
第14章 mySQ性能优化
优化MySQL数据库是数据库管理员和数据库开发人员的必备技能。MySQL优化一方面是找出系统的瓶颈,提高MySQL数据库整体的性能;另一方面,需要合理的结构设计和参数调整,以提高用户操作响应的速度;同时还要尽可能的节省系统资源,以便系统可以提供更大负荷的服务。
本章练习使用schoolDB作为示例数据库,如果没有,需要重新创建。需要插入1000条学生记录,3门课程以及学生成绩。
SQL优化
练习1:优化SQL语句的一般步骤
本练习使用sql manager管理工具完成。注册连接schoolDB数据库

点击下图红框,打开命令操作窗口。

1. Show status命令了解各种SQL的执行频率
查看当前会话执行的各项命令统计 com_XXX
show session status like 'Com_%' 其中session可省
show status like 'Com_%'
显示全局统计使用
SHOW GLOBAL STATUS LIKE 'COM_%';


2. 查看针对InnoDB存储引擎状态的统计
SHOW GLOBAL STATUS LIKE 'Innodb_%'

红色部分可以看到插入 删除 读取 更新的行的汇总数量。无论事务提交还是回滚,都进行累加。
3. 查看试图连接mySQL服务器的次数
show global status like 'connections'

4. 查看服务器工作时间
show global status like 'uptime'
练习2:通过explain 分析低效SQL的执行计划
1. 使用explain 分析SQL语句
explain select * from TStudent where studentID='00034'
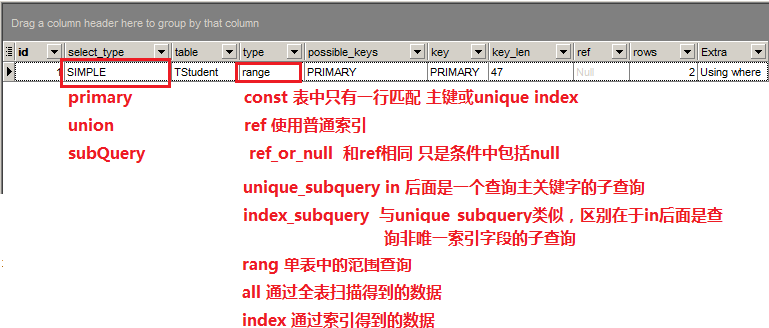
explain select * from TStudent where cardID like '%45%'

2. 确定问题并采取相应措施
如果出现对大表的全表扫描,应该在该列创建索引,并且尽量避免使用like这样的条件进行查找。
explain select * from TStudent where studentID like '%3%'

注意以下这个查询使用索引进行的,大家想想为什么?
explain select * from TStudent where studentID like '0003%'

练习3:通过索引优化查询
3. 索引的存储分类
MySQL中的索引的存储类型目前只有BTREE和HASH,具体和表的存储引擎有关。myISAM和InnoDB存储引擎都支持BTREE。Memory/Heap存储引擎可以支持HASH和BTREE
4. MySQL如何使用索引-组合索引的使用
索引用户快速找出某一列中有一特定值的行,查询使用索引的主要条件是查询条件中使用索引关键字,多列索引只有在查询条件中使用最左面的前缀,才使用索引。
在TSCore表上创建了组合主键。

查询
explain select * from TScore where studentID='00023'

explain select * from TScore where subjectID='00001'
可以看到是全表扫描

5. 条件语句中使用Like
explain select * from TStudent where studentID like '%3%'

注意以下这个查询使用索引进行的,大家想想为什么?
explain select * from TStudent where studentID like '0003%'

如果列是索引,查找空值使用索引,以下是给sname列创建索引
alter table `TStudent` add index indexName(sname)
查看查询计划
explain select * from TStudent where sname is null

6. 不适用索引的情况
如果查询的结果站记录总数的大多数,就不适用索引。
如果条件语句中有or or前面的列有索引,后面列没索引,两个索引都不用。
如果列类型是字符串,一定要用' ' 否则不使用索引查询数据。
explain select * from TStudent where studentid=00051

explain select * from TStudent where studentid='00051'

7. 查看索引使用情况
show status like 'Handler_read%'

