
Apache Spark是通用的大规模数据处理框架。 了解spark如何执行作业对于获取大部分作业非常重要。
关于Spark评估范式的简短回顾:Spark使用的是惰性评估范式,在该范式中,Spark应用程序在驱动程序调用“ Action”之前不会执行任何操作。
惰性评估是所有运行时/编译时优化火花可以完成的关键。
懒惰的评估不是新概念。 它在函数式编程中使用了数十年。 数据库还使用它来创建逻辑和物理执行计划。 像tensorflow这样的神经网络框架也基于惰性评估。 首先,它构建计算图,然后执行它。
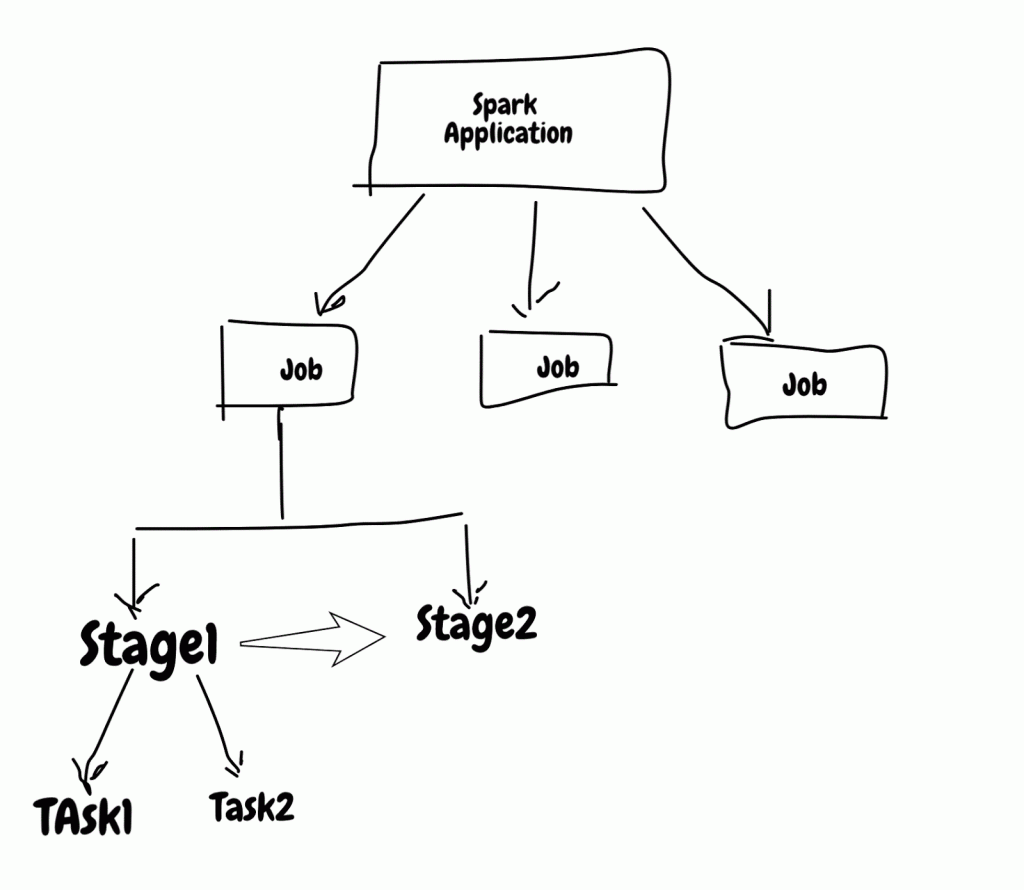
Spark应用程序由工作,阶段和任务组成。 作业和任务由Spark并行执行,但作业内部阶段是顺序执行的。 当您想要调整火花作业时,知道并行执行和顺序执行的内容非常重要。
阶段是按顺序执行的,因此具有多个阶段的作业将使它窒息,并且前一阶段将进入下一个阶段,并且这会带来一些开销,其中涉及将阶段输出写入持久性源(即磁盘,hdfs,s3等)并再次读取。 这也称为广泛转换/混洗依赖性。
单阶段作业将非常快,但是您无法使用单阶段构建任何有用的应用程序。
例子
让我们看一些代码示例以更好地理解这一点。
val topXNumbers = randomNumbers
.filter(_ > 1000) //Stage 1
.map(value => (value, 1)) // Stage 1
.groupByKey() //Stage 2
.map(value => (value._1, value._2.sum)) //Stage 2
.sortBy(_._2, false) //Stage 3
.count() // Stage 3 星火DAG 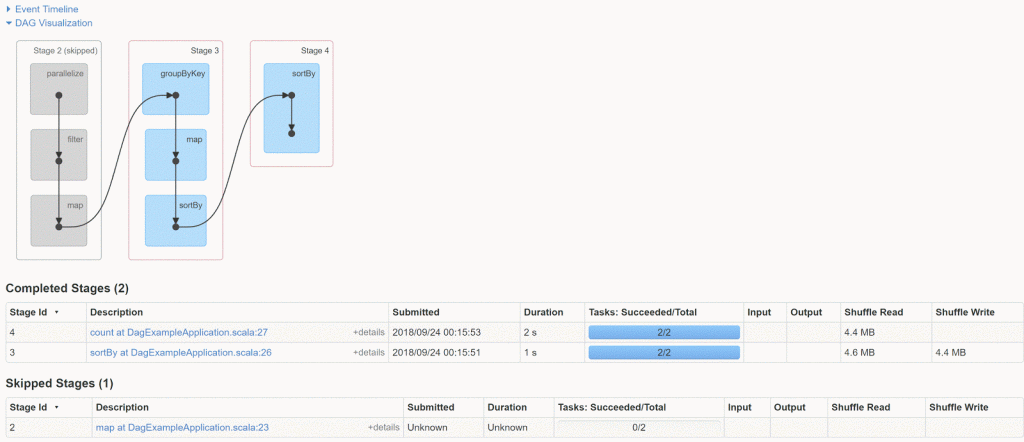
spark ui的DAG视图非常清楚地表明Spark如何查看/执行应用程序。
