前言
在web渗透过程中,Web指纹识别是信息收集环节中一个比较重要的步骤,通过一些开源的工具、平台或者手工检测CMS系统是公开的CMS程序还是二次开发至关重要,能准确的获取CMS类型、Web服务组件类型及版本信息可以帮助安全工程师快速有效的去验证已知漏洞。
在指纹识别的学习过程中,借用了很多开源的工具和指纹库,如fofa、WhatWeb、w11scan、WebEye、御剑等等,在此感谢各种大佬的无私奉献。本文并无技术上的创新和突破,只是把一些指纹库重新进行了整合和梳理并进行了开源
常见指纹检测的对象
1、CMS信息:比如大汉CMS、织梦、帝国CMS、phpcms、ecshop等;
2、前端技术:比如HTML5、jquery、bootstrap、pure、ace等;
3、Web服务器:比如Apache、lighttpd, Nginx, IIS等;
4、应用服务器:比如Tomcat、Jboss、weblogic、websphere等;
5、开发语言:比如PHP、Java、Ruby、Python、C#等;
6、操作系统信息:比如linux、win2k8、win7、kali、centos等;
7、CDN信息:是否使用CDN,如cloudflare、360cdn、365cyd、yunjiasu等;
8、WAF信息:是否使用waf,如Topsec、Jiasule、Yundun等;
9、IP及域名信息:IP和域名注册信息、服务商信息等;
10、端口信息:有些软件或平台还会探测服务器开放的常见端口。
常见的指纹识别方式
1、特定文件的MD5
一些网站的特定图片文件、js文件、CSS等静态文件,如favicon.ico、css、logo.ico、js等文件一般不会修改,通过爬虫对这些文件进行抓取并比对md5值,如果和规则库中的Md5一致则说明是同一CMS。这种方式速度比较快,误报率相对低一些,但也不排除有些二次开发的CMS会修改这些文件。
2、正常页面或错误网页中包含的关键字
先访问首页或特定页面如robots.txt等,通过正则的方式去匹配某些关键字,如Powered by Discuz、dedecms等。
或者可以构造错误页面,根据报错信息来判断使用的CMS或者中间件信息,比较常见的如tomcat的报错页面。
3、请求头信息的关键字匹配
根据网站response返回头信息进行关键字匹配,whatweb和Wappalyzer就是通过banner信息来快速识别指纹,之前fofa的web指纹库很多都是使用的这种方法,效率非常高,基本请求一次就可以,但搜集这些规则可能会耗时很长。而且这些banner信息有些很容易被改掉。