8. 两个简单的实用的优化方法
定期分析和检查表
analyze table TStudent
本语句用于分析和存储表的关键字分布,分析的结果将可以使的系统得到准确的统计信息,使得SQL能够生成正确的执行计划。
check table TStudent
本语句的作用是检查一个或多个表是否有错误,check table对MyISAM和InnoDB表有作用。
常用的SQL的优化
9. 优化Insert语句
如果从同一个客户端一次插入很多行,尽量使用下面的语句,能大大缩减客户端与数据库之间的连接、关闭等消耗。
insert student values
(45,'李双江','212121212121212121121','北京海淀区','213322323232'),
(46,'冯玲娥','212121212121212121121','北京海淀区','213322323232'),
(47,'李双江','212121212121212121121','北京海淀区','213322323232')
不要使用以下语句
insert student values (45,'李双江','212121212121212121121','北京海淀区','213322323232');
insert student values (46,'冯玲娥','212121212121212121121','北京海淀区','213322323232');
insert student values (47,'李双江','212121212121212121121','北京海淀区','213322323232');
10. 使用delayed选项
如果从多个客户端插入很多行,能通过使用INSERT delayed语句得到更高的速度。其含义是让INSERT语句马上执行,其实数据都被放在内存的队列中,并没有真正写入磁盘。这比每条语句分别插入要快的多。LOW_PRIORITY刚好相反,在所有其他用户对表的读写完后才进行插入。
该参数支持MyISAM数据引擎。

insert delayed student values (46,'冯玲娥','212121212121212121121','北京海淀区','213322323232');
11. 将索引文件和数据文件分别放到不同的盘
12. RAID磁盘
13. 从文件装载一个表时,使用load data infile 比insert语句块20倍
14. 可以使用一个索引来满足Order by,不需要额外的排序。Where条件和Order by 使用相同的索引,并且order by的顺序和索引顺序相同。
15. 优化嵌套子查询 子查询可以被更有效率的join替代,使用join不需要在内存中使用临时表。
16. MySQL如何优化or条件 两个条件必须有索引,否则不是用索引
优化数据库对象
练习4:优化表的数据类型
使用PROCEDURE ANALYSE()来对表进行分心,该函数可以对数据表中列的数据类型提出优化建议。
select * from TStudent PROCEDURE ANALYSE();

通过拆分提高表的访问效率
17. 垂直拆分
将一个有很多列的表,分解成多个表,使用主键进行关联,可以使数据行变小,一页就能存放更多的数据,使用jion进行连接。如果一个表,有的列常用,有些列不常用,就可以垂直拆分。
18. 水平拆分
根据一列或多列数据的值把数据行放到两个队表中。以下情况使用水平拆分
1. 表很大 分割后可以降低查询时需要读的数据和索引的页数。同时也降低了索引的层数,提高查询速度。
2. 表中的数据有很强的独立性 比如表中数据,记录不同地区或不同时间的数据。特别是有些数据常用,有些不常用。
3. 需要把数据放到多个介质上。放到不同的硬盘。
这种查询需要使用多个表名,使用UNION将结果连接起来,增加了操作的复杂性。
逆规范化
规范化,降低了数据冗余,以及数据修改引起的数据不一致。但是需要多个表进行jion,降低了查询的性能,为了性能考虑,不严格使用规范化设计数据库。
反规范化的好处,降低连接操作的需求,降低外键和索引的数目,还能减少表的数量。
常用的反规范化技术有:
1. 增加数据冗余
2. 增加派生列
3. 重新组表
4. 分割表
反规范化技术需要维护数据的完整性。常用的维护完整性方法有:
5. 批处理 是指定期运行批处理作业或存储过程对派生列进行修改,这在实时性要求不高的情况使用
6. 由应用逻辑来实现 使用事务,在一个事务中对所有涉及到的表进行增删改操作。因为同一逻辑必须在所有应用中使用和维护,容易遗漏,特别是在需求变化大时,不易维护。
7. 使用触发器实现,易于维护。
使用中间表提高统计查询速度
比如一个表记录了客户每天的消费记录,你需要统计用户本周客户消费总金额和近一周不同时间段用户的消费总金额。你就应该将本周的数据插入到一个新表,然后使用新表进行统计。
优点:
8. 中间表与源表隔离
9. 中间表可以灵活添加索引或增加临时用字段。从而达到提高统计查询效率和辅助统计查询的作用。
锁问题
MySQL不同的存储引擎支持不同的锁机制。myISAM和MEMORY存储引擎采用表级锁;BDB存储引擎采用的是页面锁,也支持表级锁;InnoDB及支持行级锁、也支持表级锁,默认情况是采用行级锁。
MySQL有三个级别的锁。
三种锁地特性:
表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低。
行级锁:开销稍大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
页面锁:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般。
练习5:查看锁
这是myISAM存储引擎支持表锁,这也是早起mySQL版本中唯一支持的锁类型。
19. 查询表级锁争用情况
show status like 'table%'