上面的代码创建了3个阶段,每个阶段的边界都有一些开销,例如(Shuffle读/写)。
单阶段(例如阶段1)中的步骤已合并过滤器和地图。
该视图还具有“任务”,这是执行的最小工作单元。 该应用程序每个阶段有2个任务。
spark应用程序如何执行? 让我们深入研究如何执行它。 Spark应用程序需要3个组件来执行:
- 驱动程序–提交请求以掌握和协调所有任务。
- 集群管理器–根据驱动程序的请求启动spark执行程序。
- 执行程序–执行作业并将结果发送回驱动程序。
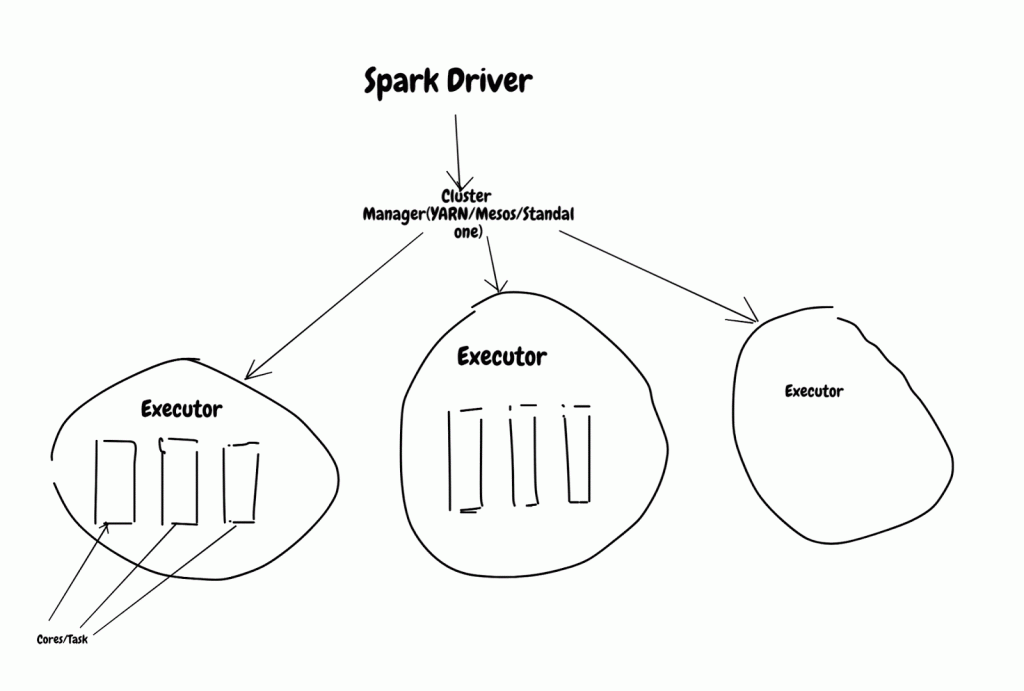
Spark应用程序涉及的2个重要组件是Driver&Executor,当这些组件中的任何一个承受压力时,Spark作业可能会失败,可能是内存/ CPU /网络/磁盘。
在下一节中,我将分享我在执行人方面的一些经验。
执行器问题 :每个执行器需要2个参数Cores&Memory。 核心决定执行者可以处理多少个任务,并且该执行者中所有核心/任务之间共享内存。 每个火花作业都有不同类型的需求,因此 反模式,以对所有Spark应用程序使用单一配置。
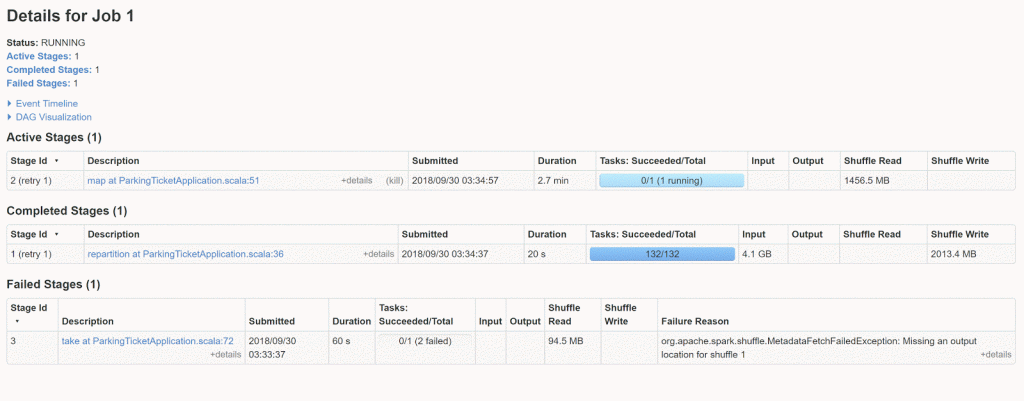
问题1 –执行者的任务过多 :如果任务太大而无法容纳在内存中,执行者将无法处理任务或运行缓慢。 没什么可寻找这个问题的:
- 驱动程序日志文件长时间停顿(即日志文件不移动)
- GC时间过长,可以从spark UI的“执行者”页面进行验证
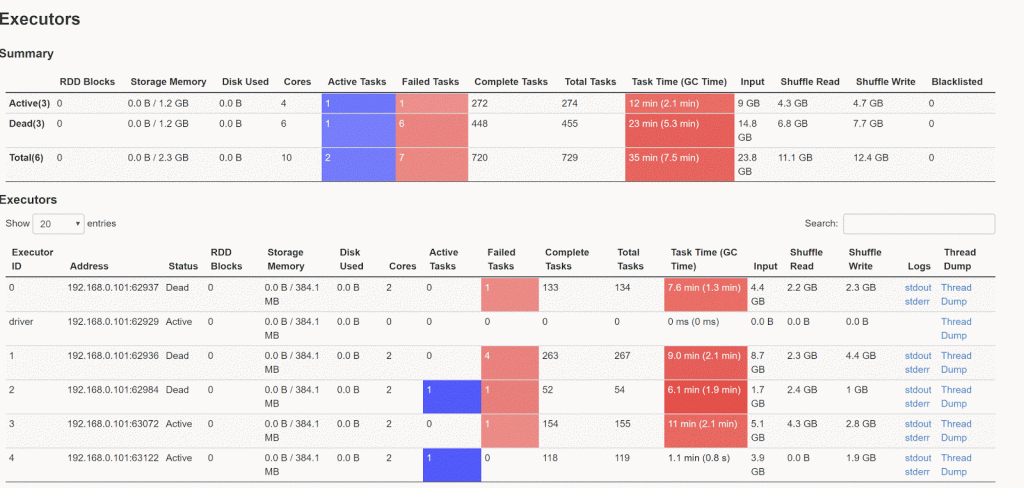
- 重试舞台
- 执行器记录完整的“内存映射图”消息
2018-09-30 03:30:06 INFO ExternalSorter:54 - Thread 44 spilling in-memory map of 371.0 MB to disk (6 times so far)