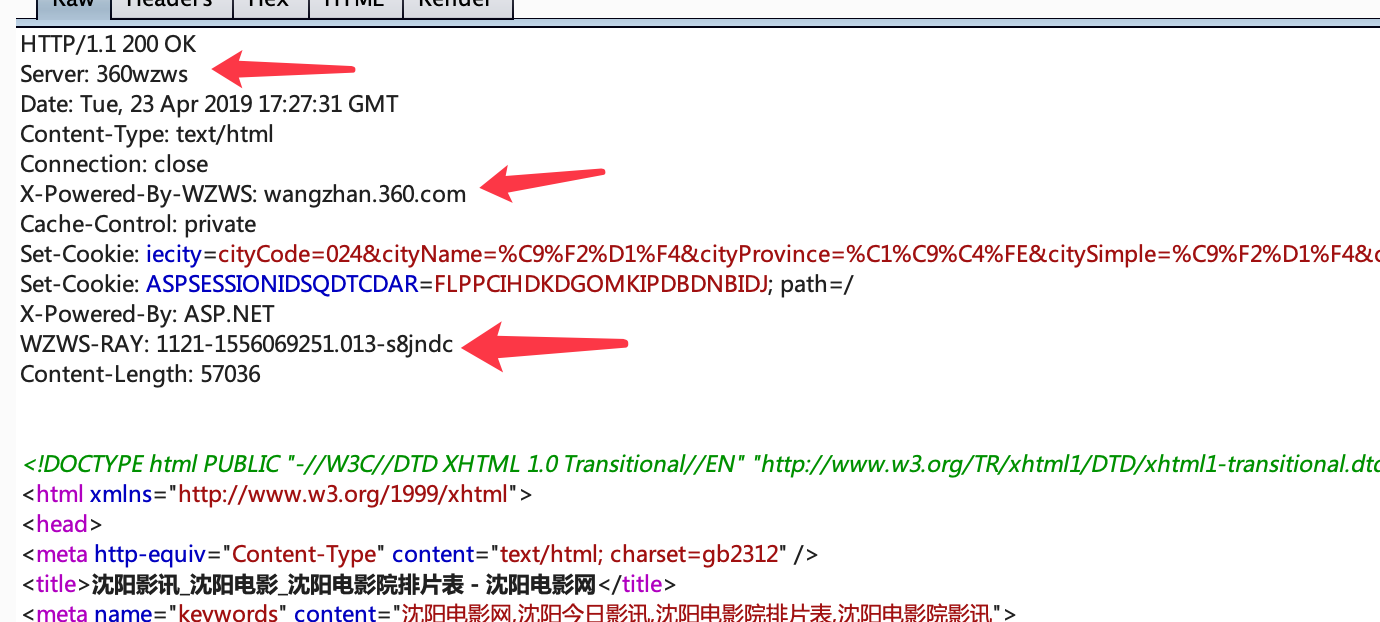
根据response header一般有以下几种识别方式:
(1)查看http响应报头的X-Powered-By字段来识别;
(2)根据Cookies来进行判断,比如一些waf会在返回头中包含一些信息,如360wzws、Safedog、yunsuo等;
(3)根据header中的Server信息来判断,如DVRDVS-Webs、yunjiasu-nginx、Mod_Security、nginx-wallarm等;
(4)根据WWW-Authenticate进行判断,一些路由交换设备可能存在这个字段,如NETCORE、huawei、h3c等设备。
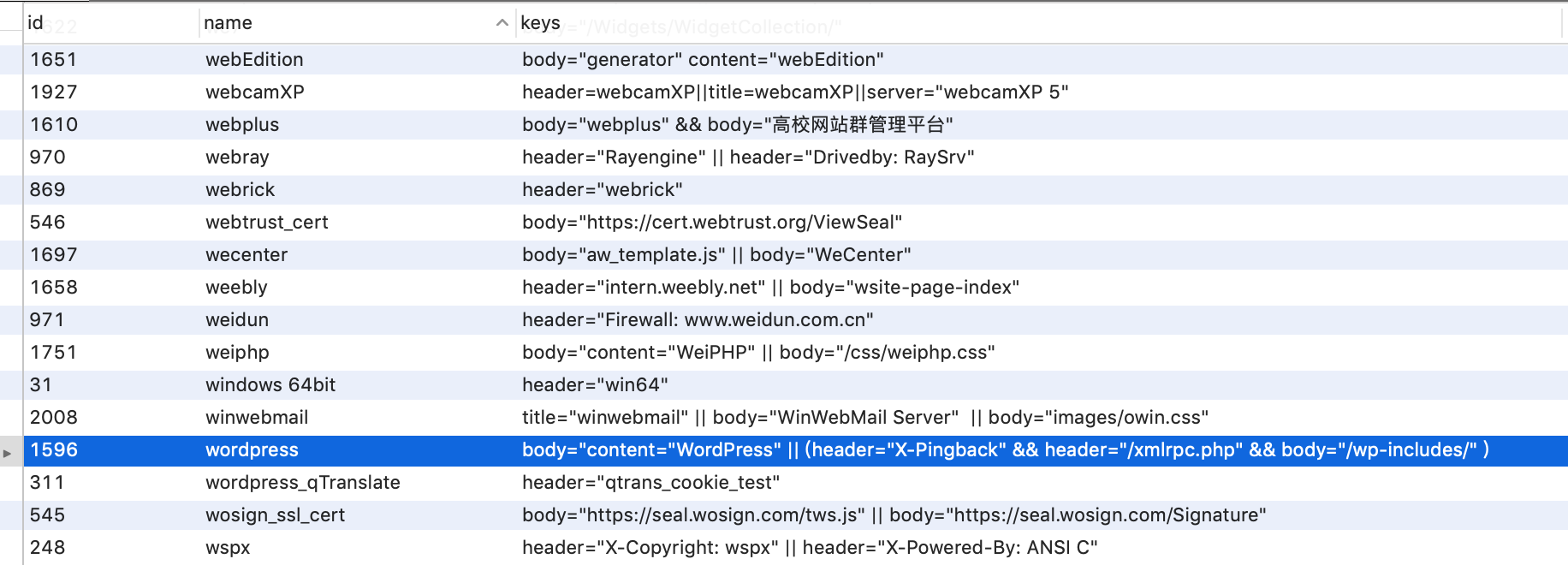
4、部分URL中包含的关键字,比如wp-includes、dede等URL关键特征
通过规则库去探测是否有相应目录,或者根据爬虫结果对链接url进行分析,或者对robots.txt文件中目录进行检测等等方式,通过url地址来判别是否使用了某CMS,比如wordpress默认存在wp-includes和wp-admin目录,织梦默认管理后台为dede目录,solr平台可能使用/solr目录,weblogic可能使用wls-wsat目录等。
5、开发语言的识别
web开发语言一般常见的有PHP、jsp、aspx、asp等,常见的识别方式有:
(1)通过爬虫获取动态链接进行直接判断是比较简便的方法。
asp判别规则如下<a[^>]*?href=('|")[^http][^>]*?\.asp(\?|\#|\1),其他语言可替换相应asp即可。
(2)通过
X-Powered-By进行识别
比较常见的有X-Powered-By: ASP.NET或者X-Powered-By: PHP/7.1.8
(3)通过
Set-Cookie进行识别
这种方法比较常见也很快捷,比如Set-Cookie中包含PHPSSIONID说明是php、包含JSESSIONID说明是java、包含ASP.NET_SessionId说明是aspx等。
指纹识别工具
在研究指纹识别技术的时候,不可避免的分析了大量指纹识别工具,在此将自己用过的几个感觉不错的工具和平台介绍一下。
国外指纹识别工具
WhatWeb(推荐指数★★★★★)
下载地址:https://github.com/urbanadventurer/WhatWeb
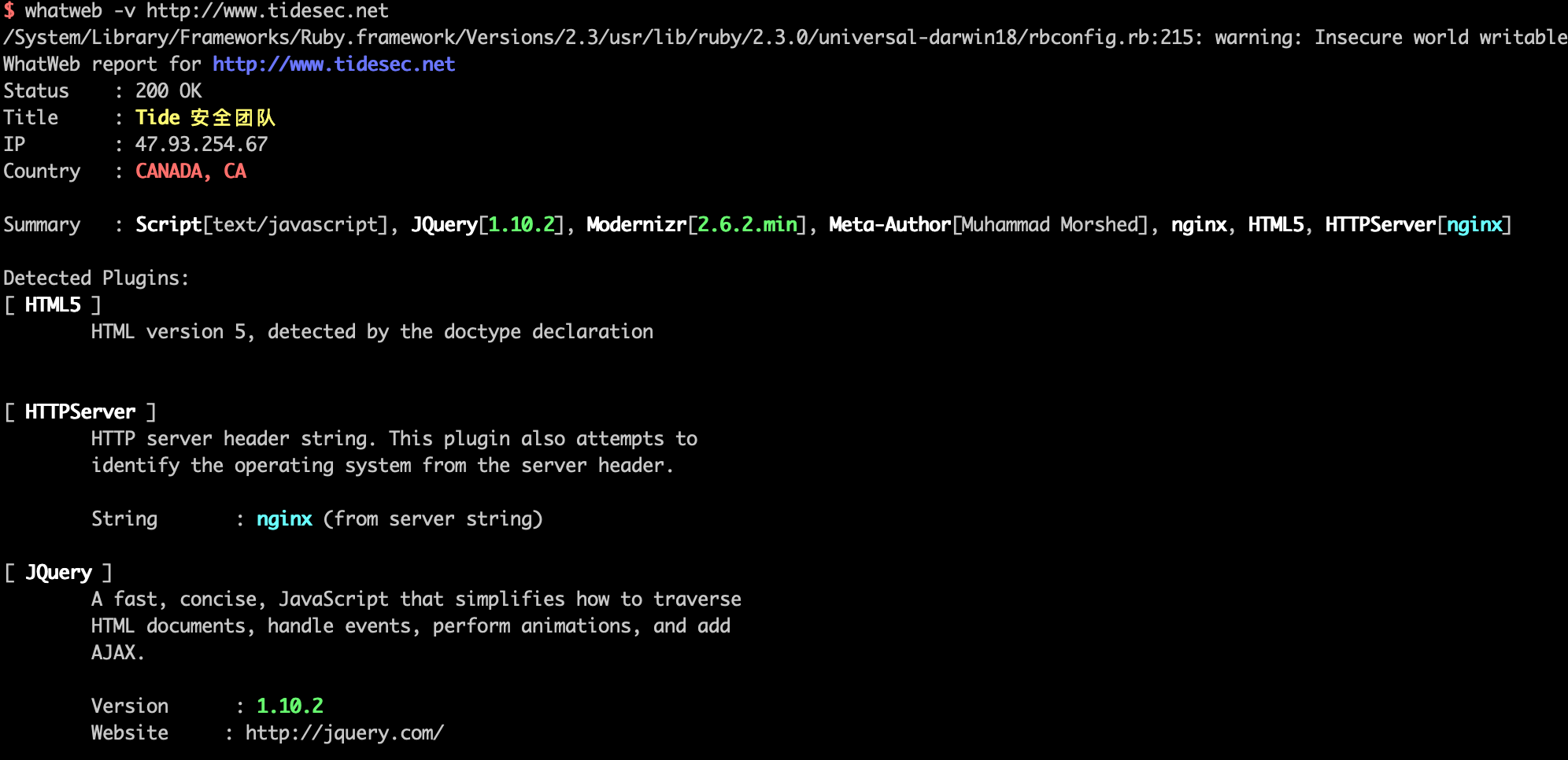
