
1 引言
从目前使用大模型的经验来看,大模型更擅长解决基于生成的软性问题,但在处理基于决策的硬性问题,例如选择正确答案等方面效果相对较差。
生成问题通常使用掩码来隐藏上下文信息,让模型通过上文生成下文,这是一种自监督方法;而决策问题通常需要一个明确的答案,如是或否、A/B/C 选项,因此需要使用有监督数据进行训练或微调模型。
将生成和强化学习结合起来是解决这个问题的一种思路,强化学习通过奖励函数直接或间接地为模型提供有监督的判定标准。因此,在大模型中引入强化学习可以提升其判断能力。
2 RLHF
英文名称:Deep Reinforcement Learning from Human Preferences
中文名称:从人类偏好中进行深度强化学习
链接:https://arxiv.org/abs/1706.03741
作者:Paul F Christiano, Jan Leike, Tom B Brown...
机构:OpenAI, DeepMind
日期:2017-06-12 v1
首先是优化生成聊天对话,由于无法直接提供得分,因此采取了学习相对值的方法。这种方法主要依赖于人类标注的偏好,即确定人类更倾向于接受机器人的 A 回答还是 B 回答。这个概念最早由 OpenAI 和 DeepMind 在 2017 年共同发表的 论文阅读_RLLLM_RLHF 中提出。当时,大模型还未出现,这种方法被用于游戏和机器人环境中,旨在改进强化学习的算法。该算法的训练数据来自人类的标注,提供问题和两个选项,让人类选择更倾向于 A 或 B,或者两者都同样喜欢,或者无法做出判断,从而构建有监督的数据。实验发现,在某些环境中,人类标注的数据比游戏中直接提供得分的学习方式更快、更有效。

3 RLAIF
英文名称: RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback
中文名称: RLAIF:利用AI反馈扩展强化学习
链接: http://arxiv.org/abs/2309.00267v2
作者: Harrison Lee, Samrat Phatale, Hassan Mansoor, Thomas Mesnard, Johan Ferret, Kellie Lu, Colton Bishop, Ethan Hall, Victor Carbune, Abhinav Rastogi, Sushant Prakash
机构: Google Research
日期: 2023-09-01
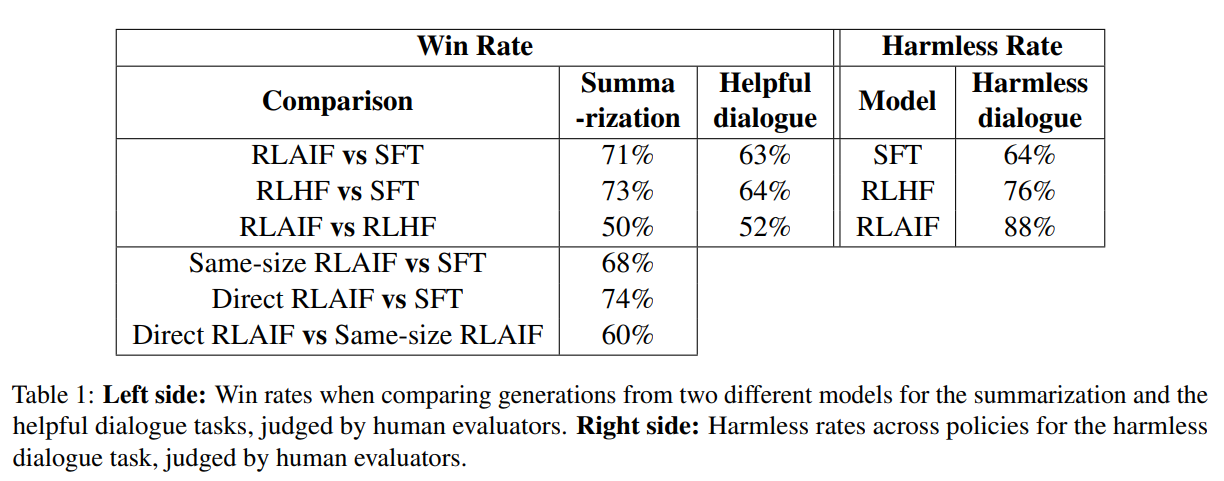
后来出现了大模型,人们使用 RLHF 来训练这些大模型,以提升它们学习人类偏好的能力。随着时间的推移,大模型逐渐成为主流,越来越多的人开始从事偏好数据标注工作。因此,人们开始思考是否可以通过机器自动标注来减少人力成本。论文 论文阅读_RLLLM_RLAIF 中进行的实验中,研究者使用 PaLM 2 对偏好进行标注,并将训练奖励模型的标注学习与直接让模型给出 0-10 分进行了比较。这两种方法的差异在于,传统的标注只是选择两个答案中哪个更好,并没有体现出好坏程度是 9:1 还是 6:4;而大模型有能力可以给出一定的分值。实验证明,在引入这些分值后,即使不训练奖励模型,也能得到更好的效果。
4 SPO
英文名称: A Minimaximalist Approach to Reinforcement Learning from Human Feedback
中文名称: 一种极简极大化的强化学习方法:来自人类反馈的学习
链接: http://arxiv.org/abs/2401.04056v1
作者: Gokul Swamy, Christoph Dann, Rahul Kidambi, Zhiwei Steven Wu, Alekh Agarwal
机构: Google Research
日期: 2024-01-08
进一步的研究发现,上述方法可能隐含着 A>B、B>C,可推出 A>C 的逻辑,而实际上在石头剪刀布这类游戏中,A>C 可能并不成立。因此,提出了 论文阅读_RLLLM_SPO 方法。该方法不再将选择 A 与 B 相比较,而是同时考虑选项 A 和其他多个方法(BCDE...),计算 A 在这些方法中的位置作为其相对客观分值,以更准确地学习选项的好坏,并做出更好的决策。

5 Reflexion