20. 查看锁
当上面出现锁等待的情况下,使用putty连接输入以下命令
show global status like 'innodb_row_lock%'

Innodb_row_lock_current_waits:当前正在等待锁定的数量;
Innodb_row_lock_time:从系统启动到现在锁定总时间长度;
Innodb_row_lock_time_avg:每次等待所花平均时间;
Innodb_row_lock_time_max:从系统启动到现在等待最常的一次所花的时间;
Innodb_row_lock_waits:系统启动后到现在总共等待的次数;
输入以下命令,查看全局的表锁
show global status like 'table%'

如果Table_locks_waited的值比较高,则说明存在着较严重的表级锁争用情况。
Table_locks_immediate表示立即释放表锁数
等待的锁不多,就不需要使用InnoDb
优化mySQL
练习6:查看mysql参数
和大多数数据库一样,MySQL也提供了很多参数来进行服务器的设置。
21. 查看mySQL Server参数
show variables

查看当前会话状态
show status

查看全局状态
show global status

22. 影响mySQL性能的重要参数
将索引加到缓存,能够提高查找速度。
绝大多数参数不需要用户调整,key_buffer_size参数,用来设置索引块缓存的大小,被所有线程共享,此参数适用于MyISAM存储引擎。
使用putty连接mySQL设置这个参数
set global hot_cache2.key_buffer_size=128*1024;
global标识对每一个新的连接,此参数都将生效,hot_cache2是新的key_buffer名称。
然后可以把相关表的索引放到指定的索引缓存中。
将相关表索引放到指定的索引缓存中。

可以看到有两个索引

将TStudent表的索引加载到缓存。

磁盘I/O问题
使用磁盘阵列
23. RAID技术
RAID-0 读写快 无冗余
RAID-1 读快 写一般 有冗余 有一半的磁盘浪费
RAID-10 先做RAID-1 在做RAID -0 读写性能好
RAID-4 使用一个单独的磁盘存放校验数据,当一个磁盘坏掉,
RAID-5 将校验数据分布在多个磁盘 写性能不如RAID 0、RAID 1和RAID 10,出现坏盘,读性能下降。
RAID技术有硬件实现的也有软件实现的,即操作系统实现的。
应用优化
减少对mySQL的访问
要想提高访问速度,能够一次连接就能取的所有结果,就不要分两步。这样能够大大减少对数据库无谓的重复访问。
例如
第一个查询得到用户学号和姓名
Select studentID,sname from TStudent where studentID='00005'
第二个查询得到用户的班级
Select class from TStudent where studentID='00005'
这样就需要想数据库提交两次查询。
使用一个SQL语句实现,将class放到变量以备后用。
Select studentID,sname, class from TStudent where studentID='00005'
练习7:使用查询缓存
MySQL的查询缓存,就是将select语句查询的结果放到缓存,再遇到个相同的查询,服务器就会从查询缓存中重新得到查询结果,不再需要解析和执行查询。
适合更新不频繁的表。表结构和数据更改后,查询缓存值的相关条目被清空。
show variables like '%query_cache%'

按顺序执行以下命令查看缓存的数量
show status like 'Qcache%'
Select class from TStudent where studentID='00046';
Select class from TStudent where studentID='00056'
show status like 'Qcache%'
增加cache层
在应用端增加cache层来减轻数据库负担的目的,cache层有很多种,也有很多证实现方式。
比如,把部分数据从数据库抽取出来放到应用端以文本形式存储,如果有查询需求就直接重文本(cache)中查询。由于cache中数据量小,能够达到较高的访问效率。但是也涉及到数据更新,需要及时刷新cache。
负载均衡
负载均衡是一种在实际应用中非常普遍的方法。从Web服务器到数据库服务器都可以使用负载均衡。现在介绍mySQL负载均衡方法。
利用mySQL复制分流查询操作
主服务器负载数据更改,从服务器负载查询。数据复制的延迟需要考虑。
采用分布式数据库架构
MySQL cluster适用于大数据量,负载高的情况,有良好的扩展性和高可用性。
转载于:https://blog.51cto.com/91xueit/1138067




