Whatweb 是一个开源的网站指纹识别软件,拥有超过1700+个插件,它能识别的指纹包括 cms 类型、博客平台、网站流量分析软件、javascript 库、网站服务器,还可以识别版本号、邮箱地址、账户 id、web 框架模块等。
Whatweb 是基于 ruby 语言开发,因此可以安装在具备 ruby 环境的系统中,目前支持 Windows/Mac OSX/Linux。
在debian/ubuntu系统下可直接`apt-get install whatweb`,kali已自带。使用非常简单whatweb 即可,也可以加参数-v显示更详细的信息。
Wapplyzer(推荐指数★★★★)
下载地址:https://github.com/AliasIO/Wappalyzer
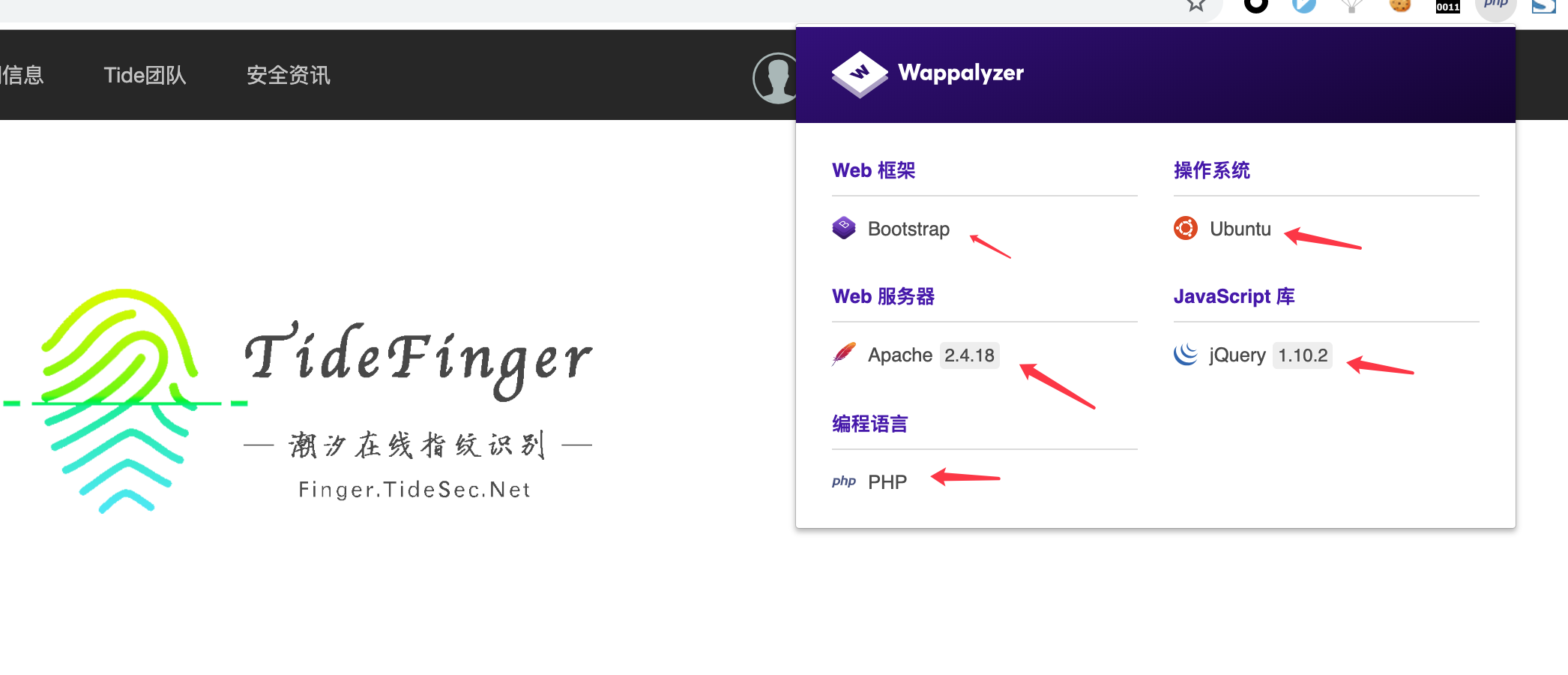
Wappalyzer 是一个实用的跨平台网站分析工具,用于帮助开发者、研究者和设计者检测网页使用的是什么技术,以更好地衡量自己的项目中该使用什么技术。Wappalyzer 的功能和 BuiltWith 类似,可检测内容管理系统(CMS),电子商务平台、Web服务器、JavaScript框架和已安装的分析工具等。
Wappalyzer可直接在chrome或火狐的应用商城直接搜索安装。Wappalyzer目前可识别65个大类的1216个应用,查看可检测的应用程序列表:https://wappalyzer.com/applications
Whatruns(推荐指数★★★★)
Whatruns是为chrome开发的一款web指纹识别程序,还可以显示托管的CDN、wordpress插件、wordpress字体等,拥有丰富的插件支持。
跟Wappalyzer安装类似,Whatruns可直接在chrome应用商城直接搜索安装。
安装完成后,通过插件图标来获取服务的详细运行信息,效果如下。有时候信息会比Wapplyzer还详细一些,但有时候获取速度稍慢。

Plecost(推荐指数★★★)
下载地址:https://github.com/iniqua/plecost
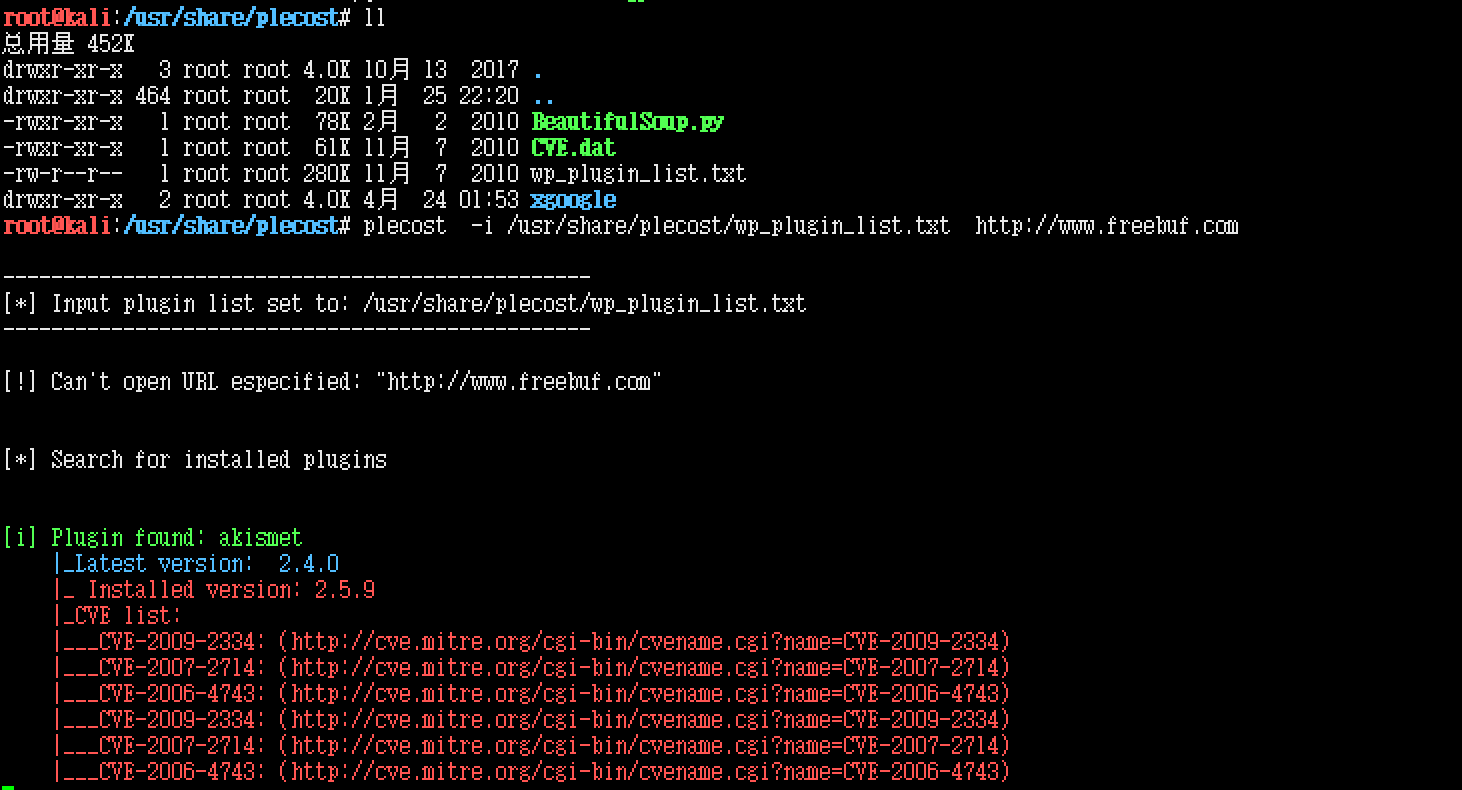
Plecost是Wordpress博客引擎的漏洞指纹识别和漏洞查找器,能识别Wordpress版本并能查找到cve,不过访问不了google的话可能有些功能就受限了。Plecost基于python架构,利用了Beautiful Soup来解析html、xml文件识别网站使用的插件及版本。
