
现在,在阅读此博客之前,您必须知道MFCC(梅尔频率倒谱系数)广泛用于人工智能中的语音识别。MFCC基本上用于从给定的音频信号中提取特征。我们先来看一下MFCC中涉及的步骤的流程图说明:
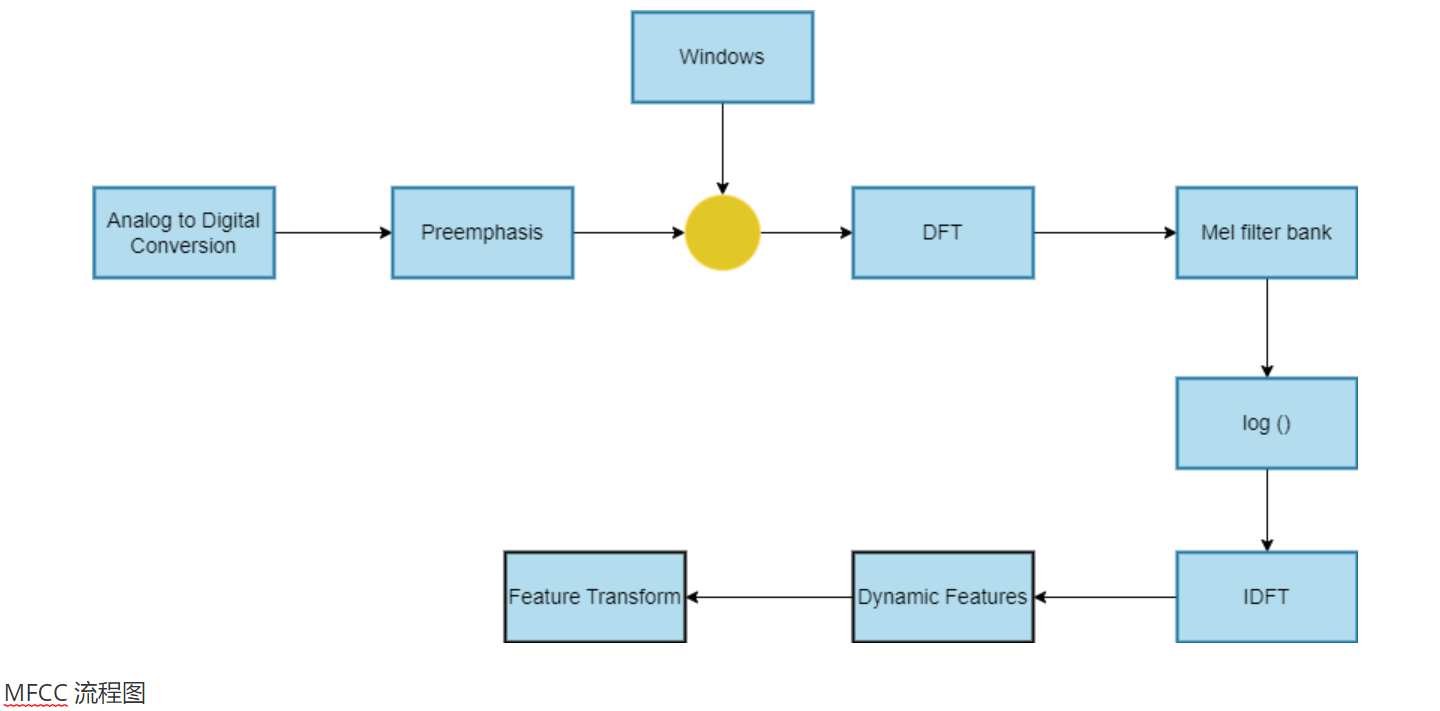
模数转换: 此步骤基本上涉及将模拟信号转换为数字信号。这是因为我们在语音识别中执行的大多数步骤都是在数字信号上完成的。将模拟信号转换为数字信号涉及各种步骤,如采样、量化、归一化、基于帧的处理等。这些步骤的详细说明将在下一篇博客中分享。
预加重: 预加重步骤通常使用一阶高通滤波器实现。滤波器强调高频内容,这对于区分语音和音频信号中的重要细节至关重要。通过预加重应用高通滤波器,高频分量的幅度相对于低频分量得到提升。在较高频率下增加声音的能量将提高手机检测的准确性。(不要将自己与手机混淆)
窗口化: 简单来说,窗口化是指将音频信号分成不同的段,标准为25ms和10ms之间的距离。此外,在制作段以避免由于切碎而不是矩形段而导致的过度噪音的同时,我们有汉明窗口。 选择值25ms的原因: 该人在1秒内说出的平均单词数为3个单词。每个单词包含 4 个电话,而电话又包含 3 个状态。 因此,1 秒内的状态总数 = 3 * 4 * 3 = 36 个状态。因此,1 个状态大约需要 28 毫秒,接近所选值 25 毫秒。
**DFT(离散傅里叶变换):
**在接下来的步骤中,我们将使用DFT将信号从时域转换为频域,以计算MFCC系数。简单来说,你可以把它看作是一系列复数。
Mel Filter Bank: 在深入探讨这个术语之前,让我们先了解一下像我们这样的人类是如何听到声音的?