2018-09-30 03:30:24 INFO ExternalSorter:54 - Thread 44 spilling in-memory map of 379.5 MB to disk (7 times so far)
2018-09-30 03:30:38 INFO ExternalSorter:54 - Thread 44 spilling in-memory map of 373.8 MB to disk (8 times so far)
2018-09-30 03:30:58 INFO ExternalSorter:54 - Thread 44 spilling in-memory map of 384.0 MB to disk (9 times so far)
2018-09-30 03:31:17 INFO ExternalSorter:54 - Thread 44 spilling in-memory map of 382.7 MB to disk (10 times so far)
2018-09-30 03:31:38 INFO ExternalSorter:54 - Thread 44 spilling in-memory map of 371.0 MB to disk (11 times so far)
2018-09-30 03:31:58 INFO ExternalSorter:54 - Thread 44 spilling in-memory map of 371.0 MB to disk (12 times so far)- 执行器日志出现OOM错误
2018-09-30 03:34:35 ERROR Executor:91 - Exception in task 0.0 in stage 3.0 (TID 273)
java.lang.OutOfMemoryError: GC overhead limit exceeded
at java.util.Arrays.copyOfRange(Arrays.java:3664)
at java.lang.String.<init>(String.java:207)
at java.lang.StringBuilder.toString(StringBuilder.java:407)
at sun.reflect.MethodAccessorGenerator.generateName(MethodAccessorGenerator.java:770)
at sun.reflect.MethodAccessorGenerator.generate(MethodAccessorGenerator.java:286)
at sun.reflect.MethodAccessorGenerator.generateSerializationConstructor(MethodAccessorGenerator.java:112)如何解决呢?
很快出现的一种选择是在执行器端增加内存。 它可以工作,但是可以在执行程序端添加多少内存将受到限制,因此很快您将用尽该选项,因为大多数集群都是共享的,并且它对可分配给执行程序的最大内存有限制。
下一个更好的选择是减小单个任务的大小,一切由您控制。 这需要更多的洗牌权衡,但是仍然比以前更好。
Spark UI快照,可用于不良运行和良好运行。
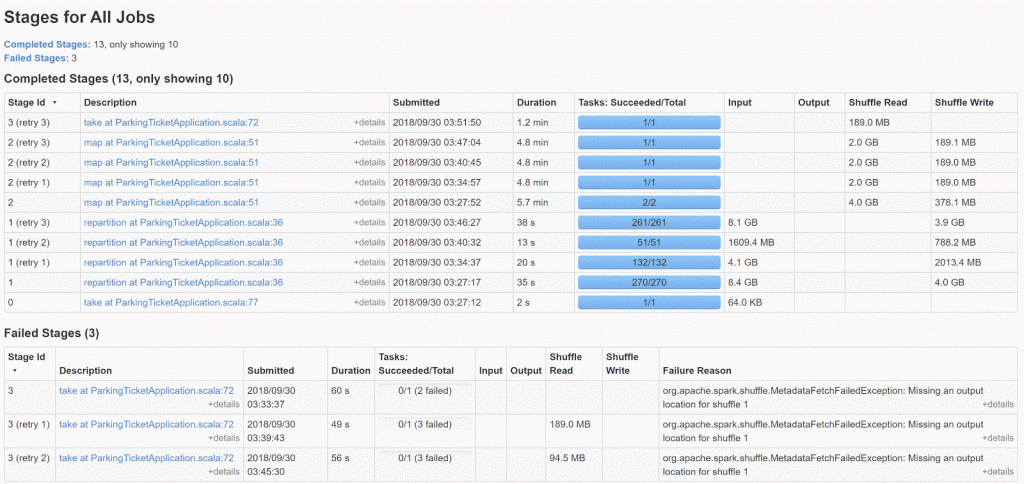
不良运行
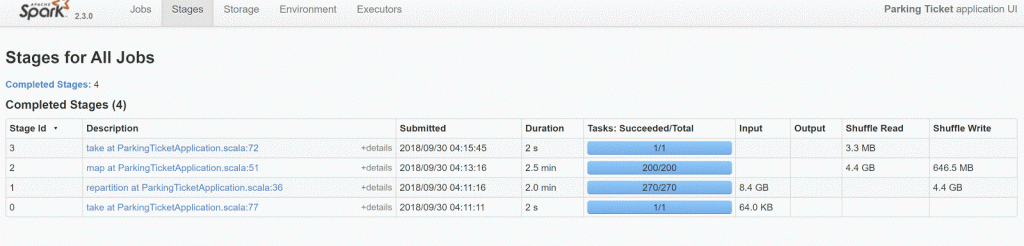
好运
第二个是调整分区大小。 不良运行表明所有需要调整分区大小的指标。
问题2 –执行程序中的内核过多 :这也是一个非常常见的问题,因为我们想通过抛出太多任务来使执行程序过载。 让我们看看如何确定是否存在此问题:
- 执行者方面花费在GC上的时间
- 执行器日志和消息–溢出的内存映射
- 峰值执行内存