使用也比较方便plecost -i /usr/share/plecost/wp_plugin_list.txt http://www.freebuf.com
BlindElephant(推荐指数★★)
下载地址:https://github.com/lokifer/BlindElephant
BlindElephant是一款Web应用程序指纹识别工具。该工具可以读取目标网站的特定静态文件,计算其对应的哈希值,然后和预先计算出的哈希值做对比,从而判断目标网站的类型和版本号。目前,该工具支持15种常见的Web应用程序的几百个版本。同时,它还提供WordPress和Joomla的各种插件。该工具还允许用户自己扩展,添加更多的版本支持。
不过该软件最新更新是在2013年,插件库应该算比较旧的了。
下载及安装可参考https://github.com/lokifer/BlindElephant,kali中已经内置。
使用命令:BlindElephant.py http://www.freebuf.com

国内指纹识别工具
御剑web指纹识别程序
下载地址:https://www.webshell.cc/4697.html
御剑web指纹识别程序是御剑大神开发的一款CMS指纹识别小工具,该程序由.NET 2.0框架开发,配置灵活、支持自定义关键字和正则匹配两种模式、使用起来简洁、体验良好。在指纹命中方面表现不错、识别速度很快、但目前比较明显的缺陷是指纹的配置库偏少。
windows下图形界面,比较亲民,扫描速度略慢,指纹库略少,可手工更新。
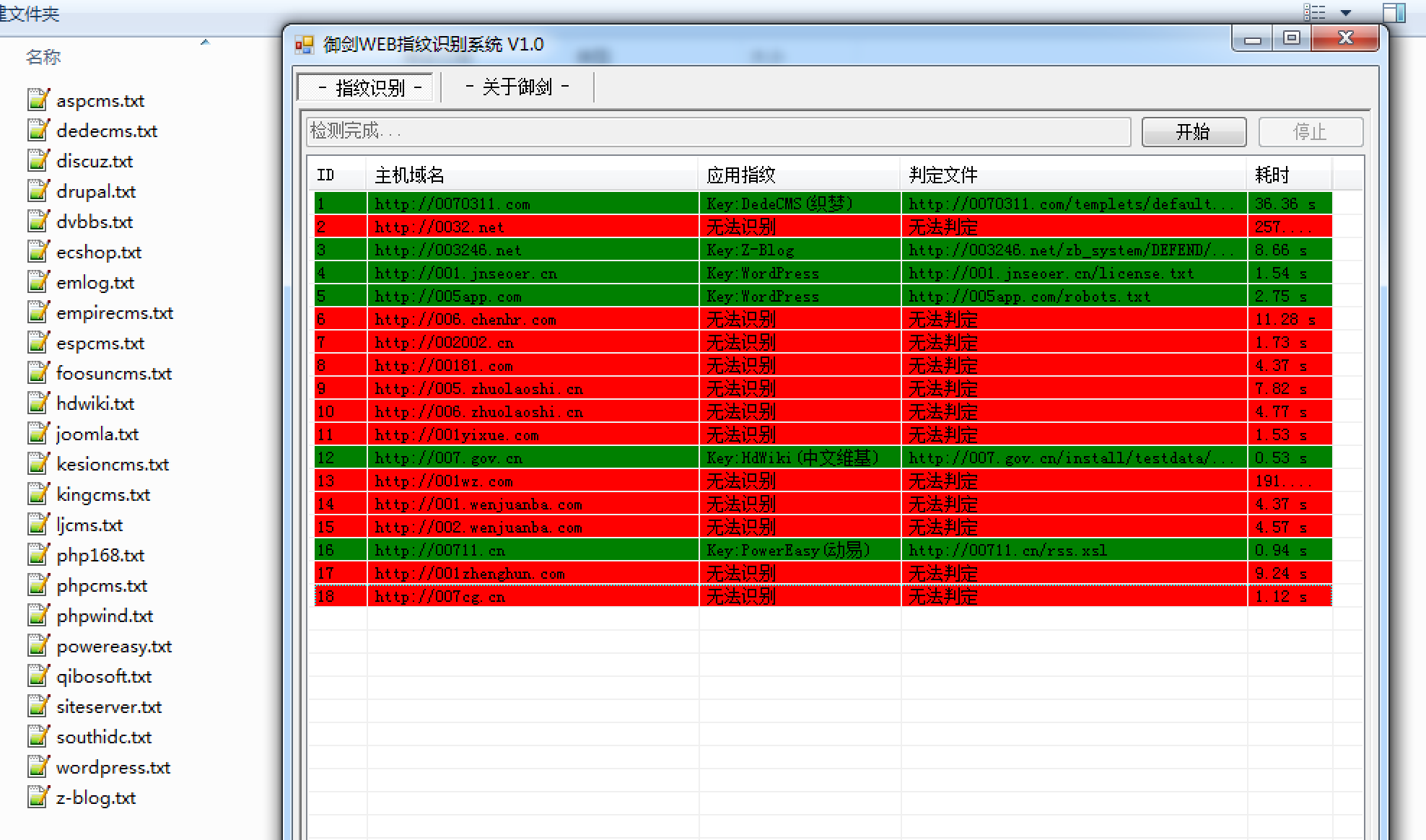
Test404轻量WEB指纹识别
下载地址:https://www.test404.com/post-1618.html
Test404轻量WEB指纹识别程序是一款CMS指纹识别小工具,配置灵活、支持自行添加字典、使用起来简洁、体验良好。在指纹命中方面表现不错、识别速度很快。可手动更新指纹识别库,而且该软件在2019.04月刚刚更新了一版。

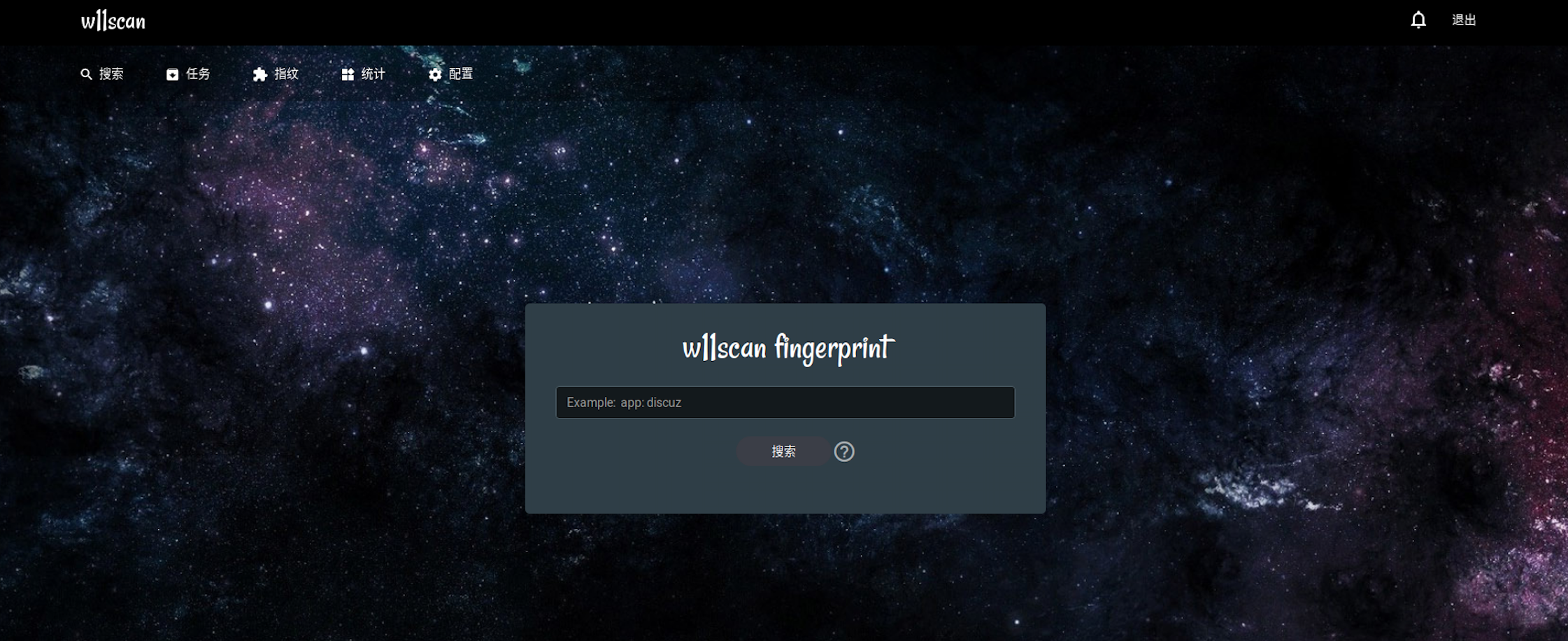
w11scan分布式WEB指纹识别平台
w11scan是一款分布式的WEB指纹识别系统(包括CMS识别、js框架、组件容器、代码语言、WAF等等),管理员可以在WEB端新增/修改指纹,建立批量的扫描任务,并且支持多种搜索语法。
安装和下载可参考:https://github.com/w-digital-scanner/w11scan