英文名称: Reflexion: Language Agents with Verbal Reinforcement Learning
中文名称: 反思:具有言语强化学习的语言智能体
文章: http://arxiv.org/abs/2303.11366
代码: https://github.com/noahshinn/reflexion
作者: Noah Shinn (Northeastern University)
日期: 2023-05-20 v1
上述方法主要用于优化聊天体验,即通过修改奖励函数打分,使模型生成人类更喜欢的回答。接下来考虑一种扩展使用大模型的场景,在游戏,机器人或者其它 Agent 领域中,环境对于大模型来说是未知的,可以采取行动的选项是固定而非由模型自定义的。在这种状态空间和行为空间受限制且很大的情况下,如何优化大模型的决策能力。
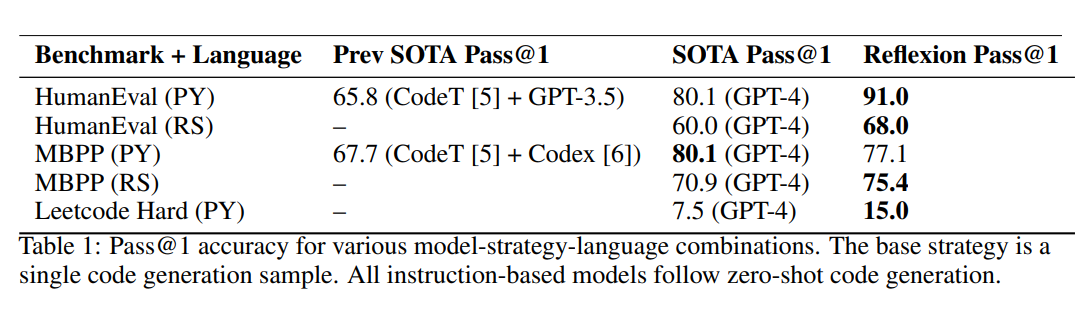
论文 论文阅读_反思模型_Reflexion 中提出了一种不训练模型的方法。该方法通过记录模型在环境中的探索过程,并在模型失败时,利用大模型的思考内容推理出问题所在,并将其记录下来。同时,该方法利用之前的经验和上下文环境生成短期记忆,并通过对过去的反思生成长期记忆。结合了长短期记忆,在模型外围构建辅助方法,而不需要对模型进行调参。最终实验结果表明,该方法在各个实验中将基准得分提升了约 10%,可视为非常有效的适应环境的方法。
6 GLAM
英文名称: Grounding Large Language Models in Interactive Environments with Online Reinforcement Learning
中文名称: 通过在线强化学习在交互式环境中建立大型语言模型
链接: https://arxiv.org/pdf/2302.02662.pdf
代码: https://github.com/flowersteam/Grounding_LLMs_with_online_RL
作者: Thomas Carta, Clément Romac, Thomas Wolf, Sylvain Lamprier, Olivier Sigaud, Pierre-Yves Oudeyer
机构: 法国波尔多大学,Hugging Face...
日期: 2023-02-06 v1
进而有研究利用强化学习模型探索环境,对大模型调参,以优模型在现实环境中的决策力。论文阅读_RLLLM_GLAM 通过使用大模型作为决策模块,为每个选项评分来解决这个问题。该方法基于给定提示 p 的条件下计算每个动作 A 中每个 token 的条件概率。然后通过环境反馈的训练,利用强化学习方法对作为决策模块的大模型进行微调。这种方法结合了对环境的探索和大模型本身的语言推理能力。实验结果表明,在实际场景中表现出了非常好的效果。相比于从专家标注数据中学习,从探索中学习对于解决复杂问题更加有效。
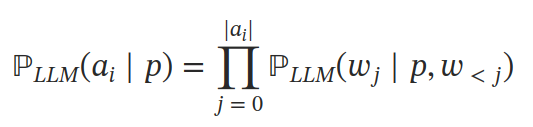
7 RLLLMs
英文名称: True Knowledge Comes from Practice: Aligning LLMs with Embodied Environments via Reinforcement Learning
中文名称: 实践出真知:通过强化学习将LLMS与具体环境对齐
链接: https://arxiv.org/abs/2401.14151
代码: https://github.com/WeihaoTan/TWOSOME
作者: Weihao Tan, Wentao Zhang, Shanqi Liu, Longtao Zheng, Xinrun Wang, Bo An
机构: 新加坡南洋理工大学, 浙江大学, Skywork AI
日期: 2024-01-25
在实验中上述模型也有一些弱点,如:经过强化学习精调的模型损失了之前的部分语言能力,对新对象的泛化能力较强,但对新能力的泛化能力较差。论文阅读_RLLLMs_实践出真知 致力于解决上述问题,他利用了对选项的归一化、Lora 等技术以及提示设计,在半精度 LLaMA-7B 模型上进行实验。所有实验均在一个 NVIDIA Tesla A100 40GB GPU 中完成,并且训练得到的模型仅为 4.2M。这为大模型 + 强化学习的应用提供了进一步指导。



