基本上,当我们将其与高频音频进行比较时,人耳对低频音频非常敏感。仅举一个例子,我们可以说人类可以轻松区分 100Hz 和 200Hz 音频之间的区别,但我们很难区分 2100Hz 和 2000Hz 音频之间的区别。因此,为了在机器中模拟这一点,我们使用mel标度来找到人类可以听到的音频频率:
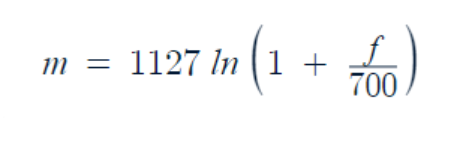
梅尔频率
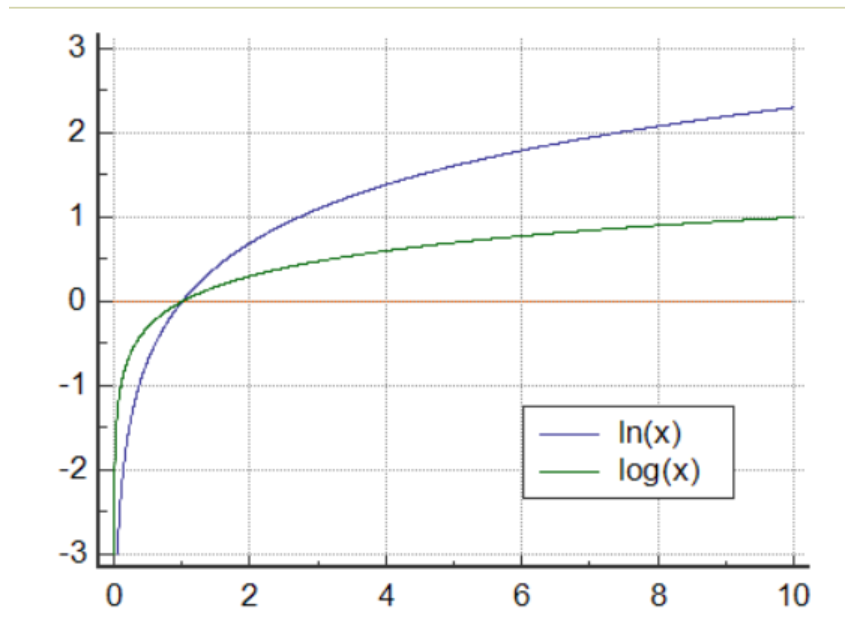
Log(): 让我们回顾一下对数函数的一个重要属性,它告诉我们,在较低的输入值下,梯度相对较*大,而输入值较大的梯度相对较小。*这意味着随着输入值的增加,输入值也会减小。这类似于我们的听力机制。人耳在较低能量下对音频信号比在较高能量下更敏感。这就是为什么我们将应用 log() 函数来模仿人耳。
IDFT: IDFT 代表 逆离散傅里叶变换。提取MFCC特征后,我们需要将音频信号从频域转换为时域。MFCC模型在应用IDFT和能量作为特征后,采用前12个系数。
动态特征: 除了13个特征外,MFCC还将考虑特征的一阶和二阶导数。这给我们留下了更多的 26 个功能需要考虑。因此,MFCC 将从每个音频信号生成 39 个特征。 **Δ系数(Δ MFCC)或一阶导数*表示静态MFCC系数随时间的变化率。它们有助于捕获动态变化。 增量-增量系数 (ΔΔ MFCC) 或二阶导数***表示增量系数随时间变化的加速度或变化率。它们都有助于获得每个帧的最终特征向量。


