手工安装稍微复杂,不过作者提供了docker部署,方便很多,使用了Mongodb,内置了1800多条常见的指纹,可以识别多达538种常见CMS,当然也可以手工添加指纹。
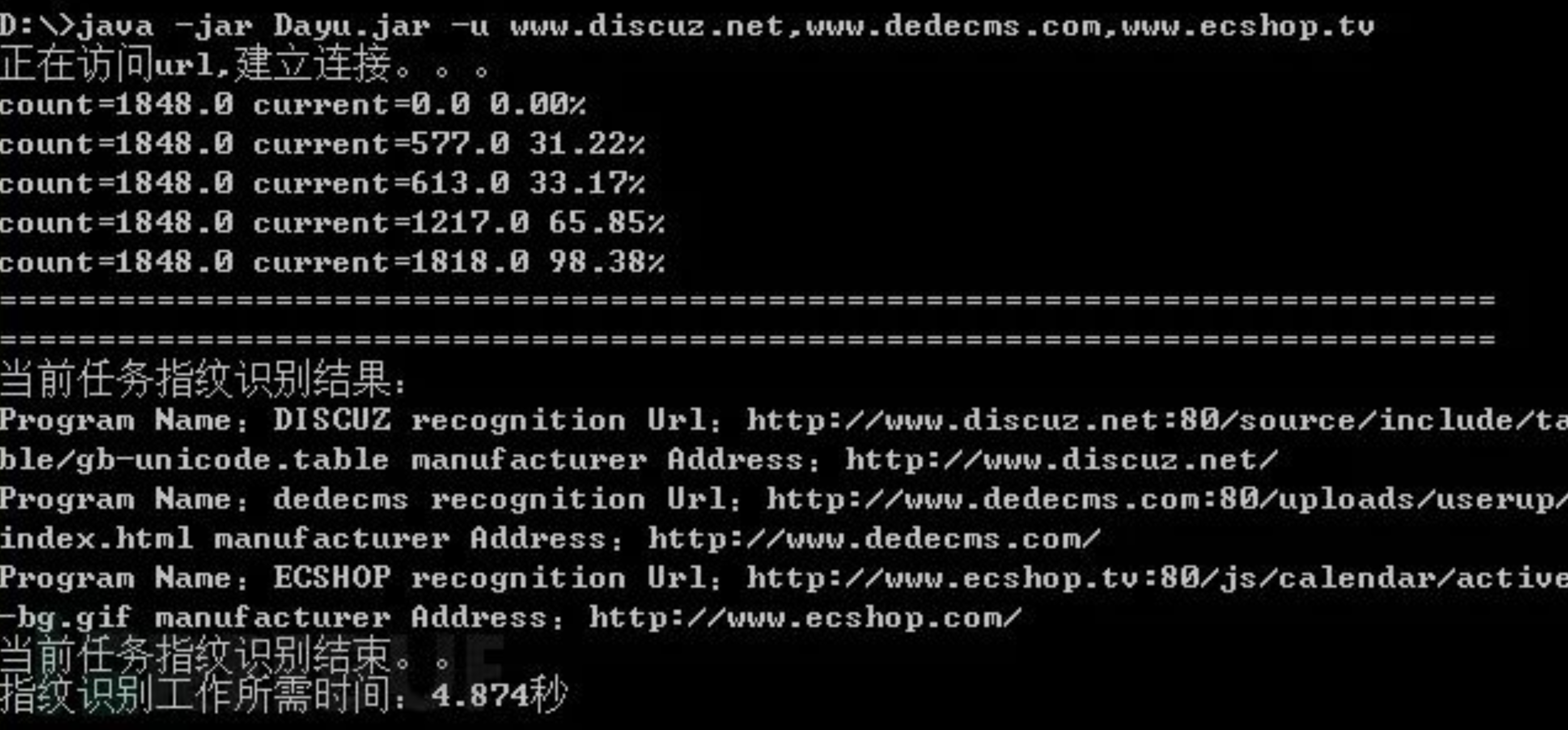
Dayu指纹识别工具
下载地址:https://github.com/Ms0x0/Dayu
“大禹”为一款c/s结构jar文件工具,只需本地安装java环境,加参数-u即可,具体设置参数可参考github介绍。
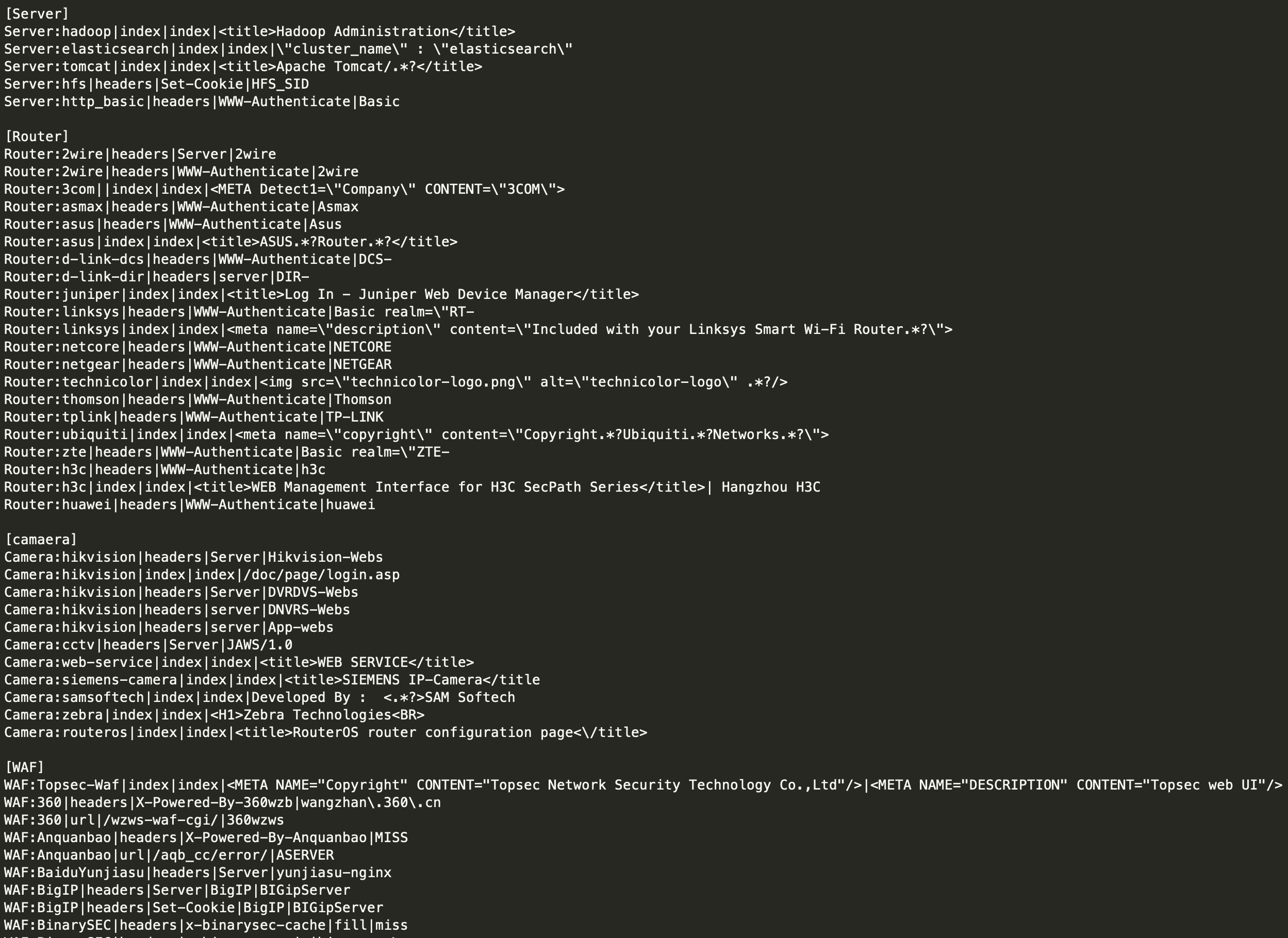
WebEye
下载地址:https://github.com/zerokeeper/WebEye/
WebEye可快速简单地识别WEB服务器类型、CMS类型、WAF类型、WHOIS信息、以及语言框架,使用异步实现指纹的快速识别。
识别速度比较快,不过指纹库不是很多,指纹库不是基于md5之类的,而是类似于fofa通过http头信息、关键字等进行快速识别。
作者对指纹进行了分类,如摄像头、waf、cdn、网络设备等,很多指纹都是精心搜集的。
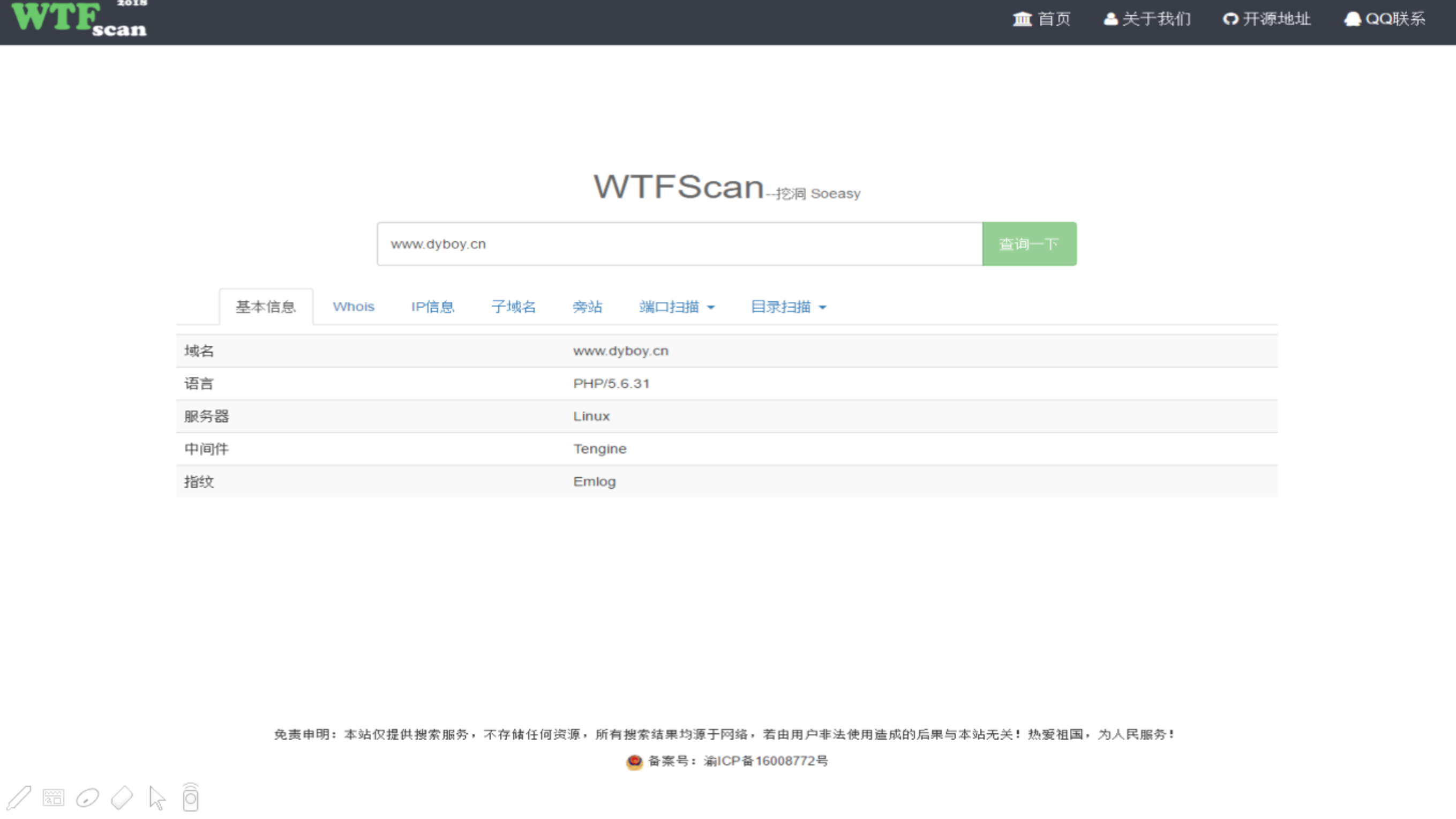
WTF_Scan
下载地址:https://github.com/dyboy2017/WTF_Scan
WTF团队出品的指纹识别平台,包括的功能也相对比较多,除了指纹识别外,还有DNS解析、子域名、CDN、端口扫描、敏感目录等。
不过就单独说指纹规则来说,不算很多,可以自己添加完善,在WTF_Scan/wtf/app/api/cms/cms.txt文件中进行指纹修改。
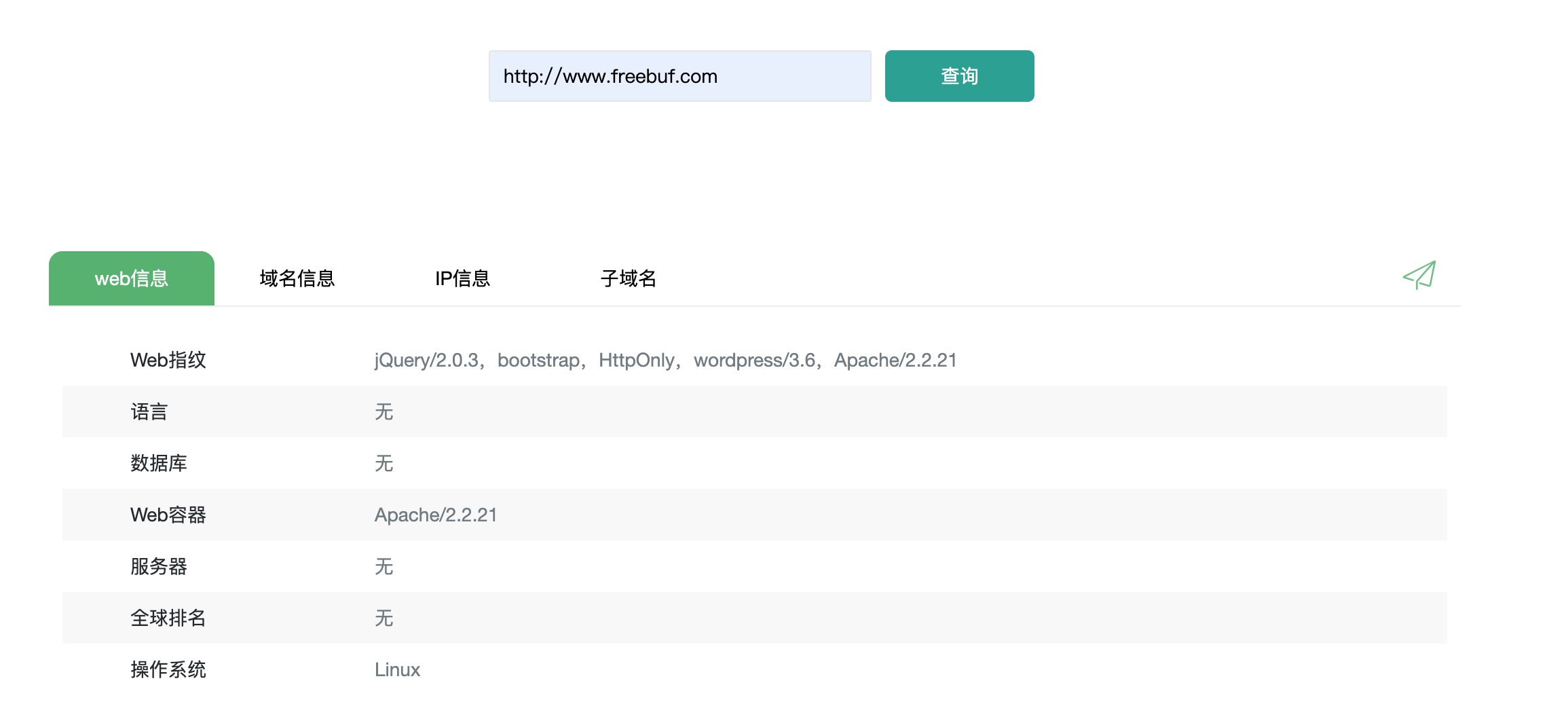
Webfinger
基于fofa的规则库进行快速检索,大约2000+条指纹数据,位于lib/web.db可自行添加修改。
下载地址:https://github.com/se55i0n/Webfinger
类似的还有个CMSCANhttps://github.com/cuijianxiong/cmscan/
FingerPrint
好像是百度的一个MM用perl写的一款工具,调用Wappalyzer模块进行指纹识别。
下载地址:https://github.com/tanjiti/FingerPrint
在线指纹识别
云悉指纹识别
http://www.yunsee.cn/
指纹库很强大,速度也很快,我们前端还仿了下云悉的界面,免费服务,好像还能提供api接口,学习的榜样!