我将放置来自sparkUI的2个快照
Partition Executor Cores Memory
Run 1 100 2 4 2g
Run 1 100 2 2 2g
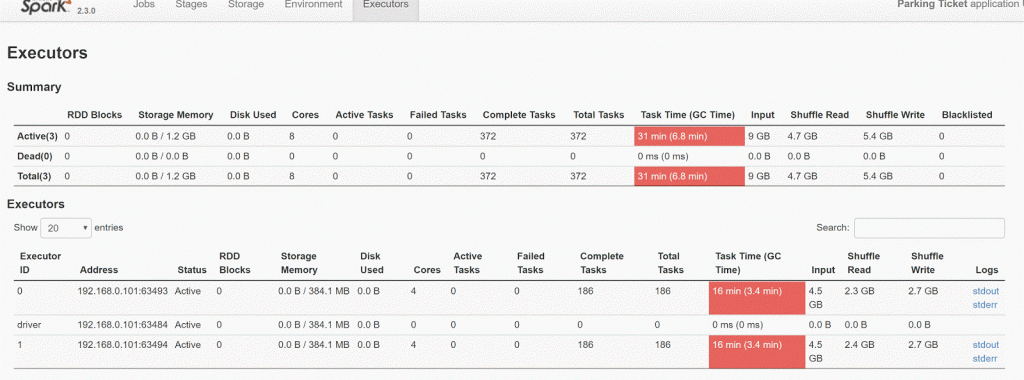
4核/ 2执行器
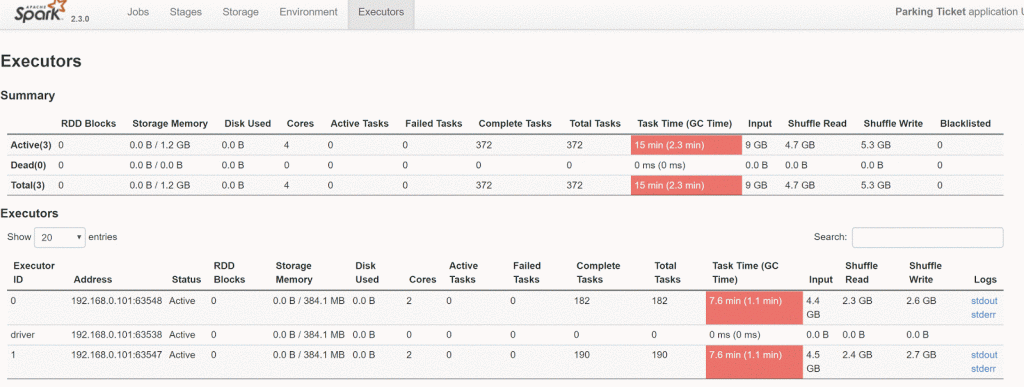
2核心/ 2执行器
8核(4 * 2 Exe)一个人忙于GC开销,而4核(2 * 2 Executor)的一切都减少了一半,仅使用4个核就更高效。
如果您看到这样的模式,请减少执行程序核心,并增加执行程序数量,以使Spark工作更快。
问题3 –纱线内存开销 :这是我的最爱,并且以下错误确认Spark应用程序存在此问题
“ ExecutorLostFailure(执行器2退出是由于正在运行的任务之一引起的)原因:容器因超出内存限制而被YARN杀死。
已使用XXX GB的XXX GB物理内存。 考虑提高spark.yarn.executor.memoryOverhead”
每当出现此错误时,大多数开发人员都会在堆栈上溢出并增加“ spark.yarn.executor.memoryOverhead”参数值。
这是不错的选择,因为短期内它很快就会再次失败,您将继续增加它,最终用尽选择权。
我认为增加“ spark.yarn.executor.memoryOverhead”作为反模式,因为指定的任何内存都会添加到执行程序的总内存中。
此错误表示执行程序过载,最好的选择是尝试我上面提到的其他解决方案。
Spark有太多的调整参数,以至于有时看起来像是在计划驾驶舱中选址。
此博客中使用的所有代码都可以在@sparkperformance github repo上找到
翻译自: https://www.javacodegeeks.com/2018/10/anatomy-apache-spark-job.html



















