什么使用索引?
- 通过创建唯一性索引, 可以保证数据库表中每一行数据的唯一性。
- 可以大大加快数据的检索速度(大大减少的检索的数据量),这也是创建索引的最主要的原因。
- 帮助服务器避免排序和临时表
- 将随机IO变为顺序IO
- 可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
索引这么多优点,为什么不对表中的每个列创建一个索引呢?
- 当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
- 索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。
- 创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
Mysq|索引主要使用的两种数据结构
哈希索引
对于哈希索引来说,底层的数据结构就是哈希表,因此在绝大多数需求为单条记录查询的
时候,可以选择哈希索引,查询性能最快:其余大部分场景,建议选择BTree索引。
B+树索引
Mysql的BTree索弓|使用的是B树中的B+ Tree。但对于主要的两种存储引擎(MylSAM和
InnoDB)的实现方式是不同的。
两种索引的适用场景:
- 如果是单条记录的查询,哈希索引是最佳的选择,但实际上日常的需求中我们多数是多条记录的查询,b+树索引有序,并且叶子节点指针相连,相对之下就比哈希索引快多了,我们一般情况下多数是区间查找,我们遍历所有叶子节点就能得到所有的数据,并且在大量数据需要装入内存时,b+树索引支持分批加载,同时树的高度较低,提高查找效率。
覆盖索引介绍
- 如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为”覆盖索引"。我们知道在InnoDB存储引擎中,如果不是主键索引,叶子节点存储的是主键+列值。最终还是要”回表”,也就是要通过主键再查找一-次。 这样就会比较慢。
- 覆盖索引就是把要查询出的列和索引是对应的,不做回表操作!
使用示例: - 现在我创建了索引l(username,age),在查询数据的时候:
select username , age from user where username = 'Java' and age= 22- 要查询出的列在叶子节点都存在!所以,就不用回表。
选择索引和编写利用这些索引的查询的3个原则
- 1.单行访问是很慢的。特别是在机械硬盘存储中(SSD的随机I/O要快很多,不过这一点仍然成立)。如果服务器从存储中读取一 个数据块只是为了获取其中一行,那么就浪费了很多工作。最好读取的块中能包含尽可能多所需要的行。 使用索引可以创建位置引,用以提升效率。
- 2.按顺序访问范围数据是很快的,这有两个原因。
- 第一,顺序I/O不需要多次磁盘寻道,所以比随机I/O要快很多(特别是对机械硬盘)。
- 第二,如果服务器能够按需要顺序读取数据,那么就不再需要额外的排序操作,并且GROUPBY查询也无须再做排序和将行按组进行聚合计算了。
- 3.索引覆盖查询是很快的。如果一个索引包含了查询需要的所有列,那么存储引擎就不需要再回表查找行。这避免了大量的单行访问,而上面的第1点已经写明单行访问是很慢的。
简单来说:一次查询尽量读取多的行数。最好按顺序访问范围数据,速度是很快的,因为避免了多次寻道操作,可以不需要额外的排序操作,建立覆盖索引时,避免回表再查。
本文章为转载内容,我们尊重原作者对文章享有的著作权。如有内容错误或侵权问题,欢迎原作者联系我们进行内容更正或删除文章。



















{kind=link}