如果指纹能开源就好了,哈哈~~
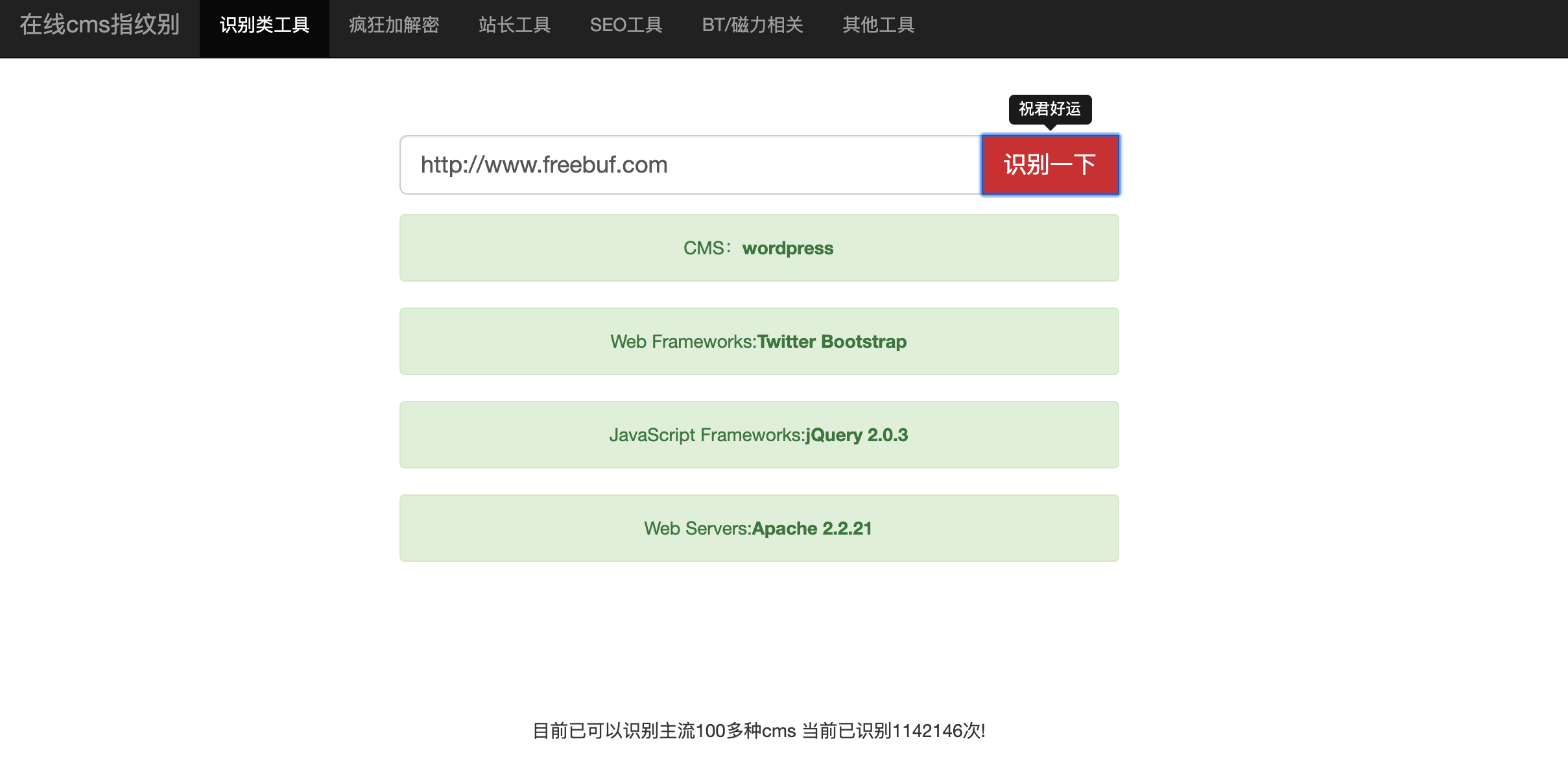
bugscaner指纹识别
http://whatweb.bugscaner.com/look/
目前好像指纹比较少,很多都识别不出来了。
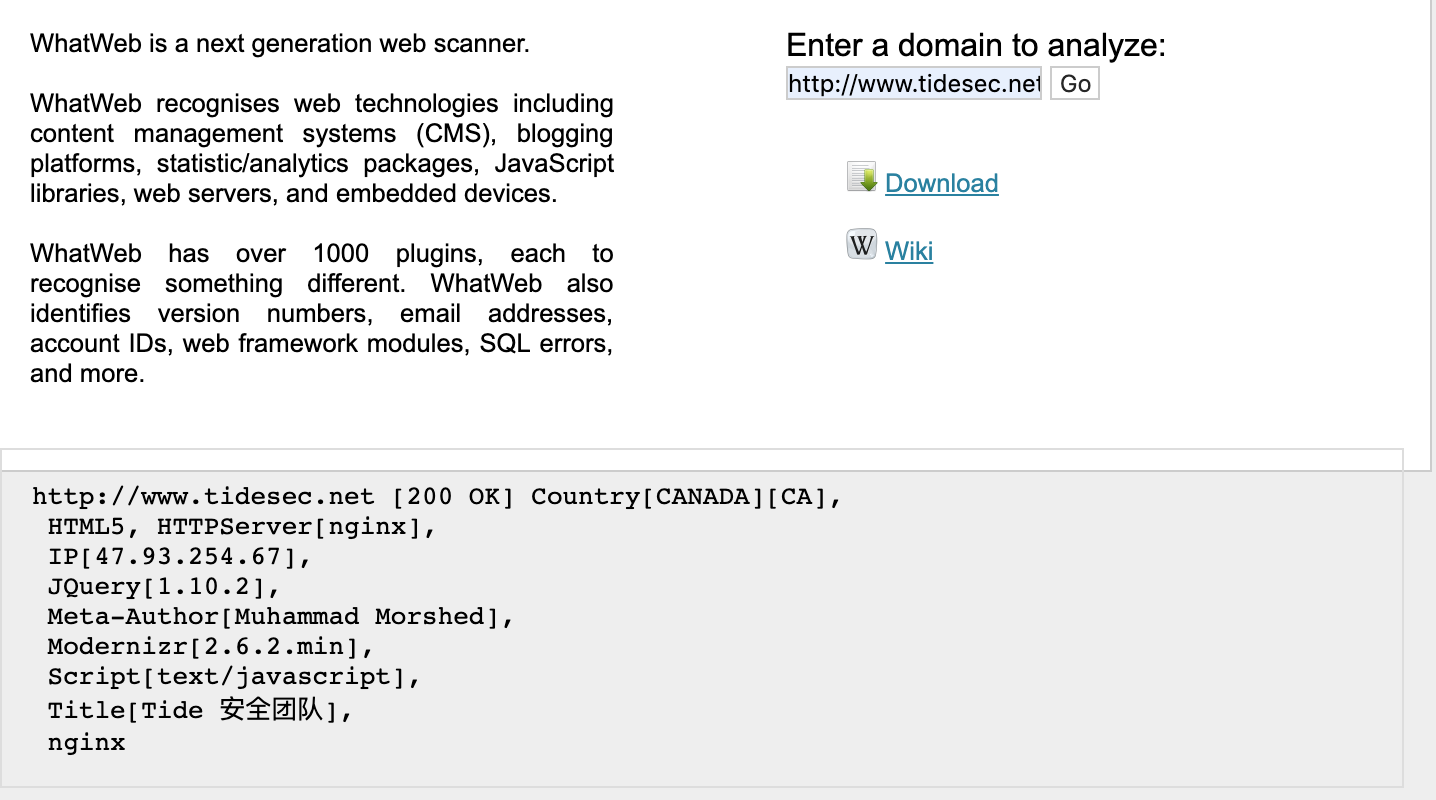
whatweb.net
https://whatweb.net/
之前功能还不错,现在好像只能查看到header信息了。
TideFinger
上面介绍了那么多超级工具,都不好意思写自己做的小破烂东西了…大佬们可以关掉本页面了…
通过对各种识别对象、识别方法、识别工具的分析,发现大家的指纹库各式各样,识别方式也是各有千秋,传统的md5、url路径的方式居多,识别header信息的也是不少,但没有一个能集众家之长的小工具。
于是我们就做了一个小工具TideFinger
https://github.com/TideSec/TideFinger指纹库整理
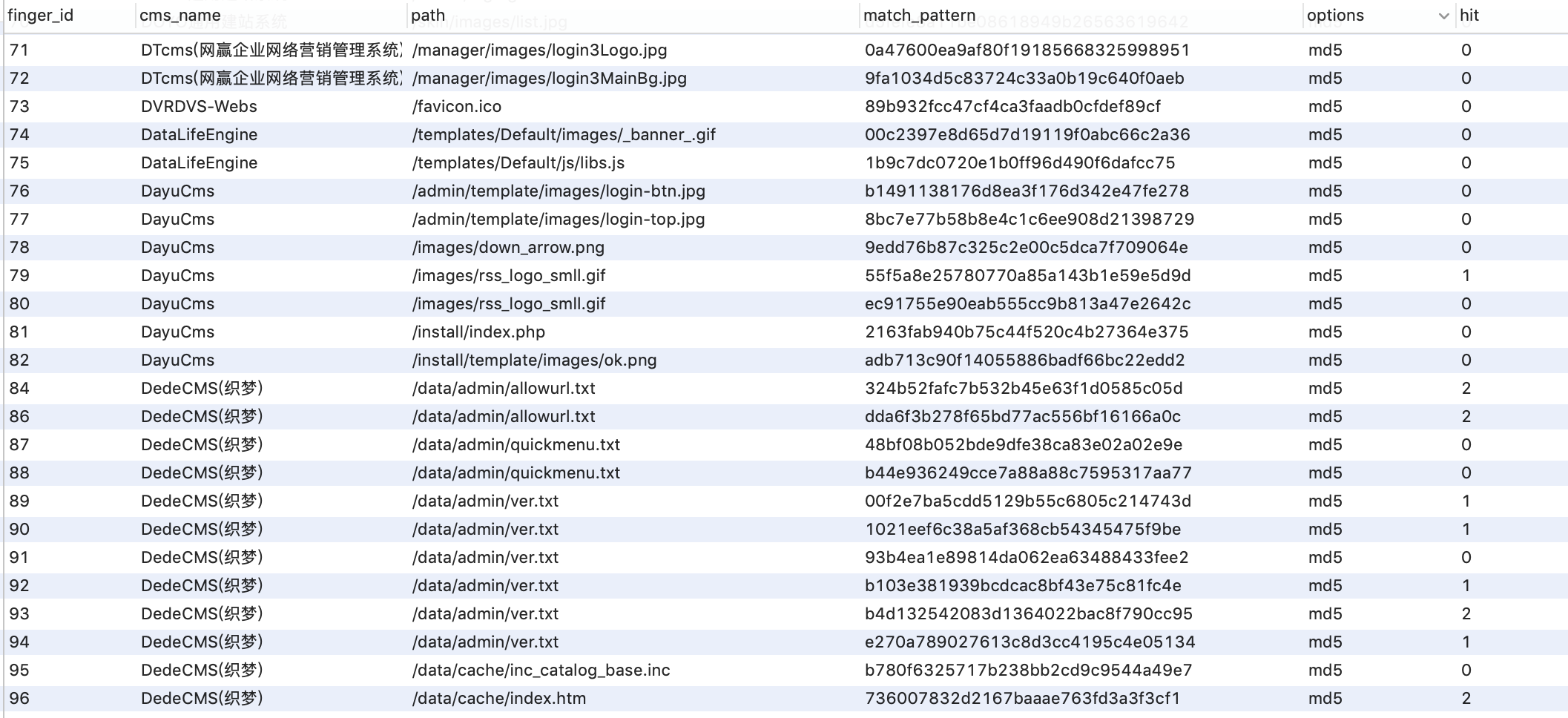
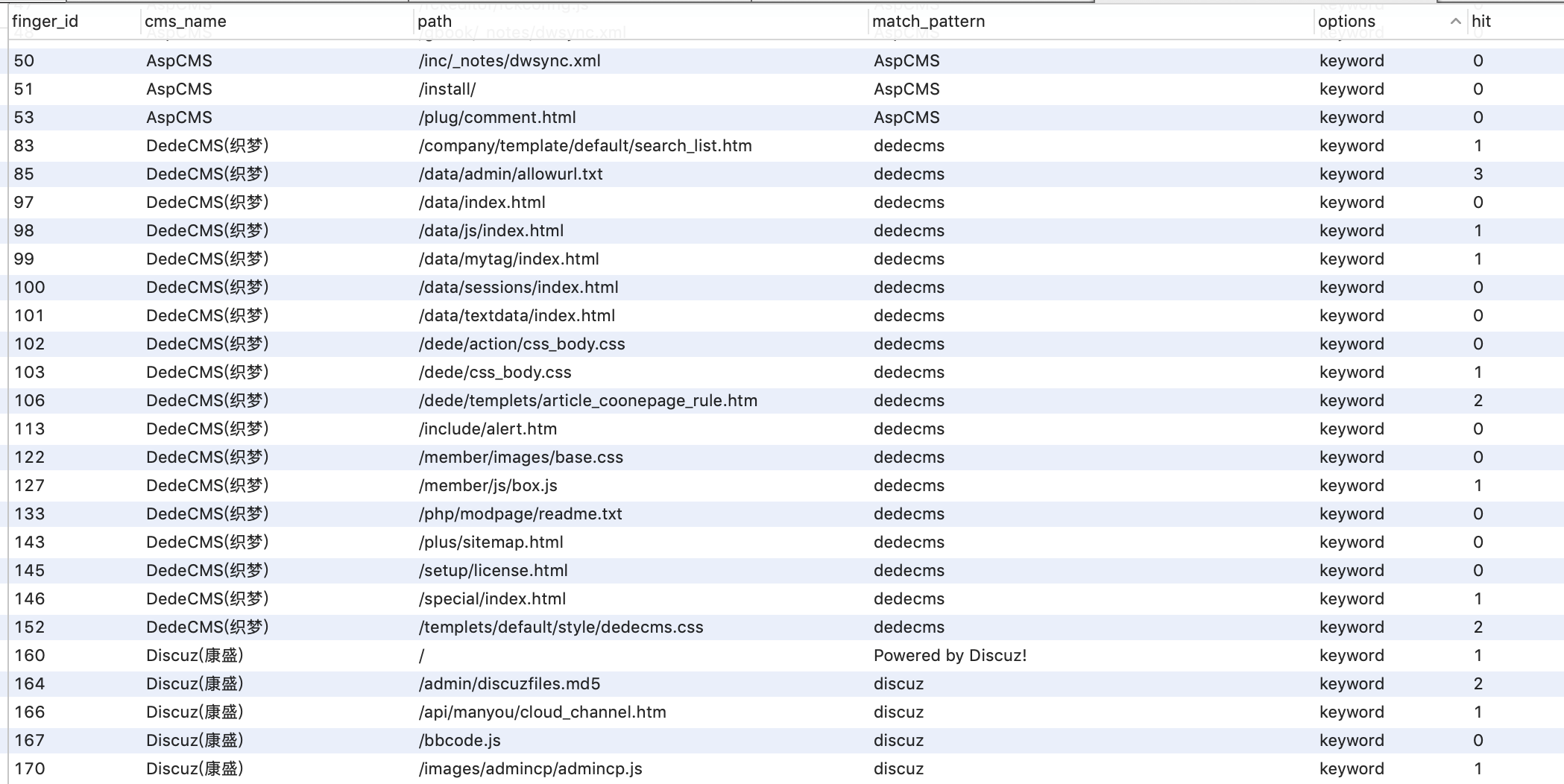
我们搜集了上面所有的指纹软件,从中提取了指纹库,进行了统一的格式化处理并进行去重,最终得到了一个大约2078条的传统指纹库。本来想把fofa的库也合并进来,发现格式差异有些大,便保持了fofa指纹库,并把WebEye的部分指纹和fofa指纹进行了合并。这样就保留了两个指纹库,其中cms指纹库为传统的md5、url库,大约2078条指纹,可通过关键字、md5、正则进行匹配,fofa库为2119指纹,主要对Header、url信息进行匹配。
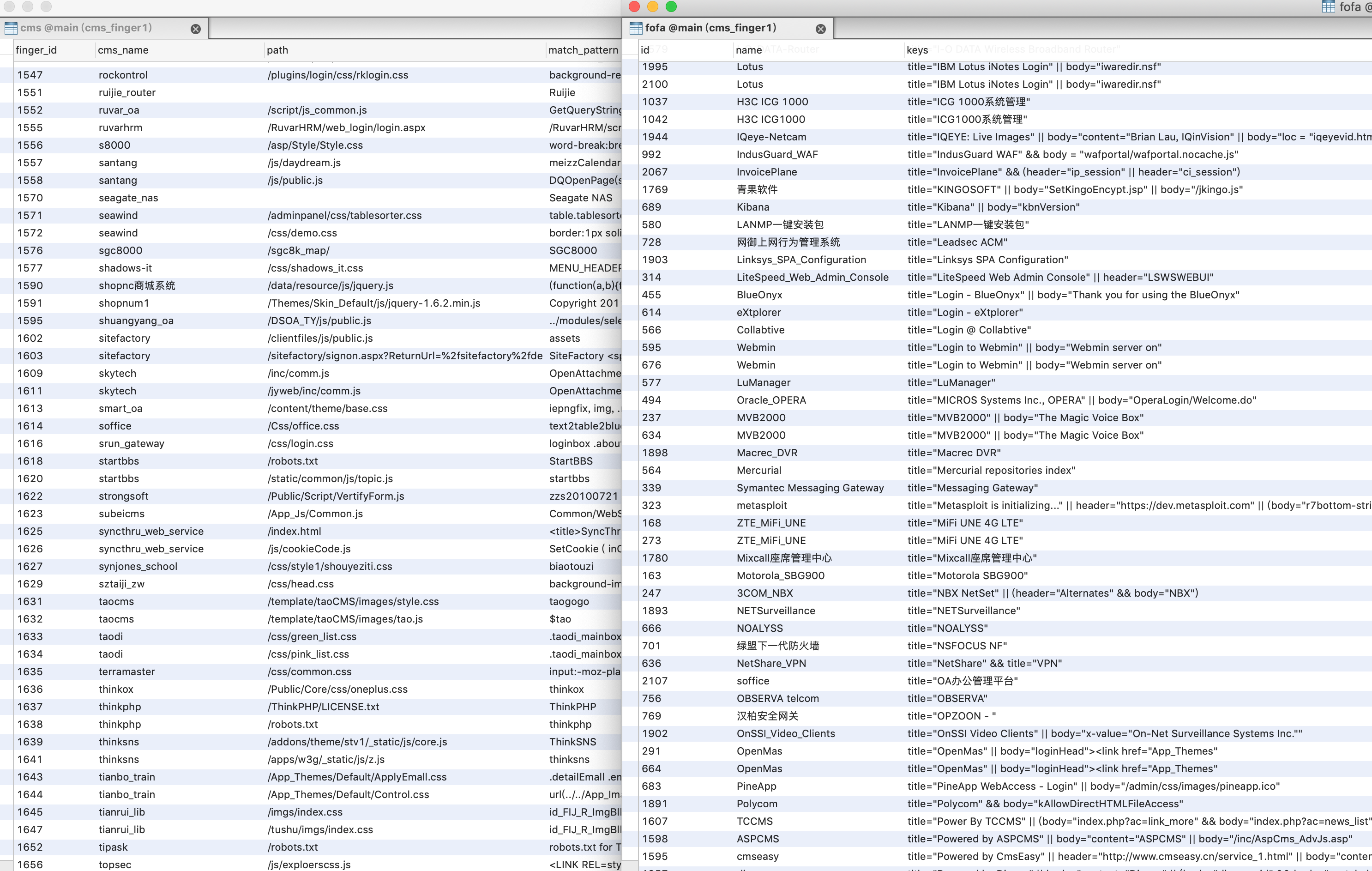
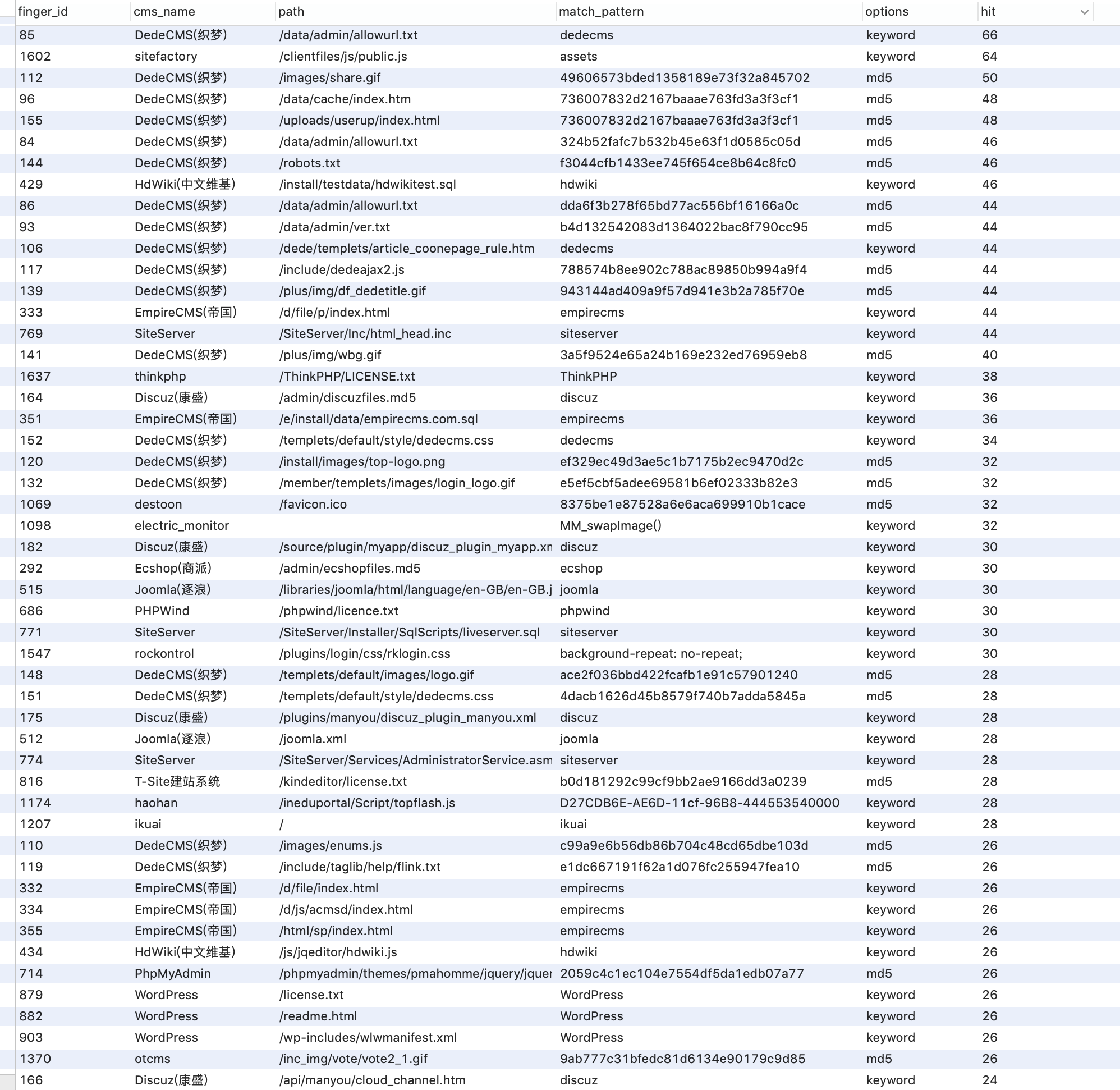
指纹库优化
在对指纹库整理去重后,对每个指纹进行了命中率的标识,当匹配到某个指纹时该指纹命中率会加1,而在使用指纹时会从优先使用命中率高的指纹。
然后我们从互联网中爬取了10W个域名进行了命中率测试,然后对一些误报率比较高的指纹进行了重新优化,得到了一份相对更高效的指纹库。
未知指纹发现
目前新指纹的识别基本还是靠人工发现然后分析规则再进行添加,所以各平台都有提交指纹的功能,但是我们没有这种资源,只能另想办法。
