
案例一
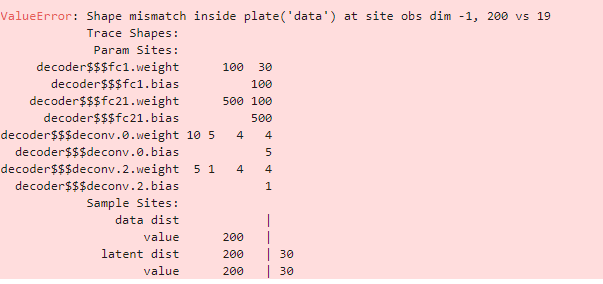
当我试图构建一个VAE模型时,我收到以下错误,我不知道如何调试它。
这是模型的代码,我的数据的维数是[1000,1,20,10] |

你好@AmyTanJ,你能粘贴更多的事物形状的细节吗,例如,通过添加如下的日志语句并粘贴输出?如果我能看到更多的张量大小,我会更容易帮助调试。我的猜测是,如果您正在处理2d图像,您需要将事件维度更改为2: - .to_event(1)+ .to_event(2) 日志记录语句: |
谢谢回复,你的瞎猜是对的! |
是的, 很高兴修复了您的模型,我现在将关闭此问题🙂 |
案例2
Subsampling pyro.plate Results in Shape Mismatch
def horseshoe_classification2(data, y):
N, feature_dim = data.shape
# - Horseshoe prior.
# Global shrinkage parameter (tau) multiplies a coefficient's local shrinkage parameter (lambda_i) to compute the
# standard deviation of the Gaussian that generates that coefficient (beta_i).
tau = pyro.sample('tau', dist.HalfCauchy(torch.ones(1)))
# Local shrinkage parameter (lambda_i) represents the local component of the standard deviation of the Gaussian that
# generates that coefficient (beta_i).
with pyro.plate('lambdas_plate', feature_dim):
lambdas = pyro.sample('lambdas', dist.HalfCauchy(torch.ones(feature_dim)))
# The horseshoe prior assumes each coefficient (beta_i) is conditionally independent.
with pyro.plate('beta_plate', feature_dim):
# Reparameterize to improve posterior geometry (not specific to horseshoe regression).
with poutine.reparam(config={'betas': LocScaleReparam()}):
betas = pyro.sample('betas', dist.Normal(0, tau * lambdas))
# Kappa_i is roughly interpreted as the amount of weight that the posterior mean for beta_i places on 0 after the data
# has been observed (this interpretation is primarily for regression when sigma^2 and tau^2 both equal 1).
pyro.deterministic('kappas', 1/(1 + lambdas**2))
# - Intercept prior.
intercept = pyro.sample('intercept', dist.Normal(0, 10))
# - Linear model.
p = data @ betas + intercept
# # - Likelihood.
# with pyro.plate('data', size=N, subsample_size=10000) #as ind:
# pyro.sample('y', dist.Bernoulli(logits=p), obs=y.index_select(0, ind))
修改为这样 ,采样和目标维度要对应上
# - Likelihood.
with pyro.plate('data', size=N, subsample_size=10000) as ind:
pyro.sample('y', dist.Bernoulli(logits=p.index_select(0, ind)), obs=y.index_select(0, ind))
# Set up training objects.
guide = AutoDiagonalNormal(horseshoe_classification2)
svi = SVI(horseshoe_classification2, guide, optim.Adam({"lr": 0.01}), loss=Trace_ELBO())
# Train model.
num_iters = 5000
for i in range(num_iters):
elbo = svi.step(X_train, y_train)
if i % 500 == 0:
print("Elbo loss: {}".format(elbo))
案例3
for layer_idx, layer in enumerate(self.layers):
layer.weight = PyroSample(dist.Normal(0., prior_scale * np.sqrt(2 / self.layer_sizes[layer_idx])).expand(
[self.layer_sizes[layer_idx + 1], self.layer_sizes[layer_idx]]).to_event(2))
layer.bias = PyroSample(dist.Normal(0., prior_scale).expand([self.layer_sizes[layer_idx + 1]]).to_event(1))这段代码是在一个深度学习模型的上下文中,使用 Pyro 库为模型的权重和偏置参数定义先验分布。代码执行以下步骤:
1. **遍历模型层**:使用 `enumerate` 函数遍历 `self.layers` 中的每个 `layer`,`layer_idx` 是当前层的索引。
2. **为权重定义先验分布**:
- `PyroSample` 是 Pyro 中的一个函数,用于将先验分布赋给模型参数。
- `dist.Normal(0., prior_scale * np.sqrt(2 / self.layer_sizes[layer_idx]))` 定义了一个正态分布,其中:
- 均值(`mean`)是 `0.`,表示权重的先验均值假设为 0。
- 方差(`variance`)是 `prior_scale` 乘以 `np.sqrt(2 / self.layer_sizes[layer_idx])`,这里 `prior_scale` 是一个超参数,控制先验分布的宽度,而 `np.sqrt(2 / self.layer_sizes[layer_idx])` 是根据层的大小调整的项,这通常与权重的方差成反比。
- `.expand([self.layer_sizes[layer_idx + 1], self.layer_sizes[layer_idx]])` 将分布扩展到权重矩阵的形状,其中 `self.layer_sizes[layer_idx]` 是当前层的神经元数量,`self.layer_sizes[layer_idx + 1]` 是下一层的神经元数量。
- `.to_event(2)` 指定了分布的事件维度,这里 `2` 表示权重矩阵是二维的。
3. **为偏置定义先验分布**:
- 偏置的先验分布也是正态分布,均值为 `0.`,方差为 `prior_scale`。
- `.expand([self.layer_sizes[layer_idx + 1]])` 将分布扩展到偏置向量的形状,长度为下一层的神经元数量。
- `.to_event(1)` 指定了分布的事件维度,这里 `1` 表示偏置是一维的。
### 总结
这段代码为神经网络的每层权重和偏置参数定义了正态分布作为先验。权重的方差根据层的大小进行调整,这是一种常见的做法,称为“权重衰减”或“正则化”,有助于防止过拟合。偏置的方差则不随层大小变化。使用 `PyroSample` 将这些先验分布赋给模型参数,使得在贝叶斯推断过程中可以学习这些参数的最优值。



















{kind=link}