
一、最简单的来讲,利用贝叶斯变换公式的分类算法就是贝叶斯分类器。
先验概率和后验概率公式:
")
二、朴素贝叶斯分类器
1、思想:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。
2、算法流程
第一阶段——准备工作阶段,这个阶段的任务是为朴素贝叶斯分类做必要的准备,主要工作是根据具体情况确定特征属性,并对每个特征属性进行适当划分,然后由人工对一部分待分类项进行分类,形成训练样本集合。这一阶段的输入是所有待分类数据,输出是特征属性和训练样本。这一阶段是整个朴素贝叶斯分类中唯一需要人工完成的阶段,其质量对整个过程将有重要影响,分类器的质量很大程度上由特征属性、特征属性划分及训练样本质量决定。
第二阶段——分类器训练阶段,这个阶段的任务就是生成分类器,主要工作是计算每个类别在训练样本中的出现频率及每个特征属性划分对每个类别的条件概率估计,并将结果记录。其输入是特征属性和训练样本,输出是分类器。这一阶段是机械性阶段,根据前面讨论的公式可以由程序自动计算完成。
第三阶段——应用阶段。这个阶段的任务是使用分类器对待分类项进行分类,其输入是分类器和待分类项,输出是待分类项与类别的映射关系。这一阶段也是机械性阶段,由程序完成。
3、P(a|y)的估计
当为离散值时:训练样本中各个划分在每个类别中出现的频率即可用来估计P(a|y)
当为连续值时:通常假定其值服从高斯分布(也称正态分布)。即:
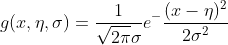
而
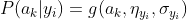
因此只要计算出训练样本中各个类别中此特征项划分的各均值和标准差,代入上述公式即可得到需要的估计值。是当P(a|y)=0怎么办,当某个类别下某个特征项划分没有出现时,就是产生这种现象,这会令分类器质量大大降低。为了解决这个问题,我们引入Laplace校准,它的思想非常简单,就是对没类别下所有划分的计数加1,这样如果训练样本集数量充分大时,并不会对结果产生影响,并且解决了上述频率为0的尴尬局面。
限制条件,就是特征属性必须有条件独立或基本独立(实际上在现实应用中几乎不可能做到完全独立)
四、贝叶斯网络
一个贝叶斯网络定义包括一个有向无环图(DAG)和一个条件概率表集合。DAG中每一个节点表示一个随机变量,可以是可直接观测变量或隐藏变量,而有向边表示随机变量间的条件依赖;条件概率表中的每一个元素对应DAG中唯一的节点,存储此节点对于其所有直接前驱节点的联合条件概率。
贝叶斯网络可以看做是Markov链的非线性扩展。这条特性的重要意义在于明确了贝叶斯网络可以方便计算联合概率分布。一般情况先,多变量非独立联合条件概率分布有如下求取公式:
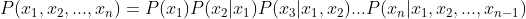
而在贝叶斯网络中,由于存在前述性质,任意随机变量组合的联合条件概率分布被化简成
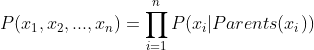
其中Parents表示xi的直接前驱节点的联合,概率值可以从相应条件概率表中查到。
五、朴素贝叶斯分类器居于sklearn.naive_bayes 工具包中,分为:
1)、GaussianNB ,假设特征是正太分布的。一个使用场景:根据给定人的高度和宽度,判定这个人的性别。
2)、MultinomialNB 假设特征就是出现次数。
3)、BernoulliNB 判断词语是否出现二值特征。
六、应用
文本情感分析(观点挖掘)
1、调参利器:GridSearchCV
2、评估函数:metrics.f1_score
3、清洗文章:为TfidfVectorizer 提供自己定制的preprocessor():在字典中定义一系列常用表情和它们的替代词语,用正则表达式及其扩展来定义那些缩写形式。
4、把词语类型考虑进去:词性标注pos:nltk.pos_tag(),这是一个成熟的分类器,它将一列切分后的词语作为输入,输出一列元祖,其中每个元素包含部分原始句子和它们的词性标注。


