于是想到了一个比较笨的方法:从网站中爬取一些静态文件,如png、ico、jpg、css、js等,提取url地址、文件名、计算md5写入数据库,这样再爬下一个网站,一旦发现有相同的md5,就把新的url也加入到那条记录中,并把hint值加1,这样爬取10W个站点后,就能得到一个比较客观的不同网站使用相同md5文件的数据了。
获取链接代码部分
excludeext = ['.png', '.ico', '.gif','.svg', '.jpeg','js','css','xml','txt']
def getPageLinks(url):
try:
headers = requests_headers()
content = requests.get(url, timeout=5, headers=headers, verify=False).text.encode('utf-8')
links = []
tags = ['a', 'A', 'link', 'script', 'area', 'iframe', 'form'] # img
tos = ['href', 'src', 'action']
if url[-1:] == '/':
url = url[:-1]
try:
for tag in tags:
for to in tos:
link1 = re.findall(r'<%s.*?%s="(.*?)"' % (tag, to), str(content))
link2 = re.findall(r'<%s.*?%s=\'(.*?)\'' % (tag, to), str(content))
for i in link1:
links.append(i)
for i in link2:
if i not in links:
links.append(i)
except Exception, e:
print e
print '[!] Get link error'
pass
return links
except:
return []有兴趣的可以查看具体代码https://github.com/TideSec/TideFinger/blob/master/count_file_md5.py文件。
爬取的结果如下:

当然了,里面肯定很多都属于误报,比如上图中第一个其实是个500错误页面,所以出现的比较多,第二个是政府网站最下边那个常见的“纠错”的js,所以用的也比较多…
