目录
Apache Commons Compress 概述
本地文件解压缩代码示例
文件压缩并提供网络下载
Web 网络文件下载方式汇总
Apache Commons Compress 概述
1、Apache Commons Compress 官网:http://commons.apache.org/proper/commons-compress/index.html
2、Apache Commons Compress 库定义了一个用于处理 ar,cpio,Unix 转储,tar,zip,gzip,XZ,Pack200,bzip2、7z,arj,lzma,snappy,DEFLATE,lz4,Brotli,Zstandard,DEFLATE64 和 Z 文件的 API 。
3、当前 Compress 版本是 1.19,并且需要 Java 7 及以上支持。
现在 ParallelScatterZipCreator 会按照条目添加到存档的顺序来写入条目。 现在默认情况下解析额外的字段时 ZipArchiveInputStream和ZipFile 更具宽容性。 TarArchiveInputStream 具有新的宽松模式,该模式可能允许它读取某些已损坏的档案。 |
4、官网用户使用手册提供了各种压缩格式的处理方式(本文仅以常用的 zip 格式为例进行介绍):http://commons.apache.org/proper/commons-compress/examples.html
5、Apache Commons Compress 官网下载:http://commons.apache.org/proper/commons-compress/download_compress.cgi
6、可以从 Maven 中央仓库获取依赖:https://mvnrepository.com/artifact/org.apache.commons/commons-compress
<!-- https://mvnrepository.com/artifact/org.apache.commons/commons-compress -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-compress</artifactId>
<version>1.19</version>
</dependency>核心 API
1)压缩输入流,用于解压压缩文件:public abstract class ArchiveInputStream extends java.io.InputStream

2)压缩输处出流,用于压缩压缩文件:public abstract class ArchiveOutputStream extends java.io.OutputStream

3)压缩文件内部存档的条目,压缩文件内部的每一个被压缩文件都称为一个条目:public interface ArchiveEntry

本地文件解压缩代码示例
1、生产中常见的需求之一就是对服务器上的某些文件进行压缩,或者解压。本文以常用的 zip 格式为例进行介绍。
import org.apache.commons.compress.archivers.ArchiveEntry;
import org.apache.commons.compress.archivers.zip.Zip64Mode;
import org.apache.commons.compress.archivers.zip.ZipArchiveEntry;
import org.apache.commons.compress.archivers.zip.ZipArchiveInputStream;
import org.apache.commons.compress.archivers.zip.ZipArchiveOutputStream;
import java.io.*;
/**
* 压缩工具类
*
* @author helloworld
*/
public class ZipUtil {
/**
* 将文件打包成 zip 压缩包文件
*
* @param sourceFiles 待压缩的多个文件列表。只支持文件,不能有目录,否则抛异常。
* @param zipFile 压缩文件。文件可以不存在,但是目录必须存在,否则抛异常。如 C:\Users\Think\Desktop\aa.zip
* @param isDeleteSourceFile 是否删除源文件(sourceFiles)
* @return 是否压缩成功
*/
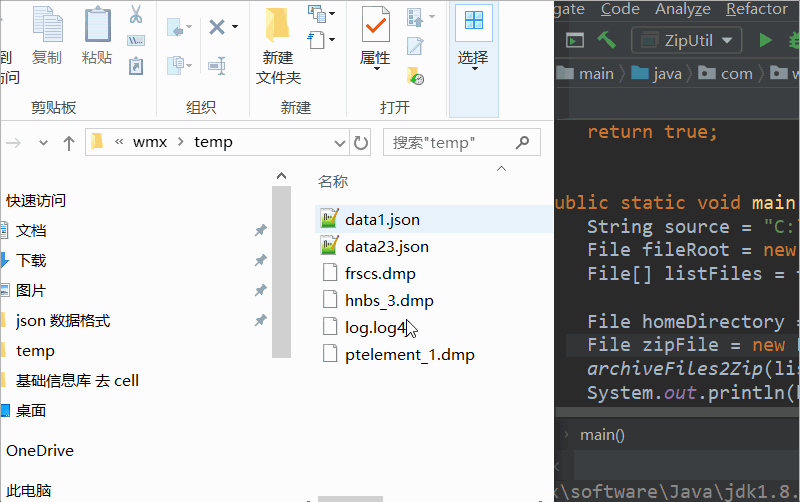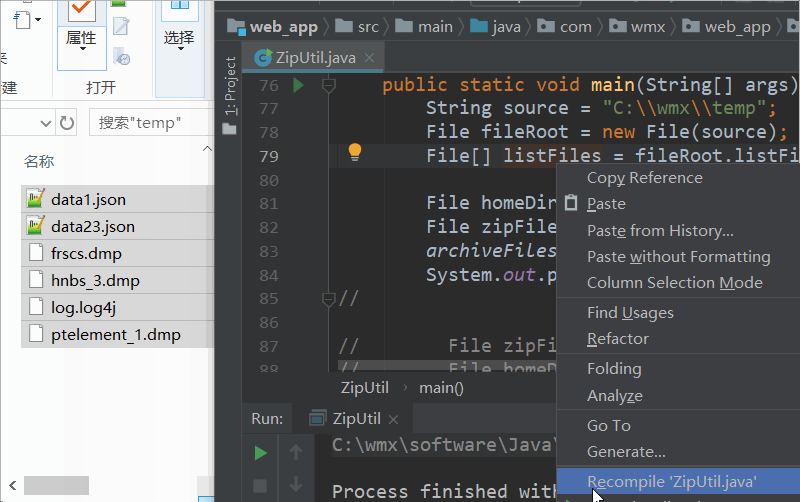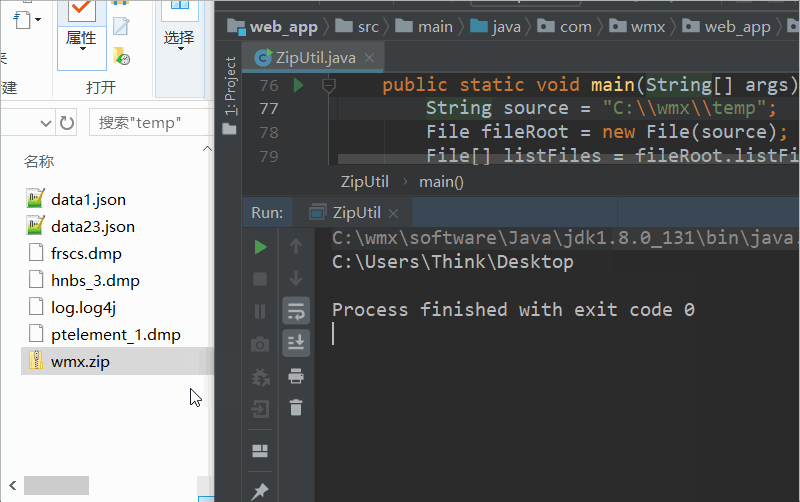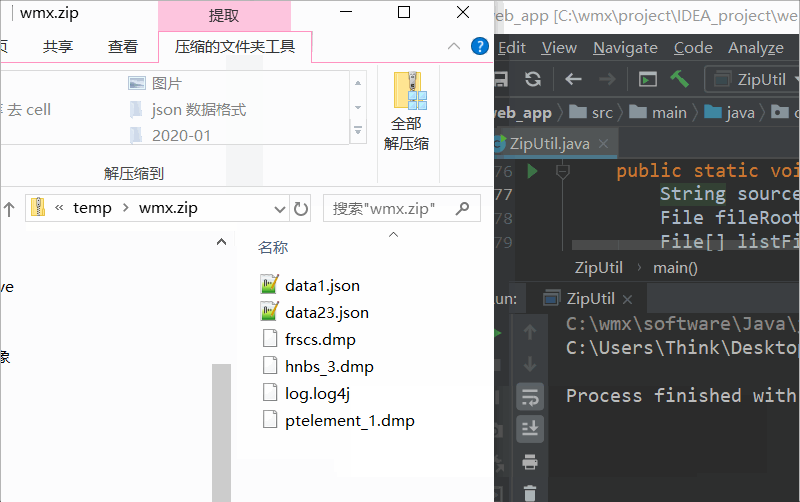
public static boolean archiveFiles2Zip(File[] sourceFiles, File zipFile, boolean isDeleteSourceFile) {
InputStream inputStream = null;//源文件输入流
ZipArchiveOutputStream zipArchiveOutputStream = null;//压缩文件输出流
if (sourceFiles == null || sourceFiles.length <= 0) {
return false;
}
try {
zipArchiveOutputStream = new ZipArchiveOutputStream(zipFile);//ZipArchiveOutputStream(File file) :根据文件构建压缩输出流,将源文件压缩到此文件.
//setUseZip64(final Zip64Mode mode):是否使用 Zip64 扩展。
// Zip64Mode 枚举有 3 个值:Always:对所有条目使用 Zip64 扩展、Never:不对任何条目使用Zip64扩展、AsNeeded:对需要的所有条目使用Zip64扩展
zipArchiveOutputStream.setUseZip64(Zip64Mode.AsNeeded);
for (File file : sourceFiles) {
//将每个源文件用 ZipArchiveEntry 实体封装,然后添加到压缩文件中. 这样将来解压后里面的文件名称还是保持一致.
ZipArchiveEntry zipArchiveEntry = new ZipArchiveEntry(file.getName());
zipArchiveOutputStream.putArchiveEntry(zipArchiveEntry);
inputStream = new FileInputStream(file);//获取源文件输入流
byte[] buffer = new byte[1024 * 5];
int length = -1;//每次读取的字节大小。
while ((length = inputStream.read(buffer)) != -1) {
//把缓冲区的字节写入到 ZipArchiveEntry
zipArchiveOutputStream.write(buffer, 0, length);
}
}
zipArchiveOutputStream.closeArchiveEntry();//写入此条目的所有必要数据。如果条目未压缩或压缩后的大小超过4 GB 则抛出异常
zipArchiveOutputStream.finish();//压缩结束.
if (isDeleteSourceFile) {//为 true 则删除源文件.
for (File file : sourceFiles) {
file.deleteOnExit();
}
}
} catch (IOException e) {
e.printStackTrace();
return false;
} finally {
//关闭输入、输出流,释放资源.
try {
if (null != inputStream) {
inputStream.close();
}
if (null != zipArchiveOutputStream) {
zipArchiveOutputStream.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
return true;
}
/**
* 将 zip 压缩包解压成文件到指定文件夹下
*
* @param zipFile 待解压的压缩文件。亲测 .zip 文件有效;.7z 压缩解压时抛异常。
* @param targetDir 解压后文件存放的目的地. 此目录必须存在,否则异常。
* @return 是否成功
*/
public static boolean decompressZip2Files(File zipFile, File targetDir) {
InputStream inputStream = null;//源文件输入流,用于构建 ZipArchiveInputStream
OutputStream outputStream = null;//解压缩的文件输出流
ZipArchiveInputStream zipArchiveInputStream = null;//zip 文件输入流
ArchiveEntry archiveEntry = null;//压缩文件实体.
try {
inputStream = new FileInputStream(zipFile);//创建输入流,然后转压缩文件输入流
zipArchiveInputStream = new ZipArchiveInputStream(inputStream, "UTF-8");
//遍历解压每一个文件.
while (null != (archiveEntry = zipArchiveInputStream.getNextEntry())) {
String archiveEntryFileName = archiveEntry.getName();//获取文件名
File entryFile = new File(targetDir, archiveEntryFileName);//把解压出来的文件写到指定路径
byte[] buffer = new byte[1024 * 5];
outputStream = new FileOutputStream(entryFile);
int length = -1;
while ((length = zipArchiveInputStream.read(buffer)) != -1) {
outputStream.write(buffer, 0, length);
}
outputStream.flush();
}
} catch (IOException e) {
e.printStackTrace();
return false;
} finally {
try {
if (null != outputStream) {
outputStream.close();
}
if (null != zipArchiveInputStream) {
zipArchiveInputStream.close();
}
if (null != inputStream) {
inputStream.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
return true;
}
}
文件压缩并提供网络下载
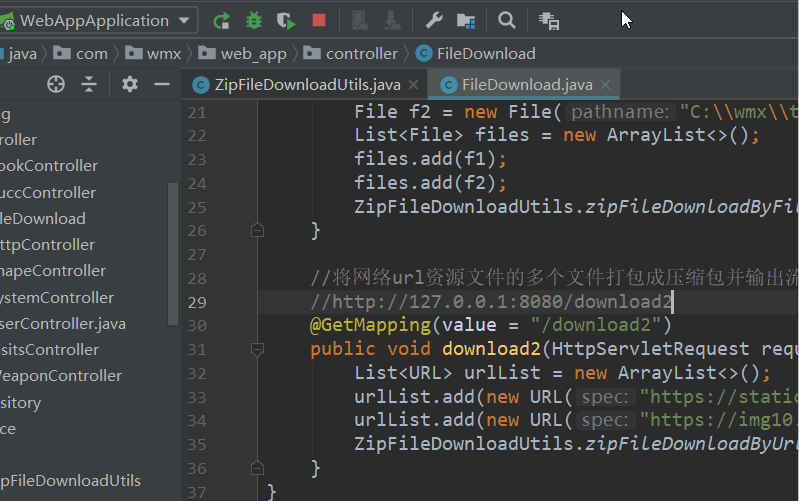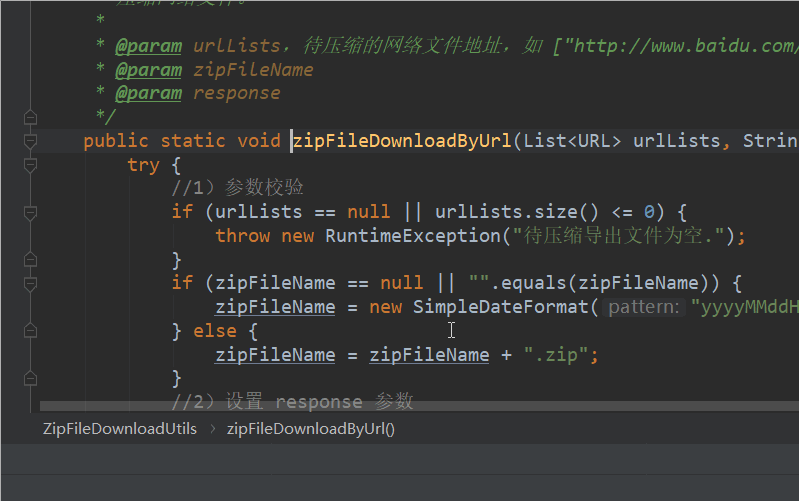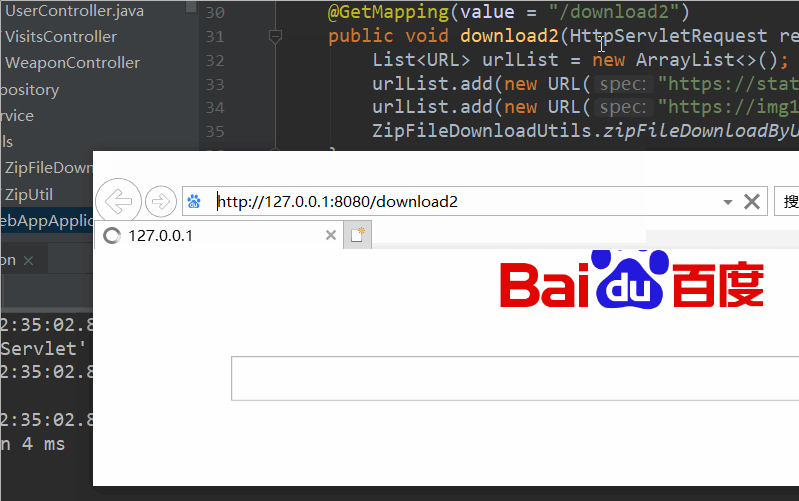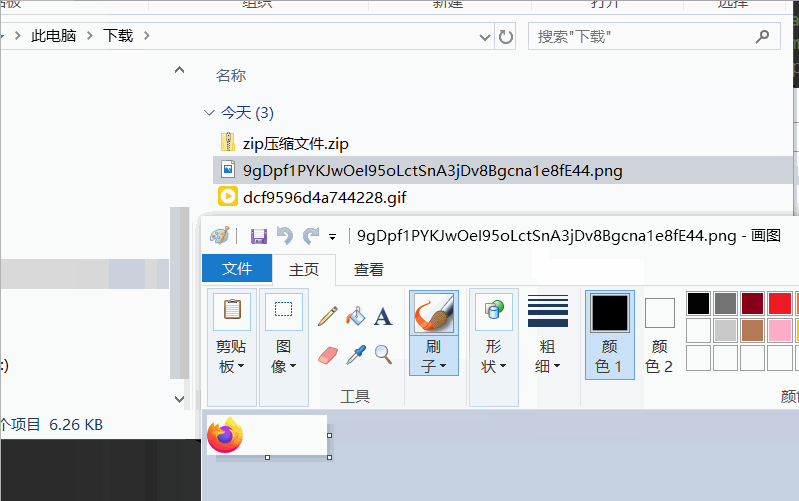
1、生产中另一个常见的需求是,用户下载的时候,有时候需要将多个文件打包成一个文件后提供下载。
import org.apache.commons.compress.archivers.ArchiveEntry;
import org.apache.commons.compress.archivers.zip.Zip64Mode;
import org.apache.commons.compress.archivers.zip.ZipArchiveEntry;
import org.apache.commons.compress.archivers.zip.ZipArchiveOutputStream;
import javax.servlet.ServletOutputStream;
import javax.servlet.http.HttpServletResponse;
import java.io.*;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLEncoder;
import java.text.SimpleDateFormat;
import java.util.*;
/**
* 压缩文件下载工具类。用于将多文件文件压缩后,提供给 ServletOutputStream 输出流共用户网页下载
*/
@SuppressWarnings("all")
public class ZipFileDownloadUtils {
/**
* 压缩本地多个文件并提供输出流下载
*
* @param filePaths :本地文件路径,如 ["C:\\wmx\\temp\\data1.json","C:\\wmx\\temp\\data2.json"]。只支持文件,不能有目录,否则抛异常。
* @param zipFileName :压缩文件输出的名称,如 "年终总结" 不含扩展名。默认文件当前时间。如 20200108111213.zip
* @param response :提供输出流
*/
public static void zipFileDownloadByFile(Set<String> filePaths, String zipFileName, HttpServletResponse response) {
try {
//1)参数校验
if (filePaths == null || filePaths.size() <= 0) {
throw new RuntimeException("待压缩导出文件为空.");
}
if (zipFileName == null || "".equals(zipFileName)) {
zipFileName = new SimpleDateFormat("yyyyMMddHHmmss").format(new Date()) + ".zip";
} else {
zipFileName = zipFileName + ".zip";
}
//2)设置 response 参数。这里文件名如果是中文,则导出乱码,可以
response.reset();
response.setContentType("content-type:octet-stream;charset=UTF-8");
response.setHeader("Content-Disposition", "attachment;filename=" + URLEncoder.encode(zipFileName, "utf-8"));
//3)通过 OutputStream 创建 zip 压缩流。如果是压缩到本地,也可以直接使用 ZipArchiveOutputStream(final File file)
ServletOutputStream servletOutputStream = response.getOutputStream();
ZipArchiveOutputStream zipArchiveOutputStream = new ZipArchiveOutputStream(servletOutputStream);
//4)setUseZip64(final Zip64Mode mode):是否使用 Zip64 扩展。
// Zip64Mode 枚举有 3 个值:Always:对所有条目使用 Zip64 扩展、Never:不对任何条目使用Zip64扩展、AsNeeded:对需要的所有条目使用Zip64扩展
zipArchiveOutputStream.setUseZip64(Zip64Mode.AsNeeded);
for (String filePath : filePaths) {
File file = new File(filePath);
String fileName = file.getName();
InputStream inputStream = new FileInputStream(file);
//5)使用 ByteArrayOutputStream 读取文件字节
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
byte[] buffer = new byte[1024];
int readLength = -1;
while ((readLength = inputStream.read(buffer)) != -1) {
byteArrayOutputStream.write(buffer, 0, readLength);
}
if (byteArrayOutputStream != null) {
byteArrayOutputStream.flush();
}
byte[] fileBytes = byteArrayOutputStream.toByteArray();//整个文件字节数据
//6)用指定的名称创建一个新的 zip 条目(zip压缩实体),然后设置到 zip 压缩输出流中进行写入.
ArchiveEntry entry = new ZipArchiveEntry(fileName);
zipArchiveOutputStream.putArchiveEntry(entry);
//6.1、write(byte b[]):从指定的字节数组写入 b.length 个字节到此输出流
zipArchiveOutputStream.write(fileBytes);
//6.2、写入此条目的所有必要数据。如果条目未压缩或压缩后的大小超过4 GB 则抛出异常
zipArchiveOutputStream.closeArchiveEntry();
if (byteArrayOutputStream != null) {
byteArrayOutputStream.close();
}
}
//7)最后关闭 zip 压缩输出流.
if (zipArchiveOutputStream != null) {
zipArchiveOutputStream.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 压缩本地多个文件并提供输出流下载。只支持文件,不能有目录,否则抛异常。
*
* @param fileLists :本地文件,如 ["C:\\wmx\\temp\\data1.json","C:\\wmx\\temp\\data2.json"]。
* @param zipFileName :压缩文件输出的名称,如 "年终总结" 不含扩展名。默认文件当前时间。如 20200108111213.zip
* @param response :提供输出流
*/
public static void zipFileDownloadByFile(List<File> fileLists, String zipFileName, HttpServletResponse response) {
if (fileLists == null || fileLists.size() <= 0) {
throw new RuntimeException("待压缩导出文件为空.");
}
Set<String> filePaths = new HashSet<>();
for (File file : fileLists) {
filePaths.add(file.getAbsolutePath());
}
zipFileDownloadByFile(filePaths, zipFileName, response);
}
/**
* 压缩网络文件。
*
* @param urlLists,待压缩的网络文件地址,如 ["http://www.baidu.com/img/bd_logo1.png"]
* @param zipFileName
* @param response
*/
public static void zipFileDownloadByUrl(List<URL> urlLists, String zipFileName, HttpServletResponse response) {
try {
//1)参数校验
if (urlLists == null || urlLists.size() <= 0) {
throw new RuntimeException("待压缩导出文件为空.");
}
if (zipFileName == null || "".equals(zipFileName)) {
zipFileName = new SimpleDateFormat("yyyyMMddHHmmss").format(new Date()) + ".zip";
} else {
zipFileName = zipFileName + ".zip";
}
//2)设置 response 参数
response.reset();
response.setContentType("content-type:octet-stream;charset=UTF-8");
response.setHeader("Content-Disposition", "attachment;filename=" + URLEncoder.encode(zipFileName, "utf-8"));
//3)通过 OutputStream 创建 zip 压缩流。如果是压缩到本地,也可以直接使用 ZipArchiveOutputStream(final File file)
ServletOutputStream servletOutputStream = response.getOutputStream();
ZipArchiveOutputStream zipArchiveOutputStream = new ZipArchiveOutputStream(servletOutputStream);
//4)setUseZip64(final Zip64Mode mode):是否使用 Zip64 扩展。
// Zip64Mode 枚举有 3 个值:Always:对所有条目使用 Zip64 扩展、Never:不对任何条目使用Zip64扩展、AsNeeded:对需要的所有条目使用Zip64扩展
zipArchiveOutputStream.setUseZip64(Zip64Mode.AsNeeded);
for (URL url : urlLists) {
String fileName = getNameByUrl(url);
InputStream inputStream = url.openStream();
//5)使用 ByteArrayOutputStream 读取文件字节
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
byte[] buffer = new byte[1024];
int readLength = -1;
while ((readLength = inputStream.read(buffer)) != -1) {
byteArrayOutputStream.write(buffer, 0, readLength);
}
if (byteArrayOutputStream != null) {
byteArrayOutputStream.flush();
}
byte[] fileBytes = byteArrayOutputStream.toByteArray();//整个文件字节数据
//6)用指定的名称创建一个新的 zip 条目(zip压缩实体),然后设置到 zip 压缩输出流中进行写入.
ArchiveEntry entry = new ZipArchiveEntry(fileName);
zipArchiveOutputStream.putArchiveEntry(entry);
//6.1、write(byte b[]):从指定的字节数组写入 b.length 个字节到此输出流
zipArchiveOutputStream.write(fileBytes);
//6.2、写入此条目的所有必要数据。如果条目未压缩或压缩后的大小超过4 GB 则抛出异常
zipArchiveOutputStream.closeArchiveEntry();
if (byteArrayOutputStream != null) {
byteArrayOutputStream.close();
}
}
//7)最后关闭 zip 压缩输出流.
if (zipArchiveOutputStream != null) {
zipArchiveOutputStream.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 压缩网络文件
*
* @param urlPaths 待压缩的网络文件地址,如 ["http://www.baidu.com/img/bd_logo1.png"]
* @param zipFileName
* @param response
*/
public static void zipFileDownloadByUrl(Set<String> urlPaths, String zipFileName, HttpServletResponse response) {
if (urlPaths == null || urlPaths.size() <= 0) {
throw new RuntimeException("待压缩导出文件为空.");
}
List<URL> urlList = new ArrayList<>();
for (String urlPath : urlPaths) {
try {
urlList.add(new URL(urlPath));
} catch (MalformedURLException e) {
e.printStackTrace();
}
}
zipFileDownloadByUrl(urlList, zipFileName, response);
}
/**
* 通过 url 获取文件的名称
*
* @param url,如 http://www.baidu.com/img/bd_logo1.png
* @return
*/
private static String getNameByUrl(URL url) {
String name = url.toString();
int lastIndexOf1 = name.lastIndexOf("/");
int lastIndexOf2 = name.lastIndexOf("\\");
if (lastIndexOf1 > 0) {
name = name.substring(lastIndexOf1 + 1, name.length());
} else if (lastIndexOf2 > 0) {
name = name.substring(lastIndexOf1 + 2, name.length());
}
return name;
}
}