
数据存储实体-区域
1:表按照“水平”的方式划分成一个或多个“区域”(region)
2:每个区域都包含一个随机id,区域内的行也是按行键有序的
3:最初每张表包含一个区域,当表增大超过阈值后,这个区域被自动分割成两个相同大小的区域
4:区域是Hbase中分布式存储和负责均衡的最小单元,以该最小单元的形式分布在集群内
区域的管理
区域服务器(Region Server)
1:为区域的访问提供服务,直接为用户提供服务
2:负责维护区域的合并与分割
3:负责数据存持久化
主服务器(Master Server)
1:管理区域服务器
2:指派区域服务器对特定区域服务
3:恢复失效的区域服务器
注释:
HRegion 是 Hbase 中分布式存储和负载均衡的最小单元。最小单元就表示不同的Hregion可以分布在不同的
HRegion server 上。但一个 Hregion 是不会拆分到多个server上的。
向表中写入数据的过程:
1:首先写入MemStore,同时写入HLog(日志是累加的,不断往结尾写,因为MemStore是基于内存的易于丢失,当
丢失时在HLog里面恢复)
2:MemStore到达一定大小的时候,MemStore会flush(flush时候单独起一个线程,不影响读)成一个
StoreFile(HFile文件)
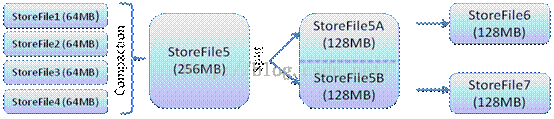
3:StoreFile的数量达到一定阀值,会触发compact将多个StoreFile合并成1个StoreFile
4:当单个StoreFile达到一定大小的时候,会触发split,将当前的Region拆分成2个Region,并且分发到
不同的Region Server上
Hstore是怎样工作的

自我领会
Region在Region Server上面,一个HRegion(一个java对象)对应一个Region,一个Hregion对应一个
或多个HStore,一个HStore对应一个列族,一个HStore主要有两个对象,一个MemStore(基于对象),一个
StoreFile(基于文件)
HLog
MemStore的同时,也会写一份数据到HLog文件中,HLog文件定期会滚动出新的,并删除旧的文件(已持久化
到StoreFile中的数据)。
2:Store在系统正常工作的前提下是没有问题的,但是在分布式系统环境中,无法避免系统出错或者宕机,因此
一旦RegionServer意外退出,MemStore中的内存数据将会丢失,于是引入了HLog。
3:当RegionServer意外终止后,Master会通过Zookeeper感知到,Master首先会处理遗留的 HLog文件,将其中
不同Region的Log数据进行拆分,分别放到相应region的目录下,然后再将失效的region重新分配,领取到这
些region的RegionServer在Load Region的过程中,会发现有历史HLog需要处理,因此会Replay HLog中的数
据到MemStore中,然后flush到StoreFiles,完成数据恢复。
RegionServer内部结构示意图
")
HBase写流程和写HLog的阶段点.
向HBase Put数据时通过HBaseClient-->连接ZooKeeper--->-ROOT--->.META.-->RegionServer-->Region:
Region写数据之前会先检查MemStore.
1. 如果此Region的MemStore已经有缓存已有写入的数据, 则直接返回;
2. 如果没有缓存, 写入HLog(WAL), 再写入MemStore.成功后再返回.
MemStore内存达到一定的值调用flush成为StoreFile,存到HDFS.
在对HBase插入数据时,插入到内存MemStore所以很快,对于安全性不高的应用可以关闭HLog,可以获得更高的写性能.
HLog的生命周期
这里就涉及到HLog的生命周期问题了.如果HLog的logSeqNum对应的HFile已经存储在HDFS了(主要是比较HLog的logSeqNum是否比与其对应的表的HDFS StoreFile的maxLongSeqNum小),那么HLog就没有存在的必要了.移动到.oldlogs目录,最后删除.
反过来如果此时系统down了,可以通过HLog把数据从HDFS中读取,把要原来Put的数据读取出来, 重新刷新到HBase.
比如现在该rs下有4个文件,储存的是4个region的信息:
file1: RegionA,4表示的是文件名是file1,其中存储了一个entry其regionname是reginA,其seqNum是4,seqnum是递增的且新建的文件的seq比原先的大
file1: RegionA,4 RegionB,5 RegionC,6 RegionD,7
file2: RegionA,8 RegionB,9 RegionC,10
file3: RegionA,11 RegionB,12 RegionD,13
file4: RegionB,14
如上面所示,假设上面4个文件都存在,且假设此时lastSeqWritten 中存储的是RegionB,14
因为lastSeqWritten储存的是最新加入的entries且并没有被flush,这说明Region A,C,D都已经flush结束的,而file1,2,3,由于其seqnum都小于14,认为这些file都已经flush成功了,可以移除了,因为A,C,D都已经flush成功,而如果1,2,3中的Region B未flush那么此时lastSeqWritten存储的肯定不是14了而是小于十四的未flush的seq


