经过一些分析整理也发现了一些小众的CMS和建站系统的指纹,比如三一网络建站系统的newsxx.php,比如大汉JCM的jhelper_tool_style.css等等,后续会持续把这些新的指纹丰富到指纹库中去。
指纹识别脚本
有了指纹库之后,识别脚本就相对比较简单了,已有的一些也都比较成熟了,直接使用了webfinger和whatcms的部分代码并进行了整合优化,于是就有了TideFinger。
1、功能逻辑都比较简单,先用fofa库去匹配,然后获取一定banner,如果banner中识别除了cms,则返回结果,如果未识别到cms,则会调用cms规则库进行匹配各规则。
2、脚本支持代理模式,当设置了-p参数,且proxys_ips.txt文件包含代理地址时,脚本会随机调用代理地址进行扫描,以避免被封ip,不过这样的话效率可能会低一些。毕竟搜集的免费代理质量还是差一些,速度会慢很多。有钱人可以找收费代理池,然后每个规则都用不同代理去请求,这样肯定不会被封!
代理地址的搜集可以使用我修改的另一个代理池https://github.com/TideSec/Proxy_Pool,提供了自动化的代理ip抓取+评估+存储+展示+接口调用。
3、经测试,一般网站把所有指纹跑一遍大约需要30秒时间,个别的网站响应比较慢的可能耗时更长一些,可以通过设置网站超时时间进行控制。
安装python2依赖库
pip install lxml
pip install requests
pip install bs4
说明:sqlite3库在Python 2.5.x 以上版本默认自带了该模块,如提示sqlite3出错请自行排查。执行脚本
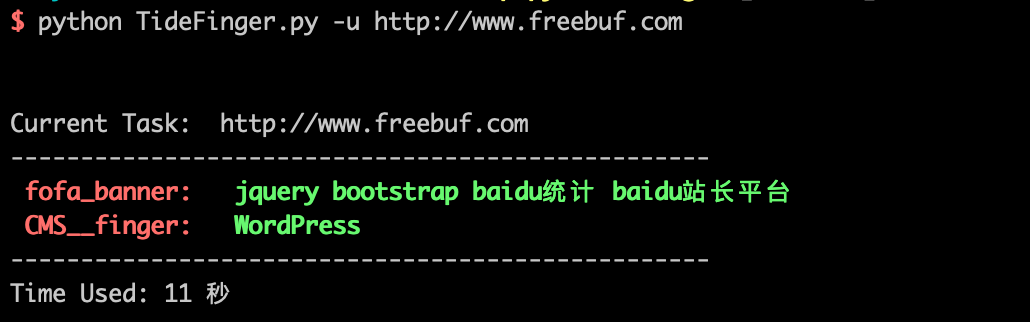
$ python TideFinger.py
Usage: python TideFinger.py -u http://www.123.com [-p 1] [-m 50] [-t 5]
-u: 待检测目标URL地址
-p: 指定该选项为1后,说明启用代理检测,请确保代理文件名为proxys_ips.txt,每行一条代理,格式如: 124.225.223.101:80
-m: 指纹匹配的线程数,不指定时默认为50
-t: 网站响应超时时间,默认为5秒指纹识别界面如下: