
目录
相关原理
爬虫:从网上爬取数据,我使用的是Urllib库
分词:本次实验使用的是结巴分词,我们需要先导入 jieba的库。
词云:
设计思想
实现过程
结果
相关原理
爬虫:从网上爬取数据,我使用的是Urllib库

其语法如下,在本次实验中只使用了参数url。


在发送请求后,网站会返回相应的响应内容。urlopen对象提供获取网站响应内容的方法函数:

分词:本次实验使用的是结巴分词,我们需要先导入 jieba的库。
结巴分词的特点有
支持三种分词模式:
精确模式,试图将句子最精确地切开,适合文本分析;
全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
主要功能有:
jieba.cut 方法接受三个输入参数: 需要分词的字符串;cut_all 参数用来控制是否采用全模式;HMM 参数用来控制是否使用 HMM 模型
jieba.cut_for_search 方法接受两个参数:需要分词的字符串;是否使用 HMM 模型。该方法适合用于搜索引擎构建倒排索引的分词,粒度比较细
待分词的字符串可以是 unicode 或 UTF-8 字符串、GBK 字符串。注意:不建议直接输入 GBK 字符串,可能无法预料地错误解码成 UTF-8
jieba.cut 以及 jieba.cut_for_search 返回的结构都是一个可迭代的 generator,可以使用 for 循环来获得分词后得到的每一个词语(unicode),或者用
jieba.lcut 以及jieba.lcut_for_search 直接返回 list
jieba.Tokenizer(dictionary=DEFAULT_DICT) 新建自定义分词器,可用于同时使用不同词典。jieba.dt为默认分词器,所有全局分词相关函数都是该分词器的映射。
本次实验使用的是jieba.lcut这个函数进行分词。并使用Countter计数器进行统计词频。
词云:
Word Cloud库是优秀的词云展示第三方库,词云以词语为基本单位,更加直观和艺术的展示文本。通常的操作步骤:首先把文本分词处理,然后用空格拼接,最后再调用Word Cloud库函数处理。
设计思想
本次实验的整体设计思想分为四个部分
- 使用网络爬虫将网上的文章进行爬取下来存储到english.txt文件中
- 使用jieba分词将english.txt文件中的英文文章进行分词
- 进行分词后在进行统计词频并以字典的方式存储
- 将统计词频后的数据导入到词云中进行词云制作
实现过程
在进行爬取网页数据的过程中我使用的是Urllib库

使用下方函数进行爬取

使用下方函数将爬取的数据保存到english.txt文本文档中

在进行文本分词的时候,我使用的是jieba库

使用下方函数进行分词

在进行统计词频的时候,我使用Count计数器

使用下方函数进行统计词频,并以字典的形式保存。

我们使用一个for循环来查找出现频率最高的十五个单词

同样使用for循环来查找长度大于6并包含6的单词的个数

使用wordcloud包进行制作词云

制作词云,并导入统计词频后的文本

最后保存词云到同名目录下即可

结果
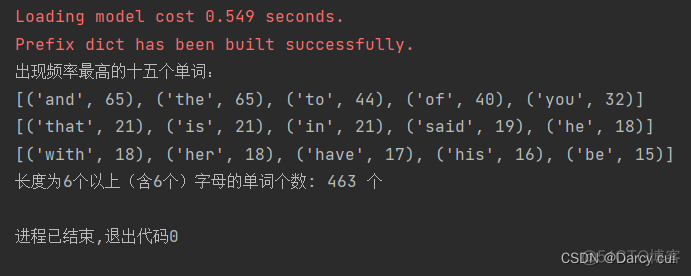
输出结果:
词云图:

源码
# author: #
# 输入库
import jieba
import wordcloud
from collections import Counter
from urllib.request import urlopen
textPage=urlopen("http://www.pythonscraping.com/pages/warandpeace/chapter1.txt")
fileObject = open('english.txt', 'wb+') # "wb+"是指 按二进制的方式打开
for ip in textPage:
fileObject.write(ip)
# fileObject.write('\n')
fileObject.close()
print(textPage.read())
from pathlib import Path
# 读取后关闭txt文件
file = open("english.txt", "r", encoding="utf-8") # 文件格式是utf-8,文件名是xxx.txt
t = file.read()
file.close()
# jieba分词
ls = jieba.lcut(t)
txt = " ".join(ls)
count1 = Counter(ls)
most_count1=count1.most_common()
words_list1 = []
#统计出现频率最高的十五个单词
for i in most_count1:
if len(i[0]) >=2 and len(i[0]) <=100:
words_list1.append(i)
print("出现频率最高的十五个单词:")
print(words_list1[:5])
print(words_list1[5:10])
print(words_list1[10:15])
num = 0
for i in most_count1:
if len(i[0]) >=6 :
num+= 1
print("长度为6个以上(含6个)字母的单词个数:",num,"个")
# words = jieba.lcut(text_content)
# 用Counter方法计算单词频率数
# 设置词云图
w = wordcloud.WordCloud(
font_path="C:/Windows/Fonts/STXINGKA.TTF", # 词云字体
width=1000, # 图片宽度
height=800, # 图片高度
background_color="white") # 图片背景颜色
# 将文字导入词云
w.generate(txt)
# 保存词云图
w.to_file("wordcloud.png")



















