我们采集了大量文本数据,但是文本中有很多重复数据影响我们对于结果的分析。分析前我们需要对这些数据去除重复,如何选择和设计文本的去重算法?常见的有余弦夹角算法、欧式距离、Jaccard相似度、最长公共子串、编辑距离等。这些算法对于待比较的文本数据不多时还比较好用,如果我们的爬虫每天采集的数据以千万计算,我们如何对于这些海量千万级的数据进行高效的合并去重。最简单的做法是拿着待比较的文本和数据库中所有的
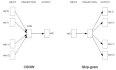
本文首先简单介绍CNN的结构,并不作详细介绍,若需要了解推荐看CS231n课程笔记翻译:卷积神经网络笔记。本文只要讲解CNN的反向传播,CNN的反向传播,其实并不是大多所说的和全连接的BP类似,CNN的全连接部分的BP是与它相同,但是CNN中卷积--池化、池化--卷积部分的BP是不一样的,仔细推导,还是有很多细节地方需要思考的,比如1、在前向传播的过程中,卷积层的输入,是通过卷积核与前
tml http://cs231n.git
1.贝叶斯定理2.朴素贝叶斯分类
1)余弦相似度:通过对两个文本分词,TF-IDF算法向量化,对比两者的余弦夹角,夹角越小相似度越高,但由于有可能一个文章的特征向量词特别多导致整个向量维度很高,使得计算的代价太大不适合大数据量的计算。2)SimHash:算法的主要思想是降维,将高维的特征向量映射成一个f-bit的指纹(fingerprint),通过比较两篇文章的f-bit指纹的Hamming Distance来确定文章是否重复
作者: 张相於,58集团算法架构师,转转搜索推荐部负责人,负责搜索、推荐以及算法相关工作。多年来主要从事推荐系统以及机器学习,也做过计算广告、反作弊等相关工作,并热衷于探索大数据和机器学习技术在其他领域的应用实践。 责编:何永灿(heyc@csdn.net) 概述个性化推荐是大数据时代不可或缺的技术,在电商、信息分发、计算广告、互联网金融等领域都起着重要的作用。具体来
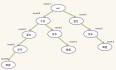
上一篇介绍了关联规则挖掘的一些基本概念和经典的Apriori算法,Aprori算法利用频繁集的两个特性,过滤了很多无关的集合,效率提高不少,但是我们发现Apriori算法是一个候选消除算法,每一次消除都需要扫描一次所有数据记录,造成整个算法在面临大数据集时显得无能为力。今天我们介绍一个新的算法挖掘频繁项集,效率比Aprori算法高很多。 FpGrowth算法通过构造一个树结构来压缩数据记录,
Copyright © 2005-2024 51CTO.COM 版权所有 京ICP证060544号